

대형 언어 모델은 성능이 뛰어나며 제로 또는 퓨샷 힌트로 새로운 작업을 해결할 수 있습니다. 그러나 실제 애플리케이션 배포에서 LLM은 메모리 활용 효율성이 낮고 컴퓨팅 리소스가 많이 필요하기 때문에 그다지 실용적이지 않습니다. 예를 들어 1,750억 개의 매개변수가 있는 언어 모델 서비스를 실행하려면 최소 350GB의 비디오 메모리가 필요하며, 현재 최첨단 언어 모델의 대부분은 5,000억 개의 매개변수를 초과했습니다. 많은 연구팀은 이를 실행할 리소스가 충분하지 않으며 실제 응용 프로그램에서 짧은 대기 시간 성능을 충족할 수 없습니다.
수동으로 레이블이 지정된 데이터나 LLM 생성 레이블을 사용한 증류를 사용하여 더 작은 작업별 모델을 훈련하는 연구도 있지만 미세 조정 및 증류에는 LLM과 비슷한 성능을 달성하기 위해 많은 양의 훈련 데이터가 필요합니다.
대형 모델의 리소스 요구 사항 문제를 해결하기 위해 워싱턴 대학과 Google은 협력하여 "Distilling Step-by-Step"이라는 새로운 증류 메커니즘을 제안했습니다. 단계별 증류를 통해 증류된 모델의 크기는 원래 모델보다 작지만 성능은 더 좋고, 미세 조정 및 증류 과정에서 필요한 훈련 데이터도 적습니다

4개의 NLP 벤치마크에 대한 실험 후 다음을 발견했습니다.
1. 미세 조정 및 증류와 비교할 때 이 메커니즘은 더 적은 수의 훈련 샘플로 더 나은 성능을 달성합니다. 
분포 증류에는 주로 두 단계가 포함됩니다.
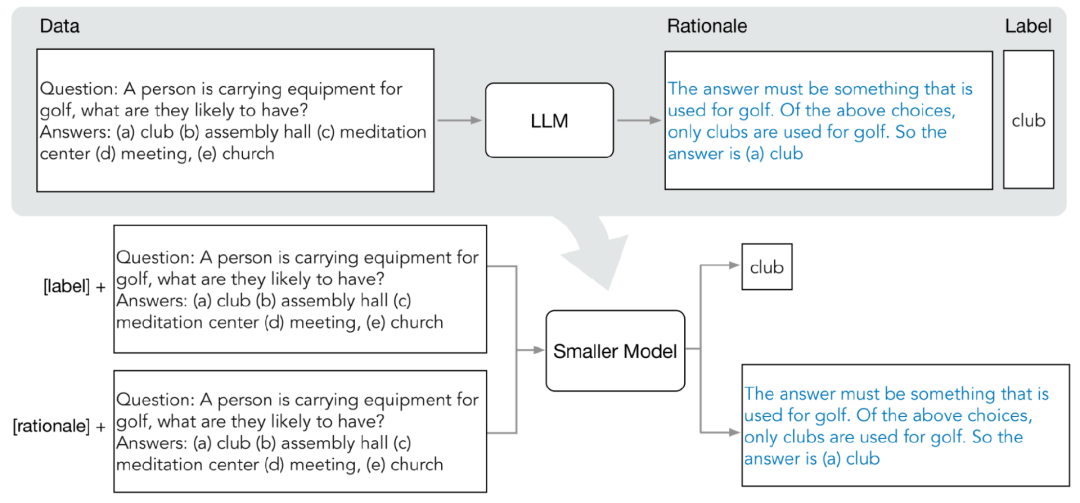
연구원은 CoT(Few-Shot Chain of Thinking)를 사용합니다. LLM 예측 중간 단계에서 추출하라는 메시지가 표시됩니다. 대상 작업을 결정한 후 먼저 LLM 입력 프롬프트에서 몇 가지 샘플을 준비하세요. 각 예는 입력, 원리 및 출력을 포함하는 삼중항으로 구성됩니다.
프롬프트를 입력한 후 LLM은 삼중항 시연을 모방하여 상식 질문 및 답변 작업과 같은 다른 새로운 질문에 대한 예측 원리를 생성할 수 있습니다. , 주어진
입력 질문:
점진적인 개선을 거쳐 LLM은 "(a) 질문에 대한 정답을 제공할 수 있습니다. 인구 "인구 밀집 지역"을 선택하고, "답은 사람이 많은 곳이어야 합니다. 위 선택지 중에서 인구 밀집 지역에만 사람이 많습니다."라는 질문에 답하는 이유를 제시합니다. LLM은 점진적인 정제를 거쳐 "(a) 인구밀도가 높은 지역"이 정답이라는 결론을 내릴 수 있었고, "답은 사람이 많은 곳이어야 한다. 위의 선택지 중에서 인구밀도가 높은 지역만"이라는 질문에 대한 답변 이유를 제공했다. 사람이 많아요." 사람."
프롬프트의 근거와 짝을 이루는 CoT 예제를 제공함으로써 상황별 학습 기능을 통해 LLM은 직면하지 않은 질문 유형에 대한 해당 답변 이유를 생성할 수 있습니다
2. 소규모 모델 교육
다중 작업 문제에 대한 교육 프로세스 구축을 통해 예측 이유를 추출하여 훈련 소형 모델에 통합할 수 있습니다
표준 라벨 예측 작업 외에도 연구원들은 새로운 이유 생성 작업을 사용하여 소형 모델을 훈련하여 모델이 사용자 생성 방법을 학습할 수 있도록 했습니다. 예측을 위한 중간 추론 단계를 수행하고 모델이 결과 레이블을 더 잘 예측하도록 안내합니다.
입력 프롬프트에 작업 접두사 "label" 및 "rationale"을 추가하여 레이블 예측 및 이유 생성 작업을 구별합니다.
실험에서 연구진은 5,400억 개의 매개변수를 갖는 PaLM 모델을 LLM 기준선으로 선택하고, 작업 관련 다운스트림 소형 모델로 T5 모델을 사용했습니다.
본 연구에서는 자연어 추론을 위한 e-SNLI와 ANLI, 상식 질문 답변을 위한 CQA, 산술수학 응용 질문을 위한 SVAMP의 4가지 벤치마크 데이터 세트에 대한 실험을 수행했습니다. 우리는 세 가지 다른 NLP 작업에 대해 실험을 수행했습니다
더 적은 훈련 데이터
단계적 증류 방법은 성능 면에서 표준 미세 조정보다 성능이 뛰어나고 더 적은 훈련 데이터가 필요합니다
in e-SNLI 데이터 세트에서 더 나은 성능 표준 미세 조정은 전체 데이터 세트의 12.5%를 사용하여 달성되며 ANLI, CQA 및 SVAMP에는 각각 훈련 데이터의 75%, 25% 및 20%만 필요합니다.
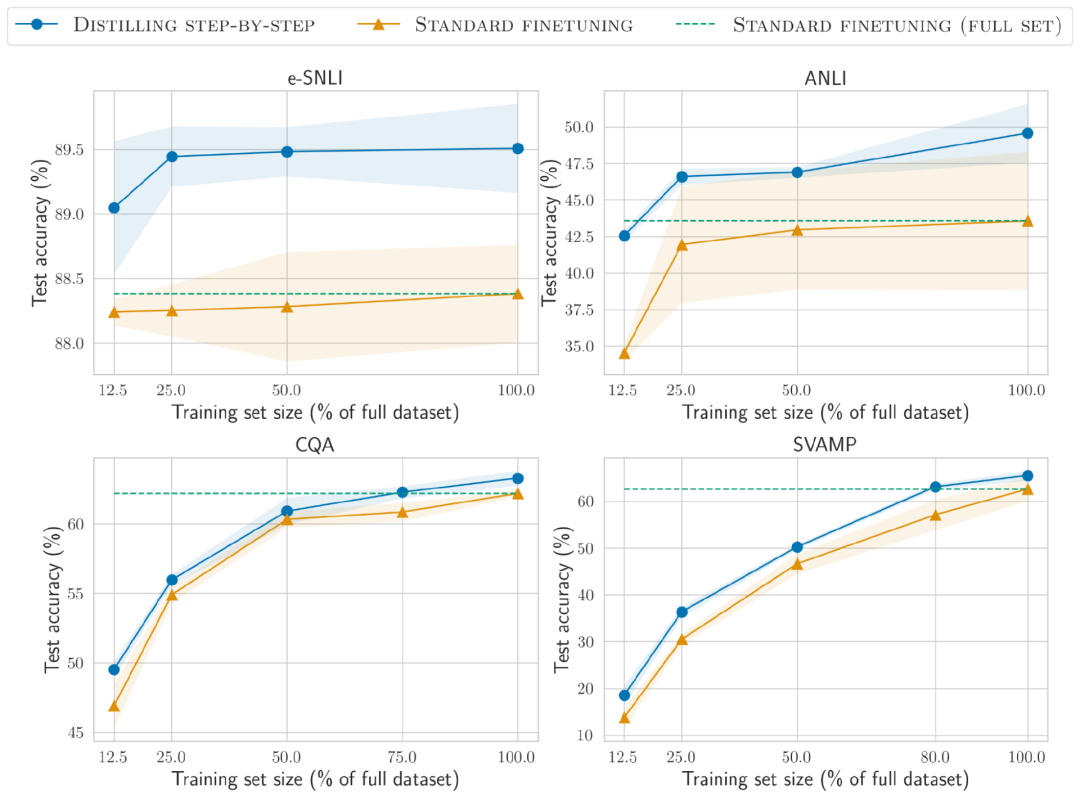
220M T5 모델을 사용하여 사람이 라벨을 붙인 다양한 크기의 데이터 세트에 대한 표준 미세 조정과 비교했을 때, 분포 증류는 모든 데이터 세트에서 더 적은 수의 훈련 예제를 사용할 때 전체 데이터 세트에 대한 표준 미세 조정보다 성능이 뛰어납니다.
더 작은 배포 모델 크기
소표본 CoT로 유도된 LLM과 비교하여 분포 증류로 얻은 모델 크기는 훨씬 작지만 성능은 더 좋습니다.
e-SNLI 데이터 세트에서 220M T5 모델을 사용하면 ANLI에서 540B PaLM보다 더 나은 성능을 얻을 수 있으며, 770M T5 모델을 사용하면 540B PaLM보다 더 나은 성능을 얻을 수 있으며 모델 크기는 1/700
더 작은 모델, 더 적은 데이터
모델 크기와 학습 데이터를 줄이면서 퓨샷 PaLM 이상의 성능을 성공적으로 달성했습니다.
ANLI에서는 770M을 사용하여 전체 데이터 세트의 80%만 사용하면서도 T5 모델은 540B PaLM보다 성능이 뛰어납니다.
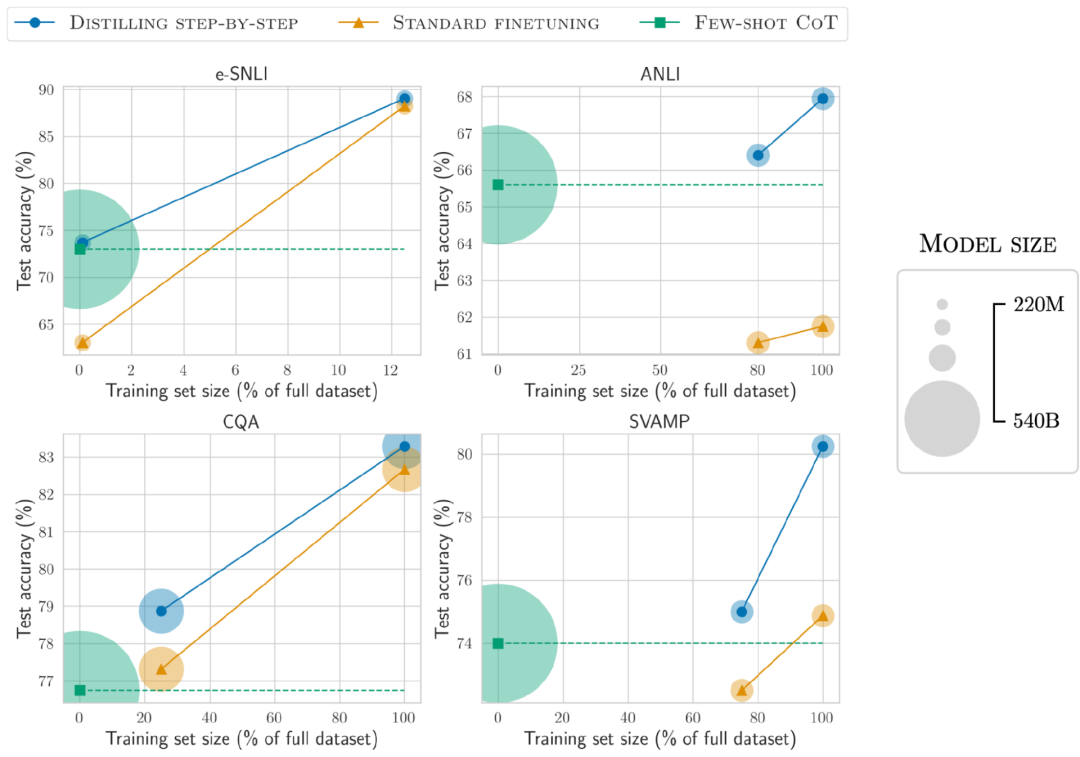
전체 100% 데이터 세트에서도 표준 미세 조정은 PaLM의 성능 수준에 도달할 수 없는 것으로 관찰되었습니다. 이는 단계적 증류를 통해 모델 크기와 훈련 데이터 양을 동시에 줄여 LLM 이상의 성능을 달성할 수 있음을 보여줍니다.
위 내용은 7억 7천만 개의 매개변수, 5,400억 개의 PaLM을 초과합니다! UW Google, ACL 2023 학습 데이터의 80%만 필요한 '단계별 증류' 제안 |의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



