

몇 가지 조정만으로 대형 모델 지원 컨텍스트 크기를 16,000개 토큰에서100만으로 확장할 수 있습니까? !
아직도LLaMA 2에는 70억 개의 매개변수만 있습니다.
현재 인기 있는 Claude 2와 GPT-4도 100,000과 32,000의 컨텍스트 길이만 지원한다는 점을 알아야 합니다. 이 범위를 벗어나면 대형 모델은 말도 안 되는 말을 하기 시작하고 내용을 기억하지 못하게 됩니다.
이제 푸단대학교와 상하이 인공 지능 연구소의 새로운 연구에서는 일련의 대형 모델에 대해 컨텍스트 창의 길이를 늘리는 방법을 찾았을 뿐만 아니라규칙도 발견했습니다.

이 규칙에 따르면1개의 하이퍼 매개변수만 조정하면,대형 모델의 외삽 성능을 안정적으로 향상시키면서출력 효과를 보장할 수 있습니다.
외삽이란 대형 모델의 입력 길이가 사전 훈련된 텍스트의 길이를 초과할 때 출력 성능의 변화를 의미합니다. 외삽 능력이 좋지 않은 경우 입력 길이가 사전 훈련된 텍스트의 길이를 초과하면 대형 모델은 "말도 안 되는 소리"를 합니다.
그렇다면 대형 모델의 외삽 기능을 정확히 향상시킬 수 있는 것은 무엇이며, 어떻게 이를 수행합니까?
대형 모델 외삽 기능을 향상시키는 이 방법은 Transformer 아키텍처의Positional Coding이라는 모듈과 관련이 있습니다.
사실 단순 주의 메커니즘(Attention) 모듈은 서로 다른 위치에 있는 토큰을 구별할 수 없습니다. 예를 들어 "나는 사과를 먹습니다"와 "사과는 나를 먹습니다"는 눈에 차이가 없습니다.
따라서 어순 정보를 이해하고 문장의 의미를 진정으로 이해할 수 있도록 위치 인코딩을 추가해야 합니다.
현재 Transformer 위치 인코딩 방법에는 절대 위치 인코딩(위치 정보를 입력에 통합), 상대 위치 인코딩(위치 정보를 주의 점수 계산에 기록) 및 회전 위치 인코딩이 있습니다. 그중 가장 인기 있는 것은 회전 위치 인코딩(Rotational Position Encoding), 즉RoPE입니다.
RoPE는 절대 위치 인코딩을 통해 상대 위치 인코딩 효과를 달성하지만 상대 위치 인코딩에 비해 대형 모델의 추정 가능성을 더 잘 향상시킬 수 있습니다.
RoPE 위치 인코딩을 사용하여 대형 모델의 외삽 기능을 더욱 자극하는 방법도 최근 많은 연구의 새로운 방향이 되었습니다.
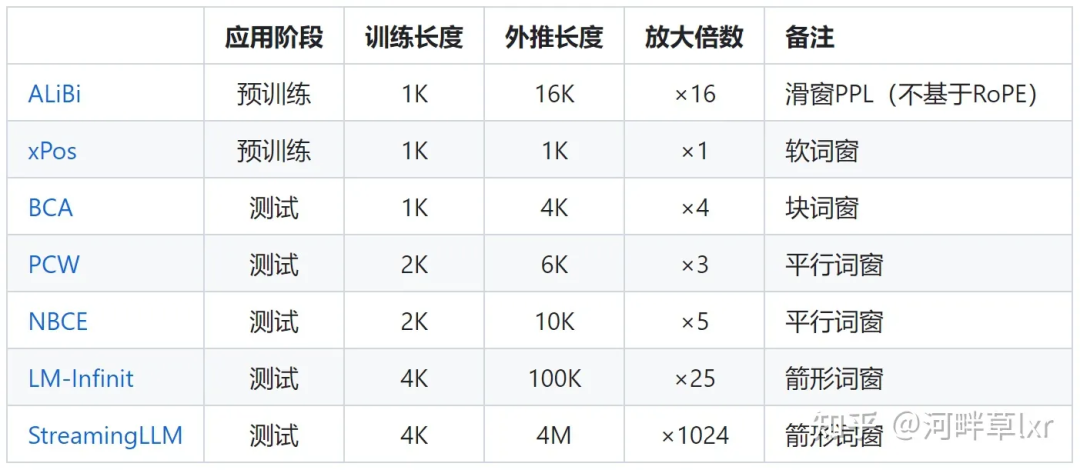
이러한 연구는 주로주의 제한과회전 각도 조정이라는 두 가지 주요 학파로 나뉩니다.
주의 제한에 관한 대표적인 연구로는 ALiBi, xPos, BCA 등이 있습니다. 최근 MIT가 제안한 StreamingLLM은 대형 모델이 무한한 입력 길이를 달성할 수 있도록 허용합니다(그러나 컨텍스트 창 길이를 늘리지는 않음). 이는 이 방향의 연구 유형에 속합니다.
Δ이미지 출처 작성자
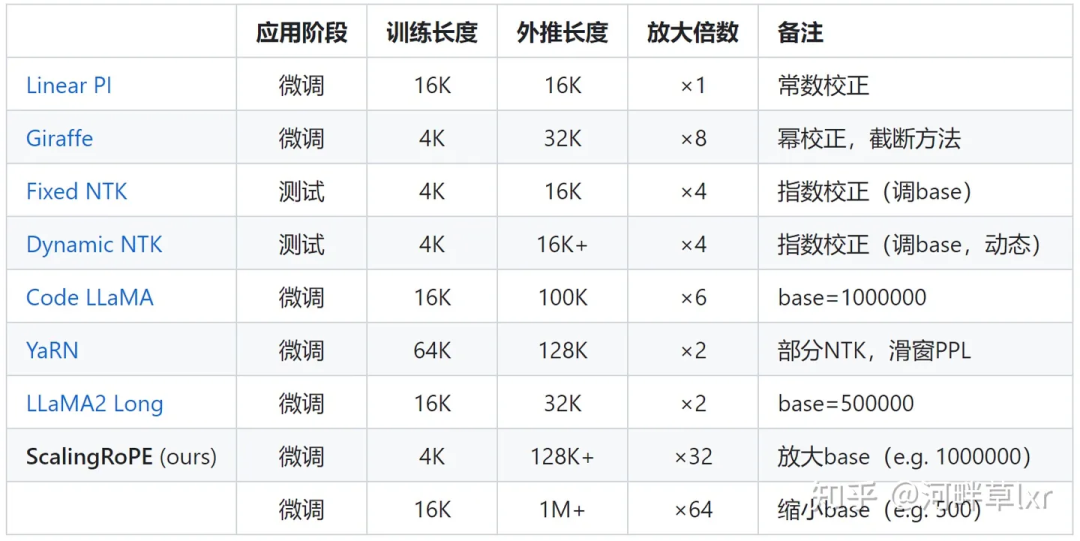
는 선형 보간, Giraffe, Code LLaMA, LLaMA2 Long 등의 일반적인 대표자가 모두 이러한 유형의 연구에 속합니다.
△원본 작성자
Meta의 최근 인기 있는 LLaMA2 Long 연구를 예로 들어, 하이퍼파라미터를 수정하여 대형 모델의 컨텍스트 길이를32,000개 토큰으로 성공적으로 확장한 RoPE ABF라는 방법을 제안했습니다.
이 하이퍼파라미터는 바로 Code LLaMA 및 LLaMA2 Long과 같은 연구에서 발견된"스위치"-
회전 각도의 기본(기본)입니다.
대형 모델의 추정 성능이 향상되도록 미세 조정하기만 하면 됩니다.
그러나 Code LLaMA이든 LLaMA2 Long이든 특정 기반과 지속적인 훈련 기간에 대해서만 미세 조정되어 외삽 기능을 향상시킵니다.
RoPE 위치 인코딩을 사용하는모든대형 모델이 외삽 성능을 안정적으로 향상시킬 수 있는 규칙을 찾을 수 있나요?
푸단대학교와 상하이 AI 연구소의 연구원들이 이 문제에 대해 실험을 진행했습니다.
그들은 먼저 RoPE 외삽 기능에 영향을 미치는 여러 매개변수를 분석하고Critical Dimension(Critical Dimension)이라는 개념을 제안했습니다. 그런 다음 이 개념을 기반으로 RoPE 기반 외삽의 확장 법칙 세트를 요약했습니다.이
법을 적용하면 RoPE 위치 인코딩을 기반으로 하는 모든 대형 모델이 추정 기능을 향상시킬 수 있습니다.먼저 임계 차원이 무엇인지 살펴보겠습니다.
정의에서 사전 학습 텍스트 길이 Ttrain, self-attention 머리 크기 수 d 및 기타 매개변수와 관련이 있으며 구체적인 계산 방법은 다음과 같습니다.
그 중 하이퍼파라미터와 회전각도 기준의 "초기값"은 10000입니다.
저자는 베이스를 확대하거나 축소하면 결국 RoPE 기반 대형 모델의 외삽 능력이 향상될 수 있음을 발견했습니다. 반면 회전 각도 베이스가 10000인 경우 대형 모델의 외삽 능력은 향상됩니다. 가장 나쁜.
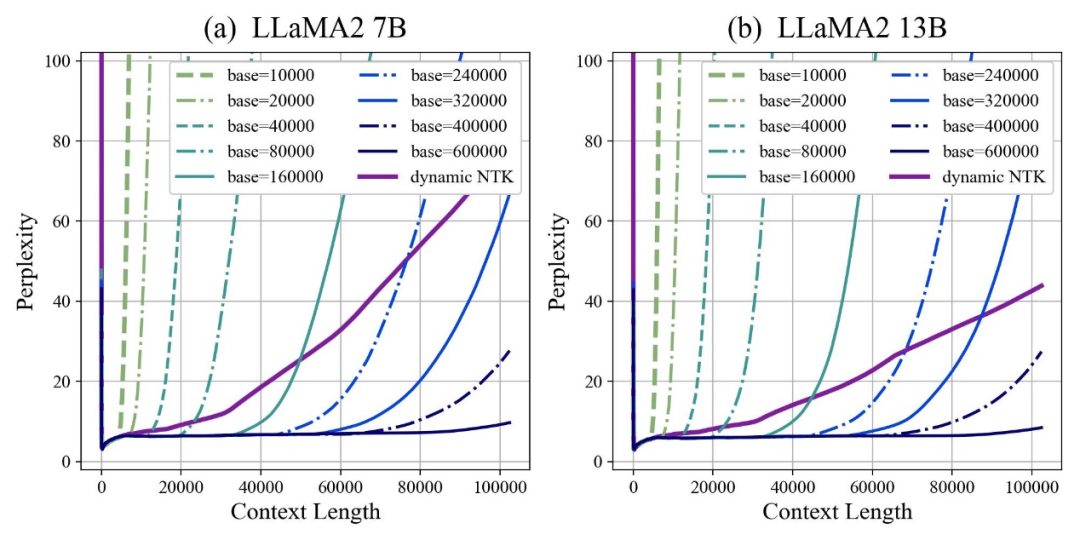
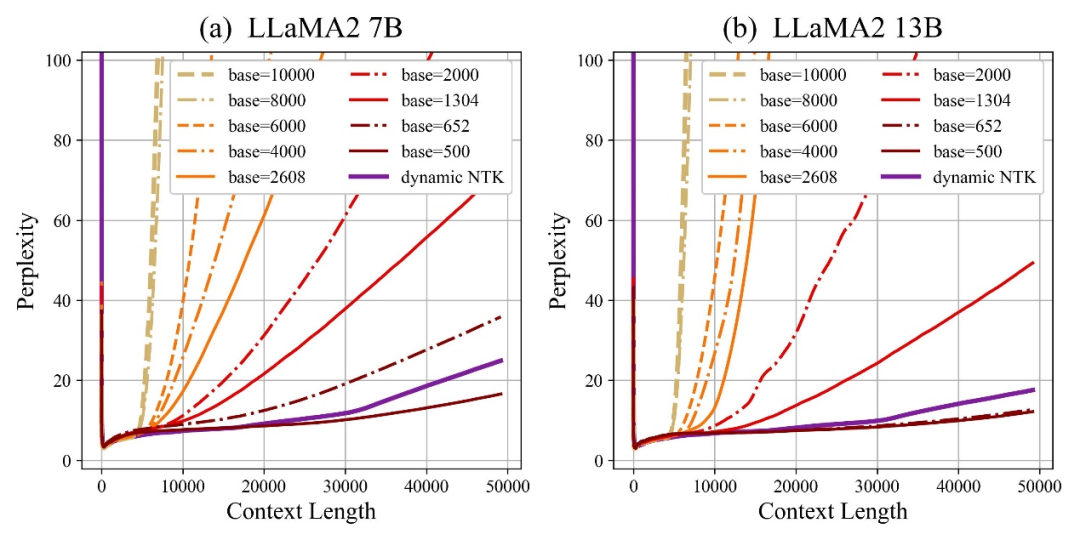
본 논문에서는 회전 각도 기준이 작을수록 위치 정보를 더 많은 차원에서 인식할 수 있고, 회전 각도 기준이 클수록 더 긴 위치 정보를 표현할 수 있다고 믿습니다.
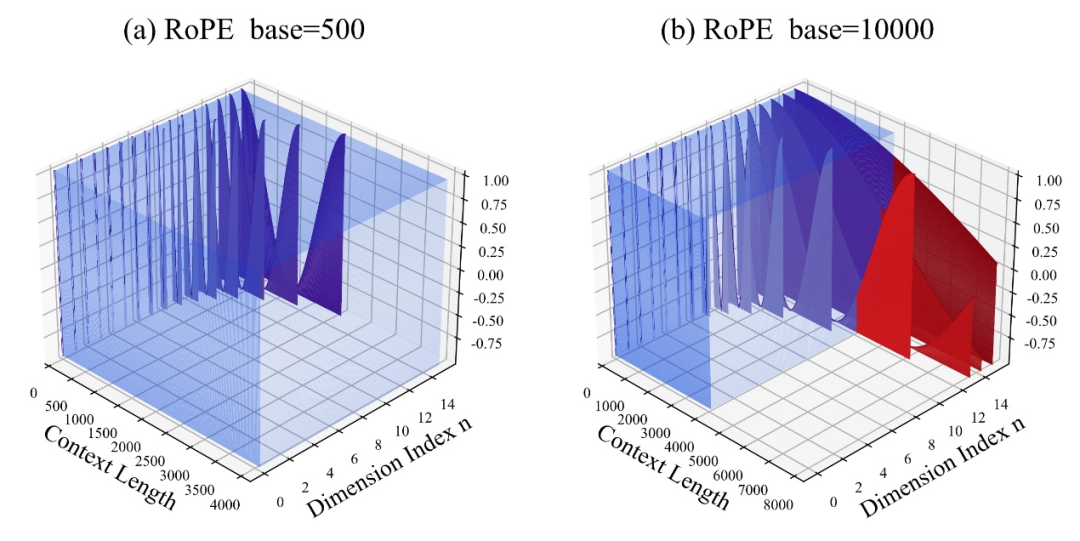
이 경우, 길이가 다른 지속적인 학습 말뭉치에 직면할 때 대형 모델의 외삽 능력을 최대화하려면 회전 각도 기반을 얼마나 줄이고 확대해야 할까요?
이 논문은 임계 차원, 지속적인 학습 텍스트 길이 및 대형 모델의 사전 학습 텍스트 길이와 같은 매개변수와 관련된 확장된 RoPE 외삽을 위한 스케일링 규칙을 제공합니다.

이 규칙에 따라 다양한 사전 학습 훈련을 수행하고 텍스트 길이를 계속 훈련하여 대형 모델의 외삽 성능을 직접 계산할 수 있습니다. 즉, 대형 모델이 지원하는 컨텍스트 길이를 예측합니다.
반대로, 이 규칙을 사용하면 회전 각도 기준을 가장 잘 조정하는 방법을 빠르게 추론할 수 있어 대형 모델의 외삽 성능이 향상됩니다.
저자는 이 일련의 작업을 테스트한 결과 실험적으로 현재 100,000, 500,000 또는 심지어 100만 개의 토큰 길이를 입력하면 추가적인 주의 제한 없이 외삽을 달성할 수 있음을 확인했습니다.
동시에 Code LLaMA 및 LLaMA2 Long을 포함한 대형 모델의 외삽 기능을 향상시키는 작업을 통해 이 규칙이 실제로 합리적이고 효과적이라는 것이 입증되었습니다.
이렇게 하면 이 규칙에 따라 "매개변수 조정"만 하면 RoPE 기반의 대형 모델의 컨텍스트 창 길이를 쉽게 확장하고 외삽 기능을 향상시킬 수 있습니다.
논문의 제1저자인 Liu Xiaoran은 현재 이 연구가 지속적인 학습 코퍼스를 개선하여 다운스트림 작업 효과를 개선하고 있다고 말했습니다. 완료되면 코드와 모델이 오픈 소스로 제공될 예정입니다~
논문 주소:
https://arxiv.org/abs/2310.05209
Github 저장소:
https://github.com/OpenLMLab/scaling-rope
종이 분석 블로그:
https://zhuanlan.zhihu.com/p/660073229
위 내용은 LLaMA2 컨텍스트 길이는 1백만 개의 토큰으로 급증하며 단 하나의 하이퍼매개변수만 조정하면 됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



