

다양한 어휘 목록이 언어 모델에 어떤 영향을 미치나요? 이러한 효과의 균형을 맞추는 방법은 무엇입니까?
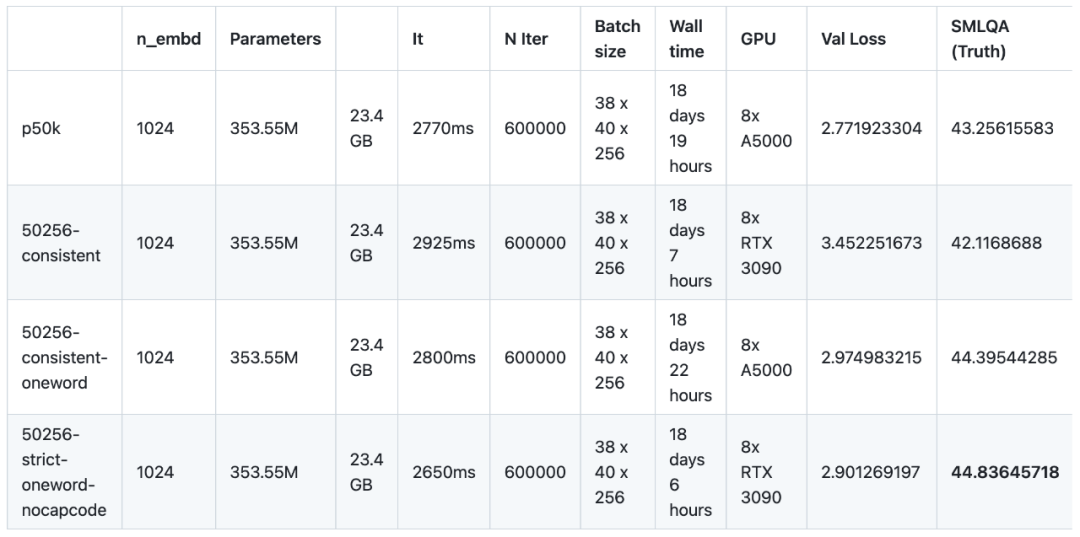
최근 실험에서 연구원들은 다양한 말뭉치로 16개 언어 모델을 사전 훈련하고 미세 조정했습니다. 이번 실험에서는 소규모 아키텍처(GPT-2 SMALL 기반)인 NanoGPT를 사용하여 총 12개의 모델을 학습시켰습니다. NanoGPT의 네트워크 아키텍처 구성은 12개의 어텐션 헤드, 12개의 변환기 레이어, 단어 임베딩 차원은 768이며 약 400,000번의 반복(약 10개의 에포크)이 수행되었습니다. 그런 다음 GPT-2 MEDIUM에서 4개의 모델을 훈련했습니다. GPT-2 MEDIUM의 아키텍처는 16개의 어텐션 헤드, 24개의 변환기 레이어로 설정되었으며 단어 임베딩 차원은 1024였으며 600,000번의 반복이 수행되었습니다. 모든 모델은 NanoGPT 및 OpenWebText 데이터 세트를 사용하여 사전 학습되었습니다. 미세 조정 측면에서 연구진은 baize-chatbot에서 제공하는 명령 데이터 세트를 사용하고 두 가지 유형의 모델에 각각 20,000개 및 500,000개의 "사전" 항목을 추가했습니다
향후 연구원들은 출시할 계획입니다. 코드 및 사전 훈련 모델, 명령어 튜닝 모델 및 미세 조정 데이터 세트
그러나 GPU 후원자가 부족하여(무료 오픈 소스 프로젝트임) 비용 절감을 위해 연구원들은 계속해서 연구 내용 공간을 더욱 개선하기 위한 작업이 아직 남아 있지만 계속 진행하십시오. 사전 훈련 단계에서 이 16개 모델은 총 147일 동안 8개의 GPU에서 실행되어야 하며(단일 GPU는 1,176일 동안 사용해야 함) 비용은 US$8,000
입니다. 연구 결과는 다음과 같습니다. 요약:
실험 결과에 따르면 englishcode-32000-consistency의 결과가 가장 좋습니다. 그러나 위에서 언급한 것처럼 단일 토큰이 여러 단어에 해당하는 TokenMonster를 사용하면 SMLQA(Ground Truth) 정확도와 단어 비율 사이에 트레이드오프가 발생하여 학습 곡선의 기울기가 증가합니다. 연구원들은 토큰의 80%가 한 단어에 해당하고 토큰의 20%가 여러 단어에 해당하도록 강제하면 이러한 상충관계가 최소화되고 "두 세계의 최고" 어휘가 달성될 수 있다고 굳게 믿습니다. 연구진은 이 방법이 한 단어 어휘 목록과 동일한 성능을 가지면서도 단어 비율을 약 50% 향상시킬 수 있다고 믿고 있다.
이 문장의 의미는 단어 분할기의 결함과 복잡성이 언어 능력보다 사실을 학습하는 모델의 능력에 더 큰 영향을 미친다는 것입니다.
이 현상은 훈련 과정에서 흥미로운 발견입니다. 모델 훈련이 작동하는 방식을 생각해 보는 것이 합리적입니다. 연구자는 자신의 추론을 정당화할 증거가 없습니다. 그러나 본질적으로 언어의 유창성은 언어의 사실성(매우 미묘하고 상황에 따라 다름)보다 역전파 중에 수정하기가 더 쉽기 때문에 이는 토크나이저 효율성의 개선이 언어의 사실성보다 일관성이 떨어짐을 의미합니다. 성별에 관계없이 , SMLQA(Ground Truth) 벤치마크에서 볼 수 있듯이 정보 충실도 향상으로 직접 변환되는 파급 효과가 있습니다. 간단히 말해서, 더 나은 토크나이저는 더 현실적인 모델이지만 반드시 더 부드러운 모델은 아닙니다. 그 반대의 경우: 비효율적인 토크나이저를 사용하는 모델은 여전히 유창하게 작성하는 방법을 배울 수 있지만 유창함을 위한 추가 비용으로 인해 모델의 신뢰성이 떨어집니다.
본 테스트를 진행하기 전, 연구진은 32000이 최적의 어휘 크기라고 믿었고, 실험 결과에서도 이를 확인했습니다. SMLQA(Ground Truth) 벤치마크에서 50256 밸런스 모델의 성능은 32000 밸런스 모델에 비해 1% 향상에 불과하지만 모델 크기는 13% 증가합니다. 이러한 관점을 명확하게 증명하기 위해 본 기사에서는 MEDIUM을 기반으로 한 여러 모델에서 어휘를 24000, 32000, 50256 및 100256 단어로 나누어 실험을 수행했습니다
.연구원들은 TokenMonster를 테스트하고 균형, 일관성, 엄격의 세 가지 특정 최적화 모드를 테스트했습니다. 다양한 최적화 모드는 구두점 및 캡코드가 단어 토큰과 결합되는 방식에 영향을 미칩니다. 연구원들은 처음에 일관성 모드가 (덜 복잡하기 때문에) 더 나은 성능을 발휘할 것이라고 예측했지만 단어 비율(즉, 문자 대 토큰의 비율)은 약간 낮을 것입니다
실험 결과는 위의 추측을 확인하는 것 같았습니다. , 그러나 연구자들은 또한 몇 가지 현상이 있음을 관찰했습니다. 첫째, 일관성 모드는 SMLQA(Ground Truth) 벤치마크에서 균형 모드보다 약 5% 더 나은 성능을 보이는 것으로 보입니다. 그러나 일관성 모드는 SQuAD(데이터 추출) 벤치마크에서 훨씬 더 낮은 성능(28%)을 나타냅니다. 그러나 SQuAD 벤치마크는 큰 불확실성(반복 실행 시 다른 결과 제공)을 보여 설득력이 없습니다. 연구자들은 균형 잡힌 패턴과 일관된 패턴 사이의 수렴을 테스트하지 않았으므로 이는 단순히 일관된 패턴이 학습하기 더 쉽다는 것을 의미할 수 있습니다. 실제로 SQuAD는 배우기 어렵고 환각을 일으킬 가능성이 적기 때문에 일관성이 SQuAD(데이터 추출)에서 더 나을 수 있습니다.
이것은 구두점과 단어를 단일 토큰으로 결합하는 데 명백한 문제가 없다는 것을 의미하므로 그 자체로 흥미로운 발견입니다. 지금까지 다른 토크나이저들은 모두 구두점과 문자를 분리해야 한다고 주장해 왔지만, 여기 결과에서 볼 수 있듯이 눈에 띄는 성능 손실 없이 단어와 구두점을 하나의 토큰으로 병합할 수 있습니다. 이는 50256-strict-oneword-nocapcode와 동등한 성능을 발휘하고 p50k_base보다 성능이 뛰어난 조합인 50256-condependent-oneword로도 확인됩니다. 50256-일관된-원워드는 간단한 구두점과 단어 토큰을 결합합니다(다른 두 조합은 그렇지 않음).
캡코드의 엄격 모드를 활성화하면 명백한 부정적인 영향을 미칠 것입니다. SMLQA에서 50256-strict-oneword-nocapcode 점수는 21.2이고 SQuAD에서는 23.8이며, 50256-strict-oneword는 각각 16.8과 20.0입니다. 그 이유는 분명합니다. 엄격한 최적화 모드는 캡코드와 단어 토큰의 병합을 방지하여 동일한 텍스트를 표현하는 데 더 많은 토큰이 필요하게 되어 단어 비율이 8% 감소합니다. 실제로 strict-nocapcode는 strict 모드보다 Consistency와 더 유사합니다. 다양한 지표에서 50256-condependent-oneword와 50256-strict-oneword-nocapcode는 거의 동일합니다
대부분의 경우, 연구자들은 이 모델이 문장 부호와 단어가 포함된 토큰의 의미를 학습하는 데 유용하다고 결론지었습니다. 그리 어렵지 않습니다. . 즉, 일관성 모델은 균형 모델보다 문법 정확도가 높고 문법 오류가 적습니다. 모든 것을 고려하여 연구원들은 모든 사람이 일관성 모드를 사용할 것을 권장합니다. 엄격 모드는 캡코드가 비활성화된 경우에만 사용할 수 있습니다.
위에서 언급했듯이 일관성 모드는 균형 모드보다 구문 정확도가 더 높습니다(구문 오류가 적음). 이는 아래 그림에서 볼 수 있듯이 단어 비율과 문법 사이의 아주 약간의 음의 상관관계에 반영됩니다. 그 외에도 가장 주목할만한 점은 GPT-2 토크나이저와 tiktoken p50k_base의 구문 결과가 TokenMonster의 50256-strict-oneword-nocapcode(98.6% 및 98.4% 및 97.5%)에 비해 (각각) 형편없다는 것입니다. . 연구자들은 처음에는 그것이 단지 우연의 일치라고 생각했지만 여러 번의 샘플링을 통해 동일한 범위의 결과가 나왔습니다. 원인이 무엇인지는 불분명합니다.
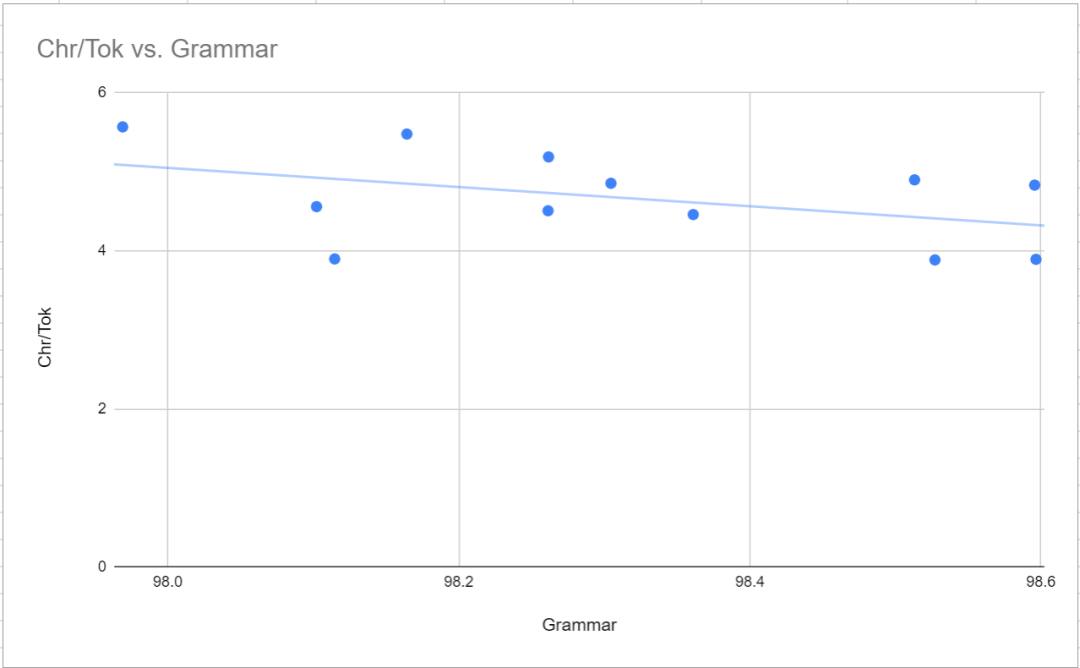
MTLD는 생성된 샘플 텍스트의 언어적 다양성을 나타내는 데 사용됩니다. 이는 어휘 크기, 최적화 모드 또는 토큰당 최대 단어 수와 같은 기능이 아닌 n_embed 매개변수와 밀접한 관련이 있는 것으로 보입니다. 이는 6000 균형 모델(n_embd는 864)과 8000 일관성 모델(n_embd는 900)에서 특히 두드러집니다.
중간 모델 중에서 p50k_base의 MTLD가 43.85로 가장 높지만 구문 점수도 가장 낮습니다. . 그 이유는 불분명하지만, 연구자들은 훈련 데이터의 선택이 다소 이상할 수 있다고 추측하고 있습니다.
SQuAD 벤치마크의 목적은 텍스트에서 데이터를 추출하는 모델의 능력을 평가하는 것입니다. 구체적인 방법은 텍스트 단락을 제공하고 질문을 하여 텍스트 단락에서 답을 찾아야 하는 것입니다. 테스트 결과는 그다지 의미가 없고, 뚜렷한 패턴이나 상관 관계가 없으며, 모델의 전체 매개변수에 영향을 받지 않습니다. 실제로 9100만 개의 매개변수를 갖는 8000 균형 모델은 3억 5400만 개의 매개변수를 갖는 50256-일관적 한 단어 모델보다 SQuAD에서 더 높은 점수를 받았습니다. 그 이유는 이 스타일의 예가 충분하지 않거나 미세 조정 데이터 세트에 질문-답변 쌍이 너무 많기 때문일 수 있습니다. 아니면 이상적인 벤치마크가 아닐 수도 있습니다.
SMLQA 벤치마크는 "자카르타는 어느 나라의 수도인가?"와 같은 객관적인 답변이 포함된 상식적인 질문을 통해 "진실 가치"를 테스트합니다. 그리고 "해리포터 책은 누가 썼나요?"
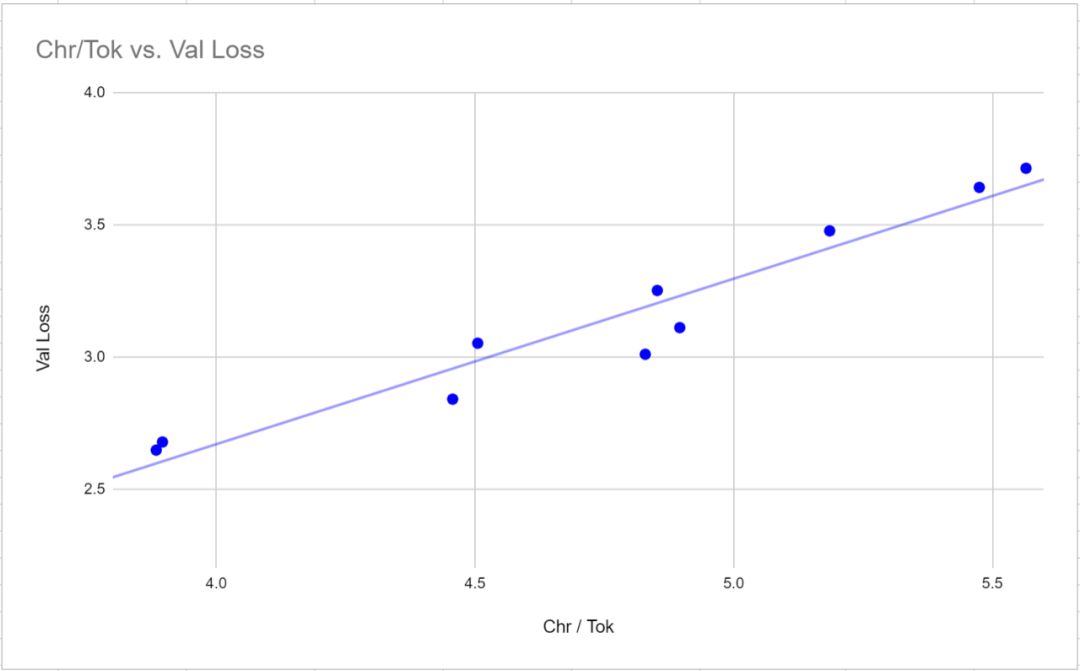
이 벤치마크 테스트에서 두 개의 참조 토크나이저인 GPT-2 Tokenizer와 p50k_base가 매우 좋은 성능을 발휘했다는 점은 주목할 가치가 있습니다. 연구원들은 처음에 몇 달의 시간과 수천 달러를 낭비했다고 생각했지만 tiktoken이 TokenMonster보다 더 나은 성능을 발휘한 것으로 나타났습니다. 그러나 문제는 각 토큰에 해당하는 단어 수와 관련이 있는 것으로 밝혀졌습니다. 이는 아래 그림과 같이 "중간"(MEDIUM) 모델에서 특히 분명합니다
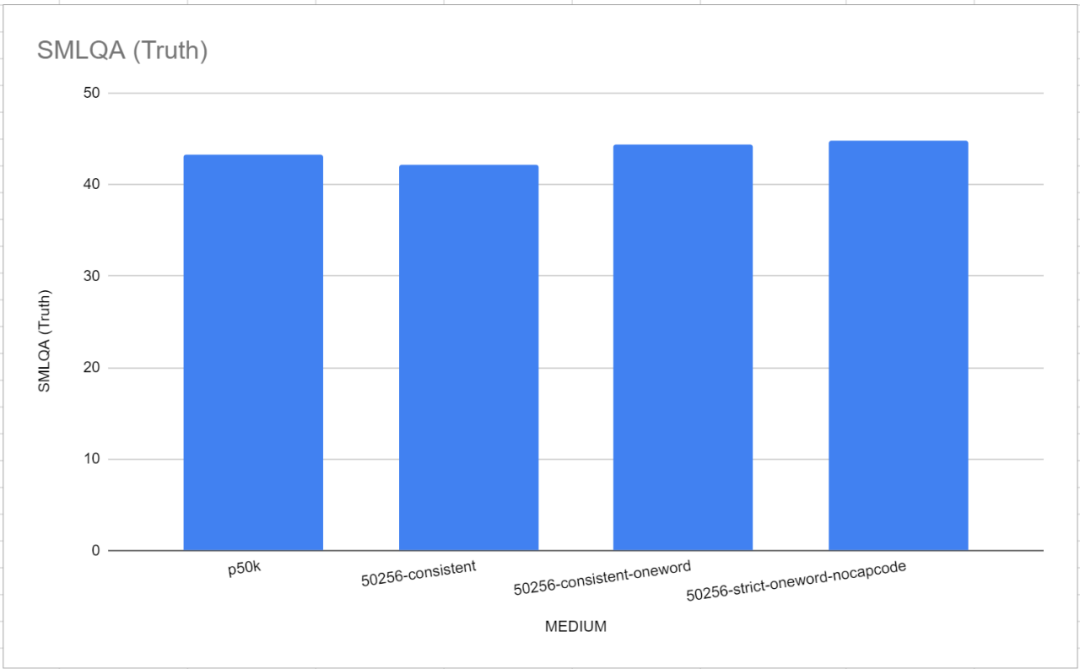
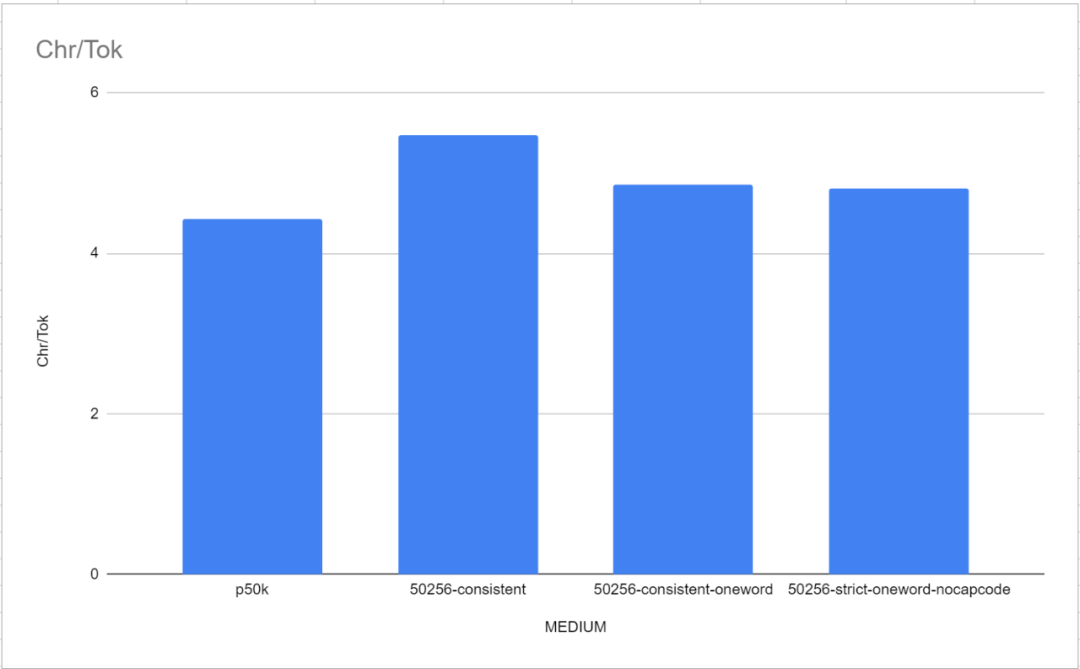 한 단어 어휘의 성능은 TokenMonster의 기본 각 토큰이 여러 단어에 해당하는 것보다 약간 더 좋습니다. 단어 어휘 목록.
한 단어 어휘의 성능은 TokenMonster의 기본 각 토큰이 여러 단어에 해당하는 것보다 약간 더 좋습니다. 단어 어휘 목록.
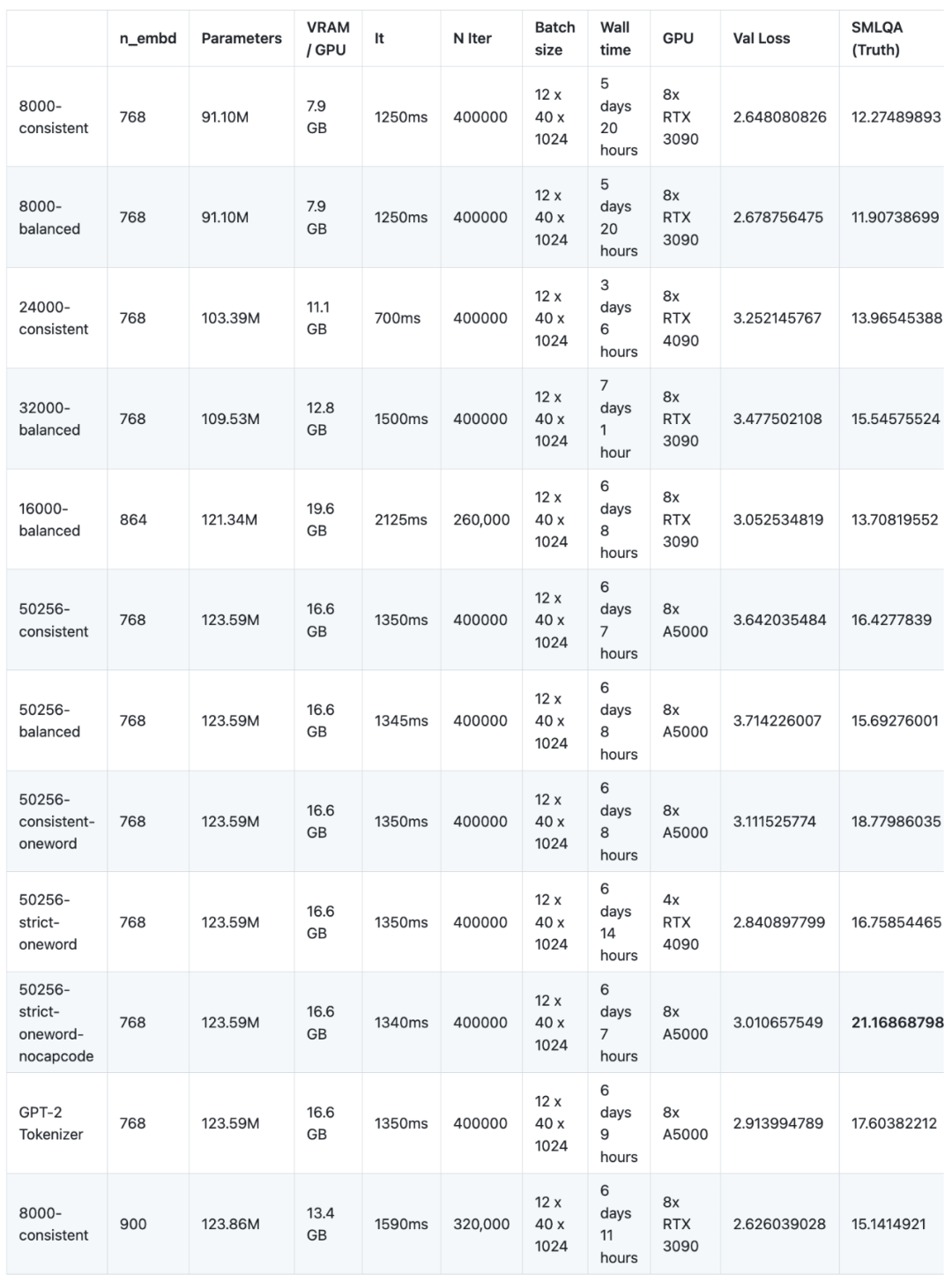
또 다른 중요한 관찰은 어휘 크기가 32,000 미만인 경우 모델 크기 감소를 보상하기 위해 모델의 n_embd 매개변수가 조정되더라도 어휘 크기가 실제 값에 직접적인 영향을 미친다는 것입니다. 연구원들은 원래 n_embd가 864(매개변수 1억 2,134만)인 16000과 n_embd가 900(매개변수 1억 2,386만)인 8000과 일치하는 것이 n_embd가 768(매개변수인 768)인 50256과 일치하는 것보다 더 나을 것이라고 생각했기 때문에 이는 직관에 어긋납니다. 1억 2,134만)이 더 나은 성능을 보였지만 사실은 아닙니다. 둘 다 훨씬 더 나쁜 성능을 보였습니다(13.7 및 15.1 대 50256-일관적 16.4). 그러나 "조정된" 두 모델 모두 동일한 훈련 시간을 받았기 때문에 사전 훈련 시간이 훨씬 단축되었습니다(동일한 시간임에도 불구하고)
연구원들은 기본 NanoGPT 아키텍처에서 12개 모델을 훈련했습니다. 아키텍처는 12개의 어텐션 헤드와 12개의 레이어를 갖춘 GPT-2 아키텍처를 기반으로 하며 임베딩 매개변수 크기는 768입니다. 이들 모델 중 어느 것도 수렴 상태에 도달하지 못했습니다. 간단히 말해서 최대 학습 능력에 도달하지 못했습니다. 모델은 400,000번의 반복을 위해 학습되었지만 최대 학습 능력에 도달하려면 600,000번의 반복이 필요한 것으로 보입니다. 이 상황의 이유는 간단합니다. 하나는 예산 문제이고, 다른 하나는 수렴점의 불확실성입니다.
소형 모델의 결과:
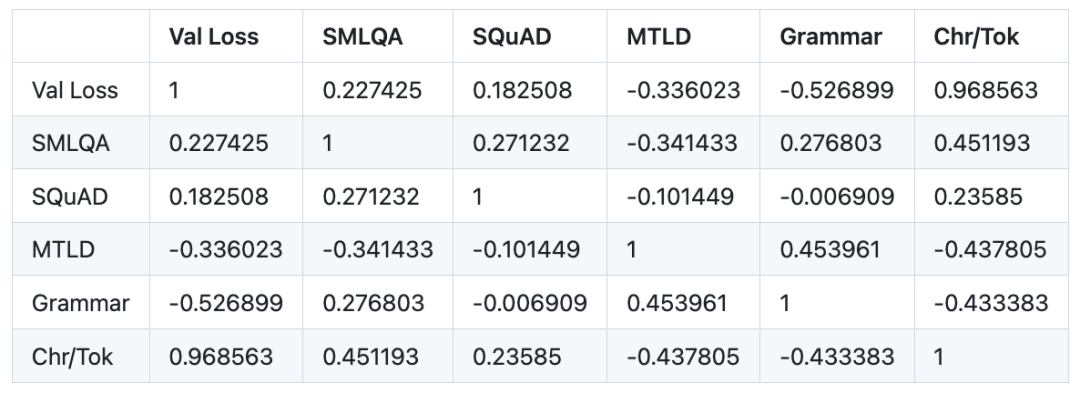
소형 모델의 Pearson 상관 관계:
소형 모델의 결론:
재작성된 내용: 어휘 크기가 32,000일 때 최적의 어휘 수준에 도달했습니다. 어휘 증가 단계에서 8,000에서 32,000까지 어휘를 늘리면 모델의 정확도가 향상됩니다. 그러나 어휘 크기가 32,000에서 50,257로 증가하면 모델의 전체 매개변수도 그에 따라 증가하지만 정확도 향상은 1%에 불과합니다. 32,000을 초과하면 게인이 급격히 감소합니다
잘못된 토크나이저 설계는 모델의 정확성에 영향을 미치지만 문법적 정확성이나 언어 다양성에는 영향을 미치지 않습니다. 9천만 ~ 1억 2천 5백만 매개변수 범위에서 더 복잡한 문법 규칙(예: 여러 단어, 단어 및 구두점 조합에 해당하는 토큰, 캡코드 인코딩 토큰 및 전체 어휘 감소)을 사용하는 토크나이저에 대한 실측 벤치마크 성능이 나쁩니다. 그러나 이 정교한 토크나이저 설계는 생성된 텍스트의 언어적 다양성이나 문법적 정확성에 통계적으로 중요한 영향을 미치지 않았습니다. 9천만 개의 매개변수가 있는 모델과 같은 소형 모델이라도 더 복잡한 마커를 효과적으로 활용할 수 있습니다. 복잡한 어휘일수록 학습하는 데 시간이 더 걸리므로 기본 사실과 관련된 정보를 습득하는 데 걸리는 시간이 줄어듭니다. 이들 모델 중 어느 것도 완전히 훈련되지 않았기 때문에 성능 격차를 줄이기 위한 추가 훈련의 가능성은 아직 남아 있습니다.
중국어로 다시 작성: 3. 검증 손실은 다른 토크나이저를 사용하는 모델을 비교할 때 유효한 측정 기준이 아닙니다. 유효성 검사 손실은 특정 토크나이저의 단어 비율(토큰당 평균 문자 수)과 매우 강한 상관 관계(0.97 Pearson 상관 관계)를 갖습니다. 토크나이저 간의 손실 값을 비교하려면 토큰보다는 문자 기준으로 손실을 측정하는 것이 더 효과적일 수 있습니다. 왜냐하면 손실 값은 각 토큰에 해당하는 평균 문자 수에 비례하기 때문입니다
4. 이러한 언어 모델은 가변 길이 응답을 생성하도록 훈련되었기 때문에 언어 모델에 대한 평가 지표로는 적합하지 않습니다(완료는 텍스트 끝 표시로 표시됨). 이는 텍스트 시퀀스가 길수록 F1 수식의 페널티가 더 심해지기 때문입니다. F1 점수는 더 짧은 응답 모델을 생성하는 경향이 있습니다.
모든 모델(90M 매개변수에서 시작)과 테스트된 모든 토크나이저(8000에서 50257 크기 범위)는 문법적으로 일관된 답변 능력을 생성할 수 있음을 보여주었습니다. 이러한 답변은 종종 부정확하거나 환상적이지만 모두 상대적으로 일관되고 상황적 배경에 대한 이해를 보여줍니다.
생성된 텍스트의 어휘 다양성과 문법 정확도는 포함 크기가 증가함에 따라 크게 증가하며 단어와 약간의 음의 상관 관계가 있습니다. 비율. 이는 단어 대 단어 비율이 클수록 문법 및 어휘 다양성 학습이 약간 더 어려워진다는 것을 의미합니다.
7. 모델 매개변수 크기를 조정할 때 단어 대 단어 비율은 SMLQA(Ground)와 관련이 있습니다. Truth) 또는 SQuAD(Information Extraction) ) 벤치마크 간에는 통계적으로 유의미한 상관관계가 없습니다. 이는 단어 대 단어 비율이 높은 토크나이저가 모델 성능에 부정적인 영향을 미치지 않음을 의미합니다.
"균형" 범주에 비해 "일관성" 범주는 SMLQA(Ground Truth) 벤치마크에서 약간 더 나은 성능을 보이는 것처럼 보이지만 SQuAD(정보 추출) 벤치마크에서는 훨씬 더 나쁜 성능을 보입니다. 이를 확인하려면 더 많은 데이터가 필요하지만
소형 모델을 훈련하고 벤치마킹한 후 연구에서 연구자는 다음을 분명히 발견했습니다. 측정된 결과는 모델의 학습 능력보다는 모델의 학습 속도를 반영했습니다. 게다가 연구원들은 기본 NanoGPT 매개변수가 사용되었기 때문에 GPU의 컴퓨팅 잠재력을 최적화하지 않았습니다. 이 문제를 해결하기 위해 연구원들은 50257개의 토큰이 있는 토크나이저와 중간 언어 모델을 사용하여 4가지 변형을 연구하기로 결정했습니다. 연구원들은 24GB GPU의 VRAM 기능을 최대한 활용할 수 있도록 배치 크기를 12에서 36으로 조정하고 블록 크기를 1024에서 256으로 줄였습니다. 그런 다음 더 작은 모델에서와 같이 400,000번 대신 600,000번의 반복이 수행되었습니다. 각 모델의 사전 훈련에는 평균 18일이 조금 넘게 걸렸으며, 이는 소형 모델에 필요한 6일의 3배입니다.
모델을 수렴하도록 훈련하면 더 단순한 어휘와 더 복잡한 어휘 간의 성능 차이가 크게 줄어듭니다. SMLQA(Ground Truth)와 SQuAD(Data Extraction)의 벤치마크 결과는 매우 유사합니다. 주요 차이점은 50256 일치가 p50k_base보다 단어 비율이 23.5% 더 높다는 장점이 있다는 것입니다. 그러나 토큰당 여러 단어가 포함된 어휘의 경우 진리값의 성능 비용이 더 작지만 페이지 상단에서 논의한 방법을 사용하면 이 문제를 해결할 수 있습니다.
의 모델 결과:
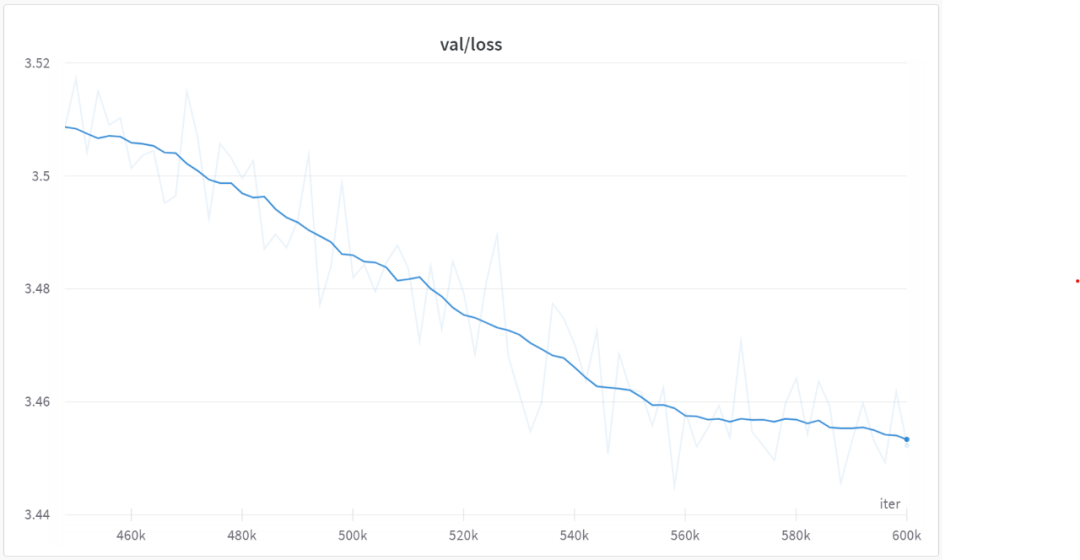
560000회 반복 후 모든 모델은 아래 그림과 같이 수렴하기 시작했습니다.
다음 단계에서는 englishcode-32000-consistency를 사용하여 MEDIUM 모델을 학습하고 벤치마킹할 것입니다. 이 어휘는 80% 단어 토큰과 20% 다중 단어 토큰으로 구성되어 있습니다
위 내용은 언어 모델 훈련에 대한 어휘 선택의 영향 탐구: 획기적인 연구의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



