

시계열 문제에는 동일한 빈도로 샘플링되지 않는 시계열 유형이 있습니다. 즉, 각 그룹에서 인접한 두 관측값 사이의 시간 간격이 다릅니다. 시계열 표현 학습은 동일 빈도 샘플링 시계열에서 많은 연구가 이루어졌지만, 이러한 불규칙 샘플링 시계열에 대한 연구는 적고, 이러한 유형의 시계열에 대한 모델링 방법은 동일 빈도 샘플링과 다릅니다. 모델링 방법의 큰 차이
오늘 소개된 글에서는 불규칙 샘플링 시계열 문제에서 표현 학습의 적용 방법을 탐색하고 NLP 관련 경험을 활용하여 다운스트림 작업에서 놀라운 효과를 얻습니다.
 Pictures
Pictures
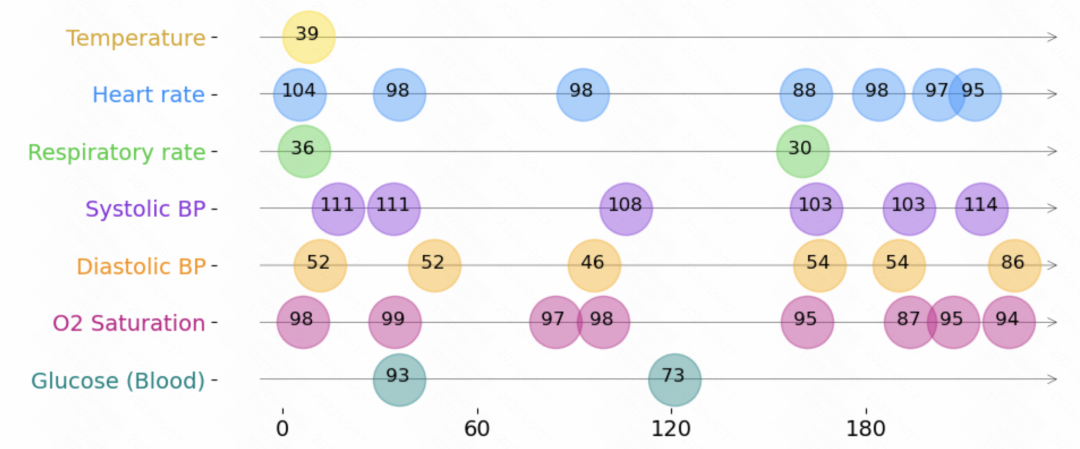
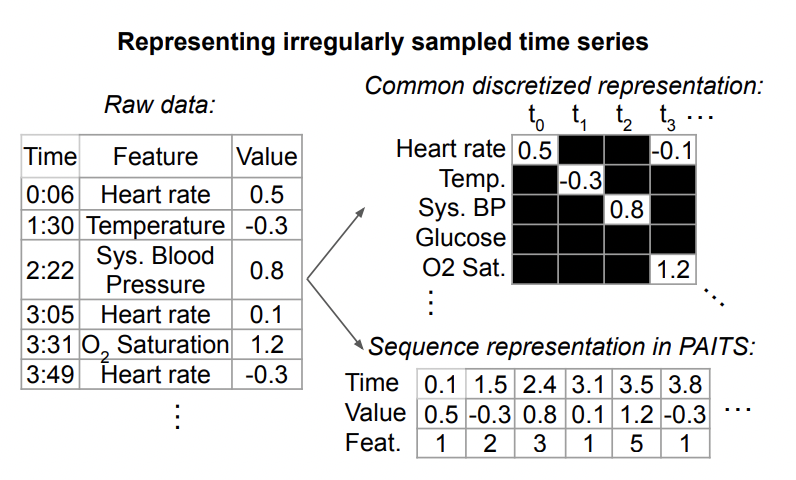
다음은 불규칙한 시계열 데이터를 아래 그림과 같이 표현한 것입니다. 각 시계열은 트리플 세트로 구성됩니다. 각 트리플에는 시간, 값, 기능이라는 세 가지 필드가 포함되어 있으며, 이는 각각 시계열의 각 요소에 대한 샘플링 시간, 값 및 기타 기능을 나타냅니다. 이러한 트리플 외에도 각 시퀀스에는 시간이 지나도 변하지 않는 다른 정적 특성과 각 시계열에 대한 레이블도 포함되어 있습니다. 트리플 데이터는 별도로 내장되고, 함께 접합되어 변환기와 같은 모델에 입력됩니다. 이렇게 각 순간의 정보와 각 순간의 시간 표현을 통합하여 모델에 입력하여 후속 작업을 예측합니다.
 Pictures
Pictures
이 기사의 작업에서 사용된 데이터에는 레이블이 지정된 데이터뿐만 아니라 비지도 사전 학습을 위한 레이블이 지정되지 않은 데이터도 포함됩니다.
2. 방법 개요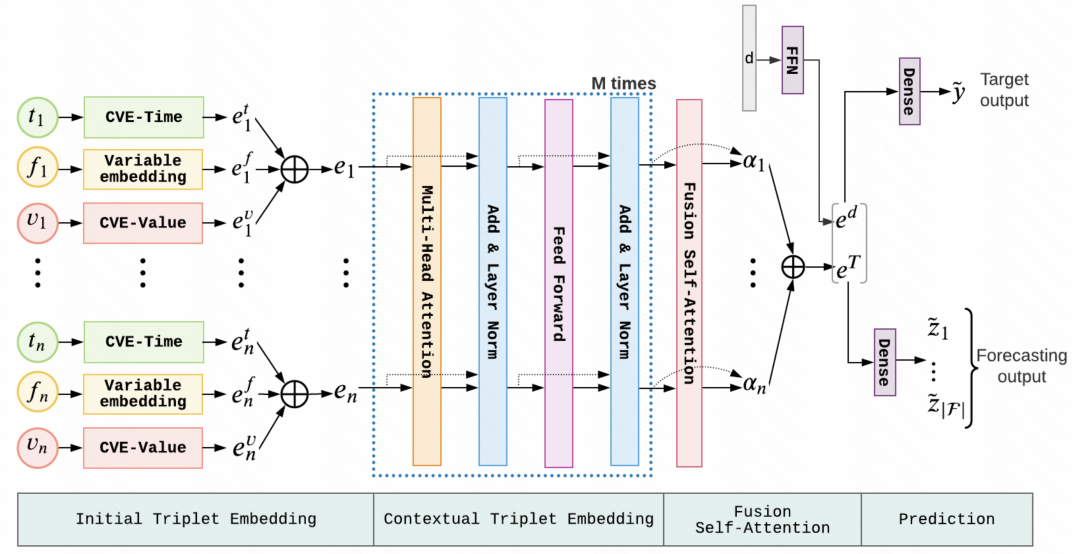 이 글의 사전 훈련 방법은 자연어 처리 분야의 경험을 참조하며 주로 두 가지 측면을 다룹니다.
이 글의 사전 훈련 방법은 자연어 처리 분야의 경험을 참조하며 주로 두 가지 측면을 다룹니다.
4. 데이터 향상 방법 설계
이 글에서는 두 가지 데이터 향상 방법을 제안합니다. 첫 번째 방법은 데이터의 다양성을 높이기 위해 데이터에 임의의 간섭을 도입하여 노이즈를 추가하는 것입니다. 두 번째 방법은 무작위 마스킹으로, 마스킹할 데이터 부분을 무작위로 선택하여 모델이 더욱 강력한 특징을 학습하도록 장려합니다. 이러한 데이터 향상 방법은 모델의 성능과 일반화 능력을 향상시키는 데 도움이 될 수 있습니다.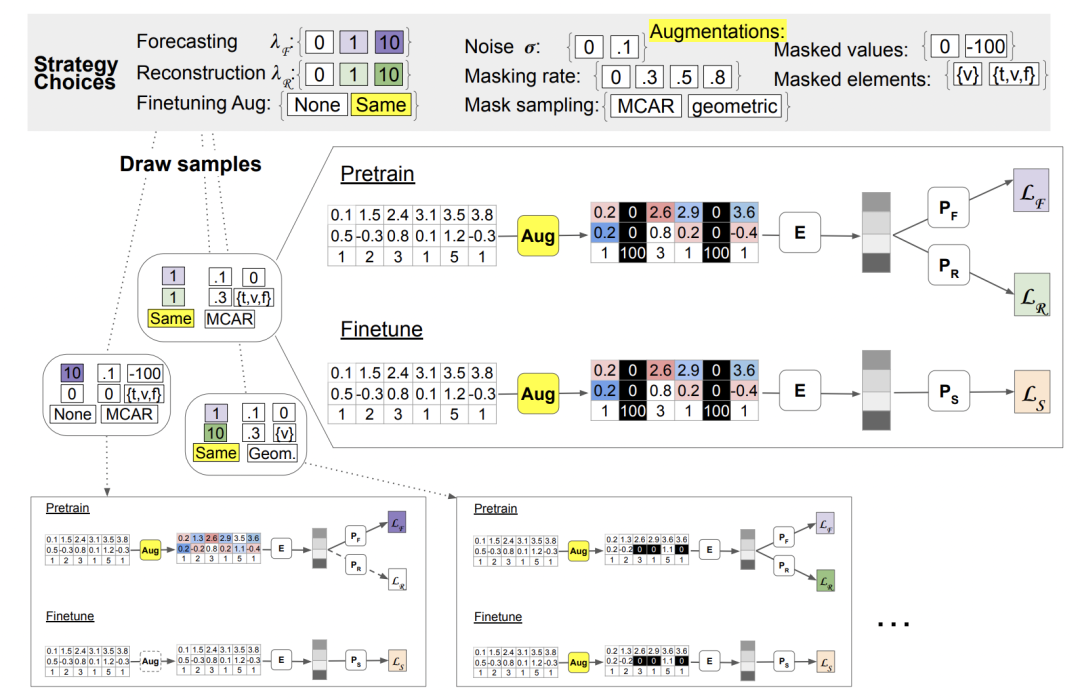 원본 시퀀스의 각 값이나 시점에 대해 가우스 노이즈를 추가하여 노이즈를 추가할 수 있습니다. 구체적인 계산 방법은 다음과 같습니다.
원본 시퀀스의 각 값이나 시점에 대해 가우스 노이즈를 추가하여 노이즈를 추가할 수 있습니다. 구체적인 계산 방법은 다음과 같습니다.
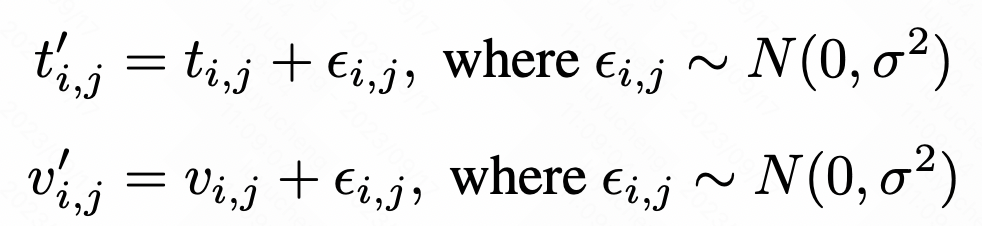 Pictures
Pictures
랜덤 마스크 방법은 NLP의 아이디어를 바탕으로 무작위 마스킹 및 교체를 위해 시간, 특징, 값 및 기타 요소를 무작위로 선택하여 향상된 시계열을 구성합니다.
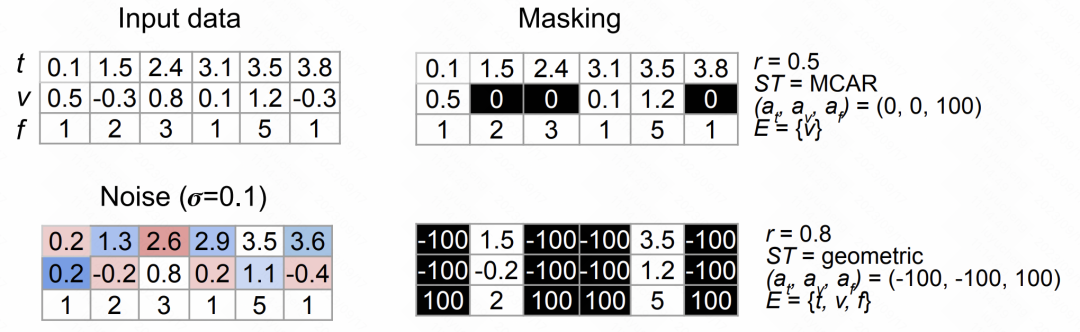
다음 그림은 위의 두 가지 유형의 데이터 향상 방법의 효과를 보여줍니다.
 Picture
Picture
또한 이 기사에서는 다양한 시계열에 대해 데이터 향상, 사전 학습 방법 등의 다양한 조합을 사용합니다. 데이터, 이러한 조합에서 최적의 사전 훈련 방법을 검색합니다.
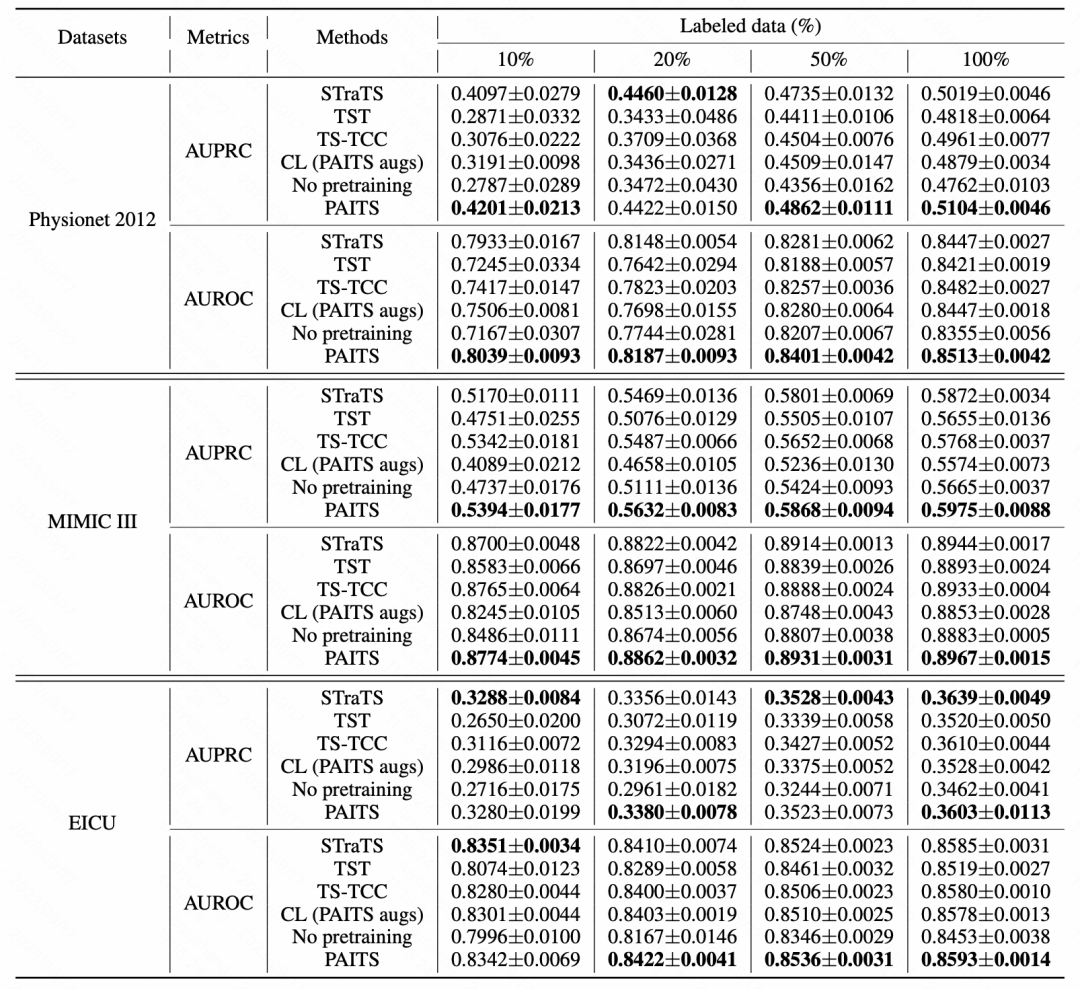
이 기사에서는 다양한 사전 학습 방법이 이러한 데이터 세트에 미치는 영향을 비교하기 위해 여러 데이터 세트에 대해 실험을 수행했습니다. 기사에서 제안한 사전 훈련 방법은 대부분의 데이터 세트에서 상당한 개선을 달성한 것을 볼 수 있습니다
 Pictures
Pictures
위 내용은 Google: 동일하지 않은 빈도 샘플링을 사용하여 시계열 표현을 학습하는 새로운 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



