

최초의 중국어-영어 이중 언어 음성 대화 오픈 소스 대형 모델이 출시되었습니다!
요 며칠 arXiv에 대규모 음성 텍스트 다중 모달 모델에 관한 논문이 게재되었는데, 시그니처 회사 중에는 이카푸의 대형 모델 회사인 01.ai - 01.ai - 의 이름이 있었습니다.
 Picture
Picture
본 논문에서는 LLaSM이라는 상용 중국어-영어 이중 언어 대화 모델을 소개합니다. 이 모델은 녹음과 문자 입력을 지원할 뿐만 아니라 '하이브리드 복식' 기능도 구현할 수 있다. , 텍스트 입력을 통한 것이 아니라
대형 모델을 사용하며 일부 네티즌들은 이미 "누워서 대화하면서 코드 작성"하는 시나리오를 상상하고 있습니다. 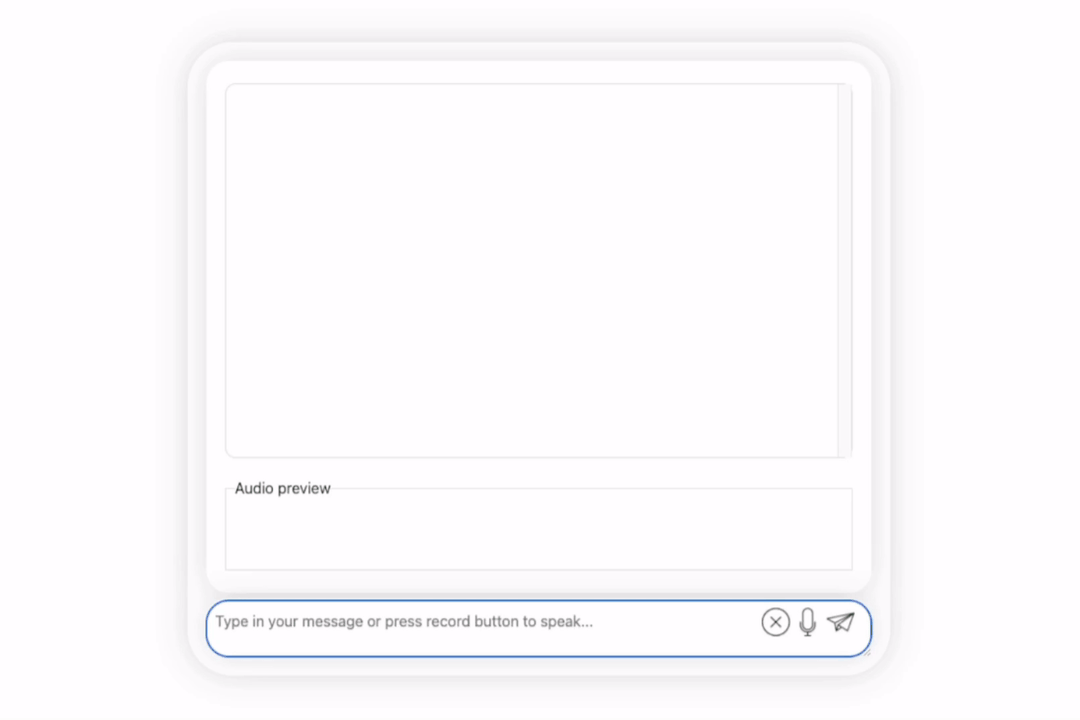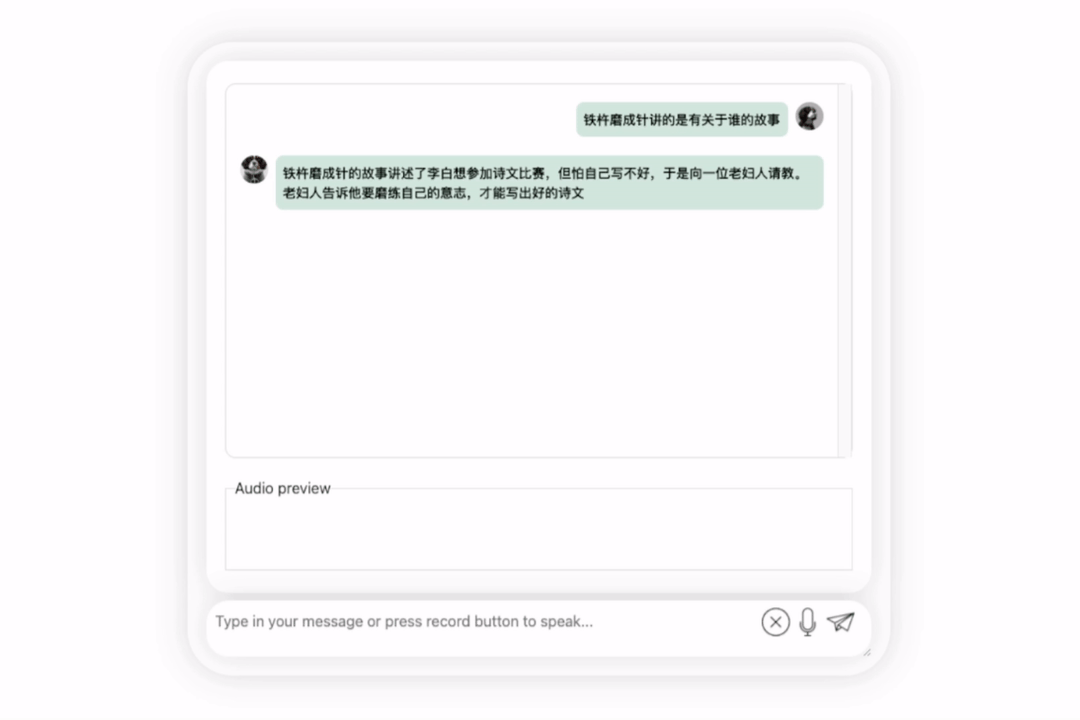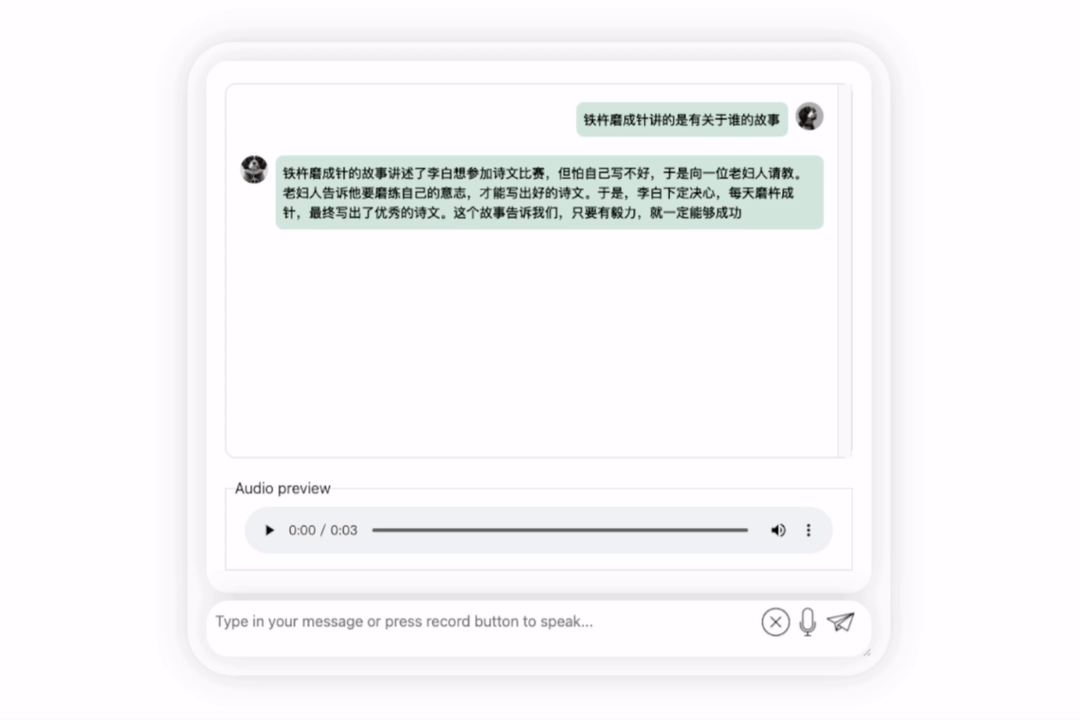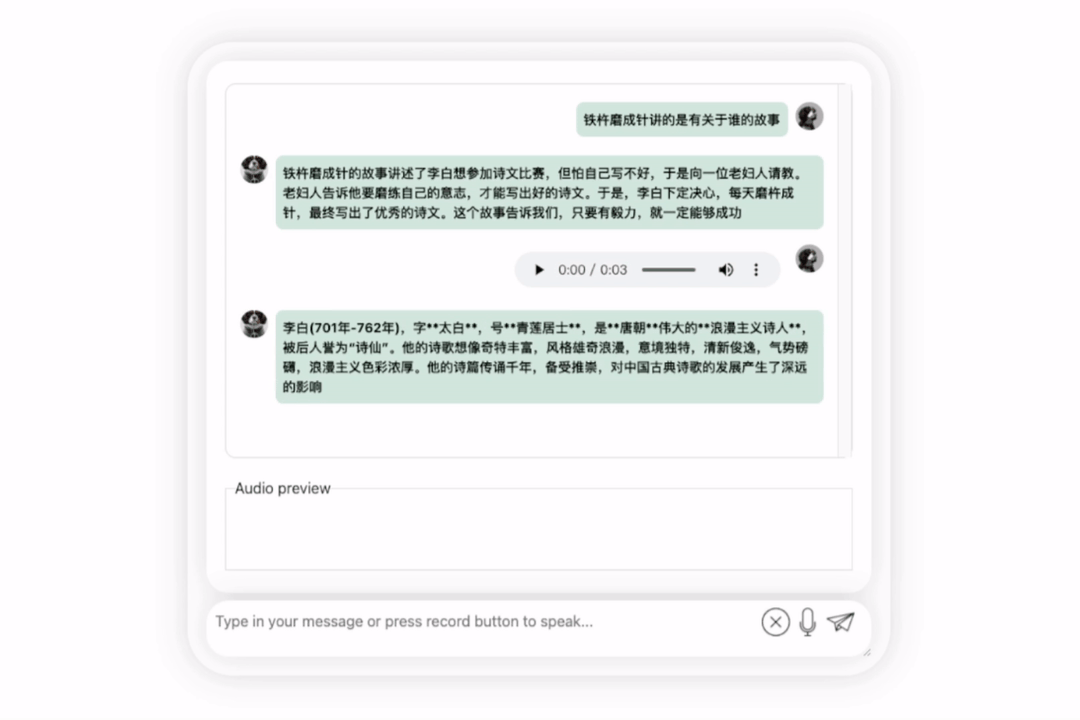
이 연구는 LinkSoul.AI, Peking University 및 01Wanwu가 공동으로 완료했습니다. 이제 오픈 소스이며 Huugian
 Pictures
Pictures
얼마나 효과적인지 살펴보겠습니다. 입니다
텍스트 음성 변환 입력을 지원하며 휴대폰에서도 재생할 수 있습니다. 연구원에 따르면 LLaSM은 중국어 및 영어 이중 언어 음성-텍스트 다중 모달 대화를 지원하는 최초의 오픈 소스이자 상용 소프트웨어입니다. 대화 모델 .
연구원에 따르면 LLaSM은 중국어 및 영어 이중 언어 음성-텍스트 다중 모달 대화를 지원하는 최초의 오픈 소스이자 상용 소프트웨어입니다. 대화 모델 .
괜찮습니다. 이백 왕조를 정확하게 설명합니다. 영어를 읽을 수 없다면 중국어로 직접 번역해도 문제가 없습니다.
 Pictures
Pictures
다음 연습에서는 "fried food"라는 단어를 in에 추가하여 중국어-영어 혼합 질문을 시도해 보겠습니다. 중국어 문장. 모델의 출력 효과도 매우 좋습니다.
 Pictures
Pictures
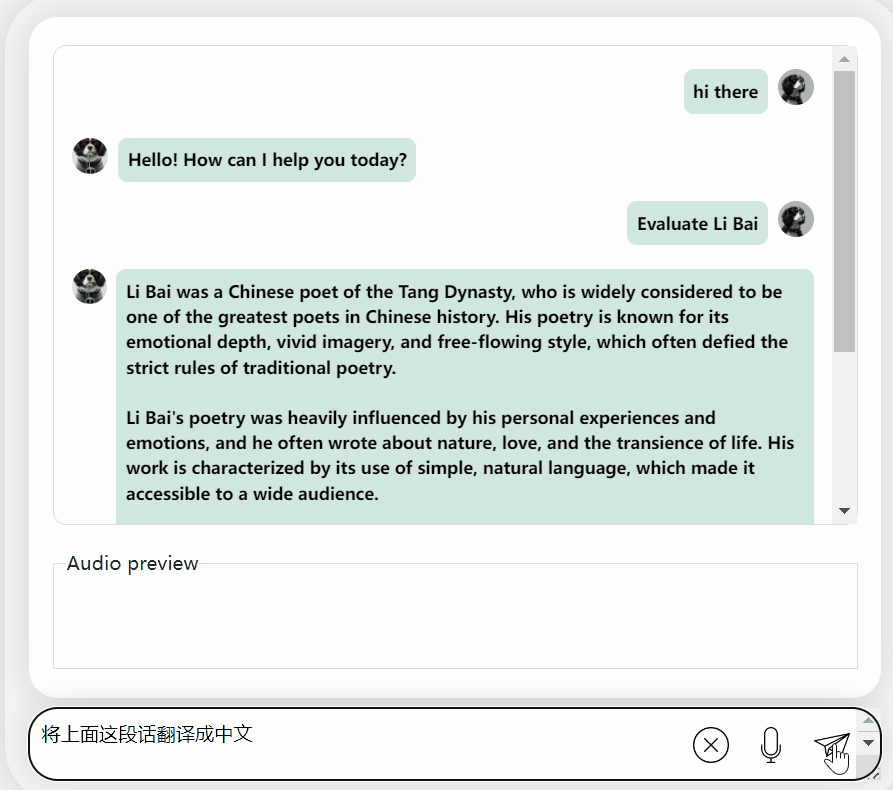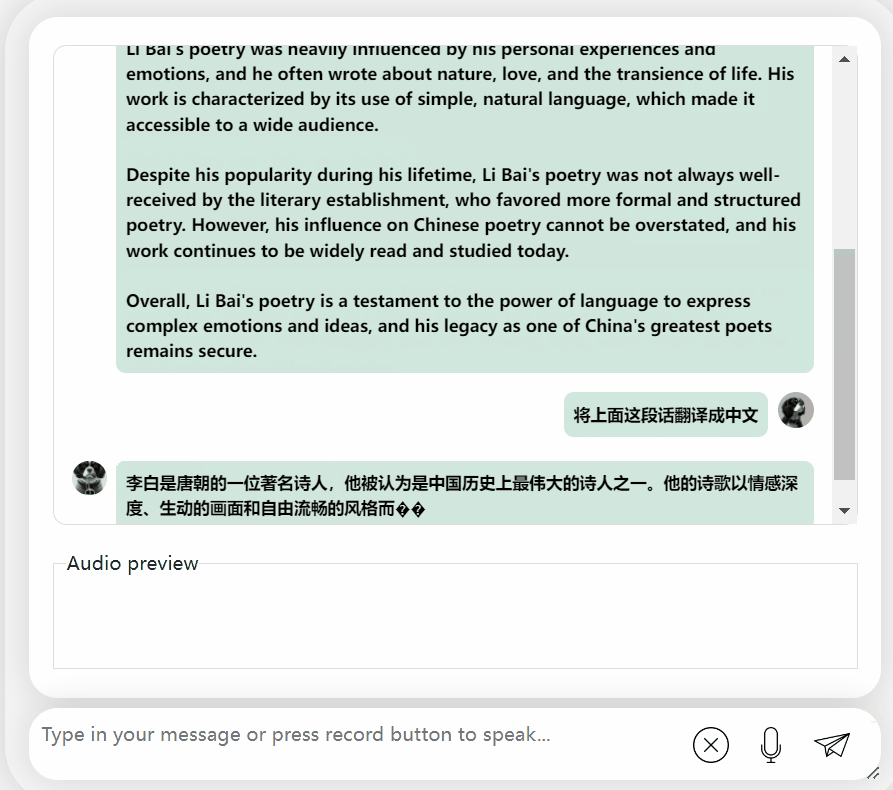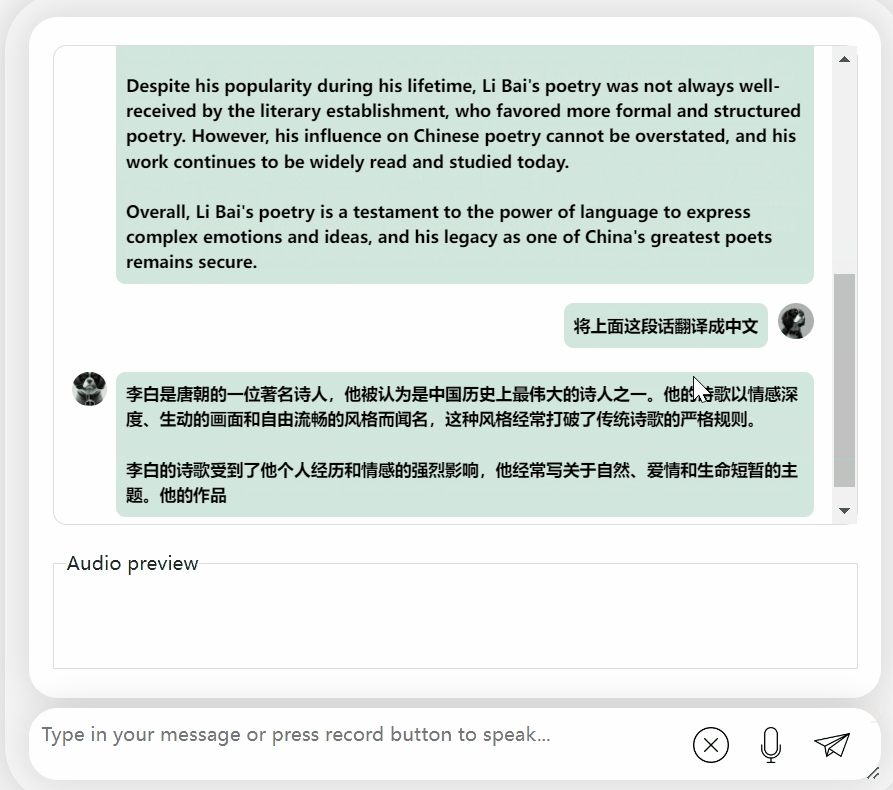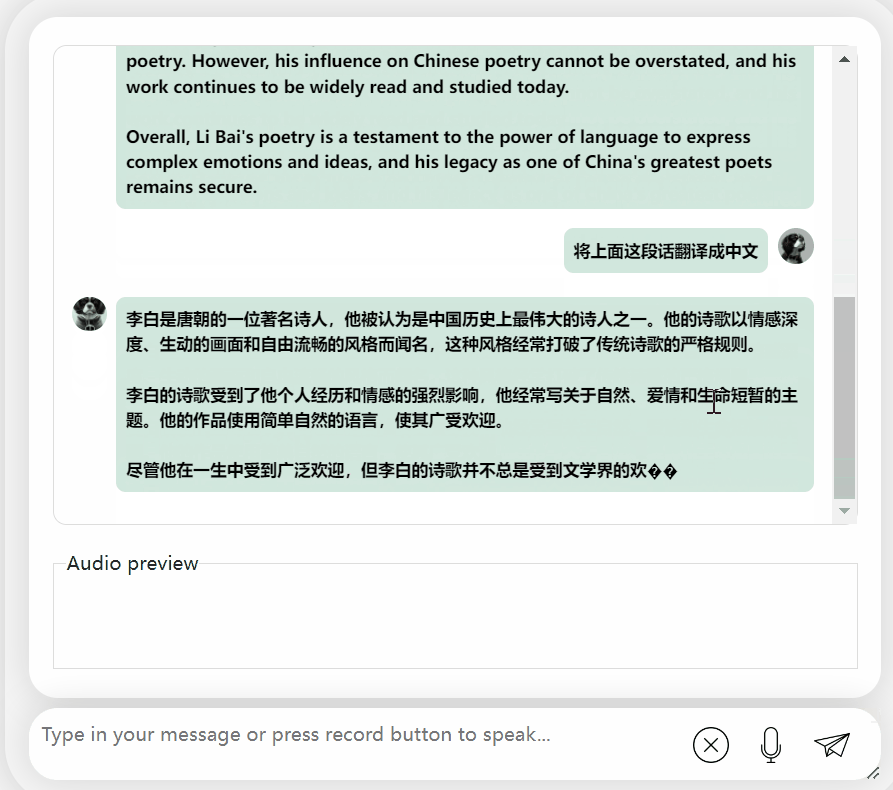
모델을 다시 시도하고 평가를 수행하여 Li Bai 또는 Du Fu 중 어느 것이 더 나은지 알아보겠습니다
오랜 고민 끝에 이 모델은 매우 객관적이고 중립적인 평가를 내릴 뿐만 아니라, 대형 모델(수동 개머리)에 필요한 기본 지식과 상식도 갖추고 있습니다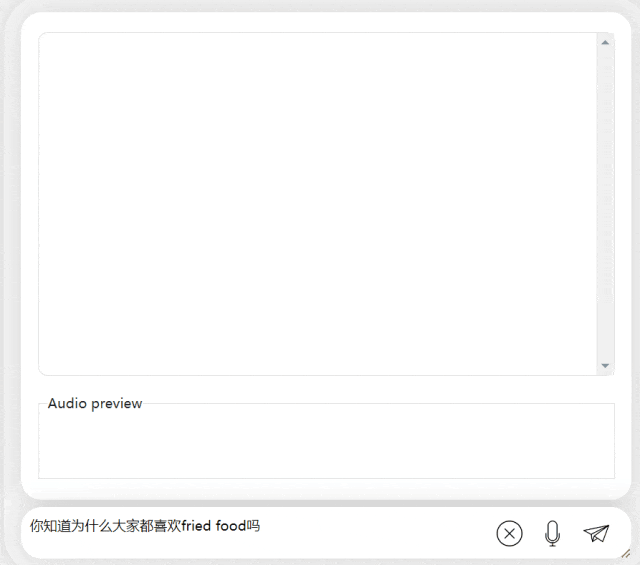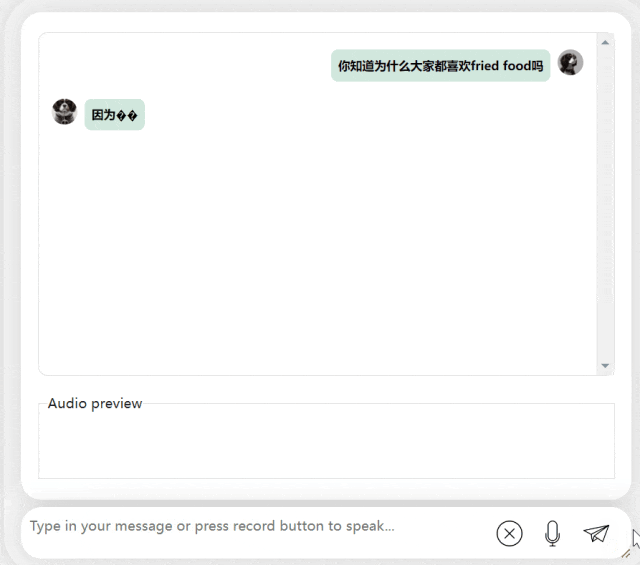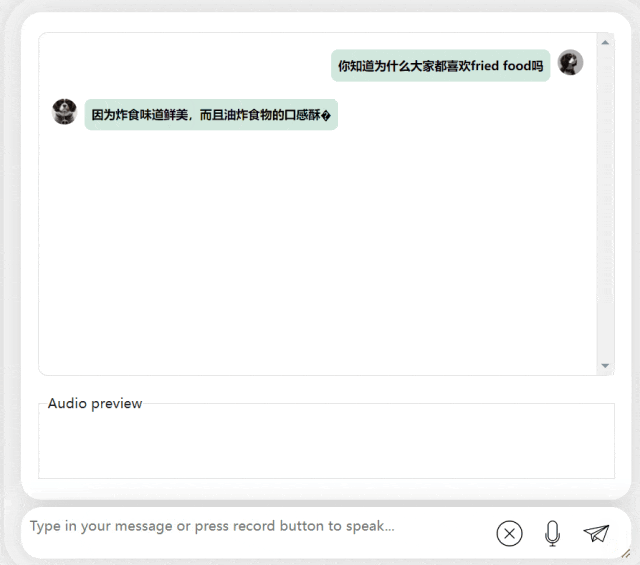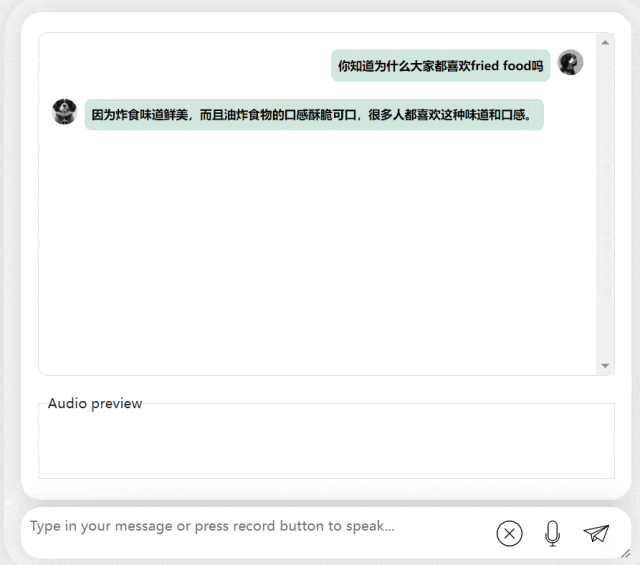
물론, 놀지 않고 놀 수도 있습니다 컴퓨터에서만 가능하지만 휴대폰에서도 가능합니다.
"나에게 레시피 추천"을 음성으로 입력하려고 합니다. 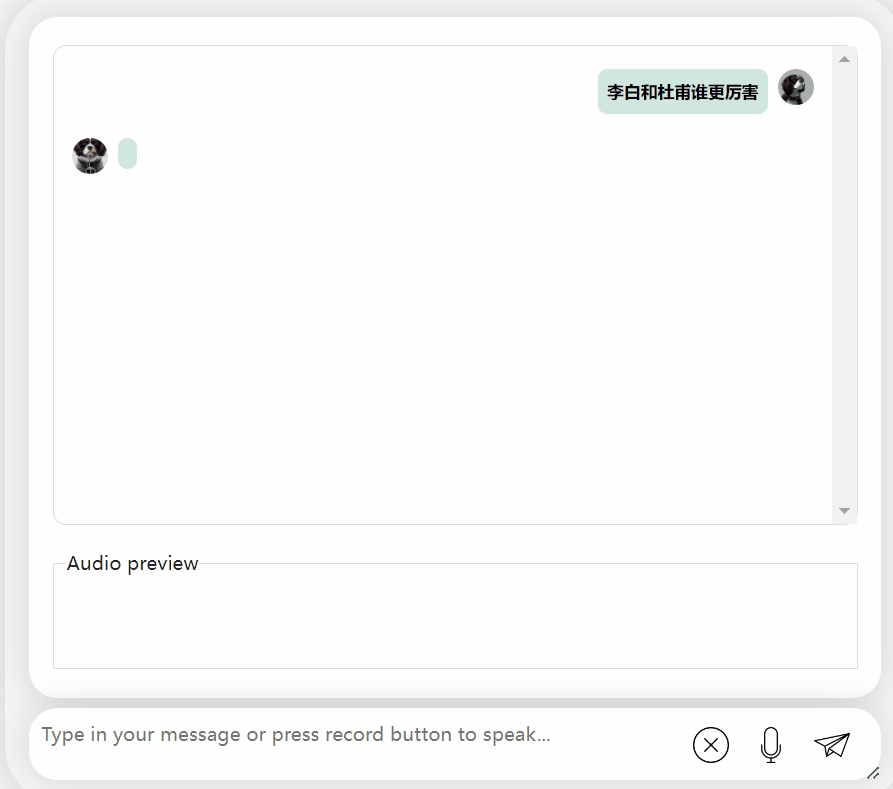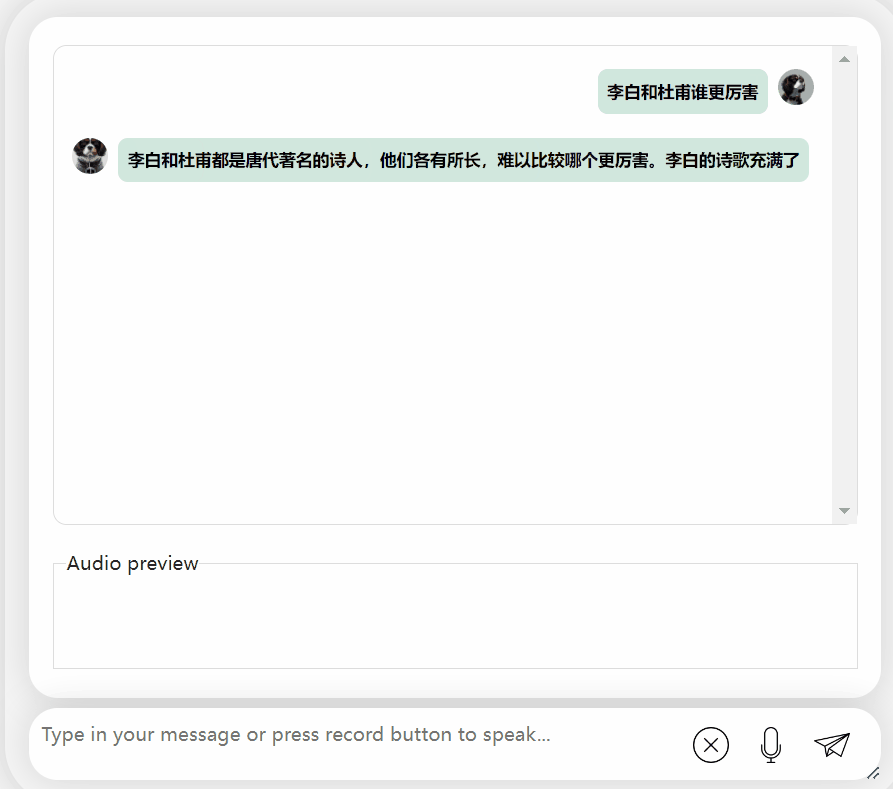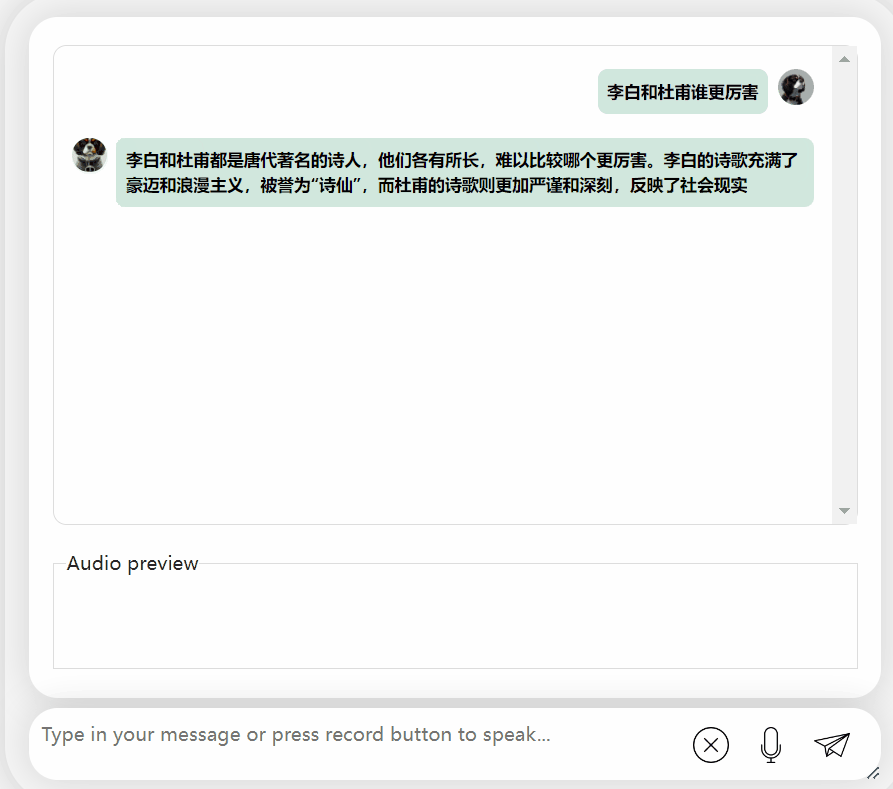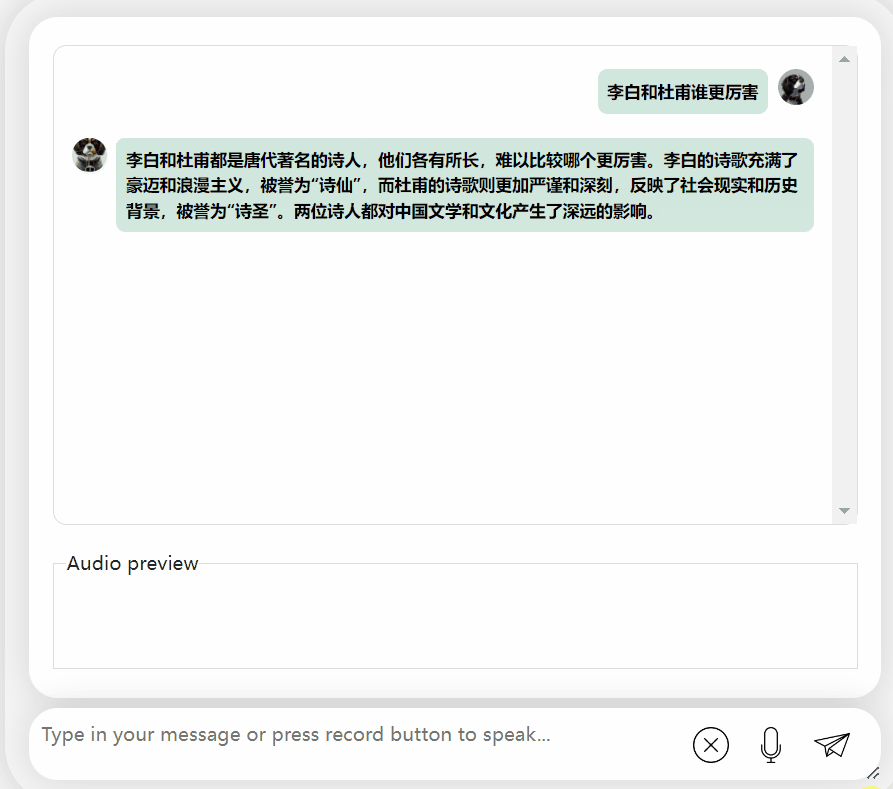 모델이 "가지 치즈" 레시피를 정확하게 출력하는 것을 볼 수 있지만, 맛있을지는 잘 모르겠습니다.
모델이 "가지 치즈" 레시피를 정확하게 출력하는 것을 볼 수 있지만, 맛있을지는 잘 모르겠습니다.
중국어와 영어가 섞여서 "테일러 스위프트의 레드"를 듣고 싶냐고 물었을 때 , 모델에 심각한 오류가 있어서 멈추지도 못하고 같은 문장을 계속해서 출력하고 있었습니다...
 Pictures
Pictures
전반적으로 중국어와 영어가 혼합된 질문이나 요청에 직면했을 때 모델 출력 성능은 여전히 좋지 않습니다.
하지만 분리해도 중국어, 영어 표현력은 여전히 좋습니다.
그렇다면 그러한 모델은 어떻게 구현되나요?
시험에 따르면 LLaSM에는 두 가지 주요 기능이 있습니다. 하나는 중국어와 영어 입력을 지원하는 것이고, 다른 하나는 음성과 텍스트의 이중 입력입니다.
이 두 가지 사항을 달성하려면 아키텍처와 교육 데이터를 각각 약간 조정해야 합니다.
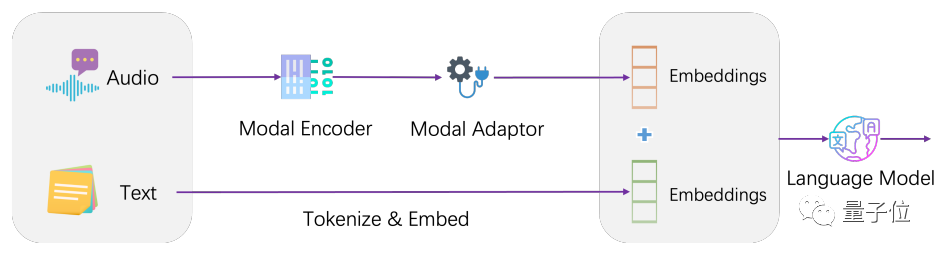
구조적으로 LLaSM은 현재 음성 인식 모델과 대규모 언어 모델을 통합합니다.
LLaSM은 자동 음성 인식 모델인 Whisper, 모달 어댑터, 대형 모델인 LLaMA 등 세 부분으로 구성됩니다.
이 과정에서 Whisper는 원본 음성 입력을 수신하고 음성 특징의 벡터 표현을 출력하는 역할을 담당합니다. 모달 어댑터의 역할은 음성 및 텍스트 임베딩을 정렬하는 것입니다. LLaMA는 음성 및 텍스트 입력 지침을 이해하고 응답
 사진
사진
을 생성하는 역할을 담당합니다. 모델 교육은 두 단계로 나뉩니다. 첫 번째 단계는 인코더와 대형 모델이 고정되어 모델이 음성과 텍스트의 정렬을 학습할 수 있도록 하는 모달리티 어댑터를 훈련하는 것입니다. 두 번째 단계는 인코더를 동결하고, 모달 어댑터 및 대형 모델을 훈련하여 모델의 다중 모달 대화 기능을 향상시키는 것입니다
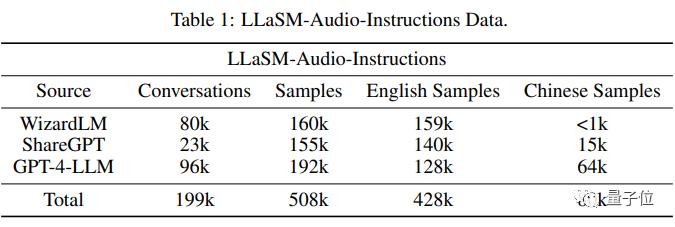
훈련 데이터에서 연구원들은 199,000개의 대화와 508,000개의 음성 텍스트 샘플 모음을 편집했습니다. 데이터세트 LLaSM -오디오 지침.
508,000개의 음성 텍스트 샘플 중 80,000개는 중국어 음성 샘플이고, 428,000개는 영어 음성 샘플입니다.
연구원들은 주로 WizardLM, ShareGPT, GPT-4-LLM과 같은 데이터 세트를 기반으로 텍스트 음성 변환을 통해 기술은 유효하지 않은 대화를 필터링하면서 이러한 데이터 세트에 대한 음성 패킷을 생성합니다.
 Pictures
Pictures
이것은 현재 데이터 세트에 이어 최대 규모의 중국어 및 영어 음성 텍스트 명령이지만 아직 정리 중입니다. 연구원에 따르면 정리된 후 오픈 소스로 제공될 예정입니다.
그러나 현재 이 논문의 출력 효과를 다른 음성 모델 또는 텍스트 모델과 비교한 것은 없습니다.
이 논문의 저자는 LinkSoul.AI, Peking University 및 Zero One Thing 출신입니다
공동 저자인 Yu Shu와 Siwei Dong은 모두 LinkSoul.AI 출신이며 이전에는 베이징 Zhiyuan 인공 지능 연구소에서 근무했습니다.
LinkSoul.AI는 이전에 최초의 오픈소스 Llama 2 대형 중국어 모델을 출시한 AI 스타트업 회사입니다.
 Pictures
Pictures
이개푸씨가 소유한 대형 모델회사로 제로원과 원월드도 이번 연구에 기여했습니다. 작가 Wenhao Huang의 Hugging Face 페이지에는 그가 푸단대학교를 졸업했다고 나와 있습니다.
 Pictures
Pictures
문서 주소:
//m.sbmmt.com/link/47c917b09f2bc64b2916c0824c715923
데모 주소:
//m.sbmmt.com/link/ bcd 0049c35799cdf57d06eaf2eb3cff6
위 내용은 새로운 대규모 음성 대화 모델이 중국에서 출시되었습니다. Kai-Fu Lee가 주도하고 Zero One and All이 참여하여 중국어 및 영어 이중 언어 및 다중 양식 지원, 오픈 소스 및 상용화 가능의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



