

Microsoft의 최신 연구는 Prompt Engineering의 힘을 다시 한 번 입증합니다. -
추가적인 미세 조정이나 전문가 계획이 필요 없이 GPT-4는 프롬프트만으로 "전문가"가 될 수 있습니다.
의료 전문 분야에서 최신 프롬프트 전략인 Medprompt를 사용하여 GPT-4는 MultiMed QA의 9개 테스트 세트에서 최고의 결과를 달성했습니다.
MedQA 데이터 세트(미국 의료 면허 시험 문제)에서 Medprompt는 GPT-4의 정확도를 처음으로 90%를 초과하여 BioGPT 및 Med-PaLM 및 기타 미세 조정 방법을 능가했습니다.
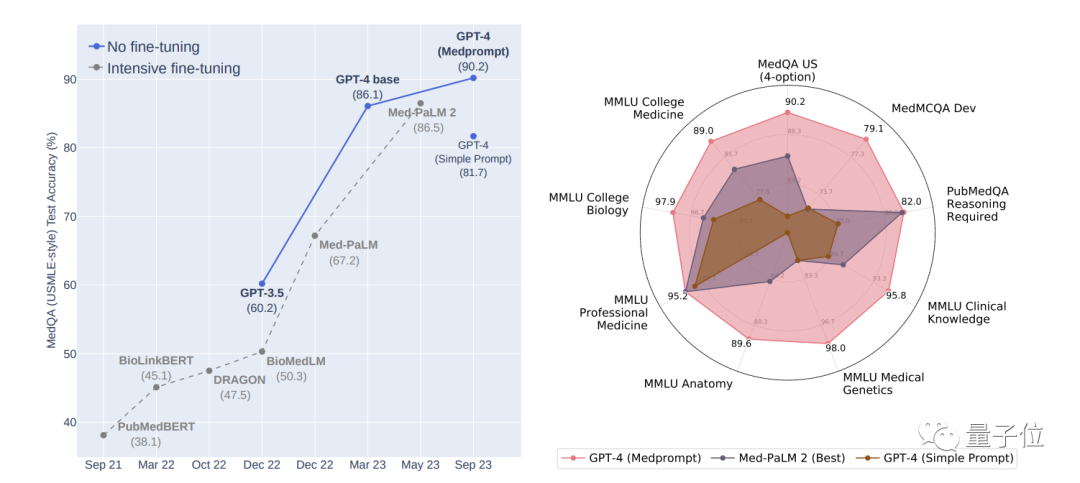
연구원들은 또한 Medprompt 방법이 보편적이며 의학에만 적용 가능한 것이 아니라 전기 공학, 기계 학습, 법학 및 기타 전공으로 확장될 수 있다고 밝혔습니다.
이 연구는 X(구 트위터)에 공유되자마자 많은 네티즌들의 관심을 끌었습니다.
와튼스쿨 Ethan Mollick 교수, Artificial Intuition 저자 Carlos E. Perez 등이 전달하고 공유해 주었습니다.
Carlos E. Perez는 "훌륭한 유도 전략에는 많은 미세 조정이 필요할 수 있습니다"라고 직접 말했습니다.
일부 네티즌들은 이러한 예감을 오랫동안 갖고 있었다고 하는데 정말 보기 좋습니다. 지금 결과!

일부 네티즌들은 이것이 정말 "급진적"이라고 생각합니다
GPT-4는 산업을 바꿀 수 있는 기술이며, 우리는 프롬프트의 한계를 건드리지도, 미세 조정의 한계에도 도달하지 않았습니다. .

Medprompt는 세 가지 마법 무기를 포함한 여러 프롬프트 전략의 조합입니다:
다음으로 하나씩 소개하겠습니다

Fewer-shot 학습은 모델을 빠르게 만드는 효과적인 방법입니다 맥락을 배우기 위해. 간단히 말해서 몇 가지 예를 입력하고 모델이 특정 도메인에 빠르게 적응하도록 하고 작업 형식을 따르는 방법을 배우십시오.
특정 작업 프롬프트에 사용되는 이러한 소수 샘플 예제는 일반적으로 고정이므로 예제의 대표성과 폭에 대한 요구 사항이 높습니다.
이전 방법은 도메인 전문가가 수동으로 예제를 만들도록하는 것이었지만, 그렇다고 해도 전문가가 선별한 고정된 소수 샘플 예제가 모든 작업에서 대표성을 갖는다는 보장은 없습니다.
Microsoft 연구진은 동적 퓨샷 예제 방법을 제안했습니다. 그래서
작업 훈련 세트를 퓨샷 예제의 소스로 사용할 수 있고, 훈련 세트가 충분히 크면 다른 예제를 사용할 수 있다는 아이디어입니다. 다양한 작업 입력을 위해 선택됨 샘플 예가 거의 없습니다.
특정 작업 측면에서 연구원들은 먼저 text-embedding-ada-002 모델을 사용하여 각 훈련 샘플과 테스트 샘플에 대한 벡터 표현을 생성했습니다. 그런 다음 각 테스트 샘플에 대해 벡터의 유사성을 비교하여 훈련 샘플에서 가장 유사한 k개의 샘플을 선택합니다
미세 조정 방법과 비교하여 동적 소수 샷 선택은 훈련 데이터를 활용하지만 모델 매개변수가 광범위한 업데이트를 필요로 하지 않습니다.
CoT(사고 사슬) 방법은 모델이 단계별로 생각하고 일련의 중간 추론 단계를 생성하는 방법입니다.
이전 방법에서는 전문가가 프롬프트에 따라 몇 가지 예를 수동으로 작성해야 했습니다. 생각의 사슬

여기에서 연구원들은 GPT-4가 다음 프롬프트를 사용하여 훈련 예제를 위한 사고 사슬을 생성하도록 요청할 수 있다는 것을 발견했습니다.
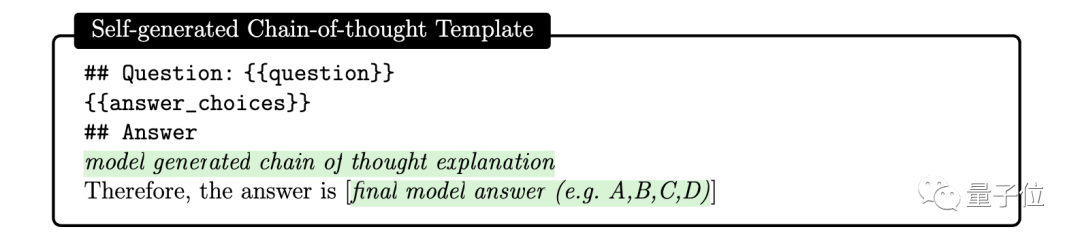
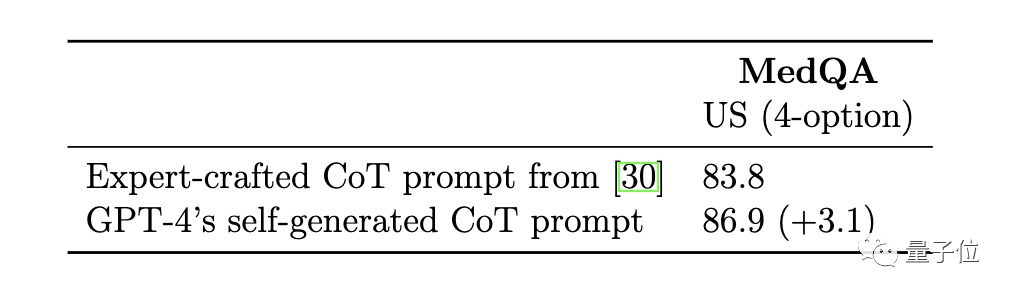
그러나 연구원들은 또한 자동으로 생성된 사고 사슬에 잘못된 추론이 포함될 수 있음을 지적했습니다. 단계를 거치므로 인증 태그가 필터로 설정되어 오류를 효과적으로 줄일 수 있습니다.
Med-PaLM 2 모델에서 전문가가 직접 제작한 사고 사슬 예제와 비교하면 GPT-4에서 생성된 사고 사슬의 기본 원리는 더 길고 단계별 추론 논리는 더 세밀합니다. .
GPT-4는 객관식 질문을 처리할 때 편향을 가질 수 있습니다. 즉, 옵션의 내용이 무엇이든 항상 A를 선택하거나 항상 B를 선택하는 경향이 있습니다. 이것이 위치 편향입니다
이 문제를 해결하기 위해 연구진은 영향을 줄이기 위해 원래 옵션의 순서를 재배열하기로 결정했습니다. 예를 들어 옵션의 원래 순서는 ABCD이며 BCDA, CDAB 등으로 변경할 수 있습니다. 그런 다음 GPT-4가 각 라운드에서 다른 옵션 순서를 사용하여 여러 라운드의 예측을 수행하도록 합니다. 이는 GPT-4가 옵션의 내용을 고려하도록 "강제"합니다.
마지막으로 여러 라운드의 예측 결과에 투표하고 가장 일관되고 올바른 옵션을 선택하세요.
위 프롬프트 전략의 조합이 메드프롬프트인지 테스트 결과를 살펴보겠습니다.
여러 테스트에서 최적
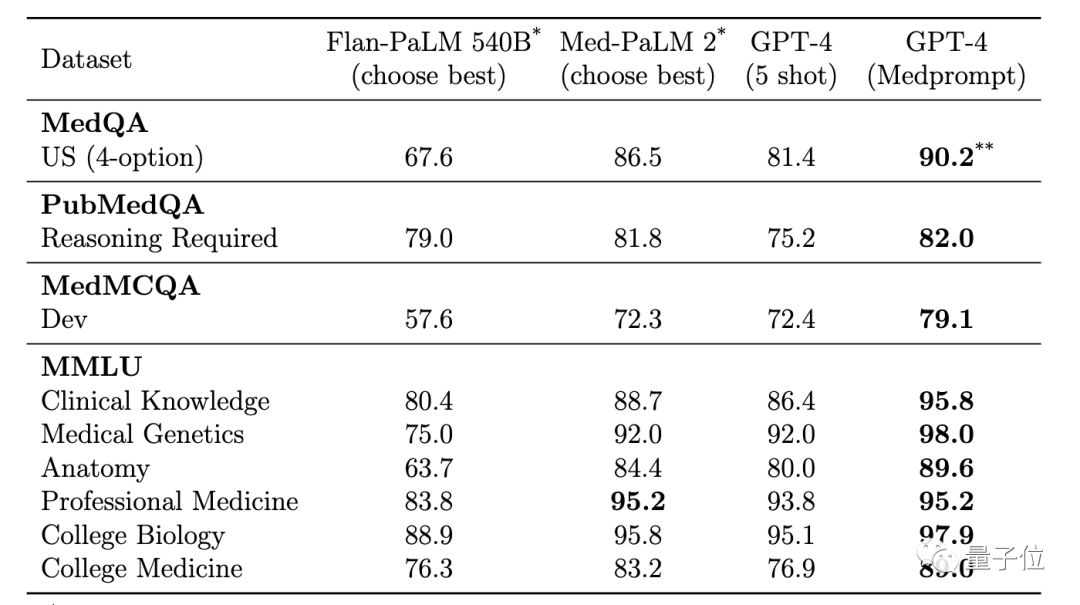 Medprompt 프롬프트 전략을 사용하는 GPT-4는 MultiMedQA의 9개 벤치마크 데이터 세트 모두에서 가장 높은 점수를 획득하여 Flan-PaLM 540B 및 Med-PaLM 2를 능가했습니다.
Medprompt 프롬프트 전략을 사용하는 GPT-4는 MultiMedQA의 9개 벤치마크 데이터 세트 모두에서 가장 높은 점수를 획득하여 Flan-PaLM 540B 및 Med-PaLM 2를 능가했습니다.
또한 연구원들은 "Eyes-Off" 데이터에 대한 Medprompt 전략의 성과에 대해서도 논의했습니다. 소위 "Eyes-Off" 데이터는 모델이 훈련 또는 최적화 과정에서 본 적이 없는 데이터를 의미합니다. 모델이 훈련 데이터에 과적합되었는지 테스트하는 데 사용됩니다
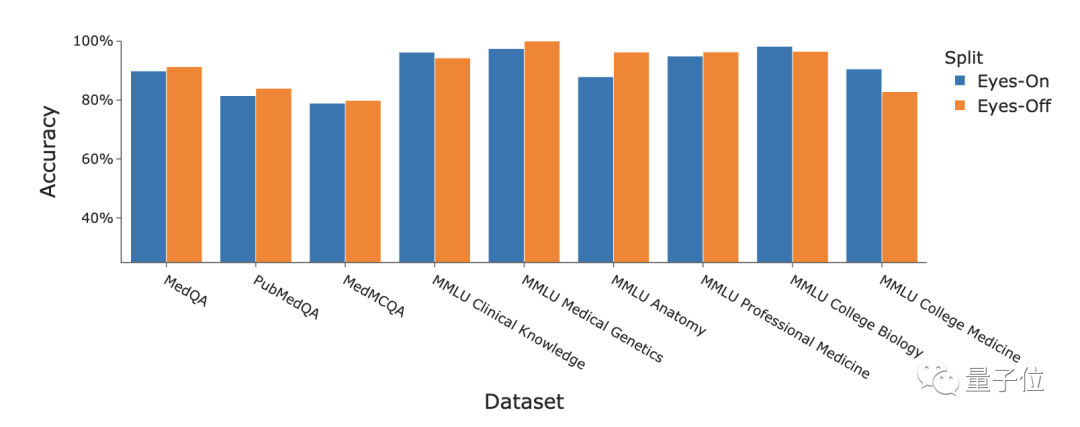 결과 GPT-4와 결합됩니다. Medprompt 전략은 여러 의료 분야에서 사용되었으며 벤치마크 데이터 세트에서 평균 정확도 91.3%로 좋은 성능을 보였습니다.
결과 GPT-4와 결합됩니다. Medprompt 전략은 여러 의료 분야에서 사용되었으며 벤치마크 데이터 세트에서 평균 정확도 91.3%로 좋은 성능을 보였습니다.
연구원들은 MedQA 데이터 세트에 대한 절제 실험을 수행하여 세 가지 구성 요소가 전체 성능에 미치는 상대적인 기여도를 조사했습니다
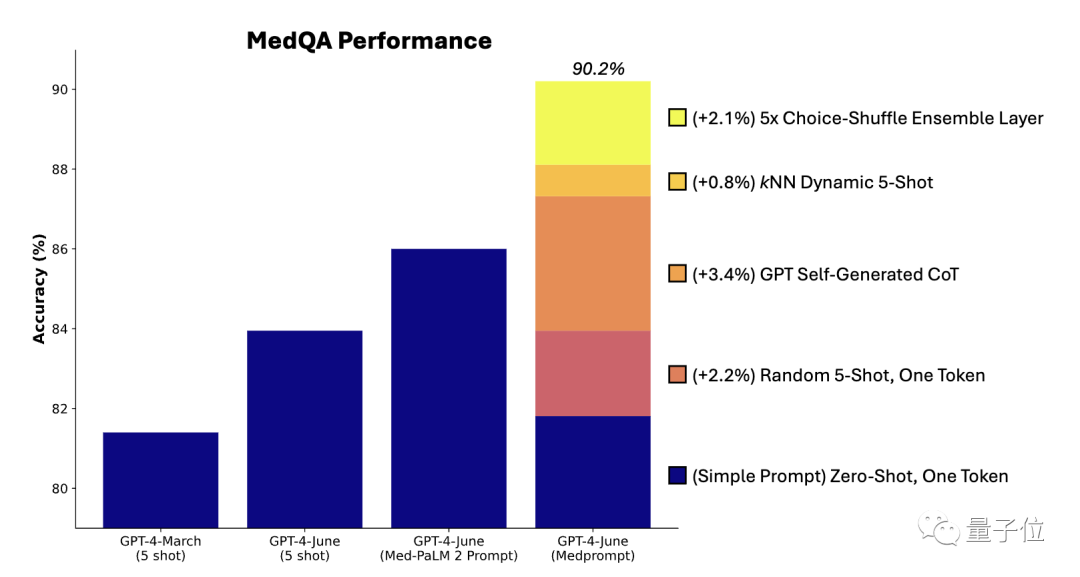 그 중에서 사고 연쇄 단계의 자동 생성이 성능 향상에 가장 큰 역할을 합니다
그 중에서 사고 연쇄 단계의 자동 생성이 성능 향상에 가장 큰 역할을 합니다
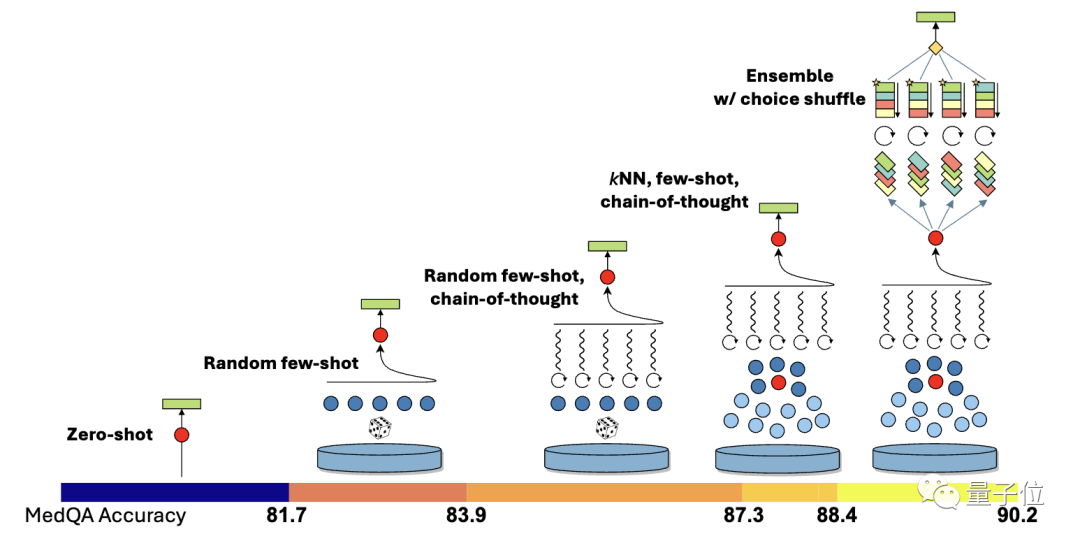 GPT-4에서 자동으로 생성된 사고 체인의 점수는 Med-PaLM 2에서 전문가가 선별한 점수보다 높으며 수동 개입이 필요하지 않습니다.
GPT-4에서 자동으로 생성된 사고 체인의 점수는 Med-PaLM 2에서 전문가가 선별한 점수보다 높으며 수동 개입이 필요하지 않습니다.
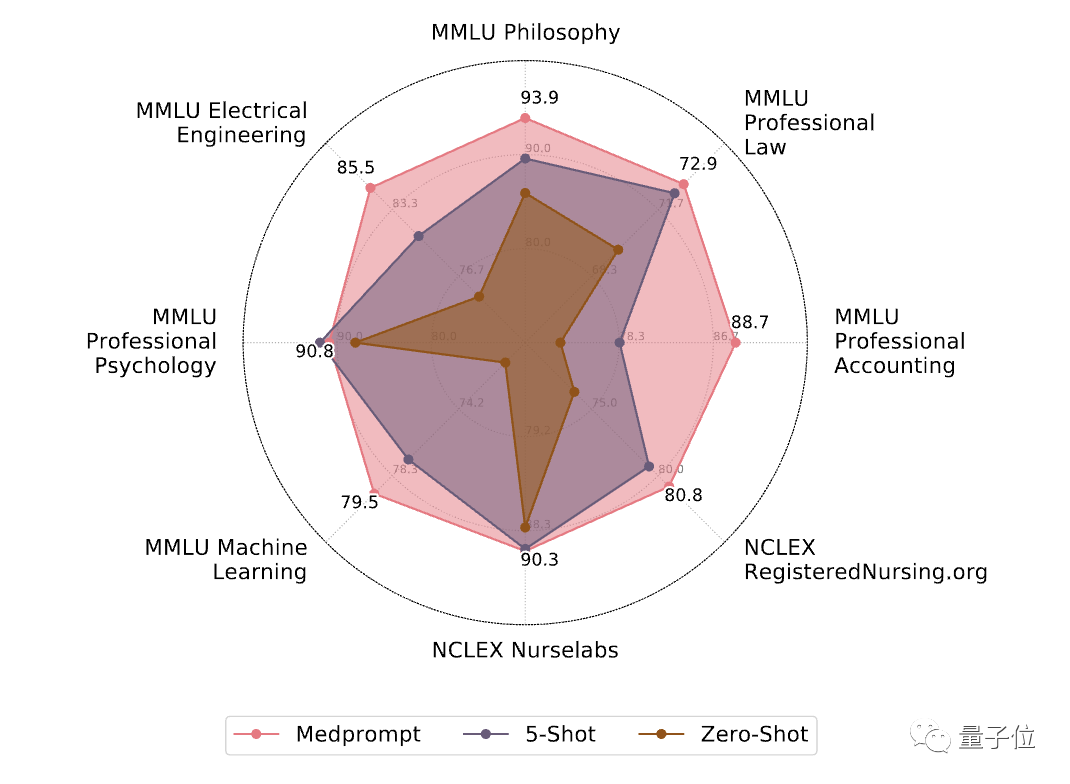
 마지막으로 연구원들은 교차 도메인 일반화 기능도 탐색했습니다. Medprompt의 MMLU 벤치마크에는 전기 공학, 기계 학습, 철학, 전문 회계, 전문 법률 및 전문 심리학 분야의 문제를 다루는 6개의 서로 다른 데이터 세트가 포함되어 있습니다.
마지막으로 연구원들은 교차 도메인 일반화 기능도 탐색했습니다. Medprompt의 MMLU 벤치마크에는 전기 공학, 기계 학습, 철학, 전문 회계, 전문 법률 및 전문 심리학 분야의 문제를 다루는 6개의 서로 다른 데이터 세트가 포함되어 있습니다.
NCLEX(국가 간호 자격증 시험) 문제가 포함된 두 개의 추가 데이터 세트도 추가되었습니다.
결과에 따르면 이러한 데이터 세트에 대한 Medprompt의 효과는 MultiMedQA 의료 데이터 세트의 개선과 유사하며 평균 정확도가 7.3% 증가했습니다.
위 내용은 Microsoft는 'Prompt Project'만으로 GPT-4를 의료 전문가로 만들었습니다! 12개 이상의 고도로 미세 조정된 모델, 전문적인 테스트 정확도가 처음으로 90%를 초과했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



