

대형 언어 모델(LLM)의 등장은 여러 분야에서 혁신을 촉진했습니다. 그러나 CoT(사고 사슬) 프롬프트 및 ICL(상황별 학습)과 같은 전략에 의해 프롬프트가 점점 복잡해지면서 컴퓨팅 문제가 발생합니다. 이러한 긴 프롬프트에는 추론을 위한 상당한 리소스가 필요하므로 효율적인 솔루션이 필요합니다. 이 기사에서는 효율적인 추론을 수행하기 위해 독점적인 LlamaIndex와 LLMLingua의 통합을 소개합니다
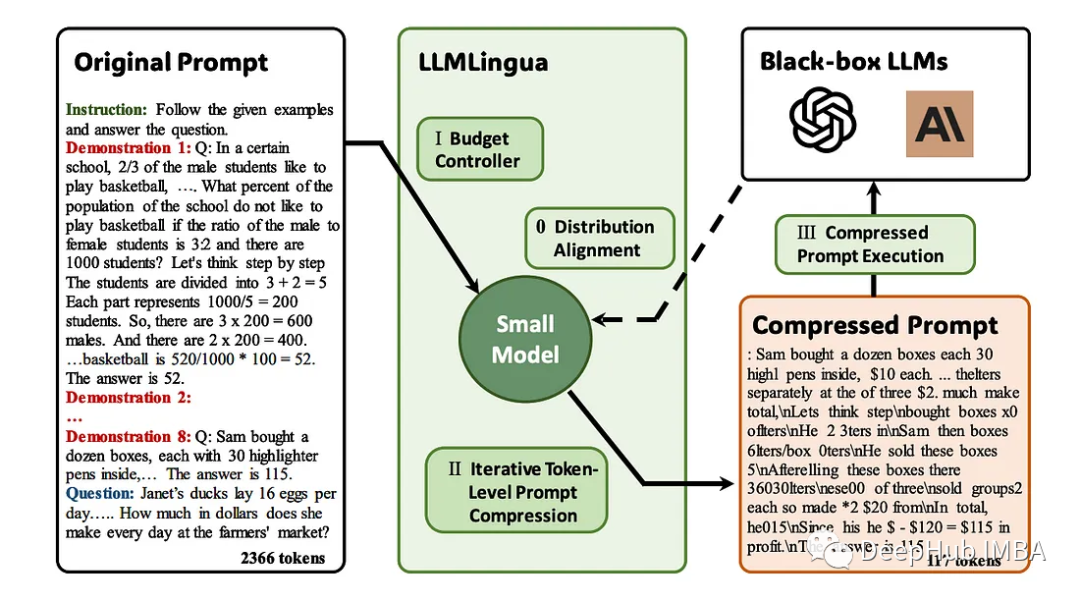
LLMLlingua는 EMNLP 2023에서 Microsoft 연구원이 발표한 논문입니다. LongLLMLingua는 긴 상황 시나리오에서 빠른 압축을 통해 llm을 향상시키는 방법입니다. 핵심 정보를 인지하는 능력을 위해서입니다.
LLMLingua와 협력하여 LLM 애플리케이션의 자세한 프롬프트에 대한 선구적인 솔루션으로 등장합니다. 이 접근 방식은 긴 프롬프트를 압축하는 동시에 의미적 무결성을 보장하고 추론 속도를 높이는 데 중점을 둡니다. 다양한 압축 전략을 결합하여 힌트 길이와 계산 효율성의 균형을 맞추는 미묘한 방법을 제공합니다.
다음은 LLMLingua와 LlamaIndex 통합의 장점입니다.
LLMLingua와 LlamaIndex의 통합은 LLML의 신속한 최적화를 위한 중요한 단계입니다. LlamaIndex는 다양한 LLM 애플리케이션에 맞춰 사전 최적화된 힌트가 포함된 전문 저장소입니다. 이 통합을 통해 LLMLingua는 풍부한 도메인별 미세 조정 힌트 세트에 액세스하여 힌트 압축 기능을 향상시킬 수 있습니다.
LLMLingua는 LlamaIndex의 최적화 힌트 라이브러리와의 시너지 효과를 통해 LLM 애플리케이션의 효율성을 향상시킵니다. LLAMA의 특화된 단서를 활용하여 LLMLingua는 압축 전략을 미세 조정하여 단서의 길이를 줄이면서 도메인별 컨텍스트를 보존할 수 있습니다. 이 협력을 통해 주요 도메인 뉘앙스를 유지하면서 추론 속도가 크게 향상되었습니다.
LLMLingua와 LlamaIndex의 통합으로 대규모 LLM 애플리케이션에 대한 영향력이 확대됩니다. LLMLingua는 LLAMA의 전문가 팁을 활용하여 압축 기술을 최적화하여 긴 팁을 처리하는 데 따른 계산 부담을 줄였습니다. 이러한 통합은 추론을 가속화할 뿐만 아니라 중요한 도메인별 정보의 보존을 보장합니다.
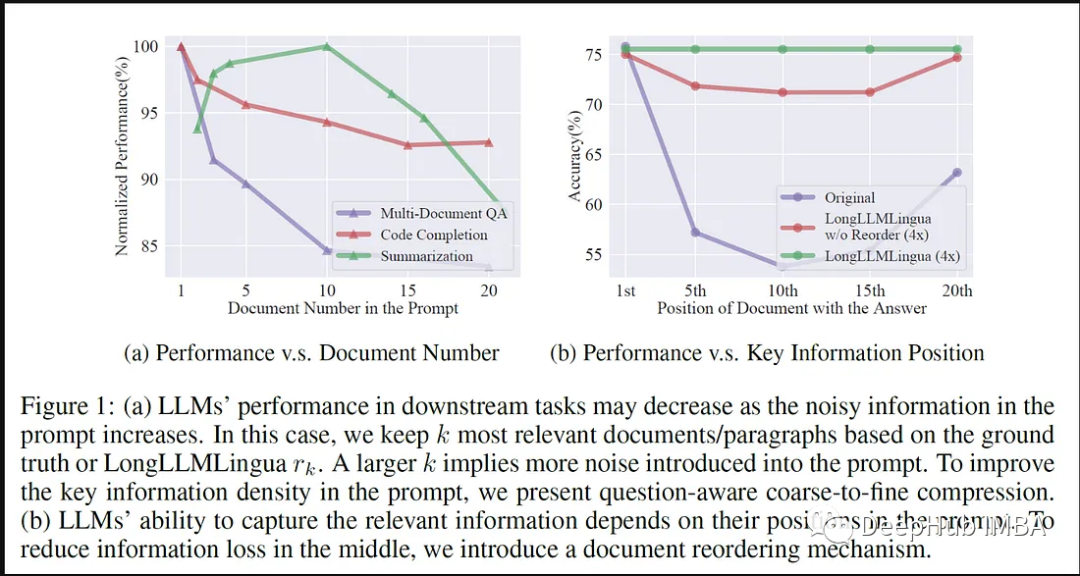
LlamaIndex를 사용하여 LLMLingua를 구현하려면 효율적인 힌트 압축 및 향상된 추론 속도를 달성하기 위한 특수 힌트 라이브러리 사용을 포함하여 일련의 구조화된 프로세스가 필요합니다
먼저 LLMLingua와 LlamaIndex 간의 연결을 설정해야 합니다. 여기에는 액세스 권한, API 구성 및 적시 검색을 위한 연결 설정이 포함됩니다.
LlamaIndex는 다양한 LLM 응용 프로그램에 맞춰진 사전 최적화 팁이 포함된 전문 저장소 역할을 합니다. LLMLingua는 이 저장소에 액세스하여 도메인별 힌트를 검색하고 이러한 힌트를 압축에 활용합니다.
4. 압축 전략 미세 조정
5. 실행 및 추론
6 반복적인 개선 및 개선
7. 테스트 및 검증
코드 구현
설치 패키지:
# Install dependency. !pip install llmlingua llama-index openai tiktoken -q # Using the OAI import openai openai.api_key = "<insert_openai_key>"</insert_openai_key>
데이터 가져오기:
!wget "https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1" -O paul_graham_essay.txt
모델 로드 :
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,load_index_from_storage,StorageContext, ) # load documents documents = SimpleDirectoryReader(input_files=["paul_graham_essay.txt"] ).load_data()
벡터 저장:
index = VectorStoreIndex.from_documents(documents) retriever = index.as_retriever(similarity_top_k=10) question = "Where did the author go for art school?" # Ground-truth Answer answer = "RISD" contexts = retriever.retrieve(question) contexts = retriever.retrieve(question) context_list = [n.get_content() for n in contexts] len(context_list) #Output #10
원본 프롬프트 및 반환
# The response from original prompt from llama_index.llms import OpenAI llm = OpenAI(model="gpt-3.5-turbo-16k") prompt = "\n\n".join(context_list + [question]) response = llm.complete(prompt) print(str(response)) #Output The author went to the Rhode Island School of Design (RISD) for art school.
LLMLingua 설정
from llama_index.query_engine import RetrieverQueryEngine from llama_index.response_synthesizers import CompactAndRefine from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor node_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder,"dynamic_context_compression_ratio": 0.3,}, )通过LLMLingua进行压缩
retrieved_nodes = retriever.retrieve(question) synthesizer = CompactAndRefine() from llama_index.indices.query.schema import QueryBundle # postprocess (compress), synthesize new_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=question) ) original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes]) compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes]) original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts) compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
打印2个结果对比:
print(compressed_contexts) print() print("Original Tokens:", original_tokens) print("Compressed Tokens:", compressed_tokens) print("Comressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")打印的结果如下:
next Rtm's advice hadn' included anything that. I wanted to do something completely different, so I decided I'd paint. I wanted to how good I could get if I focused on it. the day after stopped on YC, I painting. I was rusty and it took a while to get back into shape, but it was at least completely engaging.1] I wanted to back RISD, was now broke and RISD was very expensive so decided job for a year and return RISD the fall. I got one at Interleaf, which made software for creating documents. You like Microsoft Word? Exactly That was I low end software tends to high. Interleaf still had a few years to live yet. [] the Accademia wasn't, and my money was running out, end year back to thelot the color class I tookD, but otherwise I was basically myself to do that for in993 I dropped I aroundidence bit then my friend Par did me a big A rent-partment building New York. Did I want it Itt more my place, and York be where the artists. wanted [For when you that ofs you big painting of this type hanging in the apartment of a hedge fund manager, you know he paid millions of dollars for it. That's not always why artists have a signature style, but it's usually why buyers pay a lot for such work. [6] Original Tokens: 10719 Compressed Tokens: 308 Comressed Ratio: 34.80x
验证输出:
response = synthesizer.synthesize(question, new_retrieved_nodes) print(str(response)) #Output #The author went to RISD for art school.
LLMLingua与LlamaIndex的集成证明了协作关系在优化大型语言模型(LLM)应用程序方面的变革潜力。这种协作彻底改变了即时压缩方法和推理效率,为上下文感知、简化的LLM应用程序铺平了道路。
这种集成不仅可以提升推理速度,而且可以保证在压缩提示中保持语义的完整性。通过对基于LlamaIndex特定领域提示的压缩策略进行微调,我们平衡了提示长度的减少和基本上下文的保留,从而提高了LLM推理的准确性
从本质上讲,LLMLingua与LlamaIndex的集成超越了传统的提示压缩方法,为未来大型语言模型应用程序的优化、上下文准确和有效地针对不同领域进行定制奠定了基础。这种协作集成预示着大型语言模型应用程序领域中效率和精细化的新时代的到来。
위 내용은 LLMLingua: LlamaIndex 통합, 힌트 압축 및 효율적인 대규모 언어 모델 추론 서비스 제공의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



