

본 글은 자율주행하트 공개 계정의 승인을 받아 재인쇄되었습니다.
원제: MotionLM: Multi-Agent Motion Forecasting as Language Modeling
논문 링크: https://arxiv.org/pdf/2309.16534.pdf
저자 단위: Waymo
컨퍼런스: ICCV 2023

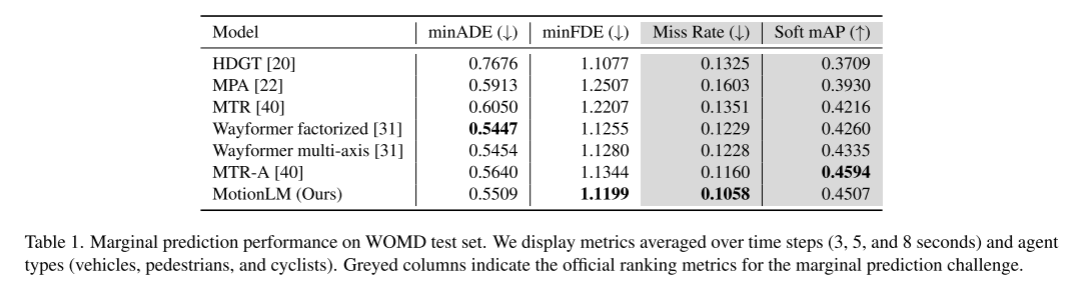
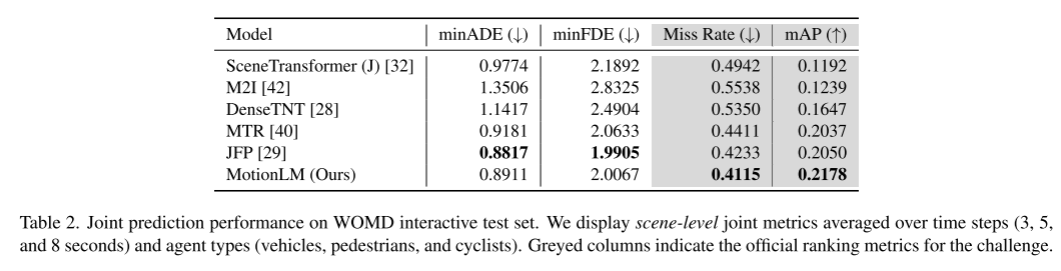
자율주행 자동차 안전 계획을 위해서는 도로 요원의 미래 행동을 확실하게 예측하는 것이 중요합니다. 본 연구는 연속적인 궤적을 개별 모션 토큰의 시퀀스로 표현하고 다중 에이전트 모션 예측을 언어 모델링 작업으로 처리합니다. 제안된 모델인 MotionLM에는 몇 가지 장점이 있습니다. 첫째, 다중 모드 분포를 최적으로 학습하기 위해 앵커 포인트나 명시적 잠재 변수를 사용할 필요가 없습니다. 대신, 시퀀스 토큰의 평균 로그 확률을 최대화한다는 표준 언어 모델링 목표를 활용합니다. 둘째, 우리의 접근 방식은 상호 작용 채점 후 개별 에이전트 궤적 생성이 발생하는 사후 상호 작용 휴리스틱을 피합니다. 이와 대조적으로 MotionLM은 단일 자동 회귀 디코딩 프로세스에서 대화형 에이전트 미래의 공동 분포를 생성합니다. 또한, 모델의 순차적 분해를 통해 시간적 인과조건 추론이 가능합니다. 우리가 제안한 방법은 Waymo Open Motion Dataset에서 새로운 최첨단 성능을 달성하여 대화형 챌린지 리더보드에서 1위를 차지했습니다
이 기사에서는 다중 에이전트 모션 예측을 A 언어로 제시합니다. 모델링 작업이 논의됩니다. 인과 언어 모델링 손실로 훈련된 개별 모션 토큰을 디코딩하기 위한 시간 인과 디코더를 소개합니다.
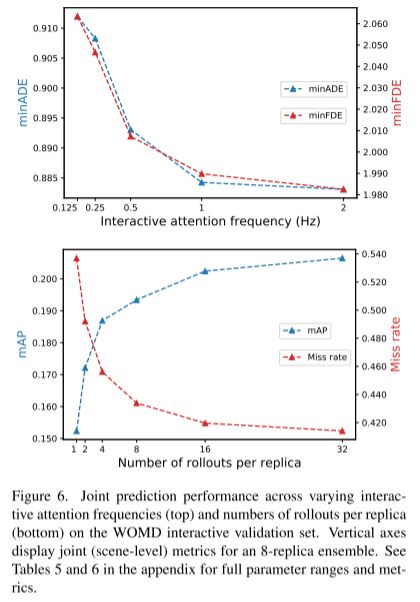
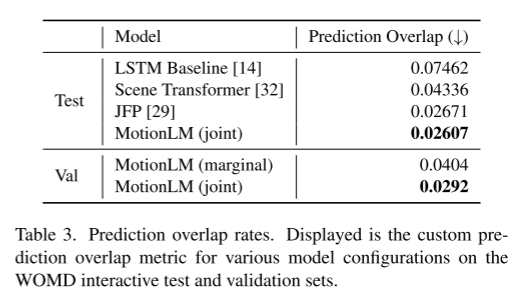
이 문서에서는 모델의 샘플링을 간단한 롤아웃 집계 방식과 결합하여 관절 궤적의 가중 패턴 인식 기능을 향상시킵니다. Waymo Open Motion Dataset 상호 작용 예측 챌린지의 실험을 통해 우리는 이 새로운 방법이 순위 공동 mAP 지표를 6% 향상시키고 최첨단 성능 수준에 도달함을 입증했습니다
이 문서에서는 우리 방법에 대한 광범위한 검토를 수행합니다. 절제 실험을 수행하고 현재의 공동 예측 모델에서는 크게 지원되지 않는 시간적 인과 조건부 예측을 분석합니다.
이 문서의 목표는 최소, 공동 및 조건부 예측을 포함한 다양한 다운스트림 작업에 적용할 수 있는 일반적인 방식으로 다중 에이전트 상호 작용에 대한 분포를 모델링하는 것입니다. 이 목표를 달성하려면 운전 시나리오에서 다양한 형태를 포착할 수 있는 표현적 생성 프레임워크가 필요합니다. 또한 여기서는 시간 종속성 절약을 고려합니다. 즉, 모델에서 추론은 방향성 비순환 그래프를 따르며, 각 노드의 상위 노드는 시간상 더 빠르며 하위 노드는 시간상 더 늦습니다. 이는 조건부 예측이 인과관계에 더 가깝습니다. 왜냐하면 시간적 인과관계에 대한 불복종으로 이어질 수 있는 특정 가짜 상관관계를 제거하기 때문입니다. 이 문서에서는 시간적 종속성을 보존하지 않는 공동 모델이 계획의 핵심 용도인 실제 에이전트 응답을 예측하는 능력이 제한적일 수 있음을 관찰합니다. 이를 위해 이 논문은 에이전트의 모션 토큰이 이전에 샘플링된 모든 토큰에 조건부로 의존하고 궤적이 순차적으로 파생되는 미래 디코더의 자동 회귀 분해를 활용합니다
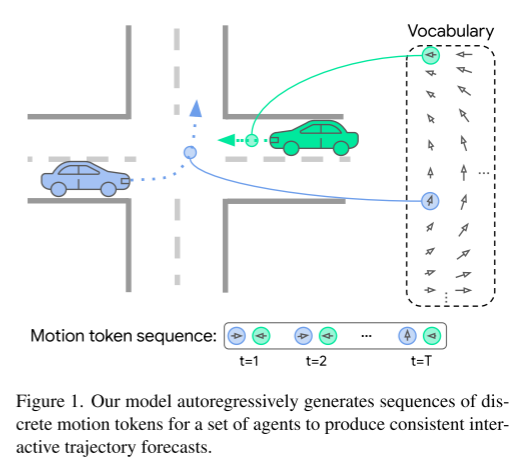
그림 1. 우리 모델은 일련의 에이전트에 대한 개별 모션 토큰 시퀀스를 자동 회귀적으로 생성하여 일관된 대화형 궤적 예측을 생성합니다.
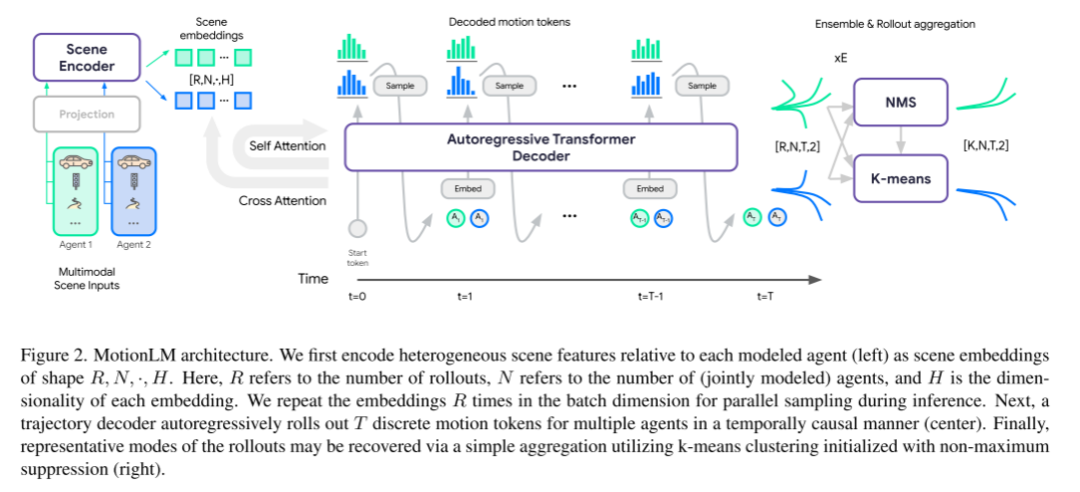
MotionLM의 아키텍처인 그림 2를 참조하세요
이 논문은 먼저 각 모델링 에이전트와 관련된 이종 장면 특징(왼쪽)을 R, N,·,H 모양의 장면 임베딩으로 인코딩합니다. 그 중 R은 롤아웃 수, N은 공동 모델링된 에이전트 수, H는 각 임베딩의 차원입니다. 추론 과정에서 샘플링을 병렬화하기 위해 본 논문에서는 배치 차원에 임베딩을 R번 반복합니다. 다음으로, 궤적 디코더는 시간적으로 인과적인 방식으로 여러 에이전트에 대해 T개의 개별 모션 토큰을 롤아웃합니다(가운데). 마지막으로, 비최대 억제 초기화(오른쪽 패널)를 사용하여 k-평균 클러스터의 간단한 집계를 통해 일반적인 롤아웃 패턴을 복구할 수 있습니다.
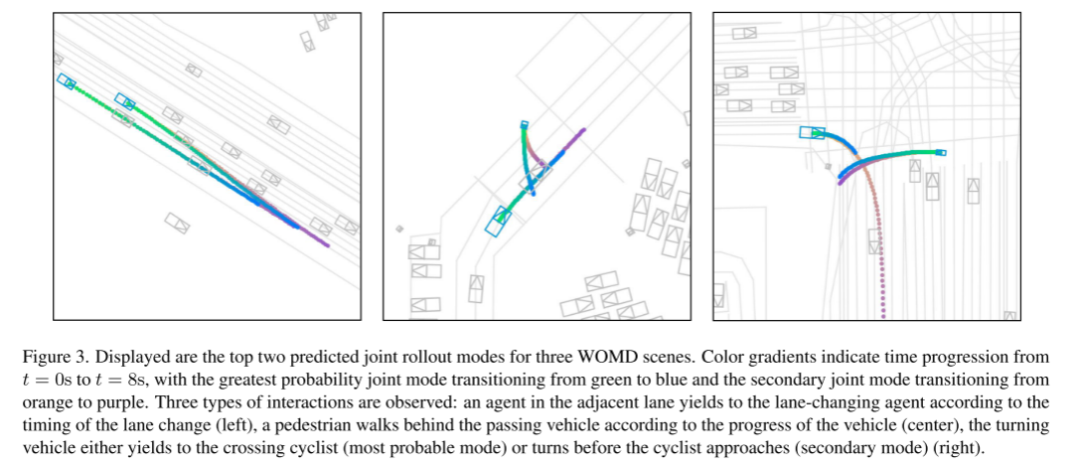
사진 3. 세 가지 WOMD 시나리오에 대한 처음 두 가지 예측 공동 롤아웃 모드가 표시됩니다.
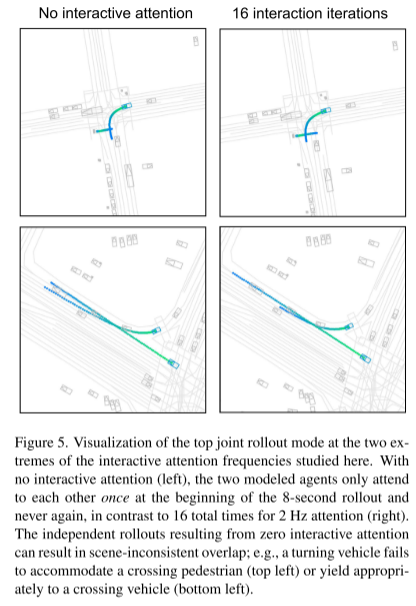
색상 그라데이션은 t = 0초에서 t = 8초까지의 시간 변화를 나타냅니다. 관절 모드는 녹색에서 파란색으로 전환되며, 하위 관절 모드는 가장 높은 확률로 주황색에서 보라색으로 전환됩니다. 우리는 세 가지 유형의 상호 작용을 관찰했습니다. 인접한 차선에 있는 에이전트는 차선 변경 시간에 따라 차선 변경 에이전트에게 양보하고(왼쪽), 보행자는 차량의 진행 상황에 따라 지나가는 차량 뒤로 걸어가고(가운데) 회전 차량은 지나가는 자전거 운전자에게 양보하거나(대부분 모드) 자전거 운전자가 접근하기 전에 회전합니다(보통 모드)(오른쪽)
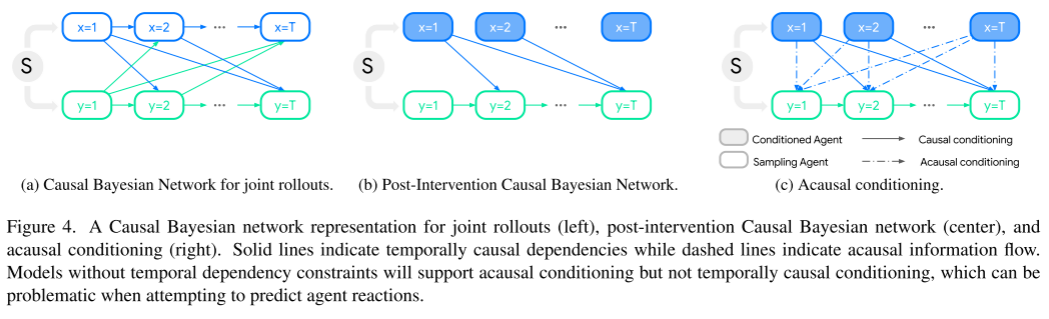
그림 4를 참조하세요. 이 그림은 공동 유도(왼쪽), 개입 후 인과 베이지안 네트워크(가운데) 및 인과 조건화(오른쪽)의 인과 베이지안 네트워크 표현을 보여줍니다.
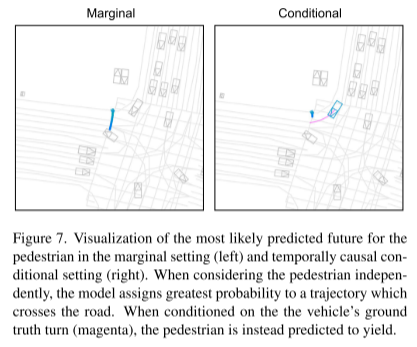
실선은 시간에 따른 인과 관계를 나타내고 점선은 인과 정보 흐름을 나타냅니다. 시간 종속적 제약이 없는 모델은 인과적 조건화를 지원하지만 시간적 인과적 조건화는 지원하지 않습니다. 이는 에이전트 반응을 예측하려고 할 때 문제가 될 수 있습니다.

Seff, A., Cera, B., Chen, D. , Ng, M., Zhou, A., Nayakanti, N., Refaat, K. S., & Sapp, B. (2023). MotionLM: 언어 모델링을 통한 다중 에이전트 모션 예측. ArXiv.
 원본 링크: https://mp.weixin.qq.com/s/MTai0rA8PeNFuj7UjCfd6A
원본 링크: https://mp.weixin.qq.com/s/MTai0rA8PeNFuj7UjCfd6A
위 내용은 MotionLM: 다중 에이전트 모션 예측을 위한 언어 모델링 기술의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



