

제너레이티브 AI 첫 해에는 모든 사람의 작업 속도가 훨씬 빨라졌습니다.
특히 올해는 모두가 대형 모델 출시에 힘쓰고 있습니다. 최근에는 국내외 기술 대기업과 스타트업들이 차례대로 대형 모델을 출시하는데요, 기자간담회가 시작되자마자 모두들 떴습니다. 주요 혁신을 이루었으며 각 회사는 1위 또는 1위 순위의 중요한 모델을 새로 고쳤습니다.
많은 사람들은 기술의 급속한 발전에 열광한 후 뭔가 잘못된 것 같다는 것을 발견합니다. 왜 모두가 1위 순위에 공유되는 걸까요? 이 메커니즘은 무엇입니까?
이때부터 '목록 스와핑' 문제도 주목받기 시작했습니다.
최근 WeChat Moments와 Zhihu 커뮤니티에서 대형 모델의 '순위 스와핑' 문제에 대한 논의가 점점 더 많아지고 있는 것을 확인했습니다. 특히 Zhihu에 대한 게시물: Tiangong Large Model Technical Report에서 많은 대형 모델이 순위를 높이기 위해 현장 데이터를 사용한다고 지적한 현상을 어떻게 평가하십니까? 그것은 모든 사람의 토론을 불러일으켰습니다.
링크: https://www.zhihu.com/question/628957425
이 연구는 Kunlun Wanwei의 "Tiangong" 대학에서 수행되었습니다. 모델 연구팀은 지난달 말 사전 인쇄 용지 플랫폼 arXiv에 대한 기술 보고서를 발표했습니다.

문서 링크: https://arxiv.org/abs/2310.19341
문서 자체는 Tiangong의 LLM(대형 언어 모델) 시리즈인 Skywork-13B에 대한 소개입니다. 저자는 분할된 말뭉치를 활용하여 각각 일반 훈련과 도메인별 강화 훈련을 목표로 하는 2단계 훈련 방법을 소개합니다.
대형 모델에 대한 새로운 연구와 마찬가지로 저자는 인기 있는 테스트 벤치마크에서 해당 모델이 좋은 성능을 발휘했을 뿐만 아니라 많은 중국 지점 작업에서 최첨단 수준(업계 최고)을 달성했다고 밝혔습니다. . 좋은).
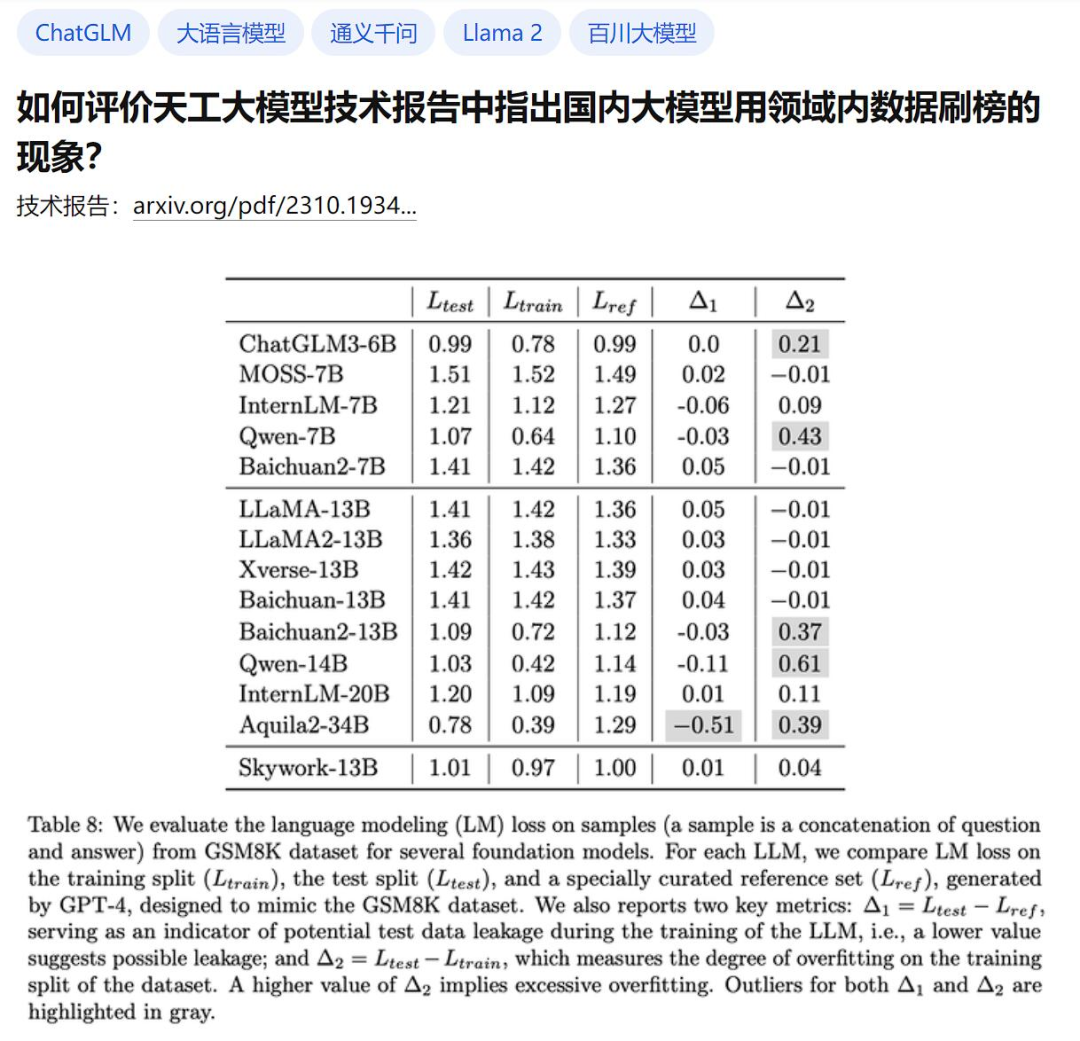
보고서에서 다수의 대형 모델의 실제 효과도 검증했으며, 일부 국내 대형 모델이 기회주의적 성향을 갖고 있다는 의혹을 제기했다는 점이 핵심이다. 표 8은 다음과 같습니다.
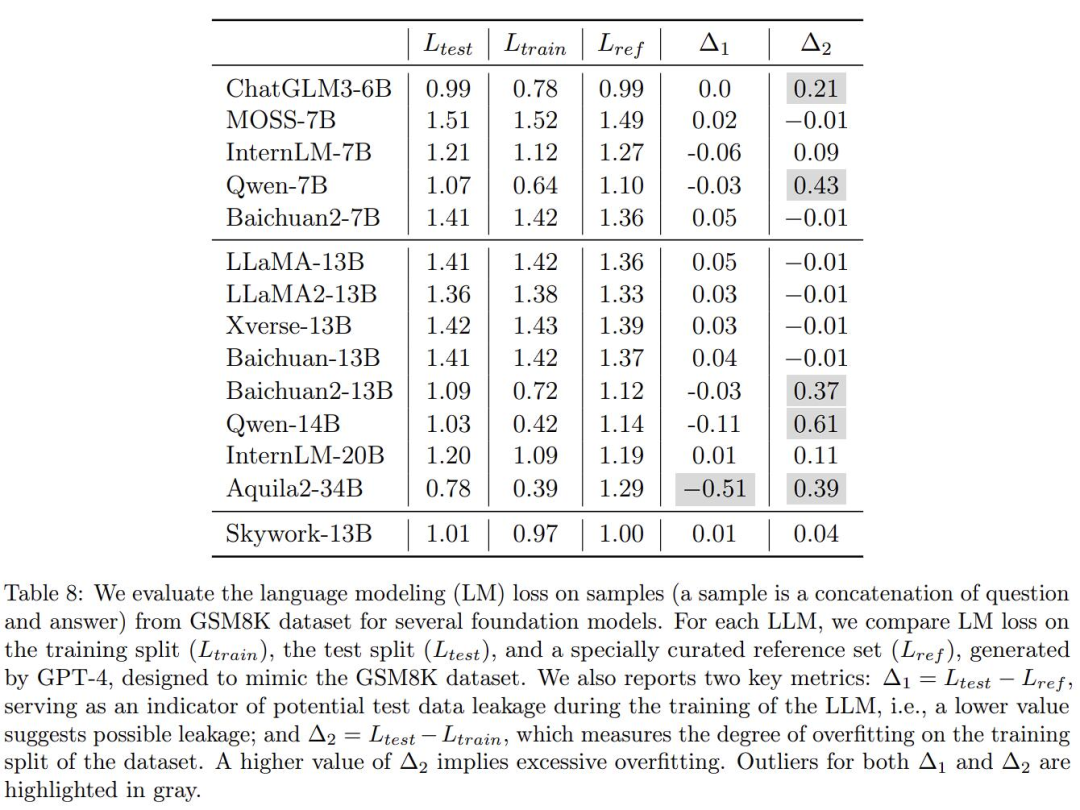
여기서 저자는 수학 응용 문제 벤치마크 GSM8K에서 업계의 여러 일반적인 대형 모델의 과적합 정도를 확인하기 위해 GPT-4를 사용하여 일부 GSM8K 샘플을 생성했습니다. 동일한 형태의 모델을 수동으로 정확성을 확인하고 생성된 데이터 세트에서 GSM8K의 원래 훈련 세트 및 테스트 세트와 비교하여 손실을 계산했습니다. 그런 다음 두 가지 측정항목이 있습니다.
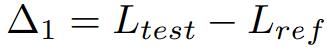
Δ1은 모델 교육 중 잠재적인 테스트 데이터 누출을 나타내는 지표로 사용되며, 값이 낮을수록 누출 가능성이 있음을 나타냅니다. 테스트 세트를 훈련하지 않으면 값은 0이 되어야 합니다.
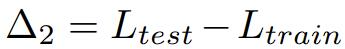
Δ2는 데이터세트 훈련 분할의 과적합 정도를 측정합니다. Δ2 값이 높을수록 과적합을 의미합니다. 훈련 세트에 대해 훈련되지 않은 경우 값은 0이어야 합니다.
간단히 설명하자면, 모델이 벤치마크 테스트의 '실제 질문'과 '답안'을 학습 중 학습 자료로 직접 사용하고 이를 점수 획득에 사용하려는 경우 여기서는 비정상이 됩니다.
좋아요, Δ1과 Δ2의 문제가 있는 부분은 위에서 회색으로 신중하게 강조 표시되어 있습니다.
네티즌들은 마침내 누군가 '데이터 세트 오염'의 공개 비밀을 알려줬다는 댓글을 남겼습니다.
일부 네티즌들은 대형 모델의 지능 수준은 여전히 기존 테스트 벤치마크로는 달성할 수 없는 제로샷 성능에 달려 있다고 말했습니다.

사진: 지후 네티즌 댓글 스크린샷
작가와 독자의 대화에서 저자는 "모든 사람이 부정행위 문제를 좀 더 이성적으로 바라볼 수 있기를 바란다. 아직 많은 모델과 GPT4 사이에는 큰 격차가 있다"고 말했다.
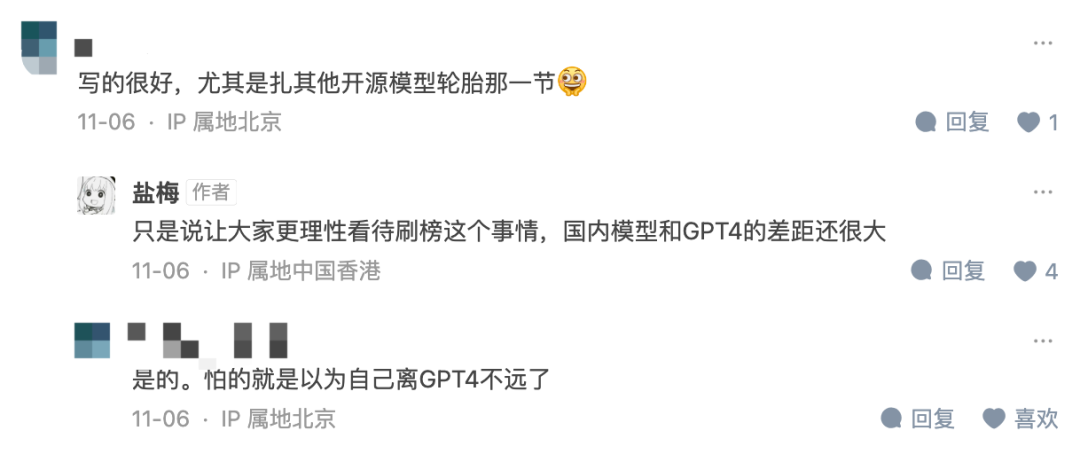
사진: Zhizhihu 기사 스크린샷 https://zhuanlan.zhihu.com/p/664985891
사실 이는 일시적인 현상이 아닙니다. . 벤치마크가 도입된 이후, 올해 9월 arXiv에 실린 매우 아이러니한 기사 제목에서 "테스트 세트에 대한 사전 훈련이 필요한 전부"라고 지적했듯이 이러한 문제가 때때로 발생했습니다.

또한 Renmin University와 Illinois University of Urbana-Champaign의 최근 공식 연구에서도 대형 모델 평가의 문제점이 지적되었습니다. 제목은 매우 눈길을 끕니다. "당신의 LLM을 평가 벤치마크 사기꾼으로 만들지 마십시오":

논문 링크: https://arxiv.org/abs/2311.01964
논문은 다음을 지적합니다. 현재 대형 모델의 핫 분야는 벤치마크 순위에 관심이 많지만 그 공정성과 신뢰성에 의문이 제기되는 부분이다. 가장 큰 문제는 데이터 오염 및 유출인데, 이는 사전 학습 코퍼스를 준비할 때 향후 평가 데이터 세트를 알 수 없기 때문에 의도하지 않게 발생할 수 있습니다. 예를 들어, GPT-3는 사전 훈련 코퍼스에 Children's Book Test 데이터 세트가 포함되어 있음을 발견했으며 LLaMA-2 논문에서는 BoolQ 데이터 세트에서 상황에 맞는 웹 페이지 콘텐츠를 추출하는 것에 대해 언급했습니다.
데이터 세트를 수집하고 정리하고 라벨을 지정하려면 많은 사람의 노력이 필요합니다. 고품질 데이터 세트가 평가에 사용할 만큼 좋다면 자연스럽게 다른 사람들이 대형 모델을 훈련하는 데 사용할 수도 있습니다.
한편, 기존 벤치마크를 사용하여 평가할 때 우리가 평가한 대형 모델의 결과는 대부분 로컬 서버에서 실행하거나 API 호출을 통해 얻은 결과였습니다. 이 과정에서 평가 성과를 비정상적으로 향상시킬 수 있는 부적절한 수단(예: 데이터 오염)이 엄격하게 검토되지 않았습니다.
더 나쁜 것은 학습 코퍼스(예: 데이터 소스)의 세부 구성이 기존 대형 모델의 핵심 "비밀"로 간주되는 경우가 많다는 것입니다. 이는 데이터 오염 문제를 탐구하는 것을 더욱 어렵게 만듭니다.
즉, 우수한 데이터의 양은 제한되어 있으며 많은 테스트 세트에서 GPT-4 및 Llama-2가 반드시 문제가 되지는 않습니다. 예를 들어 GSM8K는 첫 번째 논문에서 언급되었고 GPT-4는 공식 기술 보고서에서 훈련 세트를 사용하는 것을 언급했습니다.
데이터가 매우 중요하다고 하지 않나요? 그러면 "실제 질문"을 사용하여 점수를 매기는 대규모 모델의 성능은 훈련 데이터가 더 좋기 때문에 더 좋아질까요? 대답은 부정적이다.
연구원들은 벤치마크 누출로 인해 대규모 모델이 과장된 결과를 실행하게 된다는 사실을 실험적으로 발견했습니다. 예를 들어, 1.3B 모델은 일부 작업에서 크기가 10배 더 큰 모델을 능가할 수 있습니다. 그러나 부작용은 유출된 데이터를 모델을 미세 조정하거나 훈련하는 데만 사용할 경우 다른 일반적인 테스트 작업에서 이러한 대규모 테스트 전용 모델의 성능에 부정적인 영향을 미칠 수 있다는 것입니다.
따라서 저자는 앞으로 연구자들이 대형 모델을 평가하거나 신기술을 연구할 때 다음을 수행해야 한다고 제안합니다.
드디어 이 문제가 기술 보고서든, 논문 조사든, 커뮤니티 토론이든 모두가 대형 모델의 '랭킹 스와핑' 문제에 관심을 갖기 시작했습니다.
이에 대한 귀하의 의견과 효과적인 제안은 무엇입니까?
위 내용은 대형 모델이 '순위를 깨기' 위해 지름길을 택하고 있습니까? 데이터 오염 문제는 주목할 만하다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



