

2D 확산 모델의 도입으로 이미지 콘텐츠 제작 과정이 대폭 단순화되고 2D 디자인 산업에 혁신이 일어났습니다. 최근에는 이러한 확산 모델이 3D 생성으로 확장되어 VR, AR, 로봇공학, 게임과 같은 응용 분야에서 인건비를 절감했습니다. 많은 연구가 사전 훈련된 2D 확산 모델의 사용과 SDS(Scored Distillation Sampling) 손실을 사용하는 NeRF 방법을 탐색하기 시작했습니다. 그러나 SDS 기반 방법은 일반적으로 몇 시간의 리소스 최적화가 필요하며 다면적인 야누스 문제와 같은 그래픽의 기하학적 문제를 일으키는 경우가 많습니다
반면에 연구자는 각 리소스를 최적화하는 데 많은 시간을 들이지 않고도 이를 달성할 수 있습니다. 생성된 3차원 확산모델을 다양화하기 위한 다양한 시도도 이루어졌다. 이러한 방법을 사용하려면 일반적으로 교육용 실제 데이터가 포함된 3D 모델/포인트 클라우드를 획득해야 합니다. 그러나 실제 이미지의 경우 이러한 훈련 데이터를 얻기가 어렵습니다. 현재의 3D 확산 방법은 일반적으로 2단계 훈련을 기반으로 하기 때문에 분류되지 않은 매우 다양한 3D 데이터 세트에서 흐릿하고 노이즈 제거가 어려운 잠재 공간이 발생하므로 고품질 렌더링이 시급한 과제가 됩니다.
이 문제를 해결하기 위해 일부 연구자들은 단일 단계 모델을 제안했지만 이러한 모델의 대부분은 특정 단순 범주만 대상으로 하며 일반화가 좋지 않습니다. 따라서 이 문서의 연구자들의 목표는 빠른 달성입니다. 현실적이고 다양한 3D 생성. 이를 위해 그들은 DMV3D를 제안했습니다. DMV3D는 모델 텍스트 또는 단일 이미지의 입력을 기반으로 직접 3D NeRF를 생성할 수 있는 새로운 단일 단계 전체 카테고리 확산 모델입니다. 단일 A100 GPU에서 단 30초 만에 DMV3D는 다양한 고품질 3D 이미지를 생성할 수 있습니다.
 구체적으로 DMV3D는 3D NeRF의 재구성 및 렌더링을 디노이저에 통합하고 3D 감독을 직접 수행하지 않고도 엔드 투 엔드 방식으로 학습되는 2D 다중 뷰 이미지 확산 모델입니다. 이렇게 하면 잠재 공간 확산(예: 2단계 모델)을 위한 3D NeRF 인코더를 별도로 훈련할 때 발생할 수 있는 문제와 각 객체에 대해 지루한 최적화 방법(예: SDS)을 방지할 수 있습니다.
구체적으로 DMV3D는 3D NeRF의 재구성 및 렌더링을 디노이저에 통합하고 3D 감독을 직접 수행하지 않고도 엔드 투 엔드 방식으로 학습되는 2D 다중 뷰 이미지 확산 모델입니다. 이렇게 하면 잠재 공간 확산(예: 2단계 모델)을 위한 3D NeRF 인코더를 별도로 훈련할 때 발생할 수 있는 문제와 각 객체에 대해 지루한 최적화 방법(예: SDS)을 방지할 수 있습니다.
본 문서에 있는 방법의 본질 위 2D 다시점 확산 프레임워크를 기반으로 한 3D 재구성입니다. 이 접근 방식은 단일 뷰 확산을 통한 3D 생성 방법인 RenderDiffusion 방법에서 영감을 받았습니다. 그러나 RenderDiffusion 방법의 한계는 훈련 데이터가 특정 카테고리에 대한 사전 지식이 필요하고, 데이터의 객체는 특정 각도나 포즈를 요구하므로 일반화가 좋지 않고 어떤 유형의 객체에 대해서도 3D를 생성할 수 없다는 것입니다
연구자들에 따르면 이에 비해 폐색되지 않은 3D 개체를 설명하려면 개체가 포함된 4개의 다중 뷰 희박 투영 세트만 필요합니다. 이 훈련 데이터는 인간의 공간적 상상력에서 비롯되며, 이를 통해 사람들은 여러 객체 주변의 평면 뷰에서 완전한 3D 객체를 구성할 수 있습니다. 이러한 상상은 일반적으로 매우 정확하고 구체적입니다. 그러나 이 입력을 적용할 때 희소 뷰에서 3D 재구성 작업은 여전히 해결되어야 합니다. 이는 입력에 시끄러운 경우에도 매우 어려운 문제입니다.
우리의 방법은 단일 이미지/텍스트를 기반으로 3D 생성을 달성할 수 있습니다. 이미지 입력의 경우 희소 뷰를 노이즈 없는 입력으로 수정하고 2D 이미지 인페인팅과 유사한 다른 뷰에서 노이즈 제거를 수행합니다. 텍스트 기반 3D 생성을 달성하기 위해 연구원들은 2D 확산 모델에서 일반적으로 사용되는 주의 기반 텍스트 조건과 유형 독립적 분류자를 사용했습니다.
그들은 훈련 중에 이미지 공간 감독만 사용했으며 Objaverse 합성 이미지와 MVImgNet 실제 캡처 이미지로 구성된 대규모 데이터 세트를 사용했습니다. 결과에 따르면 DMV3D는 단일 이미지 3D 재구성에서 SOTA 수준에 도달하여 이전 SDS 기반 방법과 3D 확산 모델을 능가했습니다. 게다가, 텍스트 기반의 3D 모델 생성 방식도 이전 방식보다 좋습니다. ://justimyhxu.github.io/projects/dmv3d/
생성된 3D 이미지 효과를 살펴보겠습니다.


단일 단계 3D 확산 모델을 훈련하고 추론하는 방법은 무엇입니까?
연구원들은 먼저 3D 생성을 위해 잡음이 있는 다중 뷰 이미지를 제거하기 위해 재구성 기반 노이즈 제거기를 사용하는 새로운 확산 프레임워크를 도입했습니다. 두 번째로 확산에 조건을 적용하는 LRM 기반의 새로운 A 다중 뷰 노이즈 제거기를 제안했습니다. 시간 단계를 거쳐 3D NeRF 재구성 및 렌더링을 통해 점진적으로 다중 뷰 이미지의 노이즈를 제거하고, 최종적으로 모델은 텍스트 및 이미지 조정을 지원하도록 확산되어 제어 가능성을 생성합니다.
다시 작성해야 할 내용은 다중 시점 확산 및 노이즈 제거입니다. 재작성된 콘텐츠: 다각도 확산 및 노이즈 감소
다각도 확산. 2D 확산 모델에서 처리된 원본 x_0 분포는 데이터 세트의 단일 이미지 분포입니다. 대신, 각 그룹 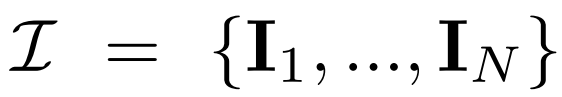 이 시점 C = {c_1, .. ., c_N}에서 동일한 3D 장면(자산)의 이미지 관찰인 다중 뷰 이미지
이 시점 C = {c_1, .. ., c_N}에서 동일한 3D 장면(자산)의 이미지 관찰인 다중 뷰 이미지  의 공동 배포를 고려합니다. 확산 프로세스는 아래 방정식(1)과 같이 동일한 노이즈 스케줄을 사용하여 각 이미지에 대해 독립적으로 확산 작업을 수행하는 것과 동일합니다.
의 공동 배포를 고려합니다. 확산 프로세스는 아래 방정식(1)과 같이 동일한 노이즈 스케줄을 사용하여 각 이미지에 대해 독립적으로 확산 작업을 수행하는 것과 동일합니다.
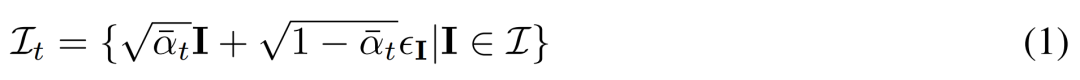
재건 기반 노이즈 제거. 2D 확산 프로세스의 반대는 본질적으로 노이즈 제거입니다. 본 논문에서 연구자들은 3D 생성을 위한 깨끗한 3D 모델을 출력하는 동시에 2D 다시점 이미지 노이즈 제거를 달성하기 위해 3D 재구성 및 렌더링을 사용할 것을 제안합니다. 구체적으로 다음과 같이 3D 재구성 모듈 E(・)를 사용하여 잡음이 있는 다중 뷰 이미지 에서 3D 표현 S를 재구성하고 미분 가능 렌더링 모듈 R(・)을 사용하여 잡음이 제거된 이미지를 렌더링합니다. 식(2)은 다음과 같습니다.
에서 3D 표현 S를 재구성하고 미분 가능 렌더링 모듈 R(・)을 사용하여 잡음이 제거된 이미지를 렌더링합니다. 식(2)은 다음과 같습니다.
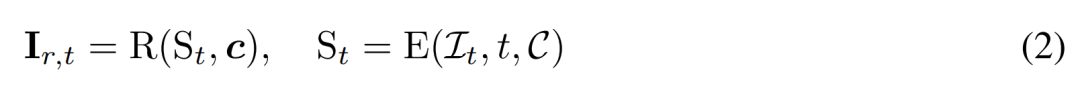
Reconstruction-based multi-view denoiser
연구원들은 LRM 기반의 다시점 디노이저를 구축하고 대형 변환기 모델을 사용하여 시끄러운 희소 뷰 포즈 이미지를 재구성했습니다. -평면 NeRF가 생성된 다음 재구성된 3평면 NeRF의 렌더링이 잡음 제거된 출력으로 사용됩니다.
재구성 및 렌더링. 아래 그림 3과 같이 연구원은 Vision Transformer(DINO)를 사용하여 입력 이미지 를 2D 토큰으로 변환한 후, 변환기를 사용하여 학습된 3면 위치 임베딩을 최종 3면에 매핑하여 자산의 모양과 모양을 3D로 표현합니다. 예측된 세 개의 평면은 다음으로 미분 가능한 볼륨 렌더링을 위해 MLP를 통해 볼륨 밀도와 색상을 디코딩하는 데 사용됩니다.
를 2D 토큰으로 변환한 후, 변환기를 사용하여 학습된 3면 위치 임베딩을 최종 3면에 매핑하여 자산의 모양과 모양을 3D로 표현합니다. 예측된 세 개의 평면은 다음으로 미분 가능한 볼륨 렌더링을 위해 MLP를 통해 볼륨 밀도와 색상을 디코딩하는 데 사용됩니다.
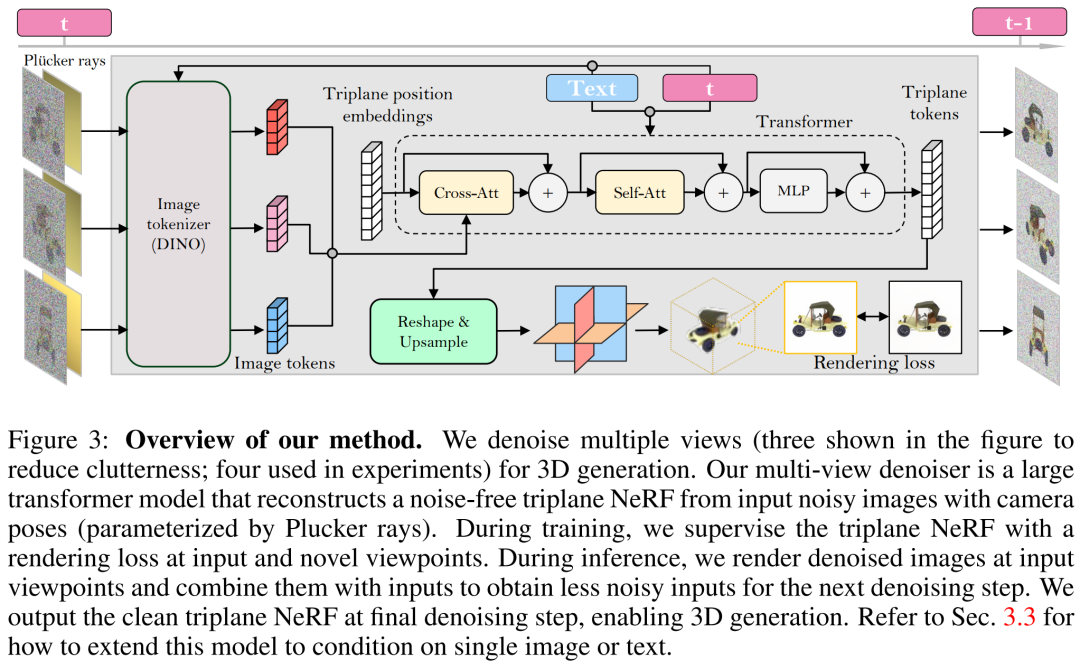
시간 조정. CNN 기반 DDPM(Denoising Diffusion Probabilistic Model)과 비교할 때, Transformer 기반 모델은 다른 시간 조정 설계가 필요합니다.
이 기사에서 모델을 훈련할 때 연구원은 매우 다양한 카메라 내부 및 외부 매개변수 데이터 세트(예: MVImgNet)에서 모델이 카메라를 이해하고 수행하는 데 도움이 되도록 입력 카메라 조정을 효과적으로 설계해야 한다고 지적했습니다. 3D 추론
내용을 다시 작성할 때 원문의 언어를 중국어로 변환해야 하지만 원문의 의미는 변하지 않습니다
위 방법을 사용하면 연구자가 제안한 모델이 무조건적인 생성 모델 역할을 할 수 있습니다. 조건부 노이즈 제거기(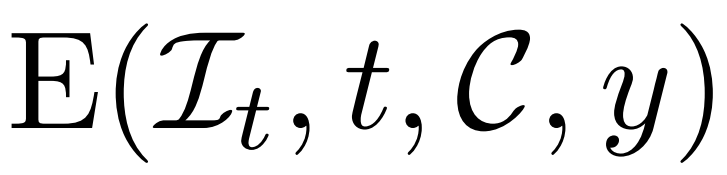 )를 활용하여 y가 텍스트나 이미지를 나타내는 조건부 확률 분포를 모델링하고 제어 가능한 3D 생성을 달성하는 방법을 설명합니다.
)를 활용하여 y가 텍스트나 이미지를 나타내는 조건부 확률 분포를 모델링하고 제어 가능한 3D 생성을 달성하는 방법을 설명합니다.
이미지 조절 측면에서 연구원들은 모델 아키텍처 수정이 필요하지 않은 간단하고 효과적인 전략을 제안했습니다.
텍스트 조절. 모델에 텍스트 조건을 추가하기 위해 연구원들은 Stable Diffusion과 유사한 전략을 채택했습니다. CLIP 텍스트 인코더를 사용하여 텍스트 임베딩을 생성하고 교차 주의를 사용하여 디노이저에 삽입합니다.
다시 작성해야 하는 콘텐츠는 훈련 및 추론
훈련입니다. 훈련 단계에서는 [1, T] 범위 내에서 시간 단계 t를 균일하게 샘플링하고 코사인 스케줄링에 따라 노이즈를 추가합니다. 그들은 무작위 카메라 포즈를 사용하여 입력 이미지를 샘플링하고 추가로 새로운 시점을 무작위로 샘플링하여 더 나은 품질을 위해 렌더링을 감독합니다.
연구원은 훈련 목표
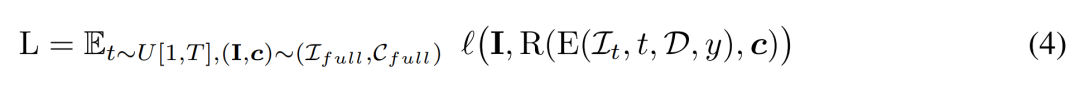
추론을 최소화하기 위해 조건부 신호 y를 사용합니다. 추론 단계에서 우리는 결과 3D 자산을 잘 포함할 수 있도록 개체를 원으로 고르게 둘러싸는 시점을 선택했습니다. 그들은 4개의 뷰에 대해 카메라 시장 각도를 50도로 고정했습니다.
실험에서 연구원들은 AdamW 최적화 프로그램을 사용하여 4e^-4의 초기 학습률로 모델을 훈련했습니다. 그들은 이 학습 속도를 위해 3K 단계의 워밍업과 코사인 감쇠를 사용했고, 노이즈 제거 모델을 훈련하기 위해 256×256 입력 이미지를 사용했으며, 감독 렌더링을 위해 128×128 잘린 이미지를 사용했습니다
필요한 데이터세트 정보 다음과 같이 재작성되었습니다. 연구원의 모델은 다중 뷰 포즈 이미지를 사용하여 훈련하면 됩니다. 따라서 그들은 Objaverse 데이터 세트에서 약 730,000개 개체의 렌더링된 다중 뷰 이미지를 사용했습니다. 각 객체에 대해 LRM 설정에 따라 고정된 50도 FOV와 균일한 조명을 사용하여 무작위 시점에서 32개의 이미지 렌더링을 수행했습니다. 연구원들은 단일 이미지 재구성 작업에서 Point-E, Shap-E, Zero-1-to-3 및 Magic123과 같은 이전 방법과 이미지 조절 모델을 비교했습니다. 그들은 PSNR, LPIPS, CLIP 유사성 점수 및 FID와 같은 측정항목을 사용하여 모든 방법의 새로운 뷰 렌더링 품질을 평가했습니다.
GSO 및 ABO 테스트 세트의 정량적 결과는 아래 표 1과 같습니다. 우리 모델은 모든 기본 방법보다 성능이 뛰어나고 두 데이터 세트의 모든 측정 항목에 대해 새로운 SOTA를 달성합니다
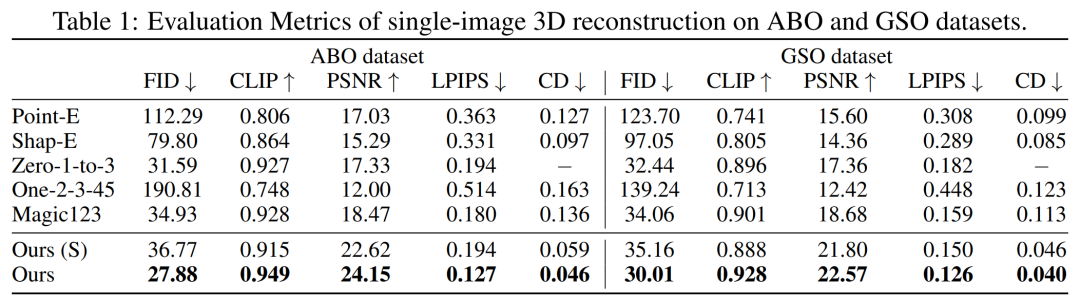 우리 모델에서 생성된 결과는 기준보다 더 나은 기하학적 및 모양 세부 정보를 갖습니다. 고품질, 이 결과는 다음을 통해 질적으로 입증될 수 있습니다. 그림 4
우리 모델에서 생성된 결과는 기준보다 더 나은 기하학적 및 모양 세부 정보를 갖습니다. 고품질, 이 결과는 다음을 통해 질적으로 입증될 수 있습니다. 그림 4
DMV3D는 2D 이미지를 훈련 대상으로 사용하는 단일 단계 모델입니다. 이에 비해 각 자산의 개별 최적화가 필요하지 않으며 다중 뷰를 제거하고 3D NeRF 모델을 직접 생성할 수 있습니다. 전반적으로 DMV3D는 3D 이미지를 빠르게 생성하고 최고의 단일 이미지 3D 재구성 결과를 얻을 수 있습니다
 다음과 같이 다시 작성했습니다. 연구원들은 또한 텍스트 기반 3D 생성 결과에 대해 DMV3D를 평가했습니다. 연구원들은 DMV3D를 모든 범주에 걸쳐 빠른 추론을 지원하는 Shap-E 및 Point-E와 비교했습니다. 연구원들은 이 세 가지 모델이 Shap-E의 50개 텍스트 프롬프트를 기반으로 생성하도록 하고 표 2
다음과 같이 다시 작성했습니다. 연구원들은 또한 텍스트 기반 3D 생성 결과에 대해 DMV3D를 평가했습니다. 연구원들은 DMV3D를 모든 범주에 걸쳐 빠른 추론을 지원하는 Shap-E 및 Point-E와 비교했습니다. 연구원들은 이 세 가지 모델이 Shap-E의 50개 텍스트 프롬프트를 기반으로 생성하도록 하고 표 2
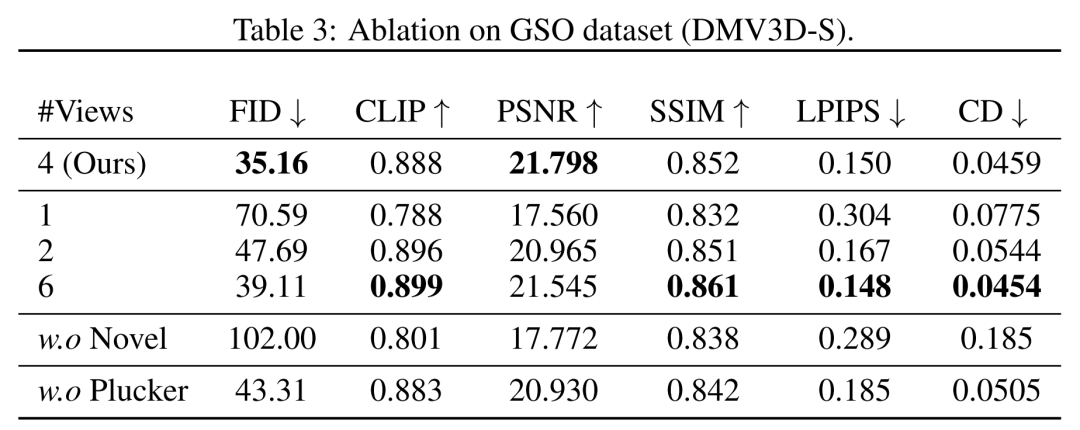
에 표시된 것처럼 두 가지 ViT 모델의 CLIP 정확도와 평균 정확도를 사용하여 생성 결과를 평가했습니다. 표의 데이터에 따르면 DMV3D가 가장 좋은 정확도를 보여줍니다. 그림 5의 정성적 결과에서 볼 수 있듯이, 다른 모델에서 생성된 결과와 비교할 때 DMV3D로 생성된 그래픽에는 분명히 더 풍부한 기하학적 및 외관 세부 정보가 포함되어 있으며 결과도 더 사실적입니다 필요 재작성 예: 기타 결과 뷰 측면에서 연구자들은 표 3과 그림 8에서 서로 다른 수의 입력 뷰(1, 2, 4, 6)로 훈련된 모델의 정량적 및 정성적 비교를 보여줍니다. 본 논문에서 제안하는 모델은 다중 인스턴스 생성 측면에서 다른 확산 모델과 유사하게 그림과 같이 무작위 입력을 기반으로 다양한 예제를 생성할 수 있다. 그림 1은 모델에 의해 생성된 결과의 일반화 가능성을 보여줍니다. DMV3D는 응용 분야에서 광범위한 유연성과 다양성을 갖추고 있으며 3D 생성 응용 분야에서 강력한 개발 잠재력을 가지고 있습니다. 그림 1과 그림 2에서 볼 수 있듯이 이 기사의 방법은 분할(예: SAM)과 같은 방법을 통해 이미지 편집 응용 프로그램에서 2D 사진의 임의 개체를 3D 차원으로 승격시킬 수 있습니다. 자세히 알아보려면 원본 논문을 읽어보세요. 많은 기술적 세부 사항 및 실험 결과



위 내용은 Adobe의 신기술: A100으로 단 30초만에 3D 이미지 생성, 텍스트와 이미지 이동의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



