

(2023년 11월 3일) 위치가 눈과 일치할 수 없기 때문에 카메라 관점을 기반으로 하는 헤드 디스플레이의 경우 정의된 공간을 기준으로 환경 내 객체의 공간적 관계를 사용자가 올바르게 인식하기 어려울 수 있습니다. 또한 동일하게 정의된 공간 내의 여러 사용자는 정의된 공간 외부의 개체에 대해 서로 다른 관점을 가질 수 있습니다.
그래서 마이크로소프트는 "주변 환경의 관점에 따른 디스플레이"라는 특허 출원에서 특히 자동차와 같은 모바일 플랫폼에서 정의된 공간을 정확하게 표현하는 환경 이미지를 제안합니다. 즉, 컴퓨팅 시스템은 정의된 공간을 둘러싼 환경의 적어도 일부에 대한 깊이 맵과 강도 데이터를 구성합니다. 그런 다음 강도 데이터는 깊이 맵 위치와 연관됩니다.
또한, 컴퓨팅 시스템은 정의된 공간 내에서 사용자의 자세에 대한 정보를 획득하고, 사용자의 자세에 기초하여 정의된 공간에서 사용자가 보고 있는 주변 환경의 부분을 결정할 수 있습니다. 컴퓨팅 시스템은 사용자 관점에서 환경의 일부를 나타내는 이미지 데이터를 추가로 얻습니다.
그런 다음 컴퓨팅 시스템은 사용자 시야 내 깊이 지도 위치의 강도 데이터를 기반으로 표시할 이미지를 생성합니다. 이러한 방식으로 하나 이상의 카메라에서 얻은 환경 뷰를 사용자의 관점으로 재투영하여 카메라의 다양한 관점으로 인한 폐색이나 시차 문제 없이 환경에 대한 올바른 뷰를 제공할 수 있습니다.
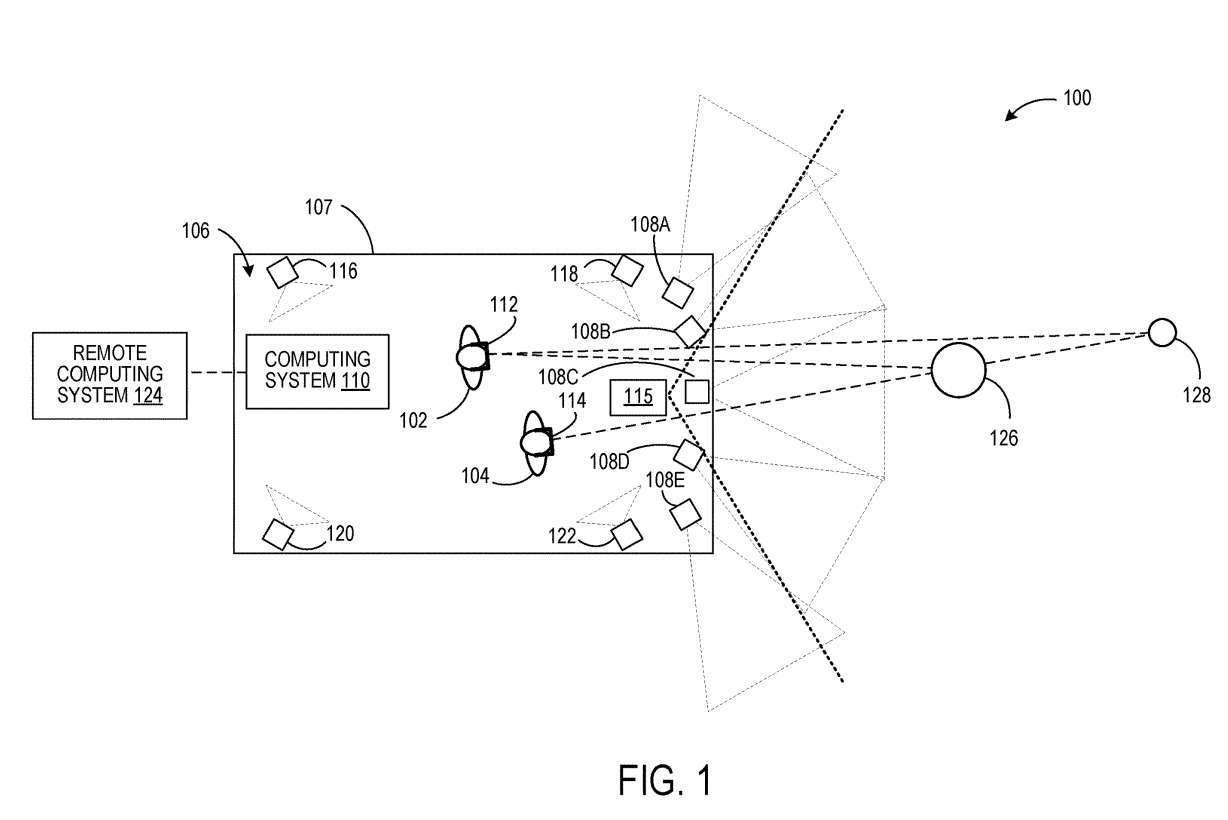
그림 1은 사용자(102 및 104)가 정의된 공간(106) 내에 위치하는 예시적인 사용 시나리오(100)를 보여줍니다. 사용자(102 및 104)는 각각 머리 장착형 장치(112 및 114)를 착용합니다.
컴퓨팅 시스템(110)은 각 사용자(102, 104)의 관점에서 정의된 공간을 둘러싼 환경을 나타내는 이미지 데이터를 생성합니다. 이를 위해, 컴퓨팅 시스템(110)은 정의된 공간(106)에 있는 각 사용자(102 및 104)의 자세에 대한 정보를 획득합니다.
일 실시예에서, 각 사용자(102, 104)의 자세는 정의된 공간의 기준 프레임에 고정되어 정의된 공간 내에서 사용자를 이미지화하도록 구성된 하나 이상의 이미징 장치로부터 결정될 수 있습니다.
그림 1에서는 이러한 이미징 장치 4개가 116, 118, 120 및 122로 표시됩니다. 이러한 이미징 장치의 예로는 스테레오 카메라 장치, 깊이 센서 등이 포함될 수 있습니다.
컴퓨팅 시스템(110)은 카메라(108A-108E)의 데이터로부터 정의된 공간(106) 주변 환경의 깊이 맵을 생성하도록 구성될 수 있습니다. 각각의 카메라(108A-108E)는 주변 환경의 일부에 대한 강도 이미지 데이터를 획득하도록 구성됩니다. 카메라는 모두 서로의 공간적 관계를 알고 있습니다.
또한 그림 1과 같이 인접한 카메라의 화각이 겹쳐집니다. 따라서 스테레오 이미징 기술을 사용하여 주변 환경에서 객체의 거리를 결정하여 깊이 맵을 생성할 수 있습니다. 다른 예에서, 카메라(108A-108E)와 별개인 선택적 깊이 센서(115)가 주변 환경의 깊이 맵을 획득하는 데 사용될 수 있습니다. 예시적인 깊이 센서에는 LiDAR 센서와 하나 이상의 깊이 카메라가 포함됩니다. 이러한 예에서, 선택적으로 강도 이미지를 획득하는 카메라의 시야는 중첩되지 않을 수 있다.
카메라의 강도 데이터는 메시의 각 정점이나 포인트 클라우드의 각 점과 같은 깊이 맵의 각 위치와 연결됩니다. 다른 예에서, 카메라의 강도 데이터는 깊이 맵의 각 위치에 대해 계산된 결합 강도 데이터를 형성하기 위해 계산적으로 결합됩니다. 예를 들어, 두 개 이상의 서로 다른 카메라의 센서 픽셀로 깊이 맵 위치를 이미지화하는 경우 두 개 이상의 서로 다른 카메라의 픽셀 값을 계산하여 저장할 수 있습니다.
다음으로, 적어도 각 사용자(102, 104)의 제스처에 기초하여 컴퓨팅 시스템(110)은 각 사용자(102, 104)가 보고 있는 정의된 공간을 둘러싼 환경의 일부를 결정하여 관점에서 해당 부분의 표현을 얻을 수 있습니다. 각 사용자(102, 104)의 환경 이미지 데이터를 제공하고 각 헤드 디스플레이(112, 114)에 이미지 데이터를 제공합니다.
예를 들어, 정의된 공간(106) 내에서 사용자의 자세와 정의된 공간(106)에 대한 주변 환경의 깊이 맵의 공간적 관계를 알면 각 사용자의 자세를 깊이 맵과 연관시킬 수 있습니다. 그런 다음 각 사용자의 시야가 정의되고 깊이 맵에 투영되어 사용자의 시야 내에 있는 깊이 맵의 부분을 결정할 수 있습니다.
다음으로, 레이 캐스팅과 같은 기술을 사용하여 시야 내에서 깊이 맵이 표시되는 위치를 결정할 수 있습니다. 위치와 관련된 강도 데이터를 사용하여 표시할 이미지를 형성할 수 있습니다. 컴퓨팅 시스템(110)은 선택적으로 클라우드 서비스와 같은 원격 컴퓨팅 시스템(124)과 통신할 수 있다. 이러한 경우, 이러한 처리 단계 중 하나 이상은 원격 컴퓨팅 시스템(124)에 의해 수행될 수 있습니다.
이렇게 하면 특정 공간 내에서 다양한 사용자가 주변 환경의 이미지를 개인적인 관점에서 관찰할 수 있습니다. 사용자(102)의 관점에서 헤드셋(112)에 의해 디스플레이되는 이미지는 환경 내의 객체(126) 및 객체(128)의 뷰를 포함할 수 있는 반면, 객체(128)의 뷰는 사용자의 관점에서 헤드셋(114)에 의해 디스플레이되는 이미지의 객체(126)에 의해 가려질 수 있다 104 .
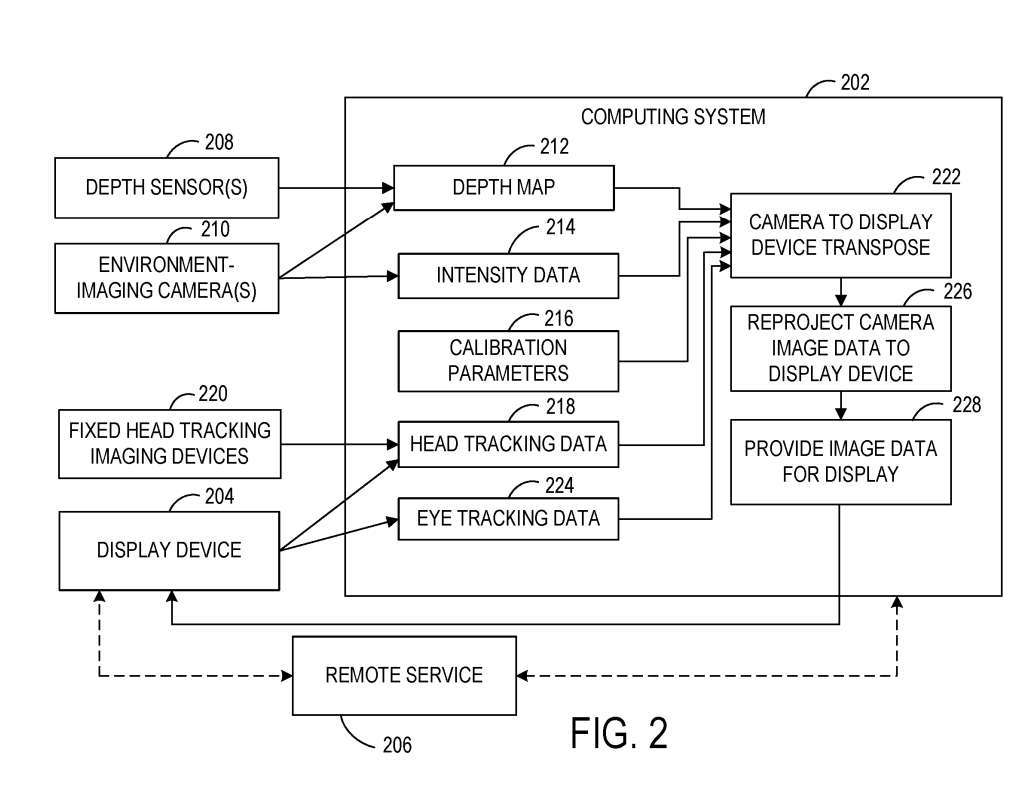
도 2는 사용자의 관점에서 정의된 공간 내에서 정의된 공간을 둘러싼 환경의 이미지를 사용자에게 표시하도록 구성된 예시적인 시스템(200)의 블록도를 보여줍니다. 시스템(200)은 정의된 공간에 국한된 컴퓨팅 시스템(202) 및 정의된 공간 내에 위치한 디스플레이 장치(204)를 포함한다.
시스템 200은 하나 이상의 카메라 210을 포함하며 환경을 이미지화하도록 구성됩니다. 일례에서, 카메라(210)는 패시브 스테레오 카메라로 사용되고 스테레오 이미징 방법은 강도 데이터 및 깊이 데이터를 획득하는 데 사용됩니다. 다른 예에서, 하나 이상의 깊이 센서(208)는 정의된 공간 주변의 깊이 데이터를 획득하기 위해 선택적으로 사용됩니다.
컴퓨팅 시스템(202)은 깊이 데이터로부터 환경의 깊이 맵(212)을 구성하기 위한 실행 가능한 명령을 포함합니다. 깊이 맵(212)은 3D 포인트 클라우드 또는 메시와 같은 임의의 적절한 형태를 취할 수 있다. 전술한 바와 같이, 컴퓨팅 시스템(202)은 하나 이상의 카메라(210)에 의해 획득된 이미지 데이터에 기초하여 깊이 맵(212)의 각 위치와 연관된 강도 데이터(214)를 수신하고 저장할 수 있다.
깊이 센서(208)와 카메라(210)의 상대적인 공간 위치는 서로에 대해 그리고 정의된 공간의 기하학적 구조에 대해 보정됩니다. 따라서, 도 2는 카메라(210) 및 깊이 센서(208)의 뷰를 사용자의 자세로 바꾸는 데 도움이 되는 입력으로 사용될 수 있는 교정 매개변수(216)를 도시하며, 이로써 디스플레이를 위해 카메라 관점에서 사용자 관점으로 이미지 데이터를 재투영하는 데 도움이 됩니다. .
일 실시예에서, 디스플레이 장치(204) 및/또는 정의된 공간은 주변 환경에 대해 지속적으로 이동할 수 있으므로, 깊이 맵(212)에 대해 디스플레이 장치(204)의 위치를 보정하기 위해 지속적인 외부 보정이 수행될 수 있습니다. 예를 들어, 디스플레이 장치(204)에 의한 깊이 맵(212)의 교정은 디스플레이 장치(204)에 의한 디스플레이의 프레임 속도로 수행될 수 있다.
컴퓨팅 시스템(202)은 정의된 공간 내에서 사용자의 자세에 대한 정보를 더 얻을 수 있습니다. 사용자의 자세는 보다 구체적으로 머리 위치와 머리 방향을 나타낼 수 있으며, 이는 사용자가 찾고 있는 정의된 공간 주변 환경의 일부를 결정하는 데 도움이 됩니다. 컴퓨팅 시스템(202)은 머리 추적 데이터(218)를 수신하도록 구성된다. 머리 추적 데이터(218)는 추가로 또는 대안적으로 정의된 공간의 기준 프레임에 고정된 하나 이상의 이미징 장치로부터 수신될 수 있습니다.
위에서 설명된 바와 같이, 컴퓨팅 시스템(202)은 머리 추적 데이터(218)로부터 결정된 사용자의 자세와 함께 깊이 맵(212) 및 대응하는 강도 데이터(214)를 사용하여 디스플레이 장치(204)의 사용자 관점에서 디스플레이할 이미지 데이터를 결정한다. 컴퓨팅 시스템(202)은 사용자의 자세를 기반으로 사용자가 보고 있는 환경의 일부를 결정하고, 사용자의 시야를 깊이 맵에 투영한 다음, 사용자의 관점에서 보이는 깊이 맵 위치에 대한 강도 데이터를 얻을 수 있습니다. 디스플레이 장치에 제공되는 이미지 데이터는 디스플레이 장치(204)의 프레임 버퍼 내에서 사후 재투영을 거칠 수 있습니다. 예를 들어 사후 재투영을 사용하면 렌더링된 이미지가 표시되기 직전에 렌더링된 이미지의 객체 위치를 업데이트할 수 있습니다. 여기서, 디스플레이 장치(204)는 움직이는 차량에 위치하며, 디스플레이 장치(204)의 프레임 버퍼에 있는 이미지 데이터는 226에서 이미지 형성과 이미지 표시 사이에 차량이 이동한 거리에 기초하여 재투영될 수 있습니다. 컴퓨팅 시스템(202)은 추후 재투영을 위해 차량 모션 기반 장치(204)를 표시하기 위해 모션 벡터를 제공할 수 있다. 다른 예에서, 모션 벡터는 디스플레이 디바이스(204)의 국부 관성 측정 유닛으로부터의 데이터로부터 결정될 수 있다. 일 실시예에서, 카메라(210)에 의해 획득된 강도 데이터의 프레임 속도는 깊이 센서(208)에 의해 획득된 깊이 맵의 프레임 속도와 다를 수 있습니다. 예를 들어, 깊이 맵을 획득하는 데 사용되는 프레임 속도는 강도 데이터를 획득하는 데 사용되는 프레임 속도보다 낮을 수 있습니다. 마찬가지로 프레임 속도는 차량 속도의 변화, 환경에서 움직이는 물체 및/또는 기타 환경 요인에 따라 달라질 수 있습니다. 이러한 예에서, 강도 데이터를 깊이 맵 위치와 연관시키기 전에, 강도 데이터 및/또는 깊이 데이터는 강도 데이터가 획득되는 시간과 깊이 맵이 획득되는 시간 사이에 발생하는 모션을 수정하기 위해 변환될 수 있습니다. 강도 데이터를 획득하기 위해 여러 대의 카메라(210)를 사용하는 경우, 정의된 공간 주변 환경의 객체가 여러 대의 카메라(210)의 영상 데이터에 나타날 수 있다. 이러한 예에서는 물체를 촬영하는 각 카메라의 강도 데이터가 사용자의 관점에 재투영될 수 있습니다.다른 예로, 물체를 촬영하는 하나의 카메라 또는 카메라 하위 집합의 강도 데이터를 사용자의 관점에 재투영할 수 있습니다. 이는 물체를 촬영하는 모든 카메라의 이미지 데이터를 사용자의 관점으로 바꾸는 것보다 더 적은 계산 리소스를 사용할 수 있습니다.
이러한 예에서는 사용자의 관점에 가장 가깝다고 판단된 관점을 가진 카메라의 이미지 데이터를 사용할 수 있습니다. 다른 예에서, 선택된 깊이 맵 위치에 대한 다수의 카메라로부터의 픽셀 강도 데이터는 평균화되거나 계산적으로 결합된 다음 깊이 맵 위치에 대해 저장될 수 있습니다.
그림 1의 예에서 사용자(102 및 104)는 헤드셋(112, 114)을 통해 컴퓨팅 시스템(110)에 의해 생성된 관점 의존 이미지를 봅니다. 도 3의 예시적인 시나리오(300)에서, 사용자는 정의된 공간(304) 내의 고정된 위치에 위치한 디스플레이 패널에서 카메라(306A-306E)에 의해 획득된 이미지 데이터를 보고 있습니다.
그러나 카메라(306A-306E)의 관점에서 이미지를 표시하는 대신, 카메라(306A-306E)의 이미지 데이터는 이미지 데이터에서 결정된 깊이 맵 또는 카메라(306A-306E)에서 획득한 데이터에서 결정된 깊이 맵과 연관됩니다. 깊이 센서.
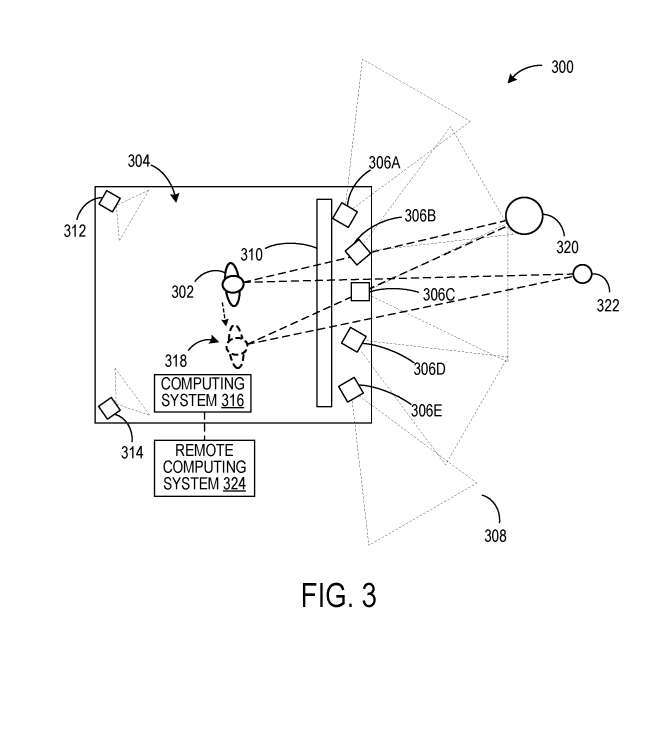
이를 통해 이미지 데이터를 사용자(302)의 투시도로 변환할 수 있습니다. 카메라(312, 314)는 사용자 제스처 추적을 수행하기 위해 정의된 공간(304)의 내부를 이미지화합니다. 사용자 자세 판단을 위해 하나 이상의 깊이 센서가 추가로 사용됩니다. 사용자(302)의 관점으로부터의 이미지 데이터는 카메라(312, 314)로부터의 데이터로부터 결정된 사용자 자세 데이터에 기초하여 디스플레이 패널(310)에 표시될 수 있다.
이 예에서, 이미지 데이터를 사용자(302)의 관점으로 재투영하는 것은 그림 2와 관련하여 위에서 설명한 작업 외에도 디스플레이 패널을 전환하기 위한 사용자 제스처도 포함할 수 있습니다. 디스플레이 패널은 사용자가 정의 공간(304) 내에서 이동할 때 변경 사항에 따라 변경됩니다.
따라서 사용자 302가 새로운 위치 318로 이동하면 환경 내의 객체 320, 322가 사용자 302의 원래 위치와 다른 각도에서 나타납니다. 컴퓨팅 시스템(316)은 선택적으로 클라우드 서비스와 같은 원격 컴퓨팅 시스템(324)과 통신할 수 있다.
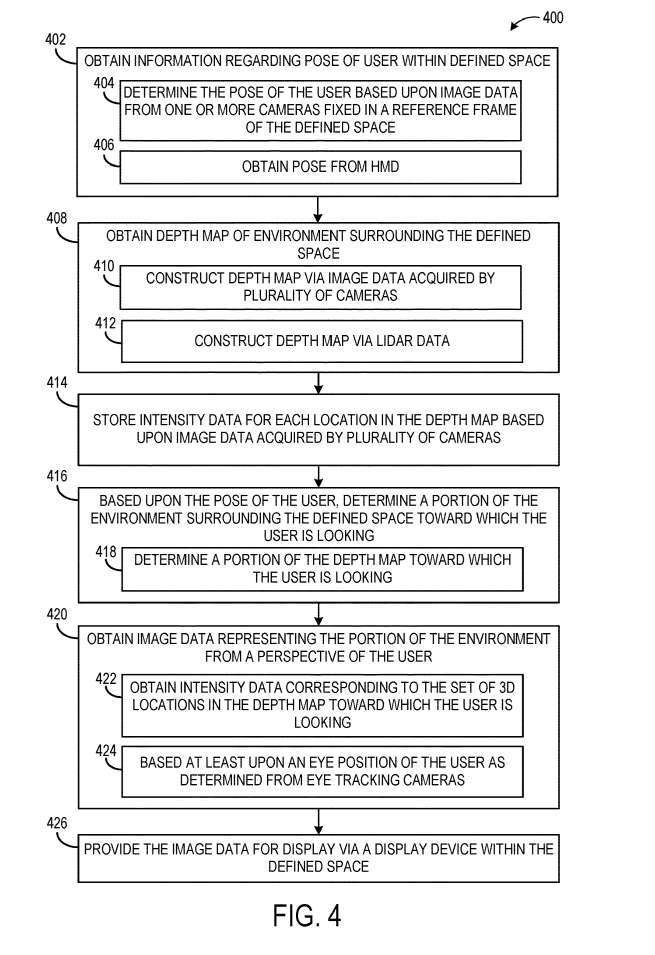
도 4는 정의된 공간 내의 사용자의 관점에서 디스플레이하기 위해 정의된 공간을 둘러싼 환경의 이미지 데이터를 제공하는 예시적인 방법(400)을 도시한다.
402에서, 방법(400)은 정의된 공간 내에서 사용자의 자세에 대한 정보를 획득하는 것을 포함합니다. 위에서 언급한 바와 같이, 예를 들어 사용자의 자세는 머리 위치와 방향을 반영할 수 있습니다. 사용자의 제스처는 공간 참조 프레임에 고정된 하나 이상의 카메라로부터 얻은 이미지 데이터를 기반으로 결정될 수 있습니다. 다른 예로서, 406에서, 사용자의 제스처는 사용자가 착용한 헤드셋으로부터 수신될 수 있으며, 이는 예를 들어 헤드셋의 하나 이상의 이미지 센서로부터의 이미지 데이터로부터 결정됩니다.
408에는 정의된 공간을 둘러싼 환경에 대한 깊이 맵을 얻는 것이 포함됩니다. 깊이 맵은 410에서 환경을 이미징하는 다수의 카메라에 의해 획득된 이미지 데이터로부터 구성될 수 있거나, 412에서 LiDAR 센서에 의해 획득된 LiDAR 데이터로부터 구성될 수 있습니다.
다른 예에서는 비행 시간 깊이 이미징과 같은 다른 적합한 유형의 깊이 감지를 활용할 수 있습니다. 그런 다음 414에서 방법(400)은 깊이 맵의 각 위치에 대한 강도 데이터를 저장하는 단계를 포함합니다.
다음 416에서는 사용자의 자세에 따라 사용자가 찾고 있는 정의된 공간을 둘러싼 환경의 부분을 결정합니다. 이는 사용자가 깊이 맵의 어느 부분을 보고 있는지를 418에서 결정하는 것을 포함할 수 있습니다. 일례에서, 사용자의 관점에서 볼 수 있는 깊이 맵의 위치를 결정하기 위해 사용자의 시야가 깊이 맵에 투영될 수 있습니다.
방법 400은 또한 420에서 사용자 관점에서 환경의 일부를 나타내는 이미지 데이터를 획득하는 단계도 포함합니다. 방법(400)은 또한 426에서 정의된 공간 내의 디스플레이 장치에 의한 디스플레이를 위한 이미지 데이터를 제공하는 것을 포함한다.
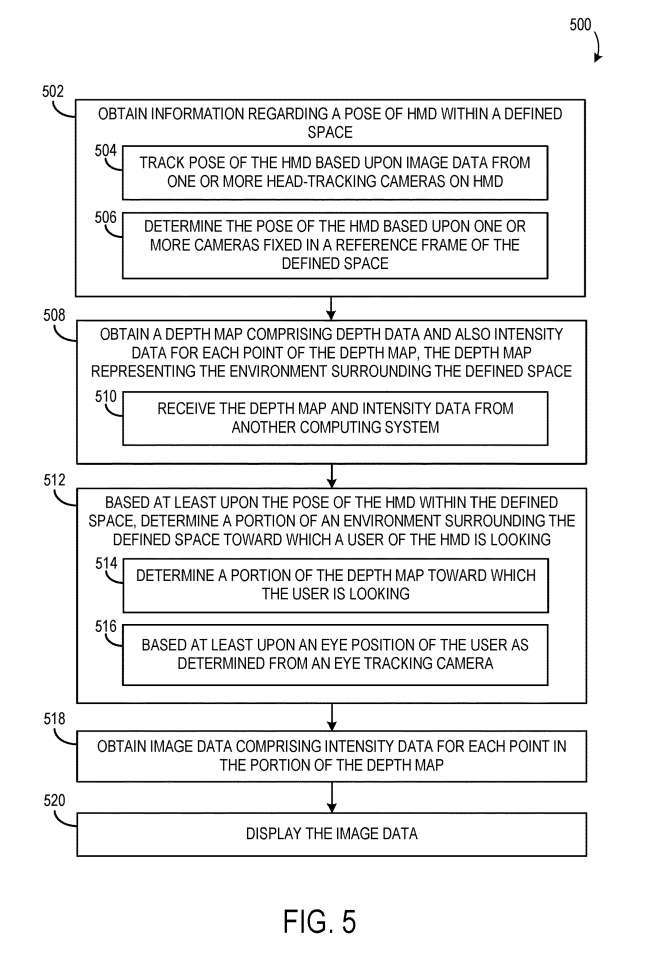
그림 5는 헤드 마운트 디스플레이를 통해 사용자의 관점에서 환경 이미지 데이터를 표시하는 예시적인 방법(500)의 흐름도를 보여줍니다.
502에서, 방법(500)은 정의된 공간 내에서 헤드셋의 자세에 대한 정보를 획득하는 것을 포함합니다. 헤드셋의 자세는 하나 이상의 헤드셋 머리 추적 카메라에서 얻은 이미지 데이터를 기반으로 추적할 수 있습니다. 504에서, 헤드셋의 자세는 공간을 정의하는 기준 프레임에 고정된 하나 이상의 카메라에 기초하여 결정될 수 있습니다. 506에서, 하나 이상의 고정 카메라가 헤드셋과 통신합니다.
508에서, 방법(500)은 깊이 맵의 각 위치에 대한 깊이 데이터 및 강도 데이터를 포함하는 깊이 맵을 획득하는 단계도 포함하며, 여기서 깊이 맵은 정의된 공간을 둘러싼 환경을 나타냅니다.
512에서는 적어도 정의된 공간 내 헤드셋의 자세에 기초하여 헤드셋 사용자가 보고 있는 정의된 공간 주변 환경의 일부를 결정합니다. 이는 514에서 사용자가 보고 있는 깊이 맵의 부분을 결정하는 것을 포함할 수 있습니다. 사용자가 보고 있는 환경/깊이 맵의 부분은 적어도 사용자의 눈 위치에 더 기초할 수 있습니다.
방법(500)은 518에서 깊이 맵 부분의 각 위치에 대한 강도 데이터를 포함하는 이미지 데이터를 획득하는 단계와 520에서 이미지 데이터를 표시하는 단계를 더 포함합니다.
관련 특허: Microsoft 특허 | 주변 환경의 관점에 따른 표시 |
"주변 환경의 관점에 따른 표시"라는 제목의 Microsoft 특허 출원은 원래 2022년 3월에 제출되었으며 최근 미국 특허청에 공개되었습니다.
위 내용은 Microsoft AR/VR 특허 공유로 다양한 카메라 각도로 인해 발생하는 폐색 또는 시차 문제를 해결합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



