

휴대폰계에 관심을 갖고 있는 친구들이라면 '안 받아도 점수를 준다'는 말이 낯설지 않을 거라 믿습니다. 예를 들어 AnTuTu, GeekBench와 같은 이론적인 성능 테스트 소프트웨어는 휴대폰의 성능을 어느 정도 반영할 수 있기 때문에 플레이어들로부터 많은 관심을 받았습니다. 마찬가지로 성능을 측정하기 위한 PC 프로세서 및 그래픽 카드용 벤치마킹 소프트웨어도 있습니다
'모든 것이 벤치마킹 가능'하기 때문에 가장 인기 있는 대형 AI 모델도 벤치마킹 대회에 참가하기 시작했습니다. 특히 '100모델 전쟁'이 시작된 이후에는 거의 매일 획기적인 발전이 이루어지고 있으며 각 회사는 스스로를 '벤치마'라고 부릅니다. 벤치마킹 1위".一"
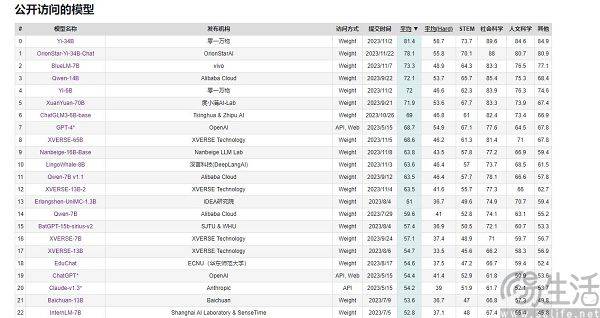
국내 대형 AI 모델은 성능 점수 측면에서는 거의 뒤처지지 않지만, 사용자 경험 측면에서는 결코 GPT-4를 능가할 수 없습니다. 이는 주요 판매 지점에서 각 휴대폰 제조업체가 항상 자신의 제품이 "판매 1위"라고 주장할 수 있다는 의문을 제기합니다. 하지만 AI 대형 모델 분야에서는 상황이 다르다. 결국 이들의 평가 기준은 기본적으로 MMLU(멀티태스킹 언어 이해 능력을 측정하는 데 사용), Big-Bench(LLM 능력을 정량화하고 추정하는 데 사용), AGIEval(대화 능력을 평가하는 데 사용) 등 기본적으로 통일되어 있습니다. 인간 수준의 문제).
현재 중국에서 자주 인용되는 대규모 모델 평가 목록으로는 SuperCLUE, CMMLU, C-Eval 등이 있습니다. 그 중 CMMLU와 C-Eval은 칭화대학교, 상하이 교통대학교, 에든버러대학교가 공동으로 구축한 종합 시험 평가 세트입니다. CMMLU는 MBZUAI, Shanghai Jiao Tong University 및 Microsoft Research Asia가 공동으로 출범했습니다. SuperCLUE는 주요 대학 인공지능 전문가들이 공동 집필했습니다
우리 모두 알고 있듯이 스마트폰 SoC, 컴퓨터 CPU 및 그래픽 카드는 수명을 보호하기 위해 고온에서 자동으로 주파수를 낮추고 저온에서는 칩 성능을 향상시킬 수 있습니다. 따라서 일부 사람들은 휴대폰을 냉장고에 넣거나 컴퓨터에 더 강력한 냉각 시스템을 장착하여 성능 테스트를 수행하며 일반적으로 평소보다 더 높은 점수를 얻을 수 있습니다. 또한, 주요 휴대폰 제조사에서도 표준 운영이 된 다양한 벤치마킹 소프트웨어에 대해 '전용 최적화'를 실시할 예정입니다
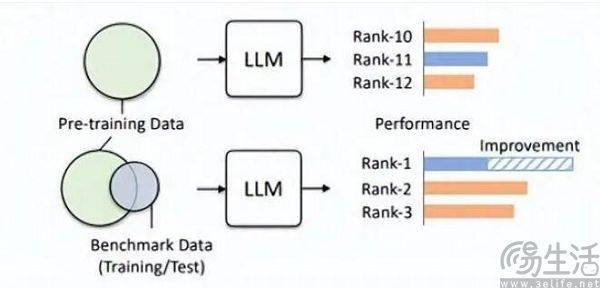
시험 전, 우연히 시험지와 표준 답안을 보고, 예상치 못한 문제를 외우면 시험 점수가 크게 향상될 것이라고 상상할 수 있습니다. 따라서 대형 모델 목록에서 미리 설정된 문제 은행이 훈련 세트에 추가되어 대형 모델이 벤치마크 데이터에 맞는 모델이 됩니다. 게다가 현재 LLM 자체가 기억력이 뛰어나기로 유명해서, 표준 답변을 암기하는 것이 식은 죽 먹기입니다
Hillhouse 팀의 연구원들은 벤치마크 누출로 인해 대형 모델이 과장된 결과를 실행하게 될 수 있다는 사실을 발견했습니다. 예를 들어 1.3B 모델은 일부 작업에서 크기가 10배 더 큰 모델을 능가할 수 있지만 부작용은 " 시험 응시" 대형 모델의 경우 다른 일반적인 테스트 작업의 성능에 부정적인 영향을 미칩니다. 결국, 생각해보면 대형 AI 모델은 원래 '질문 작성기'였으나 특정 목록에서 높은 점수를 얻기 위해 '질문 암기기'가 되었다는 사실을 알 수 있습니다. 목록의 특정 지식과 출력 스타일을 사용하면 확실히 대규모 모델을 오도할 수 있습니다.

훈련 세트, 검증 세트, 테스트 세트가 교차하지 않는 것은 분명 이상적인 상태일 뿐입니다. 결국 현실은 매우 희박하며, 데이터 유출 문제는 근본적으로 거의 불가피합니다. 관련 기술이 지속적으로 발전하면서 현재 대형 모델의 초석이 되는 트랜스포머 구조의 메모리와 수신 능력이 지속적으로 향상되고 있다. 올여름 마이크로소프트 리서치의 일반 AI 전략을 통해 모델이 1억 개의 토큰을 부담 없이 받을 수 있게 됐다. 건망증은 용납할 수 없습니다. 즉, 미래에는 대형 AI 모델이 인터넷 전체를 읽을 수 있는 능력을 갖게 될 가능성이 높다.
기술적 진보를 제쳐두더라도, 현재의 기술 수준으로는 고품질의 데이터가 항상 부족하고 생산 능력도 제한되어 있기 때문에 데이터 오염을 피하기가 사실상 어렵습니다. AI 연구팀인 에포크(Epoch)가 올해 초 발표한 논문에 따르면 AI는 5년 이내에 고품질의 인간 언어 데이터를 모두 소진할 것이며, 이 결과는 인간 언어의 성장률을 높일 것이라는 점이다. 즉, 앞으로 5년 안에 모든 인류가 출판하게 될 책, 쓰여진 논문, 쓰여진 코드를 모두 고려하여 결과를 예측합니다.
데이터 세트가 평가에 적합하다면 사전 훈련에 확실히 더 효과적일 것입니다. 예를 들어 OpenAI의 GPT-4는 권위 있는 추론 평가 데이터 세트 GSM8K를 사용합니다. 따라서 현재 대규모 모델 평가 분야에서는 대규모 모델의 데이터에 대한 수요가 끝이 없어 평가기관이 인공지능 대규모 모델보다 더 빠르고 더 멀리 나아가야 하는 난처한 문제가 있다. 제조업 자. 하지만 오늘날 평가기관은 이런 일을 전혀 할 수 없는 것 같습니다
일부 제조사에서는 왜 대형 모델의 주행 점수에 주목하고, 순위를 잇달아 올리려고 노력하는 걸까요? 실제로 이 동작의 이면에 있는 논리는 앱 개발자가 자신의 앱 사용자 수에 물을 주입하는 것과 정확히 동일합니다. 결국 앱의 가치를 측정하는 데 있어 사용자 규모는 핵심 요소이며, 현재 대규모 AI 모델의 초기 단계에서는 평가 목록의 결과가 결국 상대적으로 객관적인 유일한 기준이 됩니다. 대중의 인식, 높은 점수는 강력한 성과와 동일함을 의미합니다.
순위를 브러싱하면 강력한 홍보 효과를 가져올 수 있고 심지어 자금 조달의 기반을 마련할 수도 있지만, 상업적 이익이 추가되면 대형 AI 모델 제조업체가 순위를 브러싱하기 위해 서두르게 될 것입니다.
위 내용은 동의하지 않으면 점수를 얻게 된다. 국내 대형 AI 모델은 왜 '순위 스와핑'에 중독되는 걸까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



