

이 작업에서는 다중 프레임 포인트 클라우드로부터 밀집된 점유 래스터 데이터 세트를 구축하고 변환기 기반 2D-3D Unet 구조를 기반으로 3차원 점유 래스터 네트워크를 설계했습니다. 우리 기사가 ICCV 2023에 포함된 것을 영광으로 생각합니다. 프로젝트 코드는 이제 오픈 소스이며 누구나 사용해 볼 수 있습니다.

arXiv: https://arxiv.org/pdf/2303.09551.pdf
코드: https://github.com/weiyithu/SurroundOcc
홈페이지 링크: https://weiyithu.github.io/ SurroundOcc/
저는 최근에 미친듯이 일자리를 찾고 있었는데, 글을 쓸 시간이 없었습니다. 최근에 작업이 끝나면서 글을 쓰는 것이 좋겠다고 생각했습니다. 지후 요약. 실제로 기사의 소개글은 이미 각종 공개 계정에서 잘 작성되어 있으며, 그 홍보 덕분에 자율주행의 심장, nuScenes SOTA를 직접 참고하실 수 있습니다! SurroundOcc: 자율 주행을 위한 순수 시각적 3D 점유 예측 네트워크(Tsinghua & Tianda). 일반적으로 기여는 두 부분으로 나누어집니다. 첫 번째 부분은 다중 프레임 LiDAR 포인트 클라우드를 사용하여 밀집된 점유 데이터 세트를 구축하는 방법이고, 다른 부분은 점유 예측을 위한 네트워크를 설계하는 방법입니다. 사실 두 부분의 내용은 비교적 간단하고 이해하기 쉽습니다. 이해가 안 되는 부분이 있으면 언제든지 저에게 물어보세요. 그래서 이번 글에서는 논제보다는 좀 더 쉽게 배포할 수 있도록 현재 솔루션을 개선하는 방법과 향후 개발 방향에 대해 이야기하고 싶습니다.
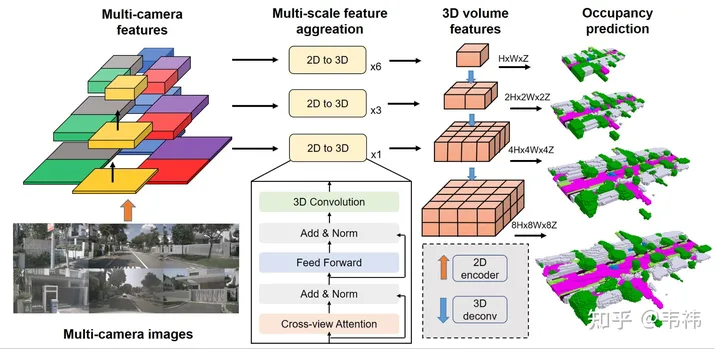
네트워크 배포가 쉬운지는 주로 보드 측에서 구현하기 어려운 연산자가 있는지 여부에 따라 다릅니다. SurroundOcc 방법에서 더 어려운 두 연산자는 변환기입니다. 레이어와 3D 컨볼루션.
변환기의 주요 기능은 2D 기능을 3D 공간으로 변환하는 것입니다. 실제로 이 부분은 LSS, Homography 또는 심지어 mlp를 사용하여 구현할 수도 있으므로 구현된 솔루션에 따라 네트워크의 이 부분을 수정할 수 있습니다. 하지만 제가 아는 한, 변압기 솔루션은 교정에 민감하지 않으며 여러 솔루션 중에서 성능이 더 좋습니다. 변압기 배포를 구현할 수 있는 능력이 있는 사람은 원래 솔루션을 사용하는 것이 좋습니다.
3D 컨볼루션의 경우 이를 2D 컨볼루션으로 대체할 수 있습니다. 여기서는 (C, H, W, Z)의 원래 3D 기능을 (C* Z, H, W)의 2D 기능으로 재구성해야 합니다. 특징 추출을 위해 2D 컨볼루션을 사용할 수 있습니다. 최종 점유 예측 단계에서는 이를 다시 (C, H, W, Z)로 재구성하고 감독을 수행합니다. 반면에 건너뛰기 연결은 더 큰 해상도로 인해 더 많은 비디오 메모리를 소비합니다. 배포 중에 제거할 수 있으며 최소 해상도 레이어만 남습니다. 우리의 실험에 따르면 3D 컨볼루션의 이 두 가지 작업에는 누신에 대한 일부 낙하점이 있지만 업계 데이터 세트의 규모는 누신보다 훨씬 크고 때로는 일부 결론이 변경되어 낙하점이 적거나 아예 없어야 한다는 사실이 밝혀졌습니다.
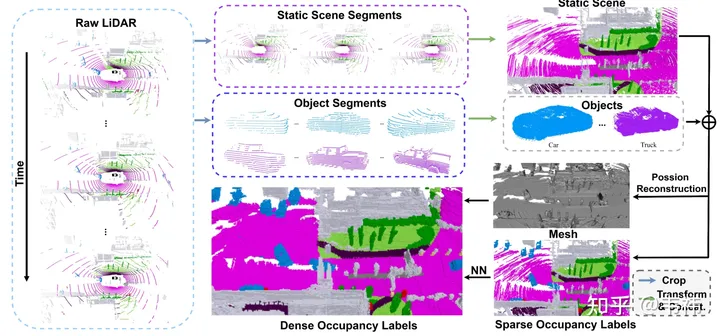
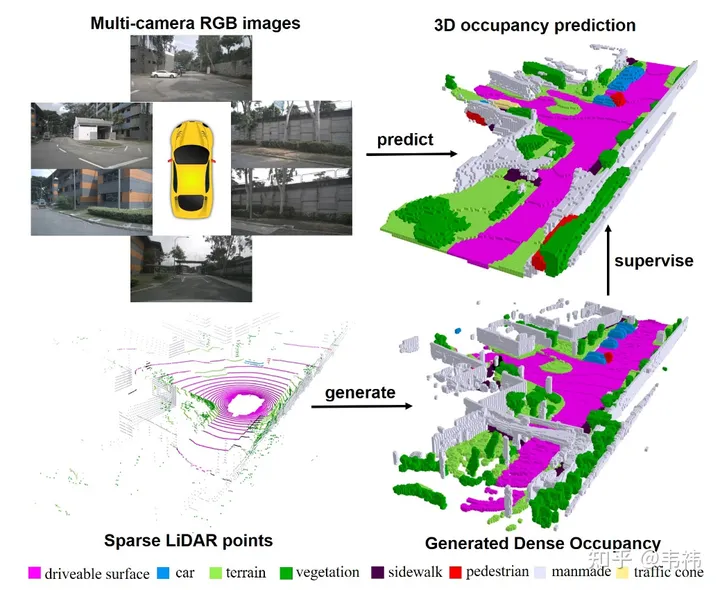
데이터세트 구성 측면에서 가장 시간이 많이 걸리는 단계는 포아송 재구성입니다. 우리는 수집을 위해 32라인 LiDAR를 사용하는 Nuscenes 데이터 세트를 사용합니다. 다중 프레임 스티칭 기술을 사용하더라도 스티칭된 포인트 클라우드에 여전히 많은 구멍이 있음을 발견했습니다. 따라서 우리는 이러한 구멍을 메우기 위해 포아송 재구성을 사용했습니다. 그러나 현재 업계에서 사용되는 많은 LiDAR 포인트 클라우드는 M1, RS128 등과 같이 상대적으로 밀도가 높습니다. 따라서 이 경우 포아송 재구성 단계를 생략하여 데이터 세트 구성 속도를 높일 수 있습니다
반면 SurroundOcc는 Nuscene에 주석이 달린 3차원 타겟 탐지 프레임을 사용하여 정적 장면과 동적 개체를 구분합니다. 그러나 실제 응용에서는 대형 3차원 표적 탐지 및 추적 모델인 autolabel을 사용하여 전체 시퀀스에서 각 객체의 탐지 프레임을 얻을 수 있습니다. 수동으로 주석을 추가한 레이블과 비교할 때 대형 모델을 사용하여 생성된 결과에는 확실히 약간의 오류가 있습니다. 가장 직접적인 징후는 여러 프레임의 객체를 이어붙인 후 나타나는 고스팅 현상입니다. 그러나 실제로 직업에서는 물체의 모양에 대한 요구 사항이 그렇게 높지 않습니다. 감지 프레임의 위치가 상대적으로 정확하면 요구 사항을 충족할 수 있습니다.
현재 방법은 여전히 LiDAR를 사용하여 점유 감독 신호를 제공하지만 많은 자동차, 특히 일부 저수준 보조 운전 차량에는 LiDAR를 통해 대량의 RGB 데이터를 다시 전송할 수 있습니다. 섀도우 모드를 선택하면 향후 방향은 RGB를 자기 지도 학습에만 사용할 수 있는지 여부입니다. 자연스러운 해결책은 감독을 위해 NeRF를 사용하는 것입니다. 구체적으로 전면 백본 부분은 그대로 유지하여 점유 예측을 얻은 다음 복셀 렌더링을 사용하여 각 카메라 관점에서 RGB를 얻고 손실은 실제 값 RGB로 수행됩니다. 훈련 세트를 생성합니다. 하지만 이 간단한 방법을 시도해 보았는데 별로 효과가 없었던 것은 아쉽습니다. 가능한 이유는 야외 장면의 범위가 너무 넓어서 너프가 감당할 수 없을 수도 있지만 그럴 수도 있습니다. 제대로 조정되지 않았습니다. 다시 시도해 보세요.
다른 방향은 타이밍과 직업 흐름입니다. 실제로 점유 흐름은 단일 프레임 점유보다 다운스트림 작업에 훨씬 더 유용합니다. ICCV 중에는 점유 흐름에 대한 데이터 세트를 컴파일할 시간이 없었고, 논문을 출판할 때 많은 흐름 기준선을 비교해야 했기 때문에 그 당시에는 작업을 하지 않았습니다. 타이밍 네트워크의 경우 상대적으로 간단하고 효과적인 BEVFormer 및 BEVDet4D 솔루션을 참조할 수 있습니다. 여전히 어려운 부분은 흐름 데이터 세트입니다. 일반 개체는 시퀀스의 3차원 타겟 감지 프레임을 사용하여 계산할 수 있지만 작은 동물 비닐봉지와 같은 특수한 모양의 개체는 장면 흐름 방법을 사용하여 주석을 추가해야 할 수 있습니다.

다시 작성해야 하는 내용은 다음과 같습니다. 원본 링크: https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug
위 내용은 SurroundOcc: 서라운드 3D 점유 그리드 새로운 SOTA!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



