

NeRF(Neural Radiation Fields)는 딥 러닝 및 컴퓨터 비전 분야의 상당히 새로운 패러다임입니다. 이 기술은 ECCV 2020 논문 "NeRF: Representing Scenes as Neural Radiation Fields for View Synesis"(Best Paper Award 수상)에 소개되었으며, 이후 현재까지 거의 800회 인용될 정도로 인기가 폭발적으로 증가했습니다[ 1]. 이 접근 방식은 기계 학습이 3D 데이터를 처리하는 기존 방식에 큰 변화를 가져옵니다.
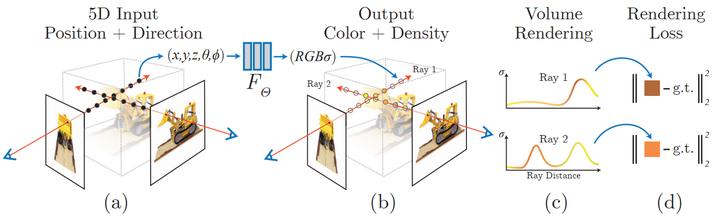
신경 방사선 장 장면 표현 및 미분 가능한 렌더링 프로세스:
카메라 광선을 따라 5D 좌표(위치 및 보기 방향)를 샘플링하여 이미지를 합성하여 이러한 위치를 MLP에 공급하여 색상 및 볼륨 밀도를 생성합니다. 볼륨 렌더링 기술은 이러한 값을 이미지로 합성합니다. 렌더링 기능은 미분 가능하므로 합성된 이미지와 실제 관찰된 이미지 간의 잔여 차이를 최소화하여 장면 표현을 최적화합니다.
NeRF는 이미지와 정확한 포즈를 조건으로 주어진 이미지에 대한 3D 장면의 새로운 뷰를 생성하는 생성 모델입니다. 이 프로세스를 종종 "새로운 뷰 합성"이라고 합니다. 뿐만 아니라 장면의 3차원 형태와 모습을 연속함수로 명확하게 정의하여 큐브를 행진시켜 3차원 메쉬를 생성할 수 있다. 이미지 데이터에서 직접 학습하지만 컨벌루션 레이어나 변환기 레이어를 사용하지 않습니다.
지난 몇 년 동안 3D 복셀부터 포인트 클라우드, 부호 있는 거리 함수에 이르기까지 기계 학습 애플리케이션에서 3D 데이터를 표현하는 방법이 많이 있었습니다. 가장 일반적인 단점은 사진 측량이나 LiDAR와 같은 도구를 사용하여 3D 데이터를 생성하거나 3D 모델을 직접 제작하여 3D 모델을 미리 가정해야 한다는 것입니다. 그러나 반사율이 높은 물체, "격자 모양" 물체 또는 투명한 물체와 같은 많은 유형의 물체는 대규모로 스캔할 수 없습니다. 3D 재구성 방법은 재구성 오류로 인해 어려움을 겪는 경우가 많으며, 이로 인해 모델 정확도에 영향을 미치는 단계 효과나 드리프트가 발생할 수 있습니다.
반대로 NeRF는 광선 광장 개념을 기반으로 합니다. 라이트 필드는 3D 볼륨 전체에서 빛의 전송이 어떻게 발생하는지 설명하는 기능입니다. 이는 공간의 각 x = (x, y, z) 좌표에서 광선이 이동하는 방향과 각 방향 d에서 θ 및 ξ 각도 또는 단위 벡터로 설명되는 방향을 설명합니다. 이들은 함께 3D 장면의 빛 투과를 설명하는 5D 기능 공간을 형성합니다. 이 표현에서 영감을 받아 NeRF는 이 공간을 색상 c = (R, G, B)와 밀도(밀도) σ로 구성된 4D 공간으로 매핑하는 함수를 근사화하려고 시도합니다. 이는 이 5D 좌표 공간으로 생각할 수 있습니다. 광선이 종료될 가능성(예: 폐색에 의해) 따라서 표준 NeRF는 F: (x, d) -> (c, σ) 형식의 함수입니다.
원본 NeRF 논문은 알려진 포즈가 있는 이미지 세트에 대해 훈련된 다층 퍼셉트론을 사용하여 이 기능을 매개변수화했습니다. 이는 이미지 모음에서 직접 3D 장면을 설명하는 것을 목표로 하는 일반화된 장면 재구성이라는 기술 클래스 중 하나입니다. 이 접근 방식에는 다음과 같은 몇 가지 매우 유용한 속성이 있습니다.
이후 퓨샷 및 싱글샷 학습[2, 3], 동적 장면 지원[4, 5], 라이트 필드 일반화를 기능에 통합하는 등 일련의 개선 논문이 등장했습니다. 필드[6], 웹의 보정되지 않은 이미지 컬렉션에서 학습[7], LiDAR 데이터 통합[8], 대규모 장면 표현[9], 신경망 없이 학습[10] 등.
전반적으로 훈련된 NeRF 모델과 알려진 포즈 및 이미지 크기를 가진 카메라가 주어지면 다음 프로세스를 통해 장면을 구축합니다.
라이트 필드(많은 문서에서는 이를 "방사선 필드"로 번역하지만 번역자는 "라이트 필드"가 더 직관적이라고 믿습니다) 기능은 일단 결합되면 여러 구성 요소 중 하나일 뿐이며, 이를 만들 수 있습니다. 이전에 비디오에서 보았던 시각 효과. 전체적으로 이 문서에는 다음 부분이 포함되어 있습니다.
의 명확성을 최대화하기 위해 설명과 관련하여 이 문서에서는 가능한 가장 간결한 코드로 각 구성 요소의 핵심 요소를 표시합니다. bmild의 원래 구현과 Yenchenlin 및 krrish94의 PyTorch 구현을 참조합니다.
2017년에 소개된 변압기 모델[11]과 마찬가지로 NeRF도 위치 인코더를 입력으로 활용하는 이점을 누리고 있습니다. 고주파수 함수를 사용하여 연속 입력을 고차원 공간에 매핑함으로써 모델이 데이터의 고주파수 변화를 학습할 수 있도록 하여 더 깔끔한 모델을 만듭니다. 이 방법은 저주파 함수에 대한 신경망의 편향을 우회하여 NeRF가 더 명확한 세부 정보를 나타낼 수 있도록 합니다. 저자는 ICML 2019[12]에 관한 논문을 참조합니다.
transformer의 위치 인코딩에 익숙하다면 NeRF의 관련 구현은 사인과 코사인 표현식이 교대로 반복되는 매우 표준적인 것입니다. 위치 인코더 구현:
# pyclass PositionalEncoder(nn.Module):# sine-cosine positional encoder for input points.def __init__( self,d_input: int,n_freqs: int,log_space: bool = False ):super().__init__()self.d_input = d_inputself.n_freqs = n_freqs # 是不是视线上的采样频率?self.log_space = log_spaceself.d_output = d_input * (1 + 2 * self.n_freqs)self.embed_fns = [lambda x: x] # 冒号前面的x表示函数参数,后面的表示匿名函数运算# Define frequencies in either linear or log scaleif self.log_space:freq_bands = 2.**torch.linspace(0., self.n_freqs - 1, self.n_freqs)else:freq_bands = torch.linspace(2.**0., 2.**(self.n_freqs - 1), self.n_freqs)# Alternate sin and cosfor freq in freq_bands:self.embed_fns.append(lambda x, freq=freq: torch.sin(x * freq))self.embed_fns.append(lambda x, freq=freq: torch.cos(x * freq))def forward(self, x) -> torch.Tensor:# Apply positional encoding to input.return torch.concat([fn(x) for fn in self.embed_fns], dim=-1)
생각: 이 위치 인코딩은 입력 지점을 시선의 샘플링 지점으로 인코딩합니다. 아니면 보는 각도가 다른가요? self.n_freqs가 시선의 샘플링 주파수입니까? 이러한 이해에 따르면 시선의 샘플링 위치여야 합니다. 왜냐하면 시선의 샘플링 위치가 인코딩되지 않으면 이러한 위치를 효과적으로 표현할 수 없고 해당 RGBA를 훈련할 수 없기 때문입니다.
원문에서 라이트 필드 함수는 NeRF 모델로 표현됩니다. NeRF 모델은 인코딩된 3D 점과 시야 방향을 입력으로 받아 RGBA 값을 반환하는 일반적인 다층 퍼셉트론입니다. 출력으로. 이 기사에서는 신경망을 사용하지만 여기서는 모든 함수 근사기를 사용할 수 있습니다. 예를 들어, Yu 등의 후속 논문인 Plenoxels는 구형 조화를 사용하여 경쟁력 있는 결과를 달성하면서 훨씬 더 빠른 훈련을 달성합니다[10].
 Pictures
Pictures
NeRF 모델은 깊이가 8개 레이어이고 대부분의 레이어의 피처 크기는 256입니다. 나머지 연결은 레이어 4에 배치됩니다. 이러한 레이어 이후에는 RGB 및 σ 값이 생성됩니다. RGB 값은 선형 레이어로 추가 처리된 다음 보는 방향과 연결되고 다른 선형 레이어를 통과한 다음 최종적으로 출력에서 σ와 재결합됩니다. NeRF 모델의 PyTorch 모듈 구현:
class NeRF(nn.Module):# Neural radiance fields module.def __init__( self,d_input: int = 3,n_layers: int = 8,d_filter: int = 256,skip: Tuple[int] = (4,), # (4,)只有一个元素4的元组 d_viewdirs: Optional[int] = None): super().__init__()self.d_input = d_input# 这里是3D XYZ,?self.skip = skip# 是要跳过什么?为啥要跳过?被遮挡?self.act = nn.functional.reluself.d_viewdirs = d_viewdirs# d_viewdirs 是2D方向?# Create model layers# [if_true 就执行的指令] if [if_true条件] else [if_false]# 是否skip的区别是,训练输入维度是否多3维,# if i in skip =if i in (4,),似乎是判断i是否等于4# self.d_input=3 :如果层id=4,网络输入要加3维,这是为什么?第4层有何特殊的?self.layers = nn.ModuleList([nn.Linear(self.d_input, d_filter)] +[nn.Linear(d_filter + self.d_input, d_filter) if i in skip else \ nn.Linear(d_filter, d_filter) for i in range(n_layers - 1)])# Bottleneck layersif self.d_viewdirs is not None:# If using viewdirs, split alpha and RGBself.alpha_out = nn.Linear(d_filter, 1)self.rgb_filters = nn.Linear(d_filter, d_filter)self.branch = nn.Linear(d_filter + self.d_viewdirs, d_filter // 2)self.output = nn.Linear(d_filter // 2, 3) # 为啥要取一半?else:# If no viewdirs, use simpler outputself.output = nn.Linear(d_filter, 4) # d_filter=256,输出是4维RGBAdef forward(self,x: torch.Tensor, # ?viewdirs: Optional[torch.Tensor] = None) -> torch.Tensor: # Forward pass with optional view direction.if self.d_viewdirs is None and viewdirs is not None:raise ValueError('Cannot input x_direction')# Apply forward pass up to bottleneckx_input = x# 这里的x是几维?从下面的分离RGB和A看,应该是4D# 下面通过8层MLP训练RGBAfor i, layer in enumerate(self.layers):# 8层,每一层进行运算x = self.act(layer(x)) if i in self.skip:x = torch.cat([x, x_input], dim=-1)# Apply bottleneckbottleneck 瓶颈是啥?是不是最费算力的模块?if self.d_viewdirs is not None:# 从网络输出分离A,RGB还需要经过更多训练alpha = self.alpha_out(x)# Pass through bottleneck to get RGBx = self.rgb_filters(x) x = torch.concat([x, viewdirs], dim=-1)x = self.act(self.branch(x)) # self.branch shape: (d_filter // 2)x = self.output(x) # self.output shape: (3)# Concatenate alphas to outputx = torch.concat([x, alpha], dim=-1)else:# Simple outputx = self.output(x)return x생각: 이 NERF 클래스의 입력과 출력은 무엇입니까? 이 수업을 통해 어떤 일이 일어나나요? __init__ 함수의 매개변수를 보면 신경망의 입력, 레벨, 차원을 주로 설정하는 것을 알 수 있는데, 5D 데이터는 입력 즉 시점 위치와 시선 방향이고 출력은 RGBA이다. 질문 출력 RGBA가 1포인트인가요? 아니면 일련의 시선인가? 시리즈인 경우 위치 코딩이 각 샘플링 지점의 RGBA를 어떻게 결정하는지 보지 못했습니까? 샘플링 간격과 같은 지침을 본 적이 없습니다. 이 RGBA가 속한 것은 무엇입니까? 눈에 보이는 시력 샘플링 포인트를 모아놓은 결과가 포인트 RGBA인가요? NERF 클래스 코드를 보면 주로 시점 위치와 시선 방향을 기준으로 다층 피드포워드 학습이 수행되는 것을 알 수 있으며, 5차원 시점 위치와 시선 방향을 입력받아 4차원 RGBA를 출력한다.
3.3 미분 가능한 볼륨 렌더러
원본 NeRF 모델 출력의 볼륨 렌더링:
def raw2outputs(raw: torch.Tensor,z_vals: torch.Tensor,rays_d: torch.Tensor,raw_noise_std: float = 0.0,white_bkgd: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:# 将原始的NeRF输出转为RGB和其他映射# Difference between consecutive elements of `z_vals`. [n_rays, n_samples]dists = z_vals[..., 1:] - z_vals[..., :-1]# ?这里减法的意义是啥?dists = torch.cat([dists, 1e10 * torch.ones_like(dists[..., :1])], dim=-1)# 将每个距离乘以其对应方向光线的范数,以转换为真实世界的距离(考虑非单位方向)dists = dists * torch.norm(rays_d[..., None, :], dim=-1)# 将噪声添加到模型对密度的预测中,用于在训练期间规范网络(防止漂浮物伪影)noise = 0.if raw_noise_std > 0.:noise = torch.randn(raw[..., 3].shape) * raw_noise_std# Predict density of each sample along each ray. Higher values imply# higher likelihood of being absorbed at this point. [n_rays, n_samples]alpha = 1.0 - torch.exp(-nn.functional.relu(raw[..., 3] + noise) * dists)# Compute weight for RGB of each sample along each ray. [n_rays, n_samples]# The higher the alpha, the lower subsequent weights are driven.weights = alpha * cumprod_exclusive(1. - alpha + 1e-10)# Compute weighted RGB map.rgb = torch.sigmoid(raw[..., :3])# [n_rays, n_samples, 3]rgb_map = torch.sum(weights[..., None] * rgb, dim=-2)# [n_rays, 3]# Estimated depth map is predicted distance.depth_map = torch.sum(weights * z_vals, dim=-1)# Disparity map is inverse depth.disp_map = 1. / torch.max(1e-10 * torch.ones_like(depth_map),depth_map / torch.sum(weights, -1))# Sum of weights along each ray. In [0, 1] up to numerical error.acc_map = torch.sum(weights, dim=-1)# To composite onto a white background, use the accumulated alpha map.if white_bkgd:rgb_map = rgb_map + (1. - acc_map[..., None])return rgb_map, depth_map, acc_map, weightsdef cumprod_exclusive(tensor: torch.Tensor) -> torch.Tensor:# (Courtesy of https://github.com/krrish94/nerf-pytorch)# Compute regular cumprod first.cumprod = torch.cumprod(tensor, -1)# "Roll" the elements along dimension 'dim' by 1 element.cumprod = torch.roll(cumprod, 1, -1)# Replace the first element by "1" as this is what tf.cumprod(..., exclusive=True) does.cumprod[..., 0] = 1.return cumprod
질문: 여기서 주요 기능은 무엇입니까? 무엇이 입력되었나요? 출력이란 무엇입니까?
3.4 층화된 샘플링
Pictures PyTorch에서 구현된 계층적 샘플링:
PyTorch에서 구현된 계층적 샘플링:
def sample_stratified(rays_o: torch.Tensor,rays_d: torch.Tensor,near: float,far: float,n_samples: int,perturb: Optional[bool] = True,inverse_depth: bool = False) -> Tuple[torch.Tensor, torch.Tensor]:# Sample along ray from regularly-spaced bins.# Grab samples for space integration along rayt_vals = torch.linspace(0., 1., n_samples, device=rays_o.device)if not inverse_depth:# Sample linearly between `near` and `far`z_vals = near * (1.-t_vals) + far * (t_vals)else:# Sample linearly in inverse depth (disparity)z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))# Draw uniform samples from bins along rayif perturb:mids = .5 * (z_vals[1:] + z_vals[:-1])upper = torch.concat([mids, z_vals[-1:]], dim=-1)lower = torch.concat([z_vals[:1], mids], dim=-1)t_rand = torch.rand([n_samples], device=z_vals.device)z_vals = lower + (upper - lower) * t_randz_vals = z_vals.expand(list(rays_o.shape[:-1]) + [n_samples])# Apply scale from `rays_d` and offset from `rays_o` to samples# pts: (width, height, n_samples, 3)pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals[..., :, None]return pts, z_vals
3.5 Hierarchical Volume Sampling(Hierarchical Volume Sampling)
这种“珩磨”过程是通过层次体积采样流程完成的。3D空间实际上非常稀疏,存在遮挡,因此大多数点对渲染图像的贡献不大。因此,对具有对积分贡献可能性高的区域进行过采样(oversample)更有好处。他们将学习到的归一化权重应用于第一组样本,以在光线上创建PDF,然后再将inverse transform sampling应用于该PDF以收集第二组样本。该集合与第一集合相结合,并被馈送到精细网络以产生最终输出。
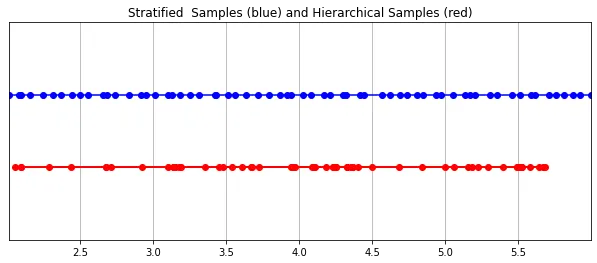
分层采样PyTorch实现:
def sample_hierarchical(rays_o: torch.Tensor,rays_d: torch.Tensor,z_vals: torch.Tensor,weights: torch.Tensor,n_samples: int,perturb: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:# Apply hierarchical sampling to the rays.# Draw samples from PDF using z_vals as bins and weights as probabilities.z_vals_mid = .5 * (z_vals[..., 1:] + z_vals[..., :-1])new_z_samples = sample_pdf(z_vals_mid, weights[..., 1:-1], n_samples, perturb=perturb)new_z_samples = new_z_samples.detach()# Resample points from ray based on PDF.z_vals_combined, _ = torch.sort(torch.cat([z_vals, new_z_samples], dim=-1), dim=-1)# [N_rays, N_samples + n_samples, 3]pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals_combined[..., :, None]return pts, z_vals_combined, new_z_samplesdef sample_pdf(bins: torch.Tensor, weights: torch.Tensor, n_samples: int, perturb: bool = False) -> torch.Tensor:# Apply inverse transform sampling to a weighted set of points.# Normalize weights to get PDF.# [n_rays, weights.shape[-1]]pdf = (weights + 1e-5) / torch.sum(weights + 1e-5, -1, keepdims=True) # Convert PDF to CDF.cdf = torch.cumsum(pdf, dim=-1) # [n_rays, weights.shape[-1]]# [n_rays, weights.shape[-1] + 1]cdf = torch.concat([torch.zeros_like(cdf[..., :1]), cdf], dim=-1) # Take sample positions to grab from CDF. Linear when perturb == 0.if not perturb:u = torch.linspace(0., 1., n_samples, device=cdf.device)u = u.expand(list(cdf.shape[:-1]) + [n_samples]) # [n_rays, n_samples]else:# [n_rays, n_samples]u = torch.rand(list(cdf.shape[:-1]) + [n_samples], device=cdf.device) # Find indices along CDF where values in u would be placed.u = u.contiguous() # Returns contiguous tensor with same values.inds = torch.searchsorted(cdf, u, right=True) # [n_rays, n_samples]# Clamp indices that are out of bounds.below = torch.clamp(inds - 1, min=0)above = torch.clamp(inds, max=cdf.shape[-1] - 1)inds_g = torch.stack([below, above], dim=-1) # [n_rays, n_samples, 2]# Sample from cdf and the corresponding bin centers.matched_shape = list(inds_g.shape[:-1]) + [cdf.shape[-1]]cdf_g = torch.gather(cdf.unsqueeze(-2).expand(matched_shape), dim=-1,index=inds_g)bins_g = torch.gather(bins.unsqueeze(-2).expand(matched_shape), dim=-1, index=inds_g)# Convert samples to ray length.denom = (cdf_g[..., 1] - cdf_g[..., 0])denom = torch.where(denom <h3>4 Training</h3><p>论文中训练NeRF推荐的每网络8层、每层256维的架构在训练过程中会消耗大量内存。缓解这种情况的方法是将前传(forward pass)分成更小的部分,然后在这些部分上积累梯度。注意与minibatching的区别:梯度是在采样光线的单个小批次上累积的,这些光线可能已经被收集成块。如果没有论文中使用的NVIDIA V100类似性能的GPU,可能必须相应地调整块大小以避免OOM错误。Colab笔记本采用了更小的架构和更适中的分块尺寸。</p><p>我个人发现,由于局部极小值,即使选择了许多默认值,NeRF的训练也有些棘手。一些有帮助的技术包括早期训练迭代和早期重新启动期间的中心裁剪(center cropping)。随意尝试不同的超参数和技术,以进一步提高训练收敛性。</p><h4>初始化</h4><pre class="brush:php;toolbar:false">def init_models():# Initialize models, encoders, and optimizer for NeRF training.encoder = PositionalEncoder(d_input, n_freqs, log_space=log_space)encode = lambda x: encoder(x)# View direction encodersif use_viewdirs:encoder_viewdirs = PositionalEncoder(d_input, n_freqs_views,log_space=log_space)encode_viewdirs= lambda x: encoder_viewdirs(x)d_viewdirs = encoder_viewdirs.d_outputelse:encode_viewdirs = Noned_viewdirs = Nonemodel = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)model.to(device)model_params = list(model.parameters())if use_fine_model:fine_model = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)fine_model.to(device)model_params = model_params + list(fine_model.parameters())else:fine_model = Noneoptimizer= torch.optim.Adam(model_params, lr=lr)warmup_stopper = EarlyStopping(patience=50)return model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper
def train():# Launch training session for NeRF.# Shuffle rays across all images.if not one_image_per_step:height, width = images.shape[1:3]all_rays = torch.stack([torch.stack(get_rays(height, width, focal, p), 0) for p in poses[:n_training]], 0)rays_rgb = torch.cat([all_rays, images[:, None]], 1)rays_rgb = torch.permute(rays_rgb, [0, 2, 3, 1, 4])rays_rgb = rays_rgb.reshape([-1, 3, 3])rays_rgb = rays_rgb.type(torch.float32)rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0train_psnrs = []val_psnrs = []iternums = []for i in trange(n_iters):model.train()if one_image_per_step:# Randomly pick an image as the target.target_img_idx = np.random.randint(images.shape[0])target_img = images[target_img_idx].to(device)if center_crop and i = rays_rgb.shape[0]:rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0target_img = target_img.reshape([-1, 3])# Run one iteration of TinyNeRF and get the rendered RGB image.outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)# Backprop!rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, target_img)loss.backward()optimizer.step()optimizer.zero_grad()psnr = -10. * torch.log10(loss)train_psnrs.append(psnr.item())# Evaluate testimg at given display rate.if i % display_rate == 0:model.eval()height, width = testimg.shape[:2]rays_o, rays_d = get_rays(height, width, focal, testpose)rays_o = rays_o.reshape([-1, 3])rays_d = rays_d.reshape([-1, 3])outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, testimg.reshape(-1, 3))val_psnr = -10. * torch.log10(loss)val_psnrs.append(val_psnr.item())iternums.append(i)# Check PSNR for issues and stop if any are found.if i == warmup_iters - 1:if val_psnr <h4>训练</h4><pre class="brush:php;toolbar:false"># Run training session(s)for _ in range(n_restarts):model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper = init_models()success, train_psnrs, val_psnrs = train()if success and val_psnrs[-1] >= warmup_min_fitness:print('Training successful!')breakprint(f'Done!')辐射场标志着处理3D数据的方式发生了巨大变化。NeRF模型和更广泛的可微分渲染正在迅速弥合图像创建和体积场景创建之间的差距。虽然我们的组件可能看起来非常复杂,但受vanilla NeRF启发的无数其他方法证明,基本概念(连续函数逼近器+可微分渲染器)是构建各种解决方案的坚实基础,这些解决方案可用于几乎无限的情况。
原文:NeRF From Nothing: A Tutorial with PyTorch | Towards Data Science
原文链接:https://mp.weixin.qq.com/s/zxJAIpAmLgsIuTsPqQqOVg
위 내용은 NeRF란 무엇입니까? NeRF 기반 3D 재구성은 복셀 기반인가요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



