

원래 의미를 바꾸지 않고 내용을 다시 작성하려면 언어를 중국어로 다시 작성해야 하며, 원래 문장이 나타날 필요는 없습니다
리뷰 | Chonglou의 내용을 다시 작성해야 합니다
최근 지난 달, 생성적 인공지능(Generative Artificial Intelligence) 지능은 독특한 텍스트, 사운드, 이미지를 만들어내는 능력으로 큰 관심을 끌었습니다. 그러나 생성적 AI의 잠재력은 새로운 데이터 생성에만 국한되지 않습니다.
생성적 AI의 기본 기술(예: 변환기 및 확산 모델)은 정보 검색 및 발견을 비롯한 많은 다른 응용 프로그램을 강화할 수 있습니다. 특히, 생성 AI는 이미지 검색에 혁명을 일으켜 사람들이 이전에는 불가능했던 방식으로 시각적 정보를 탐색할 수 있게 해줍니다.

생성 AI가 이미지 검색 경험 콘텐츠를 어떻게 재정의할 수 있는지에 대해 사람들이 알아야 할 사항은 다음과 같습니다.
기존의 이미지 검색 방법은 이미지와 함께 제공되는 텍스트 설명, 태그 및 기타 메타데이터에 의존하므로 사용자의 검색 옵션이 이미지에 명시적으로 첨부된 정보로 제한됩니다. 이미지를 업로드하는 사람들은 다른 사람들이 자신의 이미지를 검색할 수 있도록 자신이 입력하는 검색어 유형을 신중하게 고려해야 합니다. 그리고 이미지를 검색할 때 정보를 쿼리하는 사용자는 이미지 업로더가 이미지에 어떤 종류의 설명을 추가했을지 상상해야 합니다.
속담처럼 "사진은 천 단어보다 중요합니다." 하지만 이미지 설명에 쓸 수 있는 내용에는 제한이 있습니다. 물론 이는 사람들이 이미지를 어떻게 보는가에 따라 다양하게 설명될 수 있습니다. 사람들은 사진 속의 사물을 기준으로 검색하기도 하고, 스타일, 조명, 위치 등의 특징을 기준으로 검색하기도 합니다. 불행하게도 이미지에는 이렇게 풍부한 정보가 동반되는 경우가 거의 없습니다. 많은 사람들이 정보가 거의 또는 전혀 첨부되지 않은 상태로 많은 이미지를 업로드하므로 검색에서 찾기가 어렵습니다.
AI 이미지 검색은 이와 관련하여 중요한 역할을 합니다. AI 이미지 검색에는 다양한 접근 방식이 있으며, 회사마다 고유한 기술을 보유하고 있습니다. 하지만 이들 기업이 공통적으로 갖고 있는 기술도 있습니다.
인공지능 이미지 검색과 기타 여러 딥러닝 시스템의 중심에는 임베딩이 있습니다. 임베딩은 다양한 데이터 유형을 수치로 표현하는 방법입니다. 예를 들어, 512×512 해상도 이미지에는 약 260,000개의 픽셀(또는 특징)이 포함됩니다. 임베딩 모델은 수백만 개의 이미지를 학습하여 시각적 데이터의 저차원 표현을 학습합니다. 이미지 임베딩은 이미지 압축, 새로운 이미지 생성, 다양한 이미지의 시각적 속성 비교 등 다양한 유용한 영역에 적용될 수 있습니다. 동일한 메커니즘이 텍스트와 같은 다른 형식에도 적용됩니다. 텍스트 임베딩 모델은 텍스트 발췌 내용의 저차원 표현입니다. 텍스트 임베딩에는 유사성 검색 및 LLM(대형 언어 모델)에 대한 검색 향상을 포함하여 다양한 응용 분야가 있습니다.
인공 지능 이미지 검색의 작동 방식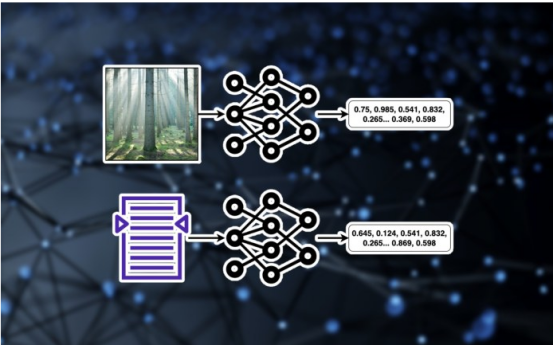
CLIP(Comparative Language on Image Pre-trained) 모델은 텍스트와 이미지의 공동 임베딩을 학습합니다.
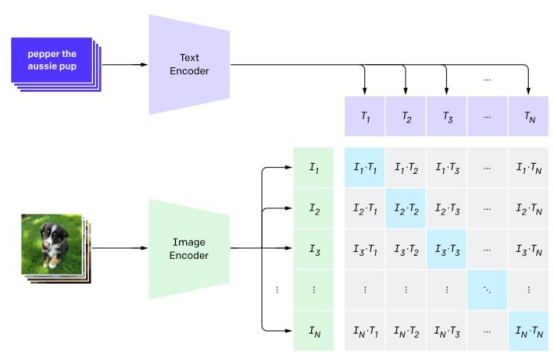 이제 텍스트를 시각적 임베딩으로 변환할 수 있는 도구가 있습니다. 이 조인트 모델에 텍스트 설명을 제공하면 텍스트 임베딩과 해당 이미지 임베딩이 생성됩니다. 그런 다음 이미지 임베딩을 데이터베이스의 이미지와 비교하고 가장 관련성이 높은 이미지를 검색할 수 있습니다. 이것이 인공지능 이미지 검색의 기본 원리입니다.
이제 텍스트를 시각적 임베딩으로 변환할 수 있는 도구가 있습니다. 이 조인트 모델에 텍스트 설명을 제공하면 텍스트 임베딩과 해당 이미지 임베딩이 생성됩니다. 그런 다음 이미지 임베딩을 데이터베이스의 이미지와 비교하고 가장 관련성이 높은 이미지를 검색할 수 있습니다. 이것이 인공지능 이미지 검색의 기본 원리입니다.
이 메커니즘의 장점은 사용자가 이미지의 시각적 특성에 대한 텍스트 설명을 기반으로 이미지를 검색할 수 있다는 것입니다. 메타데이터. "아침 안개에 싸인 울창한 숲, 키 큰 소나무 숲 사이로 비치는 밝은 햇살, 풀밭에 자라는 버섯
" 등 이전에는 불가능했던 풍부한 검색어를 사용할 수 있습니다.
위의 예에서 AI 검색은 이 쿼리와 일치하는 시각적 특성을 가진 일련의 이미지를 반환했습니다. 많은 텍스트 설명에는 쿼리 키워드가 포함되어 있지 않습니다. 그러나 임베딩은 쿼리의 임베딩과 유사합니다. AI 이미지 검색이 없으면 올바른 이미지를 찾는 것이 훨씬 더 어려울 것입니다.
때로는 사람들이 찾는 이미지가 존재하지 않고, AI 검색으로도 찾을 수 없는 경우가 있습니다. 이 경우 생성 AI는 두 가지 방법 중 하나로 사용자가 원하는 결과를 달성하도록 도울 수 있습니다.
먼저 사용자의 쿼리를 기반으로 처음부터 새로운 이미지를 만들 수 있습니다. 이 접근 방식에는 텍스트-이미지 생성 모델(예: Stable Diffusion 또는 DALL-E)을 사용하여 사용자 쿼리에 대한 임베딩을 생성하고 해당 임베딩을 활용하여 이미지를 생성하는 작업이 포함됩니다. 생성 모델은 CLIP(Contrastive Image Language Pre-training)과 같은 공동 임베딩 모델과 Transformers 또는 확산 모델과 같은 기타 아키텍처를 활용하여 내장된 값을 놀라운 이미지로 변환합니다.
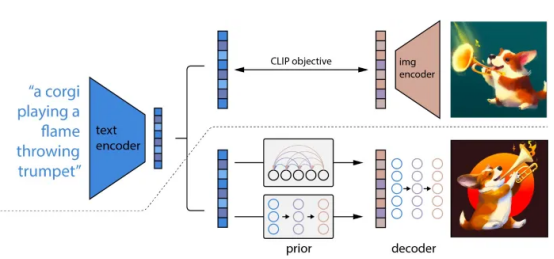 DALL-E는 Contrastive Image Language Pre-training을 사용합니다. (CLIP) 및 텍스트에서 이미지를 생성하는 확산
DALL-E는 Contrastive Image Language Pre-training을 사용합니다. (CLIP) 및 텍스트에서 이미지를 생성하는 확산
두 번째 방법은 기존 이미지를 활용하고 생성 모델을 사용하여 개인 취향에 따라 편집하는 것입니다. 예를 들어, 소나무 숲을 보여주는 이미지에서는 잔디에 버섯이 없습니다. 사용자는 시작점으로 적합한 이미지를 선택하고 생성 모델을 통해 여기에 버섯을 추가할 수 있습니다.

생성 AI는 발견과 창의성 사이의 경계를 모호하게 만드는 완전히 새로운 패러다임을 만듭니다. 그리고 단일 인터페이스 내에서 사용자는 이미지를 찾고, 이미지를 편집하고, 완전히 새로운 이미지를 만들 수 있습니다.
원제: 생성 AI가 이미지 검색을 재정의하는 방법, 저자: Ben Dickson
위 내용은 생성 AI가 이미지 검색을 재정의하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



