

BERT, GPT, Flan-T5와 같은 언어 모델부터 SAM, Stable Diffusion과 같은 이미지 모델까지 Transformer는 빠른 속도로 전 세계를 휩쓸고 있지만 사람들은 묻지 않을 수 없습니다. Transformer가 유일한 선택일까요?
스탠포드 대학과 버팔로 뉴욕 주립 대학의 연구팀은 이 질문에 대해 부정적인 답변을 제공할 뿐만 아니라 새로운 대체 기술인 Monarch Mixer를 제안합니다. 최근 팀은 arXiv에 관련 논문과 일부 체크포인트 모델 및 훈련 코드를 게시했습니다. 그런데 이 논문은 NeurIPS 2023에 선정되어 Oral Presentation 자격을 얻었습니다.

문서 링크: https://arxiv.org/abs/2310.12109
GitHub의 코드 주소: https://github.com/HazyResearch/m2
이 방법은 제거합니다. Transformer의 고비용 Attention 및 MLP는 표현력이 풍부한 Monarch 행렬로 대체되어 언어 및 이미지 실험에서 더 낮은 비용으로 더 나은 성능을 달성할 수 있습니다.
스탠포드 대학이 Transformer의 대체 기술을 제안한 것은 이번이 처음이 아닙니다. 올해 6월에는 학교의 다른 팀에서도 Backpack이라는 기술을 제안했습니다. Heart of Machine 기사 "Stanford Training Transformer Alternative Model: 170 Million 매개변수, Debiased, Controllable and Highly Interpretable"을 참조하세요. 물론 이러한 기술이 진정한 성공을 거두려면 연구 커뮤니티에서 추가 테스트를 거쳐 애플리케이션 개발자의 손에서 실용적이고 유용한 제품으로 전환되어야 합니다.
Monarch Mixer에 대한 소개와 일부 내용을 살펴보겠습니다. 이 논문의 실험 결과.
자연어 처리 및 컴퓨터 비전 분야에서 기계 학습 모델은 더 긴 시퀀스와 고차원 표현을 처리할 수 있어 더 긴 컨텍스트와 더 높은 품질을 지원할 수 있습니다. 그러나 기존 아키텍처의 시간 및 공간 복잡성은 시퀀스 길이 및/또는 모델 차원에서 2차 성장 패턴을 나타내며, 이로 인해 컨텍스트 길이가 제한되고 확장 비용이 증가합니다. 예를 들어 Transformer의 Attention 및 MLP는 시퀀스 길이 및 모델 차원에 따라 2차적으로 확장됩니다.
이 문제에 대응하여 스탠포드 대학교와 버팔로 뉴욕 주립 대학교의 연구팀은 시퀀스 길이와 모델 차원(서브이차)에 따라 복잡성이 이차 이하로 증가하는 고성능 아키텍처를 발견했다고 주장합니다.
그들의 연구는 MLP-mixer 및 ConvMixer에서 영감을 받았습니다. 이 두 연구에서는 다음과 같은 사실을 관찰했습니다. 많은 기계 학습 모델은 시퀀스와 모델 차원을 축으로 따라 정보를 혼합하고 단일 연산자를 사용하여 두 축에서 작동하는 경우가 많습니다. 구현. 예를 들어 MLP 믹서의 MLP와 ConvMixer의 컨볼루션은 모두 표현력이 뛰어나지만 둘 다 입력 차원에 따라 2차적으로 확장됩니다. 최근 일부 연구에서는 일부 하위 2차 시퀀스 하이브리드 방법을 제안했으며 이러한 방법은 모두 FFT를 사용하지만 이러한 모델의 FLOP 활용도는 매우 낮습니다. 아직 2차 확장이군요. 동시에, 품질 저하 없이 희소 밀집 MLP 레이어에 대한 몇 가지 유망한 진전이 있지만 일부 모델은 실제로 낮은 하드웨어 활용으로 인해 밀집 모델보다 느릴 수 있습니다.
이러한 영감을 바탕으로 연구팀은 표현력이 뛰어난 하위 2차 구조 행렬인 Monarch 행렬을 사용하는 Monarch Mixer(M2)를 제안했습니다. Monarch 행렬
Monarch 행렬은 일반화된 고속 푸리에 변환(FFT) 구조 행렬입니다. , 연구에 따르면 Hadamard 변환, Toplitz 행렬, AFDF 행렬 및 컨볼루션 등과 같은 다양한 선형 변환이 포함되어 있는 것으로 나타났습니다. 이러한 행렬은 블록 대각 행렬의 곱으로 매개변수화될 수 있으며 이러한 매개변수는 순열 인터리빙과 관련됩니다. 해당 계산은 하위 2차적입니다. 즉, 요소 수가 p로 설정된 경우 입력 길이가 N이면 계산 복잡도는
이므로 p = log N일 때 계산 복잡도는 O(N log N)이고 p = 2일 때사이일 수 있습니다.
M2는 Monarch 행렬을 사용하여 시퀀스 및 모델 차원 축을 따라 정보를 혼합합니다. 이 접근 방식은 구현하기 쉬울 뿐만 아니라 하드웨어 효율적이기도 합니다. 차단 대각선 모나크 인수는 GEMM(일반 행렬 곱셈 알고리즘)을 지원하는 최신 하드웨어를 사용하여 효율적으로 계산할 수 있습니다.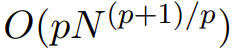
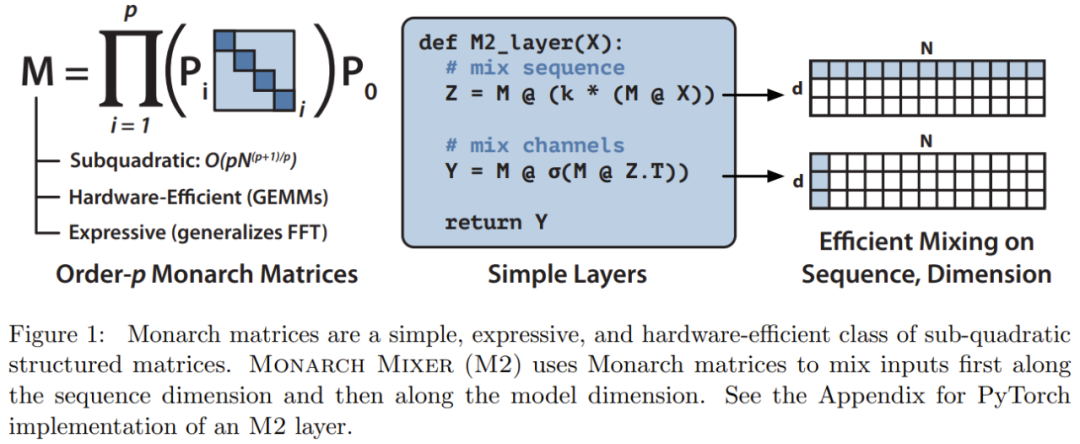
연구팀은 PyTorch를 사용하여 코드를 작성하여 40줄 미만으로 M2 레이어를 구현했으며, 행렬 곱셈, 전치, 형태 변경 및 요소별 곱에만 의존했습니다(그림 1 코드 중간의 의사 참조). 입력 크기가 64k인 경우 이러한 코드는 A100 GPU에서 25.6%의 FLOP 활용률을 달성합니다. RTX 4090과 같은 최신 아키텍처에서는 동일한 크기 입력에 대해 간단한 CUDA 구현으로 41.4%의 FLOP 활용률을 달성할 수 있습니다
Monarch Mixer에 대한 더 많은 수학적 설명과 이론적 분석은 원본 논문을 참조하세요. .
연구팀은 Monarch Mixer와 Transformer 두 가지 모델을 비교하면서 Transformer가 3가지 주요 업무를 장악하고 있는 상황을 주로 연구했습니다. 세 가지 작업은 BERT 스타일 비인과 마스크 언어 모델링 작업, ViT 스타일 이미지 분류 작업 및 GPT 스타일 인과 언어 모델링 작업입니다.
각 작업에서 실험 결과는 새로 제안된 방법이 달성할 수 있음을 보여줍니다. 주의와 MLP를 사용하지 않고 Transformer와 비슷한 수준입니다. 또한 BERT 설정에서 강력한 Transformer 기준 모델과 비교하여 새로운 방법의 속도 향상을 평가했습니다. 작업을 작성하기 위해 팀은 M2: M2-BERT를 기반으로 하는 아키텍처를 구축했습니다. M2-BERT는 BERT 스타일 언어 모델을 직접 대체할 수 있으며 BERT는 Transformer 아키텍처의 주요 애플리케이션입니다. M2-BERT 훈련에는 C4의 마스크된 언어 모델링이 사용되며 토크나이저는 bert-base-uncased입니다.
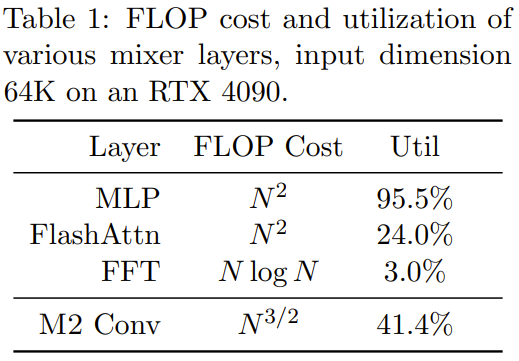
M2-BERT는 Transformer 백본을 기반으로 하지만 그림 3과 같이 M2 레이어가 어텐션 레이어와 MLP를 대체합니다.
시퀀스 믹서에서 어텐션은 잔여 양방향 게이트로 컨볼루션됩니다. 대신 컨볼루션을 수행합니다(그림 3의 왼쪽 참조). 컨벌루션을 복원하기 위해 팀은 Monarch 행렬을 DFT 및 역 DFT 행렬로 설정했습니다. 그들은 또한 투영 단계 후에 깊이별 컨볼루션을 추가했습니다.
차원 혼합기에서는 MLP의 2개의 밀집 행렬을 학습된 블록 대각 행렬로 대체합니다(Monarch 행렬의 순서는 1, b=4)
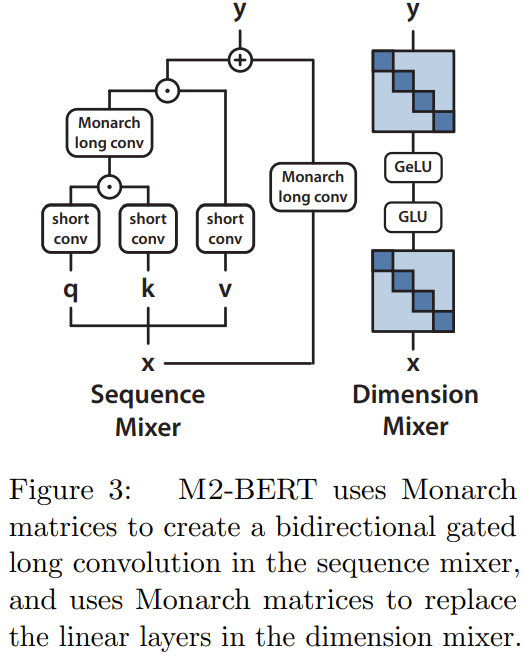
표 3은 BERT-base에 해당하는 모델의 성능을 나타내고, 표 4는 BERT-large에 해당하는 모델의 성능을 보여줍니다.
표에서 볼 수 있듯이 GLUE 벤치마크에서 M2-BERT 기반의 성능은 BERT 기반과 비슷하지만 둘 사이의 매개변수 수가 27% 더 적습니다. 동일하면 M2 -BERT-base가 BERT-base를 1.3포인트 능가합니다. 마찬가지로, 24% 더 적은 매개변수를 갖는 M2-BERT-large는 BERT-large와 동일하게 성능을 발휘하는 반면, 동일한 수의 매개변수를 사용하는 M2-BERT-large는 0.7점 이점을 갖습니다.
표 5는 BERT 기반 모델과 유사한 모델의 순방향 처리량을 보여줍니다. 보고되는 것은 A100-40GB GPU에서 밀리초당 처리되는 토큰 수로, 추론 시간을 반영할 수 있습니다
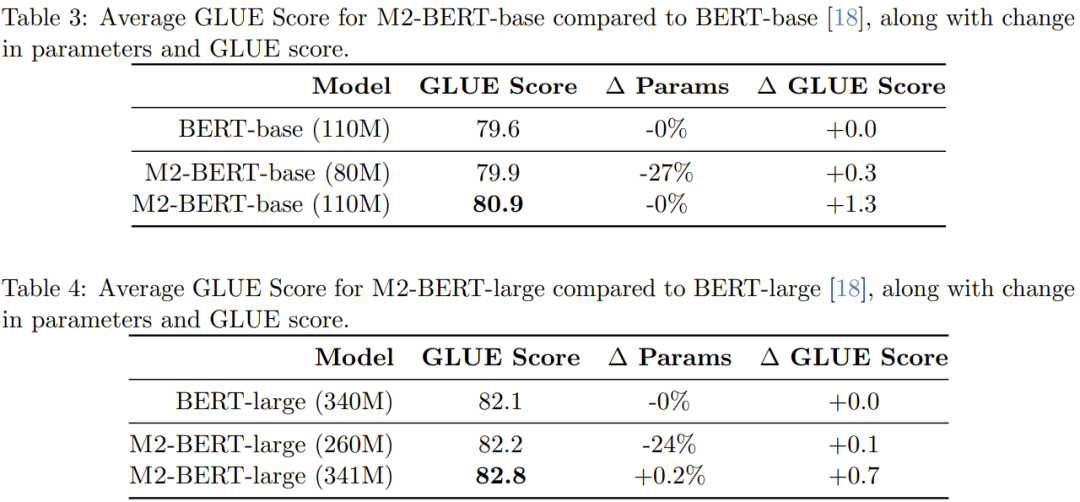
M2-BERT 기반의 처리량이 심지어 고도로 최적화된 BERT 모델은 4k 시퀀스 길이의 표준 HuggingFace 구현과 비교하여 M2-BERT 기반의 처리량이 9.1배에 도달할 수 있습니다.
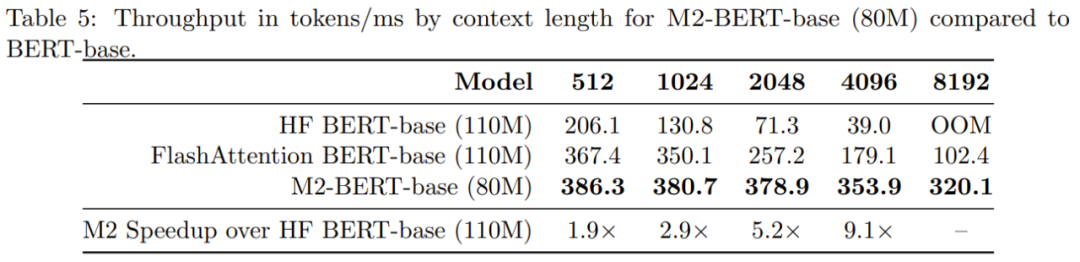
표 6은 M2-BERT 기반(80M) 및 BERT 기반에 대한 CPU 추론 시간을 제공합니다. 이 결과는 PyTorch 구현을 사용하여 이 두 모델을 직접 실행하여 얻은 것입니다.
시퀀스가 짧으면 데이터 위치의 영향이 여전히 FLOP 감소를 지배하고 필터 생성(BERT에서는 사용할 수 없음)과 같은 작업의 비용이 더 많이 듭니다. 시퀀스 길이가 1K를 초과하면 M2-BERT 기반의 가속 이점이 점차 증가하며 시퀀스 길이가 8K에 도달하면 속도 이점이 6.5배에 도달할 수 있습니다.
이미지 분류
이미지 도메인에서 새로운 방법의 장점이 언어 도메인에서와 동일한지 확인하기 위해 팀은 이미지 분류 작업에 대한 M2의 성능도 평가했습니다. 표 7은 ImageNet-1k 성능에서 Monarch Mixer, ViT-b, HyenaViT-b 및 ViT-b-Monarch(표준 ViT-b의 MLP 모듈을 Monarch 매트릭스로 대체)의 성능을 보여줍니다.
Monarch Mixer의 장점은 매우 분명합니다. 원래 ViT-b 모델을 능가하려면 매개변수 수가 절반만 필요합니다. 놀랍게도 더 적은 수의 매개변수를 가진 Monarch Mixer는 ImageNet 작업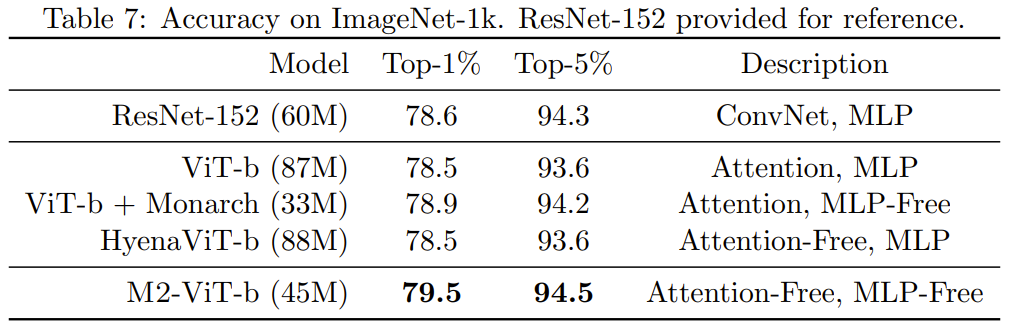
Causal Language Modeling
GPT 스타일 인과 언어 모델링 모듈을 위해 특별히 설계된 ResNet-152보다 성능이 뛰어납니다. Transformer의 중요한 응용 프로그램 . 팀은 M2-GPT라고 불리는 인과 언어 모델링을 위한 M2 기반 아키텍처를 개발했습니다.
시퀀스 믹서의 경우 M2-GPT는 현재 최첨단 어텐션 프리 언어 모델인 하이에나의 컨벌루션 필터와 H3의 매개변수는 롱 전체에서 공유됩니다. 그들은 이러한 아키텍처의 FFT를 인과 매개변수화로 대체하고 MLP 계층을 완전히 제거했습니다. 결과 아키텍처에는 주의가 전혀 없고 MLP도 전혀 없습니다.
인과 언어 모델링을 위한 표준 데이터세트인 PILE에서 M2-GPT를 사전 훈련했습니다. 결과를 표 8에 나타내었다.
새로운 아키텍처를 기반으로 한 모델은 Attention과 MLP가 전혀 없지만 사전 훈련된 Perplexity 지수에서는 Transformer와 Hyena보다 여전히 우수한 성능을 보이는 것을 볼 수 있습니다. 이러한 결과는 Transformer와 매우 다른 모델이 인과 언어 모델링에서도 탁월한 성능을 발휘할 수 있음을 시사합니다.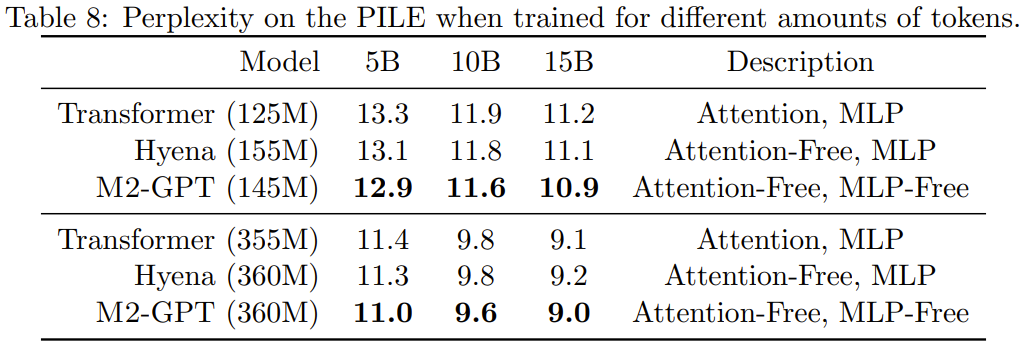
자세한 내용은 원문을 참고해주세요
위 내용은 Transformer보다 Attention 및 MLP가 없는 BERT 및 GPT가 실제로 더 강력합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



