

인공지능의 발전은 빠르게 진행되고 있지만 문제가 자주 발생합니다. OpenAI의 새로운 GPT 비전 API는 프런트엔드 측면에서 놀랍지만 환각 문제로 인해 백엔드 측면에서도 불평하기 어렵습니다.
환상은 항상 대형 모델의 치명적인 결점이었습니다. 데이터 세트의 복잡성으로 인해 오래되고 잘못된 정보가 존재하게 되어 출력 품질이 심각한 문제에 직면하게 되는 것은 불가피합니다. 정보가 너무 많이 반복되면 대형 모델에 편향이 생길 수 있으며, 이는 일종의 착각이기도 합니다. 그러나 환각은 대답할 수 없는 제안이 아닙니다. 개발 과정에서 데이터 세트의 신중한 사용, 엄격한 필터링, 고품질 데이터 세트 구축, 모델 구조 및 훈련 방법의 최적화를 통해 환각 문제를 어느 정도 완화할 수 있습니다.
대형모델이 너무 많은데 환각 완화에 얼마나 효과가 있나요? 차이점을 명확하게 비교한 순위는 다음과 같습니다
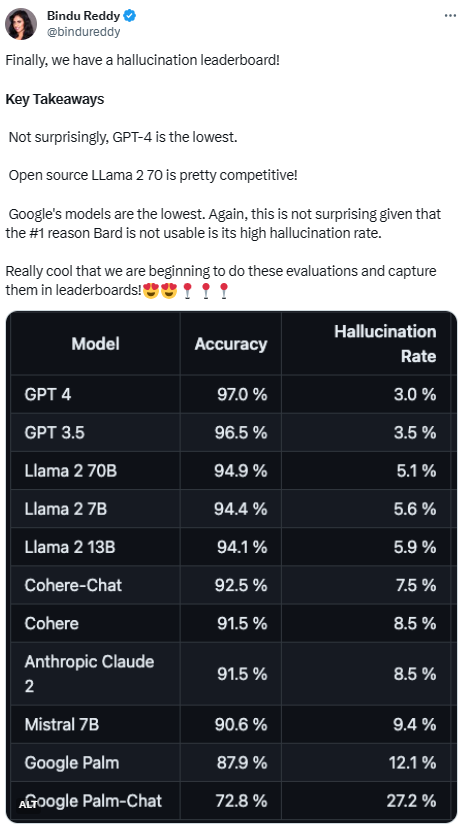
Vectara 플랫폼은 인공 지능에 초점을 맞춘 이 순위를 발표했습니다. 순위 업데이트 날짜는 2023년 11월 1일입니다. Vectara는 모델이 업데이트됨에 따라 순위를 업데이트하기 위해 환각 평가에 대한 후속 조치를 계속할 것이라고 밝혔습니다
프로젝트 주소: https://github.com /vectara /hallucination-leaderboard
이 리더보드를 결정하기 위해 Vectara는 사실적 일관성 연구를 수행하고 LLM 출력에서 환각을 감지하는 모델을 교육했습니다. 그들은 유사한 SOTA 모델을 사용하고 공개 API를 통해 각 LLM에 1,000개의 짧은 문서를 제공하고 문서에 제시된 사실만을 사용하여 각 문서를 요약하도록 요청했습니다. 이 1000개의 문서 중 각 모델별로 요약된 문서는 831개에 불과하며, 나머지 문서는 내용 제한으로 인해 하나 이상의 모델에서 거부되었습니다. Vectara는 이러한 831개의 문서를 사용하여 각 모델의 전반적인 정확도와 착시율을 계산했습니다. 각 모델이 프롬프트에 응답하지 않는 비율은 "응답률" 열에 자세히 나와 있습니다. 모델로 전송된 콘텐츠에는 불법이거나 안전하지 않은 콘텐츠가 포함되어 있지 않지만 특정 콘텐츠 필터를 트리거할 만큼 충분한 트리거 단어가 포함되어 있습니다. 이 문서는 주로 CNN/Daily Mail 자료
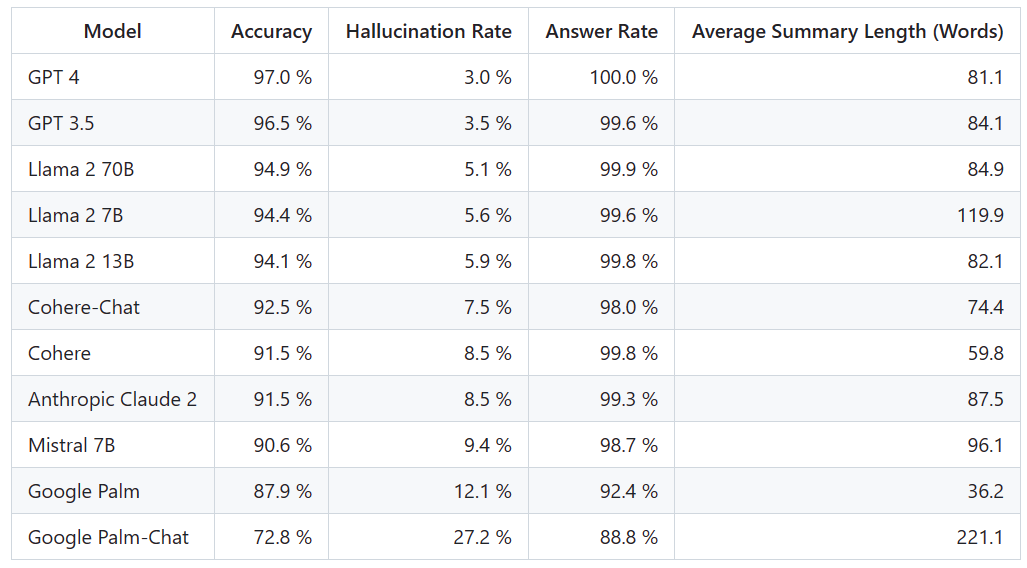
Vectara가 전반적인 사실의 정확성이 아닌 요약의 정확성을 평가한다는 점에 유의하는 것이 중요합니다. 이를 통해 제공된 정보에 대한 모델의 응답을 비교할 수 있습니다. 즉, 평가되는 것은 출력 요약이 원본 문서와 "사실상 일치"하는지 여부입니다. 각 LLM이 어떤 데이터에 대해 교육을 받았는지 알지 못하면 특정 문제에 대해 환각을 판단하는 것이 불가능합니다. 또한 참조 소스 없이 응답이 환각인지 여부를 결정할 수 있는 모델을 구축하려면 환각 문제를 해결해야 하며 평가되는 LLM보다 크거나 큰 모델을 훈련해야 합니다. 따라서 Vectara는 요약 작업에서 환각 비율을 살펴보기로 결정했습니다. 왜냐하면 그러한 비유가 모델의 전반적인 현실성을 결정하는 좋은 방법이기 때문입니다.
환각 모델의 탐지 주소는 다음과 같습니다: https://huggingface.co/vectara/hallucination_evaluation_model
또한 사용자 쿼리에 응답하기 위해 RAG(Retrieval Augmented Generation) 파이프라인에서 점점 더 많은 LLM이 사용됩니다. Bing Chat 및 Google Chat 통합과 같은. RAG 시스템에서 모델은 검색 결과 수집기로 배포되므로 이 리더보드는 RAG 시스템에서 사용될 때 모델의 정확성을 나타내는 좋은 지표이기도 합니다
GPT-4가 얼마나 잘 해왔는지를 고려하면, 그 환상 최저 금리는 놀라운 일이 아닌 것 같습니다. 하지만 일부 네티즌들은 GPT-3.5와 GPT-4의 차이가 별로 없어서 놀랐다고 합니다

LLaMA 2는 GPT-4와 GPT-3.5를 따라잡은 뒤 좋은 성적을 냈습니다. 하지만 구글의 대형 모델 성능은 만족스럽지 못했다. 일부 네티즌들은 구글의 BARD가 오답을 피하기 위해 '아직 훈련 중'이라는 표현을 자주 사용한다고 말했다. . 며칠 전
OpenAI가 GPT-4 Turbo
를 출시했습니다. 아니요, 일부 네티즌은 즉시 순위 업데이트를 제안했습니다.

다음 순위는 어떻게 될지, 큰 변화가 있을지 지켜보겠습니다.
위 내용은 대형모델 환각률 순위 : GPT-4가 3%로 가장 낮고, 구글팜이 27.2%로 높다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



