


현재 자율주행차에는 라이더, 밀리미터파 레이더, 카메라 센서 등 다양한 정보 수집 센서가 탑재되어 있습니다. 현재의 관점에서 볼 때, 자율주행의 인식 작업에서 다양한 센서가 큰 발전 가능성을 보여주었습니다. 예를 들어, 카메라를 통해 수집된 2D 이미지 정보는 풍부한 의미론적 특징을 포착하고, LiDAR가 수집한 포인트 클라우드 데이터는 인식 모델에 객체의 정확한 위치 정보와 기하학적 정보를 제공할 수 있습니다. 다양한 센서에서 얻은 정보를 최대한 활용함으로써 자율주행 인지 과정에서 불확실성 요인의 발생을 줄이는 동시에 인지 모델의 감지 견고성을 향상시킬 수 있습니다. 오늘은 Megvii의 자율주행 인지 논문을 소개합니다. 올해 ICCV2023 Visual Conference에 채택되었습니다. 이 기사의 주요 특징은 PETR과 유사한 End-to-End BEV 인식 알고리즘입니다(인식 결과에서 중복 상자를 필터링하기 위해 더 이상 NMS 후처리 작업을 사용할 필요가 없습니다). ) 동시에 모델의 인식 성능을 향상시키기 위해 LiDAR의 포인트 클라우드 정보가 추가로 사용됩니다. 기사 및 공식 오픈 소스 창고에 대한 링크는 매우 좋습니다. 링크는 다음과 같습니다:
논문 링크: https:/ /arxiv.org/pdf/2301.01283.pdf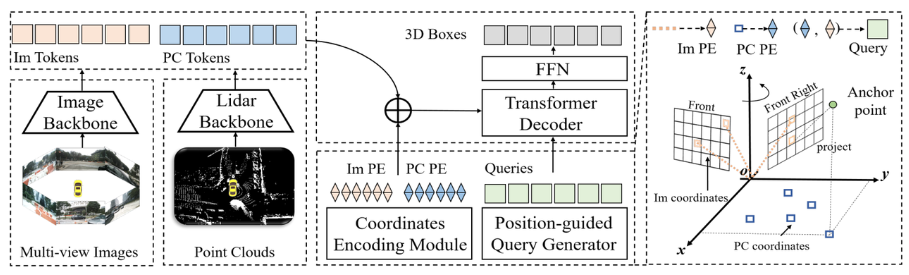 전체 알고리즘 블록 다이어그램에서 볼 수 있듯이 전체 알고리즘 모델에는 주로 다음이 포함됩니다. 세 부분
전체 알고리즘 블록 다이어그램에서 볼 수 있듯이 전체 알고리즘 모델에는 주로 다음이 포함됩니다. 세 부분
Lidar 백본 네트워크 + 카메라 백본 네트워크 (이미지 백본 + Lidar 백본)
Lidar 백본 네트워크텐서([bs * N, 1024, H / 16, W / 16])Tensor([bs * N, 1024, H / 16, W / 16])
Tensor([bs * N,2048,H / 16,W / 16])
需要重新写的内容是:张量([bs * N,256,H / 16,W / 16])
텐서([bs *N, 2048, H/16, W/16])
다시 작성해야 하는 콘텐츠는 다음과 같습니다: 텐서([bs * N, 256, H/16, W/16])
입력 텐서: 텐서([bs * N, 3, H, W])Tensor([bs * N,3,H,W])
输出张量:Tensor([bs * N,1024,H / 16,W / 16])
输出张量:``Tensor([bs * N,2048,H / 32,W / 32])`
需要进行改写的内容是:2D骨架提取图像特征
Neck(CEFPN)
根据以上介绍,位置编码的生成主要包括三个部分,分别是图像位置嵌入、点云位置嵌入和查询嵌入。下面将逐一介绍它们的生成过程
在BEV空间的网格坐标点利用pos2embed()
출력 텐서: 텐서([bs * N, 1024, H/16, W/ 16] )
다시 작성해야 하는 내용은 다음과 같습니다: 2D 뼈대 추출 이미지 기능
Neck (CEFPN)
Image Position Embedding(Im PE)Image Position Embedding의 생성 과정은 PETR의 이미지 위치 인코딩 생성 로직과 동일합니다(자세한 내용은 다음을 참조하세요). 여기서는 다루지 않을 원본 PETR 논문 너무 많은 노력이 필요함) 다음 네 단계로 요약할 수 있습니다.
3D 이미지 절두체 포인트 클라우드 카메라 내부 매개변수 매트릭스를 사용하여 카메라 좌표계로 변환하여 3D 카메라 좌표계를 얻습니다.
카메라 좌표계의 3D 포인트는 다음을 사용하여 BEV 좌표계로 변환됩니다. cam2ego 좌표 변환 행렬
Point Cloud 생성 과정 Position Embedding은 다음 두 단계로 나눌 수 있습니다
pos2embed()
# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
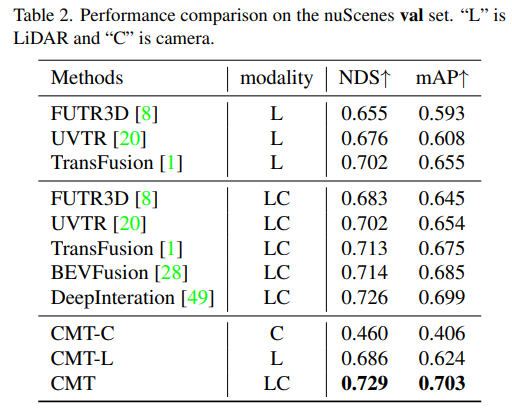
def _rv_query_embed(self, ref_points, img_metas):pad_h, pad_w = pad_shape# 由归一化坐标点映射回正常的roi range下的3D坐标点ref_points = ref_points * (pc_range[3:] - pc_range[:3]) + pc_range[:3]points = torch.cat([ref_points, ref_points.shape[:-1]], dim=-1)points = bda_mat.inverse().matmul(points)points = points.unsqueeze(1)points = sensor2ego_mats.inverse().matmul(points)points =intrin_mats.matmul(points)proj_points_clone = points.clone() # 选择有效的投影点z_mask = proj_points_clone[..., 2:3, :].detach() > 0proj_points_clone[..., :3, :] = points[..., :3, :] / (points[..., 2:3, :].detach() + z_mask * 1e-6 - (~z_mask) * 1e-6)proj_points_clone = ida_mats.matmul(proj_points_clone)proj_points_clone = proj_points_clone.squeeze(-1)mask = ((proj_points_clone[..., 0] = 0)& (proj_points_clone[..., 1] = 0))mask &= z_mask.view(*mask.shape)coords_d = (1 + torch.arange(depth_num).float() * (pc_range[4] - 1) / depth_num)projback_points = (ida_mats.inverse().matmul(proj_points_clone))projback_points = torch.einsum("bvnc, d -> bvndc", projback_points, coords_d)projback_points = torch.cat([projback_points[..., :3], projback_points.shape[:-1]], dim=-1)projback_points = (sensor2ego_mats.matmul(intrin_mats).matmul(projback_points))projback_points = (bda_mat@ projback_points)projback_points = (projback_points[..., :3] - pc_range[:3]) / (pc_range[3:] - self.pc_range[:3])rv_embeds = self.rv_embedding(projback_points)rv_embeds = (rv_embeds * mask).sum(dim=1)return rv_embeds표에서 Modality는 인식 알고리즘에 입력되는 센서 카테고리를 나타내고, C는 카메라 센서를 나타내며, 모델은 카메라 데이터만 공급합니다. LC는 LiDAR와 카메라 센서를 나타내며 모델은 여러 개의 Modal 데이터를 입력합니다. CMT-C 모델의 성능이 더 높다는 것을 알 수 있습니다. BEVDet 및 DETR3D 모델의 성능은 CenterPoint 및 UVTR과 같은 순수 LiDAR 인식 알고리즘 모델보다 높습니다. LiDAR 포인트 클라우드 데이터 및 카메라 데이터를 사용한 후 기존의 모든 단일 모달 방법을 능가하고 SOTA 결과를 얻었습니다. .nuScenes의 Val 세트에 대한 모델의 인식 결과 비교
실험 결과를 통해 LiDAR 포인트 클라우드 데이터와 카메라 데이터를 동시에 사용할 때 CMT-L의 인식 모델의 성능이 뛰어남을 알 수 있습니다. CMT는 FUTR3D, UVTR, TransFusion 및 BEVFusion과 같은 다중 모드 알고리즘과 같은 기존 다중 모드 인식 알고리즘을 크게 능가하여 값 세트에서 SOTA 결과를 달성했습니다 다음은 CMT 혁신의 절제 실험 부분입니다 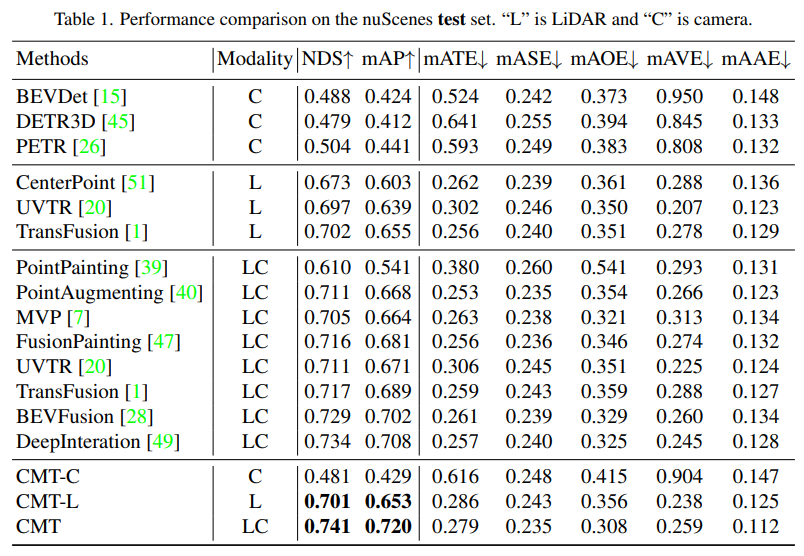
요약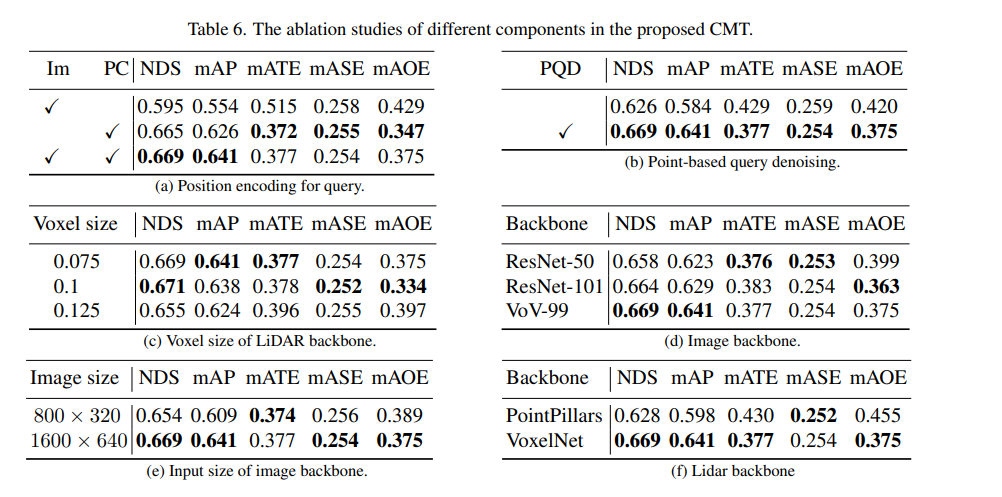
현재 모델의 지각 성능을 향상시키기 위해 다양한 양식을 융합하는 것이 인기 있는 연구 방향이 되었습니다(특히 다양한 센서가 장착된 자율주행차에서). 한편, CMT는 추가적인 후처리 단계가 필요하지 않고 nuScenes 데이터세트에서 최첨단 정확도를 달성하는 완전한 엔드투엔드 인식 알고리즘입니다. 이 글은 이 글을 자세히 소개한 글인데, 모두에게 도움이 되었으면 좋겠습니다
다시 작성해야 할 내용은 다음과 같습니다. 원문 링크: https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
위 내용은 크로스 모달 변환기: 빠르고 강력한 3D 물체 감지용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



