

최근 수학자 테렌스 타오(Terence Tao)에게 영감을 준 GPT-4는 채팅에서 펜을 돌리는 방법을 로봇에게 가르치기 시작했습니다.

이 프로젝트는 Agent Eureka라고 하며, NVIDIA, University of Pennsylvania, California Institute of Institute에서 개발했습니다. Technology와 University of Texas at Austin이 분교에서 공동으로 개발했습니다. 그들의 연구는 GPT-4 구조의 힘과 강화 학습의 장점을 결합하여 Eureka가 절묘한 보상 기능을 설계할 수 있도록 합니다.
GPT-4의 프로그래밍 기능은 Eureka에 강력한 보상 기능 설계 기술을 제공합니다. 이는 대부분의 작업에서 유레카 자체 보상 체계가 인간 전문가의 보상 체계보다 훨씬 우수하다는 것을 의미합니다. 이를 통해 펜 돌리기, 서랍 열기, 호두 판 열기 등 인간이 완료하기 어려운 일부 작업은 물론 공 던지고 잡기, 가위 조작 등과 같은 훨씬 더 복잡한 작업을 완료할 수 있습니다.
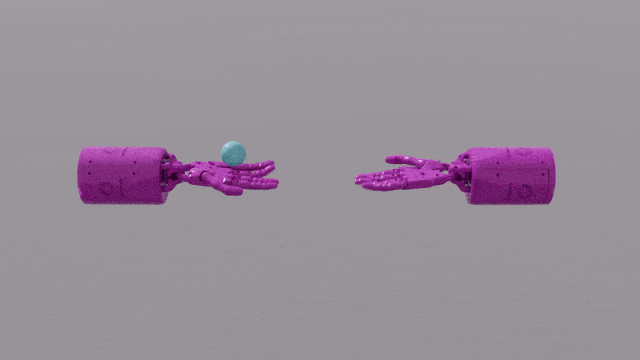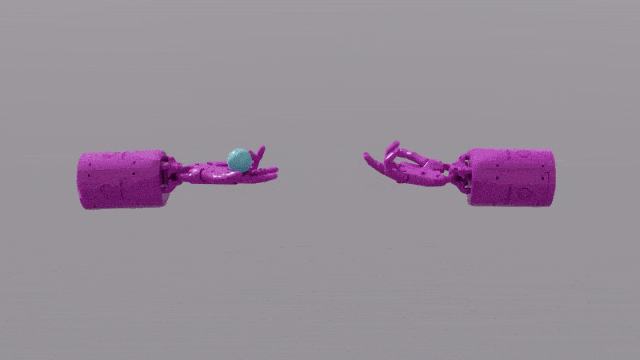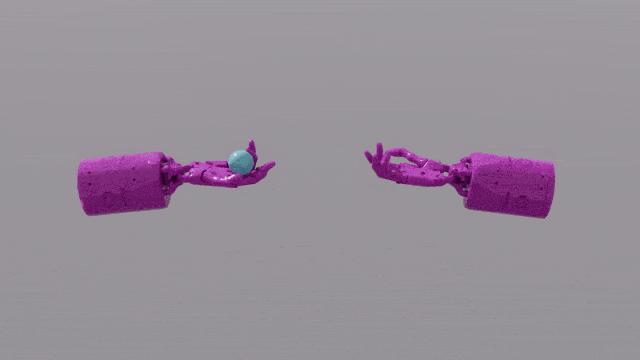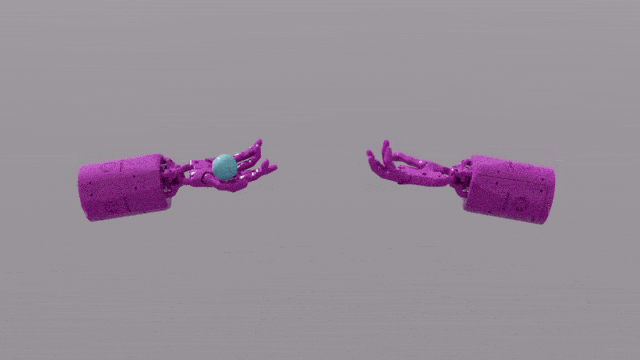 Pictures
Pictures
 Pictures
Pictures
이러한 작업은 현재 시뮬레이션 환경에서 수행되지만 이미 매우 강력합니다.
해당 프로젝트는 오픈소스로 공개되었으며, 프로젝트 주소와 논문 주소는 글 말미에 기재했습니다.
논문의 핵심 내용을 간략하게 요약했습니다.
이 문서에서는 LLM(대형 언어 모델)을 사용하여 기계 학습에서 보상 기능을 설계하고 최적화하는 방법을 탐구합니다. 좋은 보상 함수를 설계하면 머신러닝 모델의 성능을 크게 향상시킬 수 있지만, 그러한 함수를 설계하는 것은 매우 어렵기 때문에 이는 중요한 주제입니다.
연구원들이 EUREKA라는 새로운 알고리즘을 제안했습니다. EUREKA는 보상 기능을 생성하고 개선하기 위해 LLM을 채택합니다. 테스트에서 EUREKA는 29개의 서로 다른 강화 학습 환경에서 인간 수준의 성능을 달성했으며 작업의 83%에서 인간 전문가가 설계한 보상 기능을 능가했습니다.
EUREKA는 이전에는 보상 기능을 수동으로 설계할 수 없었던 몇 가지 문제를 성공적으로 해결했습니다. 빠르게 펜을 돌리는 "Shadow Hand"의 작동을 시뮬레이션하는 것과 같습니다
또한 EUREKA는 인간의 피드백을 기반으로 인간의 기대에 더 부합하는 보다 효과적인 보상 기능을 생성할 수 있는 새로운 방법을 제공합니다
EUREKA 작동 세 가지 주요 단계:
컨텍스트로서의 환경: EUREKA는 환경의 소스 코드를 컨텍스트로 사용하여 실행 가능한 보상 기능을 생성합니다
2. 진화적 검색: EUREKA는 진화적 검색과 보상 기능 개선을 통해 지속적으로 아이디어를 제안합니다
3. 반영: EUREKA는 정책 훈련의 통계를 기반으로 보상 품질에 대한 텍스트 요약을 생성하여 보상 기능을 자동으로 목표적으로 향상시킵니다. 3. 보상 반영: EUREKA는 정책 훈련의 통계 데이터를 기반으로 보상 품질에 대한 텍스트 요약을 생성하여 보상 기능을 자동으로 그리고 목표적으로 향상시킵니다.
이 연구는 강화 학습 및 보상 기능 설계 분야에 지대한 영향을 미칠 수 있습니다. 보상 기능을 자동으로 생성하고 개선하는 효율적인 방법이 제공되며, 이 방법의 성능은 많은 경우 인간 전문가의 성능을 능가합니다.
프로젝트 주소: //m.sbmmt.com/link/e6b738eca0e6792ba8a9cbcba6c1881d
문서 링크: //m.sbmmt.com/link/ce128c3e8f0c0ae4b3e843dc7cbab0f7
위 내용은 GPT4는 로봇에게 부드러운 부드러움이라고 불리는 펜을 돌리는 방법을 가르칩니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



