

Transformer는 "훈련 데이터" 이상의 새로운 문제를 해결할 수 없는 운명인가요?
대규모 언어 모델이 보여주는 인상적인 기능 중 하나는 상황에 맞는 샘플을 제공하고 제공된 최종 입력을 기반으로 모델에 응답을 생성하도록 요청하여 퓨샷 학습을 달성하는 기능입니다. 이는 기본 기계 학습 기술인 "Transformer 모델"에 의존하며, 언어 이외의 영역에서도 상황에 맞는 학습 작업을 수행할 수도 있습니다.
과거 경험에 따르면 사전 훈련된 혼합으로 잘 표현되는 작업군이나 기능 클래스의 경우 상황별 학습에 적합한 기능 클래스를 선택하는 데 비용이 거의 들지 않는다는 것이 입증되었습니다. 따라서 일부 연구자들은 Transformer가 훈련 데이터와 동일한 분포로 분포된 작업이나 기능에 대해 잘 일반화할 수 있다고 믿습니다. 그러나 일반적이지만 해결되지 않은 질문은 다음과 같습니다. 이러한 모델은 훈련 데이터 분포와 일치하지 않는 샘플에서 어떻게 작동합니까?
최근 연구에서 DeepMind의 연구원들은 실증적 연구의 도움을 받아 이 문제를 탐구했습니다. 그들은 일반화 문제를 다음과 같이 설명합니다. "모델이 기본에 속하지 않는 함수에서 사전 훈련된 데이터를 혼합하여 기본 함수 클래스에 속하지 않는 함수를 사용하여 상황 내 예제로 좋은 예측을 생성할 수 있습니까?" 사전 훈련 데이터 혼합에서 볼 수 있는 함수 클래스? )》
이 콘텐츠의 초점은 사전 훈련 과정에서 사용된 데이터가 결과 Transformer 모델의 퓨샷 학습 능력에 미치는 영향을 탐색하는 것입니다. 이 문제를 해결하기 위해 연구자들은 먼저 사전 훈련 과정에서 모델 선택을 위해 다양한 기능 계열을 선택하는 Transformer의 능력을 연구한 후(섹션 3) 여러 주요 사례의 OOD 일반화 문제에 답했습니다(섹션 4)

논문 링크: https://arxiv.org/pdf/2311.00871.pdf
다음은 연구에서 발견되었습니다. 첫째, 사전 훈련된 Transformer는 사전 훈련된 함수 클래스에서 추출된 함수를 예측하는 데 성능이 좋지 않습니다. 둘째, Transformer는 함수 클래스 공간의 희귀한 부분을 효과적으로 일반화할 수 있지만 작업이 분포 범위를 초과하면 여전히 오류가 발생합니다
Transformer는 사전 훈련 데이터 인식 이상으로 일반화할 수 없습니다. 인식 이상의 문제를 해결할 수 없습니다

일반적으로 이 기사의 기여는 다음과 같습니다.
컨텍스트 학습을 수행하고 설명하기 위해 다양한 함수 클래스를 혼합하여 Transformer 모델을 사전 훈련합니다. 모델 선택 동작의 특성
사전 훈련 데이터의 함수 클래스와 "일관되지 않는" 함수의 경우 컨텍스트 학습에서 사전 훈련된 Transformer 모델의 동작을 연구합니다.
Strong Strong 모델이 약간의 추가 통계 비용으로 상황 학습 중에 사전 훈련된 함수 클래스 중에서 모델 선택을 수행할 수 있다는 증거가 있지만 모델이 사전 훈련을 넘어 상황 학습 동작을 수행할 수 있다는 증거도 제한적입니다.
이 연구원은 이것이 보안에 좋은 소식일 수 있다고 믿습니다. 적어도 모델은 원하는 대로 작동하지 않을 것입니다

그러나 일부 사람들은 이 논문에서 사용된 모델이 적합하지 않다고 지적했습니다 ——"GPT -2 규모'는 이 기사의 모델이 약 15억 개의 매개변수로 구성되어 있다는 것을 의미하며 이는 실제로 일반화하기 어렵습니다. 

다음으로 논문의 내용을 살펴보겠습니다.
모델 선택 현상
다양한 함수 클래스의 데이터 혼합을 사전 학습할 때 문제에 직면하게 됩니다. 모델이 사전 학습 혼합에서 지원하는 컨텍스트 샘플을 만날 때 다양한 함수 클래스 중에서 선택하는 방법을 선택해야 합니다. ?
연구에 따르면 모델은 사전 훈련 데이터의 함수 클래스와 관련된 상황별 샘플에 노출될 때 최상의(또는 최고에 가까운) 예측을 할 수 있는 것으로 나타났습니다. 또한 연구원들은 단일 구성요소 함수 클래스에 속하지 않는 함수에 대한 모델 성능을 살펴보고 섹션 4에서 사전 훈련 데이터와 전혀 관련이 없는 함수에 대해 논의했습니다.
우선 선형 함수에 대한 연구부터 시작하겠습니다. 선형 함수가 상황 학습 분야에서 폭넓은 관심을 끌고 있음을 알 수 있습니다. 작년에 스탠포드 대학의 Percy Liang과 다른 사람들은 "Transformers Learn in Context?"라는 논문을 발표했습니다. 간단한 함수 클래스에 대한 사례 연구에서는 사전 훈련된 변환기가 새로운 선형 함수 컨텍스트를 학습하는 데 매우 잘 수행되어 거의 최적 수준에 도달했음을 보여주었습니다.
그들은 특히 두 가지 모델을 고려했습니다. 하나는 조밀한 선형 함수(학습된 선형 A 모델)입니다. 희소 선형 함수(모델의 모든 계수가 0이 아님)와 다른 하나는 희소 선형 함수(20개의 계수 중 2개만 0이 아님)에 대해 훈련된 모델입니다. 각 모델은 각각 새로운 조밀 선형 함수 및 희소 선형 함수에 대한 선형 회귀 및 Lasso 회귀와 비슷하게 수행되었습니다. 또한 연구원들은 이 두 모델을 희소 선형 함수와 조밀 선형 함수의 혼합에 대해 사전 훈련된 모델과 비교했습니다.
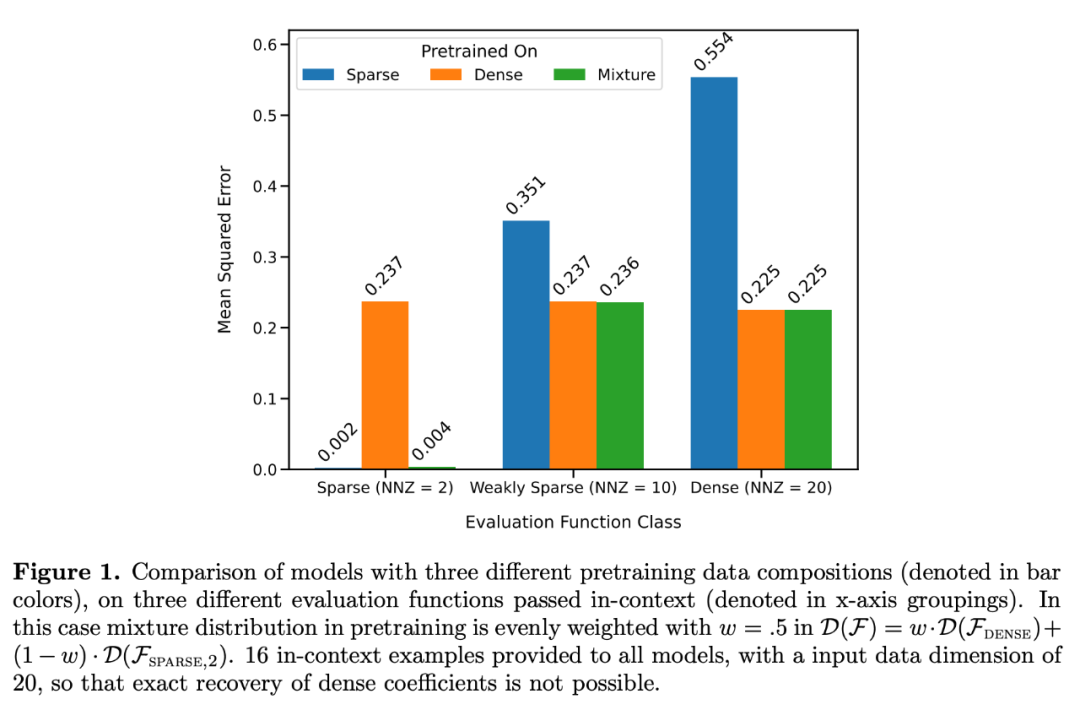
그림 1에 표시된 것처럼 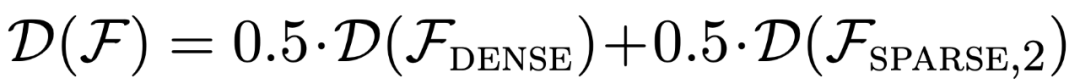 혼합에 대한 컨텍스트 학습에서 모델의 성능은 하나의 함수 클래스에서만 사전 학습된 모델과 유사합니다. 하이브리드 사전 훈련 모델의 성능은 Garg et al.[4]의 이론적 최적 모델과 유사하므로 연구자들은 모델도 최적에 가깝다고 추론합니다. 그림 2의 ICL 학습 곡선은 이 컨텍스트 모델 선택 능력이 제공된 컨텍스트 예제의 수와 상대적으로 일치함을 보여줍니다. 또한 그림 2에서는 특정 함수 클래스에 대해 다양한 중요 가중치
혼합에 대한 컨텍스트 학습에서 모델의 성능은 하나의 함수 클래스에서만 사전 학습된 모델과 유사합니다. 하이브리드 사전 훈련 모델의 성능은 Garg et al.[4]의 이론적 최적 모델과 유사하므로 연구자들은 모델도 최적에 가깝다고 추론합니다. 그림 2의 ICL 학습 곡선은 이 컨텍스트 모델 선택 능력이 제공된 컨텍스트 예제의 수와 상대적으로 일치함을 보여줍니다. 또한 그림 2에서는 특정 함수 클래스에 대해 다양한 중요 가중치 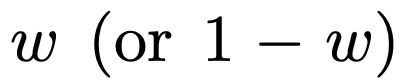 가 사용되는 것을 볼 수 있습니다.
가 사용되는 것을 볼 수 있습니다.
ICL 학습 곡선은 최고의 기준 샘플 복잡성과 거의 동일합니다. 그림 1의 ICL 학습 곡선의 지점과 일치하여 ICL 샘플 수가 증가함에 따라 편차는 작고 급격히 감소합니다. 그림 2는 Transformer 모델의 ICL 일반화가 분포 외 효과의 영향을 받는 것을 보여줍니다. 조밀한 선형 클래스와 희소 선형 클래스는 모두 선형 함수이지만 그림 2a의 빨간색 곡선(희소 선형 함수에 대해서만 사전 훈련되고 조밀한 선형 데이터에 대해 평가되는 변환기에 해당)의 성능이 좋지 않음을 알 수 있습니다. , 반대로 그림 2b의 갈색 곡선의 성능도 좋지 않습니다. 연구자들은 다른 비선형 함수 클래스에서도 유사한 동작을 관찰했습니다.
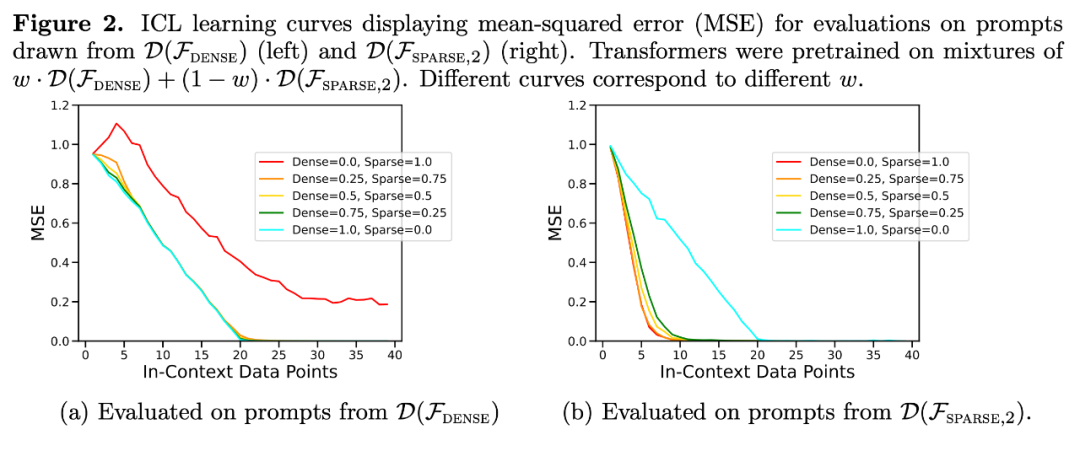 그림 1의 실험으로 돌아가서 전체 가능한 범위에 걸쳐 0이 아닌 계수 수의 함수로 오류를 플로팅하면 결과는 다음과 같습니다. = . 5의 혼합물에 대해 사전 조건화된 모델,
그림 1의 실험으로 돌아가서 전체 가능한 범위에 걸쳐 0이 아닌 계수 수의 함수로 오류를 플로팅하면 결과는 다음과 같습니다. = . 5의 혼합물에 대해 사전 조건화된 모델,
 실제로 그림 3b는 컨텍스트에 제공된 샘플이 매우 희소하거나 매우 조밀한 함수에서 나온 경우 예측이 희소 데이터 또는 조밀한 데이터만 사용하여 사전 훈련된 모델의 예측과 거의 동일하다는 것을 보여줍니다. 그러나 그 사이에서 0이 아닌 계수의 개수가 4개일 때 하이브리드 예측은 순전히 조밀하거나 순전히 희소한 사전 훈련된 Transformer의 예측과 다릅니다.
실제로 그림 3b는 컨텍스트에 제공된 샘플이 매우 희소하거나 매우 조밀한 함수에서 나온 경우 예측이 희소 데이터 또는 조밀한 데이터만 사용하여 사전 훈련된 모델의 예측과 거의 동일하다는 것을 보여줍니다. 그러나 그 사이에서 0이 아닌 계수의 개수가 4개일 때 하이브리드 예측은 순전히 조밀하거나 순전히 희소한 사전 훈련된 Transformer의 예측과 다릅니다.
이는 혼합물에 대해 사전 훈련된 모델이 단순히 예측할 단일 함수 클래스를 선택하는 것이 아니라 그 사이의 결과를 예측한다는 것을 보여줍니다.
모델 선택 능력의 한계다음으로 연구진은 모델의 ICL 일반화 능력을 두 가지 관점에서 조사했습니다. 첫째, 모델이 훈련 중에 노출되지 않은 기능의 ICL 성능을 테스트하고, 두 번째로 사전 훈련 중에 모델이 노출된 기능의 극단적인 버전의 ICL 성능을 평가합니다. 분포 외 일반화에 대한 증거는 거의 발견되지 않았습니다. 함수가 사전 훈련 중에 나타난 함수와 크게 다르면 예측이 불안정해집니다. 함수가 사전 훈련 데이터에 충분히 가까우면 모델이 잘 근사될 수 있습니다
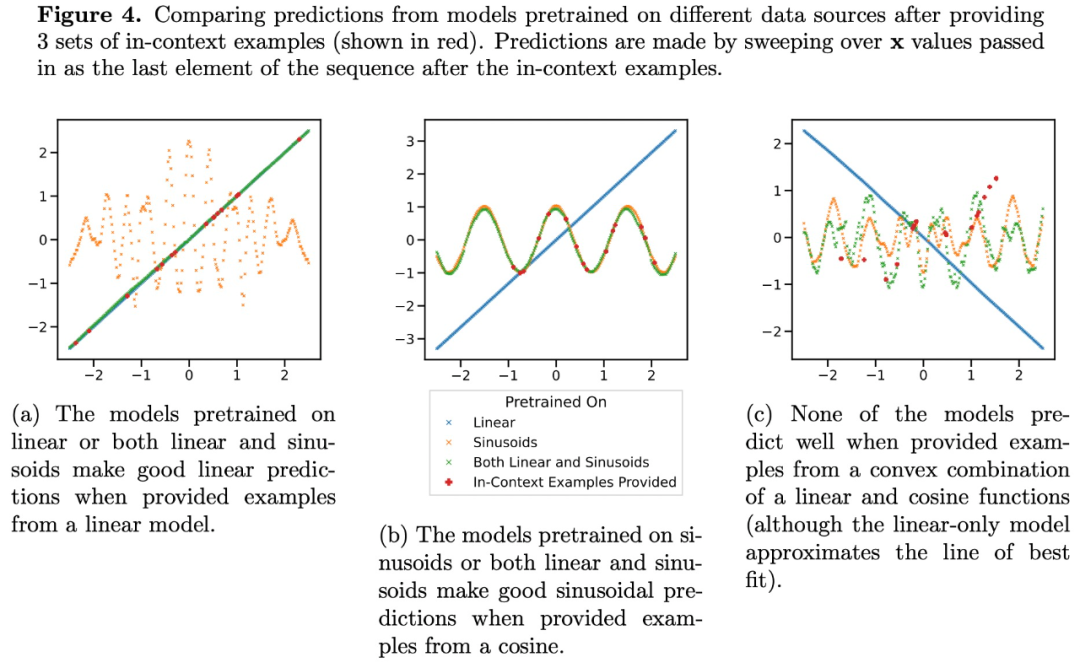
중간 희소성 수준(nnz = 3 ~ 7)에서 Transformer의 예측은 사전 훈련에서 제공되는 함수 클래스의 예측과 유사하지 않지만 그림 3a에 표시된 것처럼 그 사이 어딘가에 있습니다. 따라서 모델에는 사전 훈련된 함수 클래스를 간단하지 않은 방식으로 결합할 수 있는 일종의 귀납적 편향이 있다고 추론할 수 있습니다. 예를 들어, 모델이 사전 학습 중에 표시되는 기능 조합을 기반으로 예측을 생성할 수 있다고 의심할 수 있습니다. 이 가설을 테스트하기 위해 선형 함수, 정현파 및 두 가지의 볼록한 조합에 대해 ICL을 수행하는 기능을 조사했습니다. 그들은 비선형 함수 클래스를 더 쉽게 평가하고 시각화할 수 있도록 1차원 사례에 중점을 둡니다.
그림 4는 선형 함수와 정현파의 혼합(예:  )에 대해 사전 훈련된 모델이 두 가지를 개별적으로 예측할 수 있음을 보여줍니다. 함수 중 하나가 좋은 예측을 하지만 둘 다의 볼록 결합 함수에 적합할 수 없습니다. 이는 그림 3b에 표시된 선형 함수 보간 현상이 Transformer 상황별 학습의 일반화 가능한 귀납적 편향이 아님을 시사합니다. 그러나 컨텍스트 샘플이 사전 훈련에서 학습된 함수 클래스에 가까울 때 모델이 예측을 위해 가장 적합한 함수 클래스를 선택할 수 있다는 더 좁은 가정을 계속해서 지원합니다.
)에 대해 사전 훈련된 모델이 두 가지를 개별적으로 예측할 수 있음을 보여줍니다. 함수 중 하나가 좋은 예측을 하지만 둘 다의 볼록 결합 함수에 적합할 수 없습니다. 이는 그림 3b에 표시된 선형 함수 보간 현상이 Transformer 상황별 학습의 일반화 가능한 귀납적 편향이 아님을 시사합니다. 그러나 컨텍스트 샘플이 사전 훈련에서 학습된 함수 클래스에 가까울 때 모델이 예측을 위해 가장 적합한 함수 클래스를 선택할 수 있다는 더 좁은 가정을 계속해서 지원합니다.
자세한 연구 내용은 원문을 참고해주세요
위 내용은 DeepMind는 'Transformer는 사전 훈련 데이터 이상으로 일반화할 수 없다'고 지적했지만 일부 사람들은 이에 대해 의문을 제기했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



