

번역자가 다시 작성해야 하는 콘텐츠는 다음과 같습니다. |다시 작성해야 하는 콘텐츠는: Bugatti
리뷰어가 다시 작성해야 하는 콘텐츠는 다음과 같습니다. |필요한 콘텐츠는 다음과 같습니다. 다시 작성하는 방법은 다음과 같습니다. Chonglou
문서와 데이터에서 insights를 추출하는 것은 you정보에 입각한 결정을 내리는 데 매우 중요합니다. 그러나 민감한 정보를 다루는 경우 개인정보 문제가 발생할 수 있습니다. LangChain과 OpenAI를 함께 사용하려면 API를 다시 작성해야 합니다. 로컬 문서를 인터넷에 업로드하지 않고도 분석할 수 있습니다.
이 작업은 데이터를 로컬에 유지하고, 분석을 위해 임베딩 및 벡터화를 사용하고, 환경에서 프로세스를 실행하여 이를 수행합니다. OpenAI는 모델 교육이나 서비스 개선을 위해 고객이 API를 통해 제출한 데이터를 사용하지 않습니다. Build
Environment가상 환경을 만듭니다. 이렇게 하면 라이브러리 버전 충돌이 발생하지 않습니다. 그런 다음 다음 터미널 명령을 실행하여 필요한 라이브러리를 설치하십시오. 각 라이브러리를 pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
로그인 후 복사
:
LangChainGet OpenAI 다시 작성해야 할 것은: API 키
Key를 추가하세요. 이 키를 사용하면 API제공자가 해당 요청이 합법적인 소스에서 왔는지, 사용자가 해당 기능에 액세스하는 데 필요한 권한을 가지고 있는지 확인할 수 있습니다. OpenAI를 얻기 위해 다시 작성해야 하는 것은 API 키, OpenAI 플랫폼을 입력하는 것입니다. 그런 다음 오른쪽 상단의 계정
"
APIKey"을 클릭하면 이 나타납니다. API비밀 핵심 페이지. "새 키 만들기" 버튼을 클릭하세요. 키 이름을
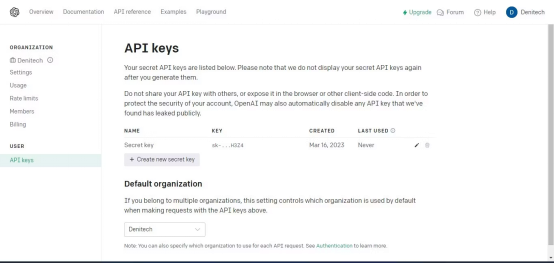
Create New Key"을 클릭하세요. OpenAI는 API키를 생성하며, 이 키를 복사하여 안전한 곳에 보관해야 합니다. 보안상의 이유로 OpenAI 계정을 통해 다시 볼 수 없습니다. 키를 분실한 경우 새 키를 생성해야 합니다. 为了能够使用安装在虚拟环境中的库,您需要导入它们。 注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。 先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。 如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。 接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。 加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。 需要改写的内容是: 分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。 您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。 该函数使用创建的QA实例来运行查询并输出结果。 主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。 接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。 嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。 这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。 最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:"__main__"构造函数来调用主函数: 这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。 要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。 以下截图展示了对PDF进行分析的结果 아래 출력은 소스 코드와 가 포함된 텍스트 파일을 분석한 결과를 보여줍니다. 분석하려는 파일이 PDF 또는 텍스트 형식인지 확인하세요. 문서 가 다른 형식 인 경우 온라인 도구를 사용하여 해당 문서를 PDF 형식 으로 변환할 수 있습니다. 전체 소스 코드는 GitHub 코드 저장소에서 확인할 수 있습니다: https://github.com/makeuseofcode/Document-analytics-using-LangChain-and-OpenAI 원제: How need to 다시 작성해야 할 내용은 다음과 같습니다. to 다시 작성해야 할 내용은 다음과 같습니다. 분석 다시 작성해야 할 내용은 다음과 같습니다. 문서 다시 작성해야 할 내용은 다음과 같습니다. With 다시 작성해야 할 내용은 다음과 같습니다. : LangChain 다시 작성해야 하는 콘텐츠는 다음과 같습니다. 다시 작성해야 하는 콘텐츠는 다음과 같습니다. 다시 작성해야 하는 콘텐츠는 다음과 같습니다. the 콘텐츠는: OpenAI 다시 작성해야 하는 콘텐츠는: API , 작성자: Denis 다시 작성해야 하는 콘텐츠는 다음과 같습니다. Kuria 다시 작성해야 하는 콘텐츠는 다음과 같습니다.
导入所需的库
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
로그인 후 복사
加载用于分析的文档
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
로그인 후 복사def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")로그인 후 복사text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="\n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
로그인 후 복사
查询文档
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
로그인 후 복사
创建主函数
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):\n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")로그인 후 복사if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
로그인 후 복사
执行文件分析
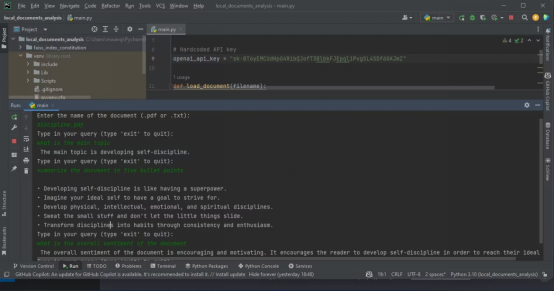
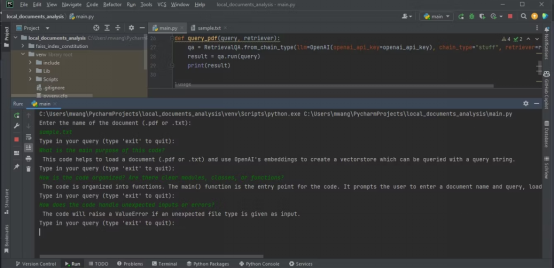
위 내용은 문서 분석을 위해 LangChain 및 OpenAI API를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



