

본래의 의미가 변하지 않기 위해 다시 표현해야 할 것은 다음과 같습니다. 먼저 교차 검증이 왜 필요한지 알아야 합니다.
교차 검증은 예측 모델의 성능과 일반화 능력을 평가하기 위해 기계 학습 및 통계에서 일반적으로 사용되는 기술입니다. 특히 데이터가 제한되어 있거나 새로운 보이지 않는 데이터로 일반화하는 모델의 능력을 평가할 때 검증은 매우 중요합니다.

어떤 상황에서 교차 검증이 사용되나요?
교차 검증의 일반적인 아이디어는 그림 5-겹 교차에 표시될 수 있습니다. 각 반복에서 새 모델은 4개의 하위 데이터 세트에서 훈련되고 마지막으로 보관된 하위 데이터 세트에서 테스트되어 모든 데이터가 일치하는지 확인합니다. 사용을 얻었습니다. 평균 점수, 표준 편차 등의 지표를 통해 모델 성능의 진정한 척도가 제공됩니다
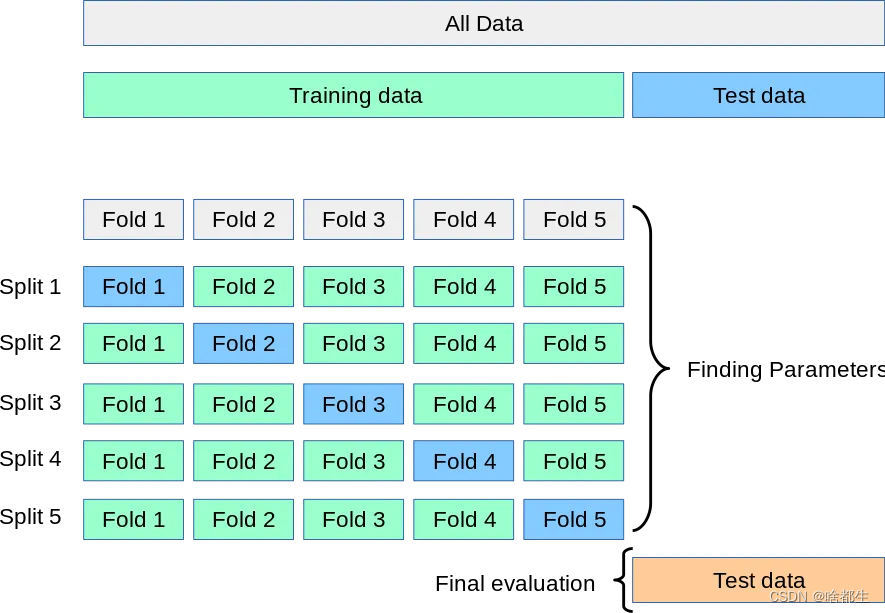
모든 것은 K-폴드 크로스오버에서 시작됩니다.
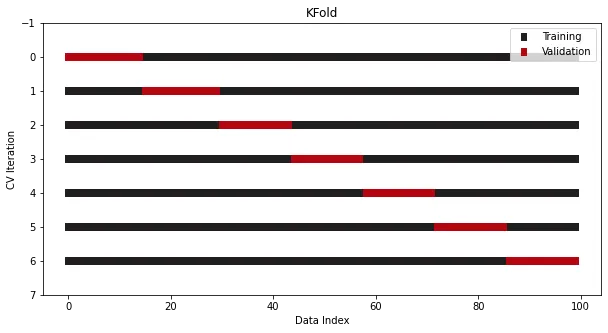
K-겹 교차 검증이 Sklearn에 통합되었습니다. 다음은 7겹 예입니다.
from sklearn.datasets import make_regressionfrom sklearn.model_selection import KFoldx, y = make_regression(n_samples=100)# Init the splittercross_validation = KFold(n_splits=7)
또 다른 일반적인 작업은 분할을 수행하기 전에 Shuffle을 수행하여 샘플의 원래 순서를 더욱 파괴하는 것입니다. 과적합 위험 최소화:
cross_validation = KFold(n_splits=7, shuffle=True)
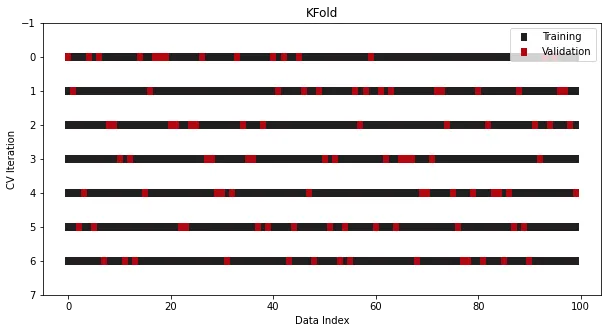
이렇게 하면 간단한 k-겹 교차 검증이 완료될 수 있습니다. 소스 코드를 꼭 확인하세요! 소스코드를 꼭 확인해보세요! 소스코드를 꼭 확인해보세요!
StratifiedKFold는 분류 문제를 위해 특별히 설계되었습니다.
일부 분류 문제에서는 데이터가 여러 세트로 나누어지더라도 목표 분포가 변경되지 않고 유지되어야 합니다. 예를 들어, 대부분의 경우 클래스 비율이 30~70인 이진 타겟은 훈련 세트와 테스트 세트에서 여전히 동일한 비율을 유지해야 합니다. 일반 KFold에서는 데이터가 분할되기 전에 섞이기 때문에 이 규칙이 깨집니다. 카테고리 비율은 유지되지 않습니다.
이 문제를 해결하기 위해 Sklearn에서 특별히 분류를 위한 또 다른 스플리터 클래스가 사용됩니다 - StratifiedKFold:
from sklearn.datasets import make_classificationfrom sklearn.model_selection import StratifiedKFoldx, y = make_classification(n_samples=100, n_classes=2)cross_validation = StratifiedKFold(n_splits=7, shuffle=True, random_state=1121218)
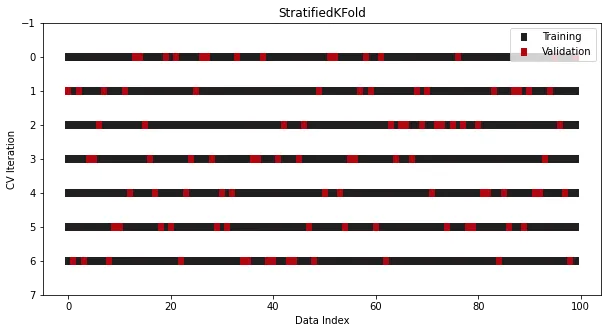
KFold와 유사해 보이지만 이제 모든 분할 및 반복에서 클래스 비율은 일관되게 유지됩니다
때때로 훈련/테스트 세트 분할 프로세스는 교차 검증과 매우 유사한 방식으로 여러 번 반복됩니다.
논리적으로는 다양한 무작위 시드를 사용하여 여러 훈련/테스트 세트를 생성합니다. 테스트 세트는 강력한 교차 검증과 유사해야 합니다. 충분한 반복으로 검증 프로세스를 수행합니다. 해당 인터페이스는 Scikit-learn 라이브러리에서도 제공됩니다.
from sklearn.model_selection import ShuffleSplitcross_validation = ShuffleSplit(n_splits=7, train_size=0.75, test_size=0.25)
 TimeSeriesSplit
TimeSeriesSplit
from sklearn.model_selection import TimeSeriesSplitcross_validation = TimeSeriesSplit(n_splits=7)
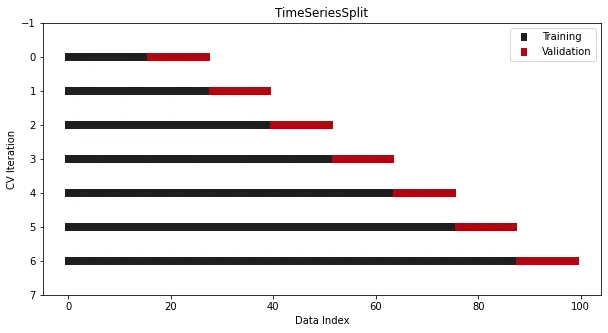 검증 세트가 항상 훈련 세트의 인덱스 뒤에 위치하는 상황 아래에서 그래프를 볼 수 있습니다. 이는 인덱스가 날짜이기 때문에 실수로 미래 날짜에 시계열 모델을 훈련하고 이전 날짜를 예측할 수 없기 때문입니다
검증 세트가 항상 훈련 세트의 인덱스 뒤에 위치하는 상황 아래에서 그래프를 볼 수 있습니다. 이는 인덱스가 날짜이기 때문에 실수로 미래 날짜에 시계열 모델을 훈련하고 이전 날짜를 예측할 수 없기 때문입니다
위 방법은 독립적이고 동일하게 분포된 데이터 세트에 대해 처리됩니다. 즉, 데이터 생성 과정은 다른 샘플의 영향을 받지 않습니다
그러나 , 어떤 경우에는 데이터가 IID(Independent and Identified Distribution) 조건을 충족하지 않습니다. 즉, 일부 샘플 간에 종속 관계가 있습니다. 이러한 상황은 Google Brain Ventilator Pressure 대회와 같은 Kaggle 대회에서도 발생합니다. 이 데이터는 수천 번의 호흡(들숨과 날숨) 동안 인공폐의 기압 값을 기록하며, 매 호흡마다 기록됩니다. 각 호흡 과정에 대한 데이터 행은 약 80개이며, 이러한 행은 서로 관련되어 있습니다. 이 경우 데이터 분할이 "호흡 과정 중간에 발생할" 수 있기 때문에 전통적인 교차 검증 방법을 사용할 수 없습니다. 그룹 데이터는 관련되어 있습니다. 예를 들어 여러 환자로부터 의료 데이터를 수집하는 경우 각 환자는 여러 샘플을 갖게 됩니다. 하지만 이러한 데이터는 환자 개개인의 차이에 영향을 받을 가능성이 높기 때문에 그룹화도 필요합니다
특정 그룹에 대해 훈련된 모델이 보이지 않는 다른 그룹에도 잘 일반화될 수 있기를 바라는 경우가 많습니다. 이러한 데이터 그룹을 "태그"로 지정하고 이를 구별하는 방법을 알려줍니다.
Sklearn에서는 이러한 상황을 처리하기 위해 여러 인터페이스가 제공됩니다.
GroupKFold위 내용은 교차 검증의 중요성은 무시할 수 없습니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



