원격의료의 등장으로 환자들은 편리하고 효율적인 의료지원을 위해 온라인 상담과 상담을 선택하는 경향이 점점 더 커지고 있습니다. 최근 LLM(대형 언어 모델)은 강력한 자연어 상호 작용 기능을 시연하여 건강 및 의료 보조자가 사람들의 삶에 들어갈 수 있다는 희망을 가져왔습니다
의료 및 건강 상담 시나리오는 일반적으로 복잡하고 개인적인 보조자가 필요합니다. 폭넓은 의학적 지식과 여러 차례의 대화를 통해 환자의 의도를 이해하고 전문적이고 상세한 답변을 제공할 수 있는 능력을 갖추고 있습니다. 의료 및 건강 상담에 직면할 때 보편적 언어 모델은 의학 지식 부족으로 인해 말하기를 피하거나 질문에 잘못 대답하는 동시에 현재 질문에 대한 상담을 완료하는 경향이 있으며 만족스러운 다단계 질문 기능이 부족합니다. 또한 현재 고품질의 중국 의료 데이터 세트는 매우 드물기 때문에 의료 분야에서 강력한 언어 모델을 훈련하는 데 어려움을 겪고 있습니다. 푸단대학교 데이터 인텔리전스 및 소셜 컴퓨팅 연구소(FudanDISC)는 중국 의료 및 건강 개인 비서인 DISC-MedLLM을 출시했습니다. 단일 라운드 질의응답 및 다중 라운드 대화의 의료 및 건강 상담 평가에서 모델의 성능은 기존 대규모 의료 대화 모델에 비해 분명한 이점을 보여줍니다. 연구팀은 또한 47만명의 사람들이 포함된 고품질 감독 미세 조정(SFT) 데이터 세트인 DISC-Med-SFT를 공개했습니다. 모델 매개변수와 기술 보고서도 오픈 소스입니다.
- 홈페이지 주소: https://med.fudan-disc.com
- Github 주소: https://github.com/FudanDISC/DISC-MedLLM
- 기술 보고서: https: //arxiv.org/abs/2308.14346

환자가 몸 상태가 좋지 않을 때 물어볼 수 있습니다. 모델은 귀하의 증상을 설명하며, 모델은 참고로 가능한 원인, 권장 치료 계획 등을 제시합니다. 정보가 부족한 경우 증상에 대한 자세한 설명을 적극적으로 요청합니다. 
사용자는 자신의 건강 상태에 따라 모델별 상담 질문을 할 수도 있으며 모델은 상세하고 유용한 답변을 제공합니다. 정보가 부족한 경우 적극적으로 질문하여 응답의 타당성과 정확성을 높입니다. 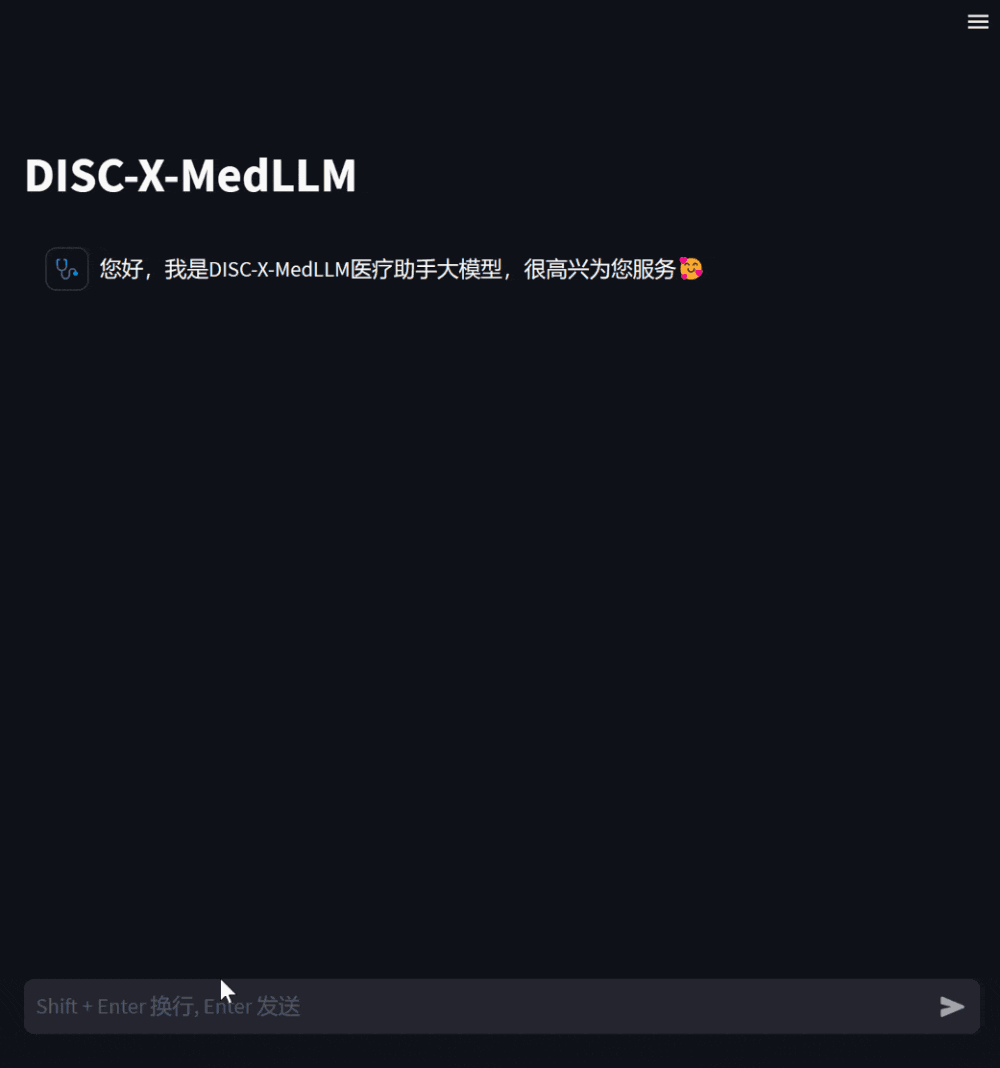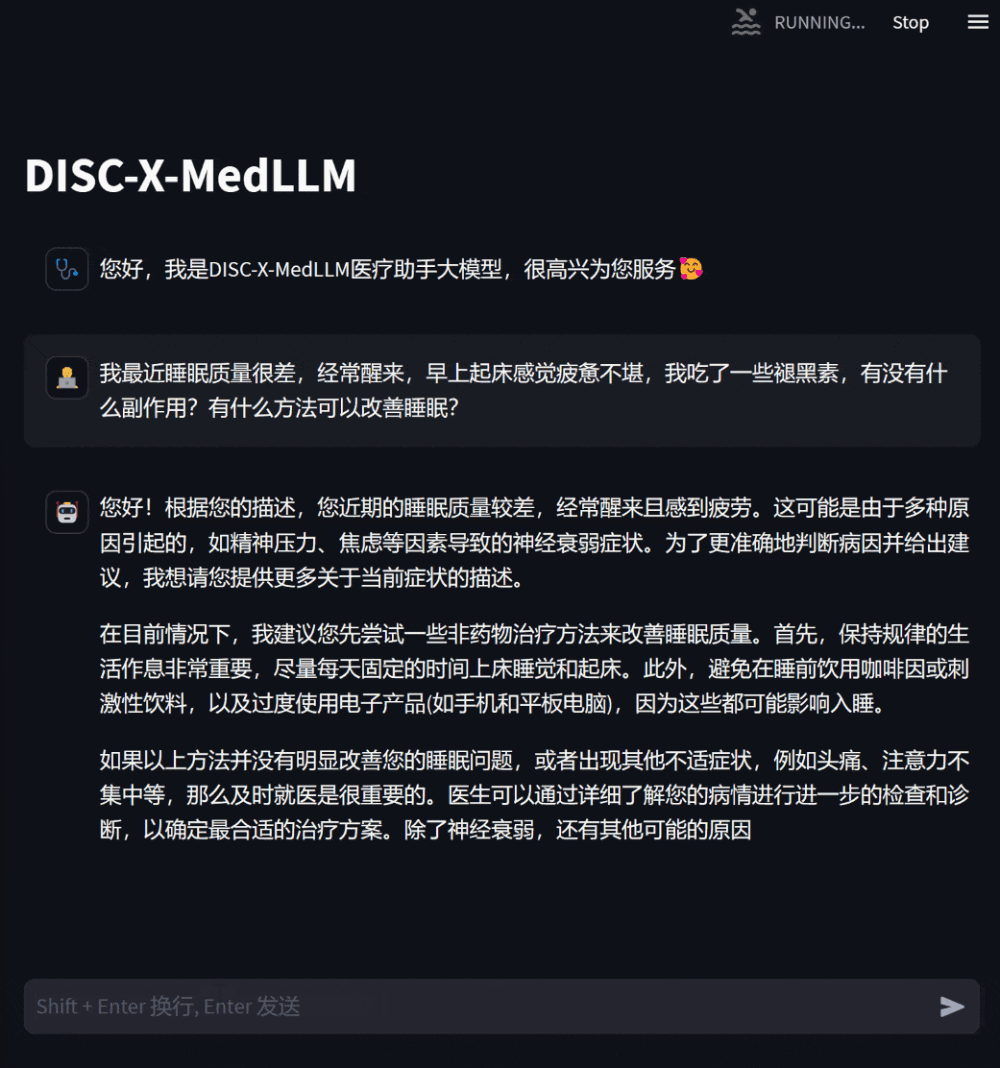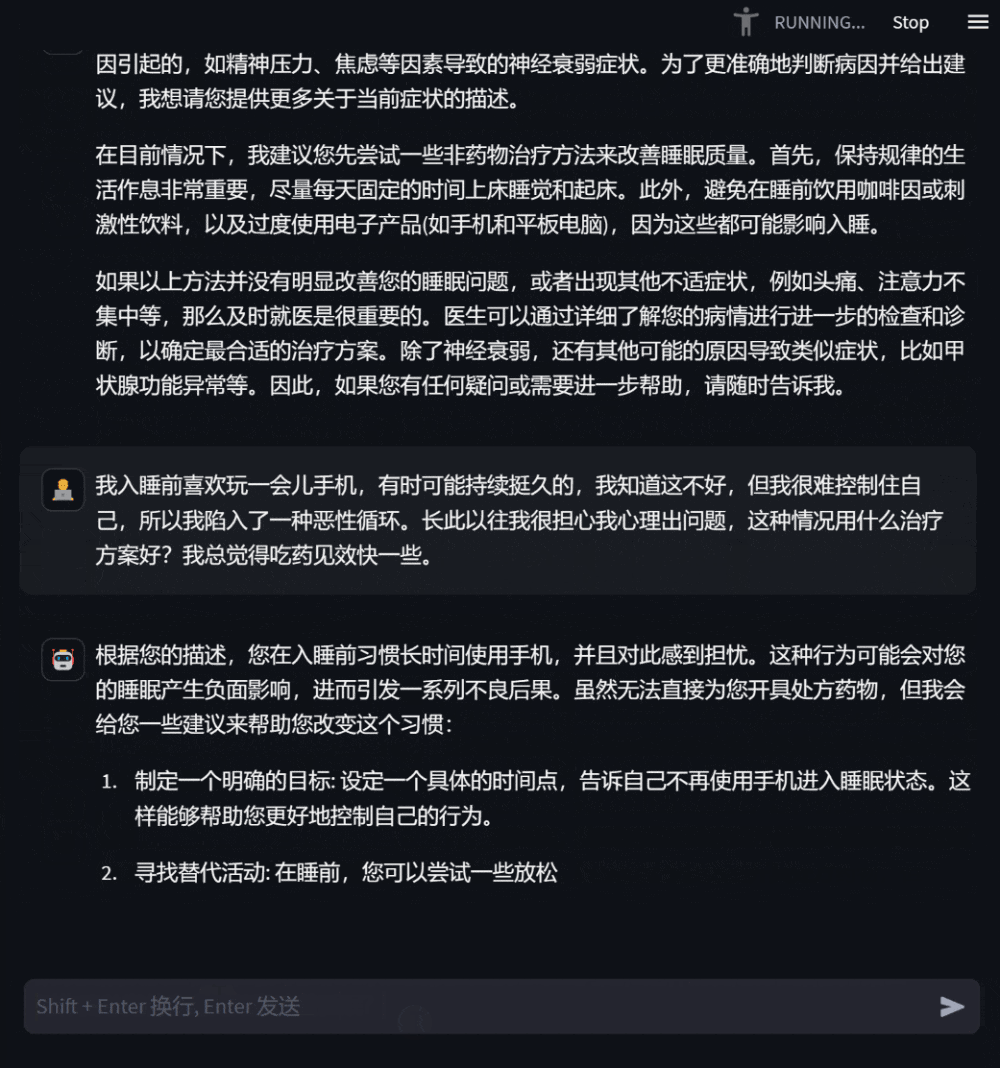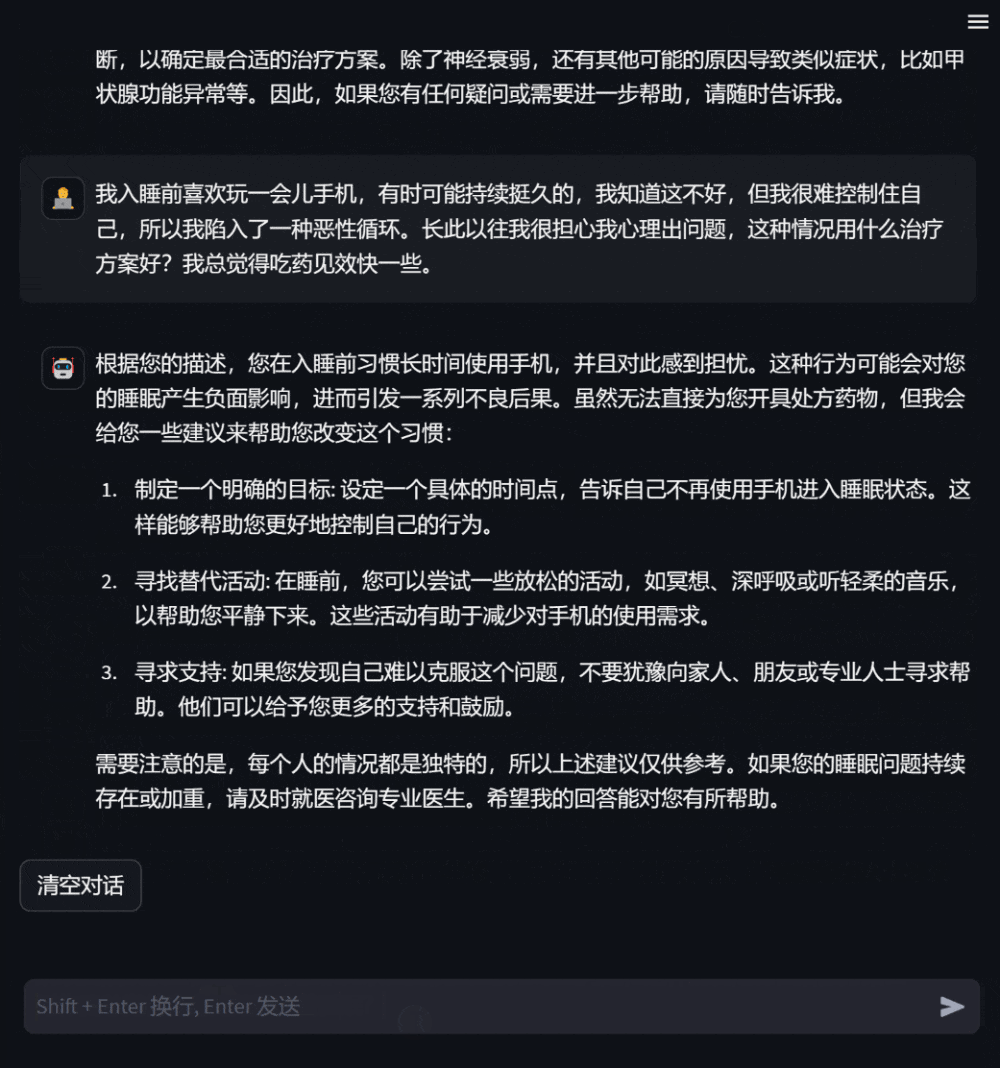
그림 3: 자신의 건강 상태에 대한 상담을 기반으로 한 대화사용자는 자신과 관련 없는 의학 지식에 대해서도 질문할 수 있습니다. 이때 모델은 답변합니다. 최대한 전문적으로 사용자가 포괄적이고 정확하게 이해할 수 있도록 합니다. 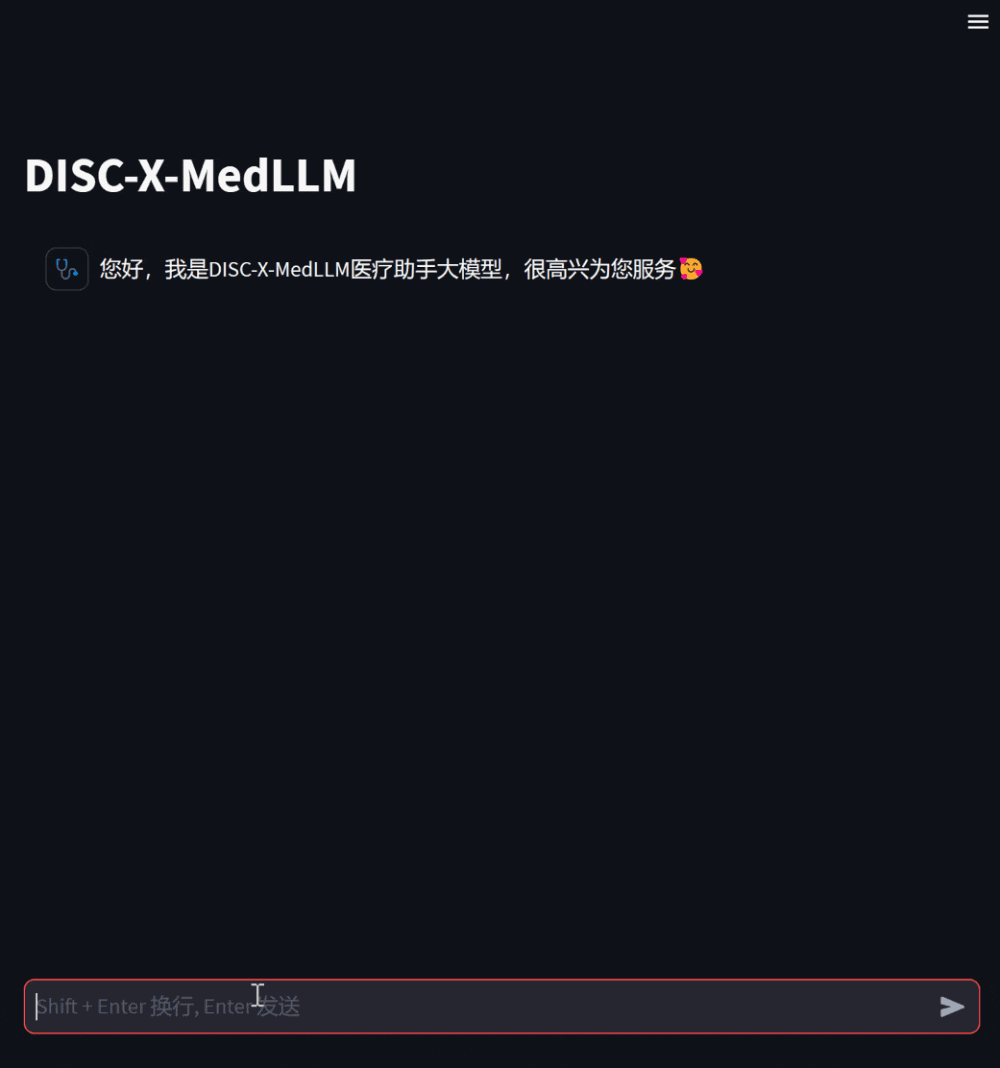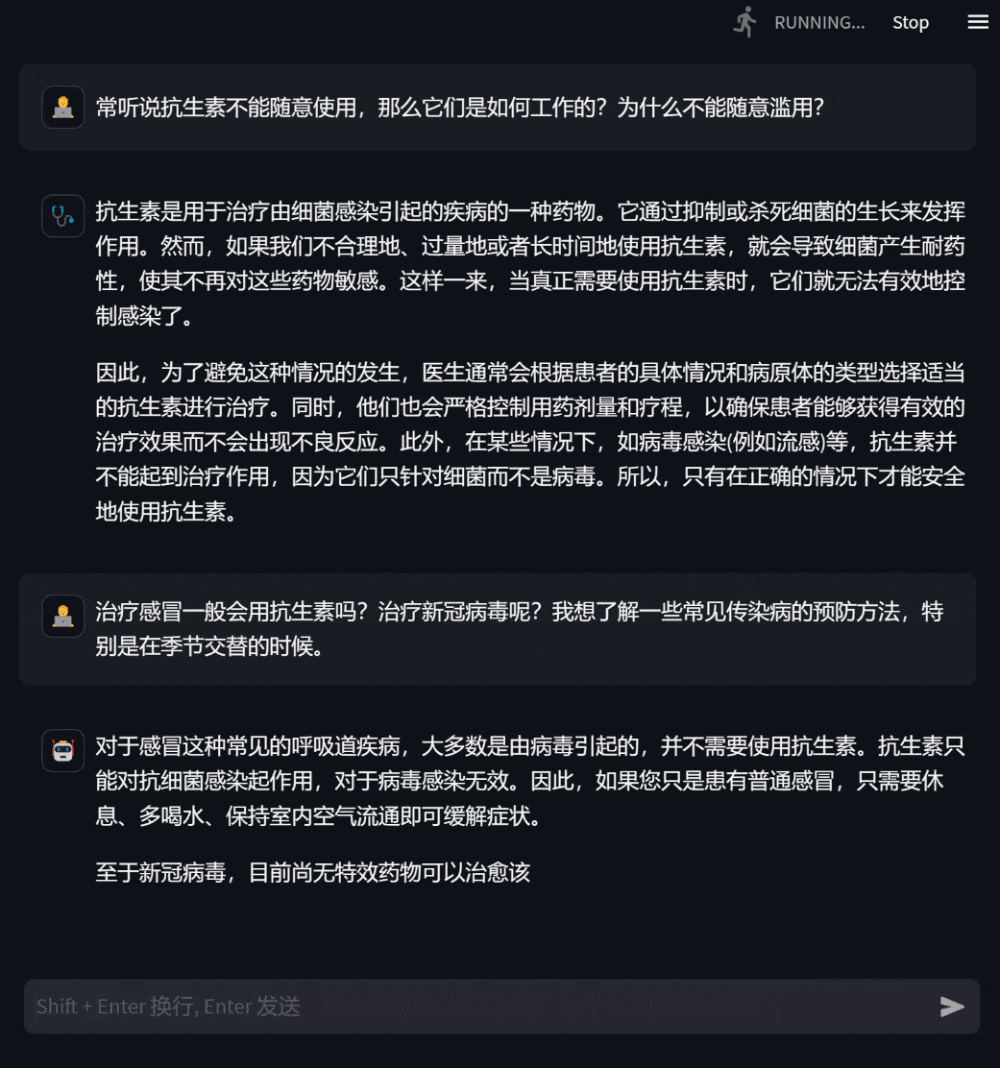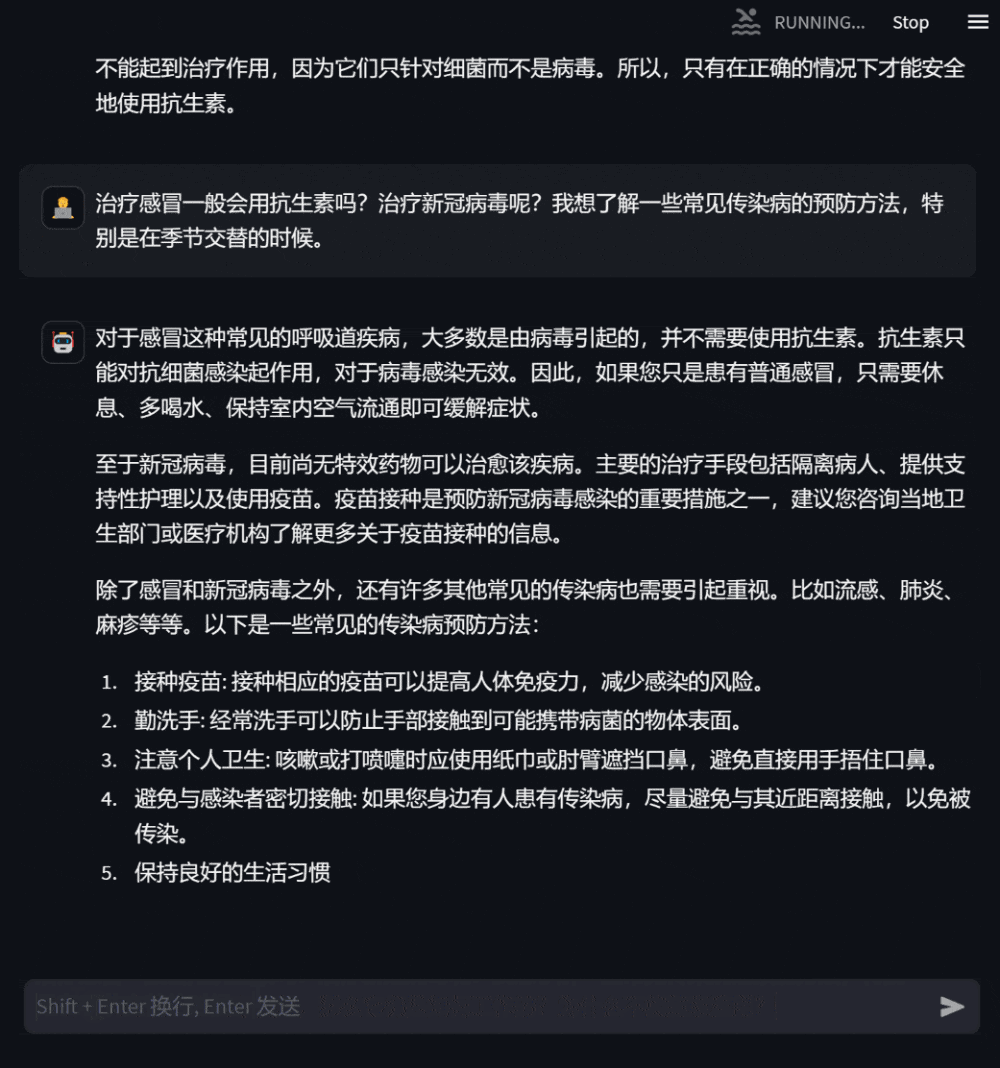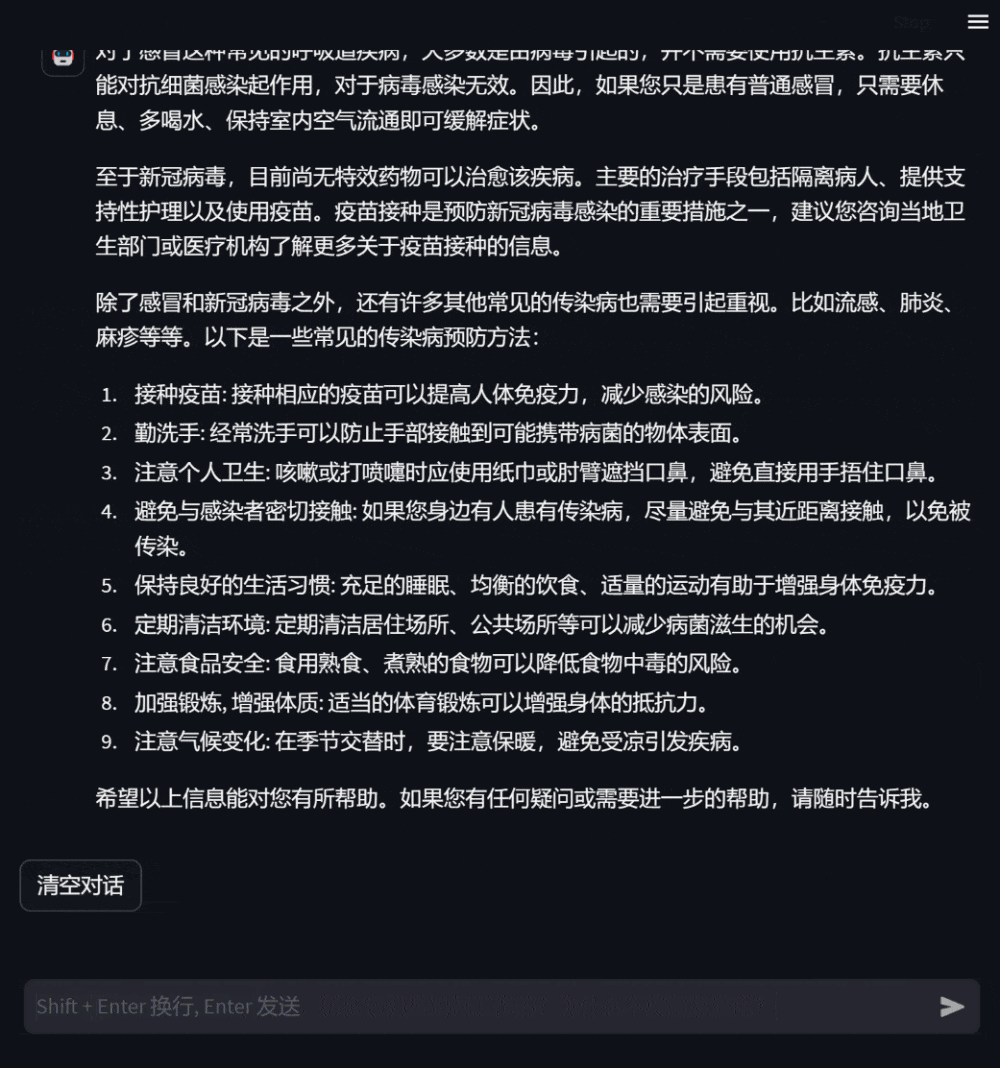
그림 4: 자신과 관련 없는 의학 지식 문의 대화DISC-MedLLM은 우리가 구축한 고품질 데이터세트 DISC-Med-SFT를 기반으로 합니다. 일반 도메인 중국 대형 모델 Baichuan-13B에 대해 훈련된 대형 의료 모델입니다. 우리의 훈련 데이터와 훈련 방법은 모든 기본 대형 모델에 적용될 수 있다는 점은 주목할 가치가 있습니다. DISC-MedLLM에는 세 가지 주요 기능이 있습니다.
- 신뢰할 수 있고 풍부한 전문 지식. 우리는 의학 지식 그래프를 정보 소스로 사용하고, 트리플을 샘플링하고, 일반 대형 모델의 언어 기능을 사용하여 대화 샘플을 구성합니다.
- 다양한 대화를 위한 심문 능력. 우리는 실제 상담 대화 기록을 정보 소스로 사용하고 대화를 재구성하기 위해 대형 모델을 사용합니다. 구축 과정에서 모델은 대화의 의료 정보를 완벽하게 정렬해야 합니다.
- 사람의 선호도에 맞춰 응답을 정렬하세요. 환자는 상담 과정에서 더 풍부한 지원 정보와 배경 지식을 얻기를 원하지만 인간 의사의 답변은 수동 검사를 통해 간결한 경우가 많습니다. 우리는 환자의 요구에 맞춰 고품질의 소규모 지침 샘플을 구성합니다.
모델과 데이터 구성 프레임워크의 장점은 그림 5에 나와 있습니다. 우리는 의료 지식 그래프와 실제 상담 데이터를 기반으로 데이터 세트의 샘플 구성을 안내하기 위해 실제 상담 시나리오에서 환자의 실제 분포를 계산했습니다. 데이터 세트를 구성하는 루프입니다. 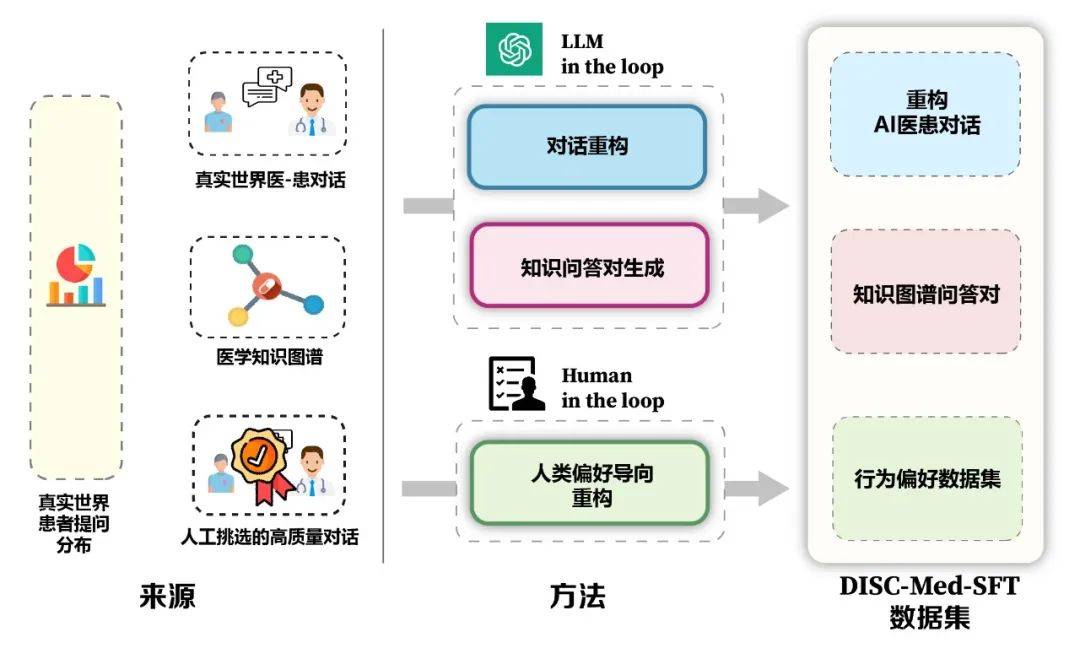
3. 방법: 데이터 세트 DISC-Med-SFT 구성 모델 훈련 과정, DISC-Med-SFT를 일반 도메인 데이터 세트와 기존 말뭉치의 데이터 샘플로 보완하여 DISC-Med-SFT-ext를 구성했습니다. 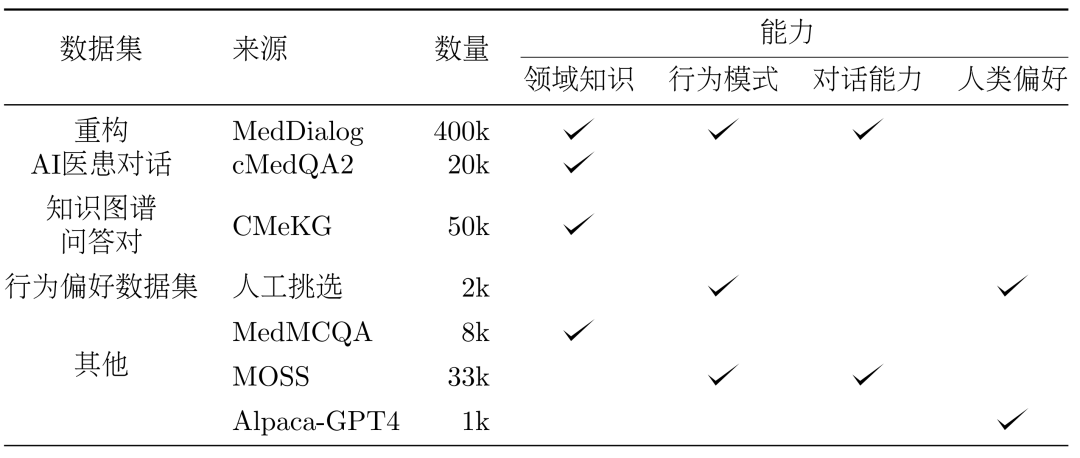
표 1: DISC-Med-SFT-ext 데이터 콘텐츠 소개데이터 세트. SFT 데이터 세트 구성을 위한 소스 샘플로 각각 2개의 공개 데이터 세트인 MedDialog와 cMedQA2에서 400,000개와 20,000개의 샘플을 무작위로 선택했습니다. 리팩토링. 실제 의사의 답변을 필요한 고품질의 균일한 형식의 답변으로 조정하기 위해 GPT-3.5를 활용하여 이 데이터 세트의 재구성 프로세스를 완료했습니다. 프롬프트는 다음 원칙을 따르도록 다시 작성해야 합니다.
- 언어적 표현을 제거하고 통일된 표현을 추출하며 의사의 언어 사용에서 불일치를 수정합니다.
- 원래 의사의 답변에 담긴 핵심 정보를 고수하고 보다 포괄적이고 논리적이 되도록 적절한 설명을 제공하세요.
- 환자에게 예약을 요청하는 등 AI 의사가 보내면 안 되는 답변을 다시 작성하거나 삭제하세요.
그림 6은 리팩토링의 예를 보여줍니다. 조정된 의사의 답변은 AI 의료보조자의 아이덴티티와 일치하며, 원의사가 제공한 핵심 정보는 그대로 유지하면서도 환자에게 더욱 풍부하고 포괄적인 도움을 제공한다. 
의학 지식 그래프에는 잘 정리된 많은 양의 의학 전문 지식이 포함되어 있습니다. QA 교육 샘플이 생성됩니다. CMeKG를 기반으로 질병 노드의 부서 정보에 따라 지식 그래프에서 샘플링하고 적절하게 설계된 GPT-3.5 모델 프롬프트를 사용하여 총 50,000개 이상의 다양한 의료 현장 대화 샘플을 생성했습니다. 학습의 마지막 단계에서는 모델의 성능을 더욱 향상시키기 위해 2차 학습에 대한 인간의 행동 선호도와 더 일치하는 데이터 세트를 사용합니다. 미세 조정을 감독했습니다. MedDialog와 cMedQA2의 두 데이터 세트에서 약 2000개의 고품질의 다양한 샘플을 수동으로 선택하여 여러 예제를 다시 작성하고 이를 GPT-4로 수정한 후 소규모 샘플 방법을 사용하여 GPT-3.5에 제공했습니다. -품질 행동 선호도 데이터 세트. 일반 데이터. 훈련 세트의 다양성을 강화하고 SFT 훈련 단계에서 기본 기능의 모델 저하 위험을 완화하기 위해 두 개의 공통 지도 미세 조정 데이터 세트인 moss-sft-003 및 alpaca gpt4 데이터에서 여러 샘플을 무작위로 선택했습니다. zh.zh. MedMCQA. 모델의 Q&A 역량을 강화하기 위해 영어 의학 분야의 객관식 질문 데이터 세트인 MedMCQA를 선택하고, GPT-3.5를 활용해 객관식 질문과 정답을 최적화하여 약 8,000명의 전문 중국어를 생성했다. 의료 Q&A 샘플. 훈련. 아래 그림과 같이 DISC-MedLLM의 훈련 과정은 두 개의 SFT 단계로 나누어집니다. 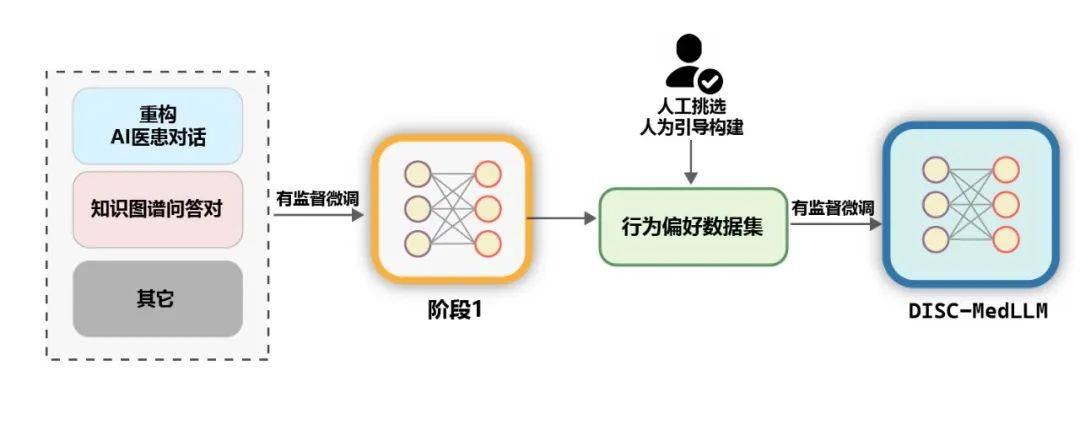
평가. 의료 LLM의 성능은 단일 라운드 QA와 다중 라운드 대화라는 두 가지 시나리오로 평가됩니다.
- 단일 QA 평가: 의학 지식 측면에서 모델의 정확성을 평가하기 위해 중국 국가 의료 자격 시험(NMLEC) 및 국가 대학원 입학 시험(NEEP)에서 1500개의 샘플을 샘플링했습니다. ) Western Medicine 306 전공 + 객관식 질문으로 단일 QA에서 모델의 성능을 평가합니다.
- 다단계 대화 평가: 모델의 대화 능력을 체계적으로 평가하기 위해 Chinese Medical Benchmark(CMB-Clin), Chinese Medical Dialogue Dataset(CMD) 및 Chinese Medical Intent의 세 가지 공개 데이터 세트에서 시작했습니다. 데이터 세트(CMID)에서 샘플을 무작위로 선택하고 GPT-3.5가 환자 역할을 하고 모델과 대화하도록 합니다. GPT-4에서 점수를 매기는 주도성, 정확성, 유용성 및 언어 품질의 네 가지 평가 지표가 제안됩니다.
모델을 비교하세요. 우리 모델은 3개의 일반 LLM과 2개의 중국 의학 회화 LLM과 비교됩니다. OpenAI의 GPT-3.5, GPT-4, Baichuan-13B-Chat 및 HuatuoGPT-13B를 포함합니다. 단일 라운드 QA 결과. 객관식 평가의 전체 결과는 표 2에 나와 있습니다. GPT-3.5는 명확한 단서를 보여줍니다. DISC-MedLLM은 소표본 설정에서 2위를 차지했고, 영표본 설정에서는 Baichuan-13B-Chat에 이어 3위를 차지했습니다. 특히 강화 학습 설정으로 훈련된 HuatuoGPT(13B)보다 성능이 뛰어납니다. 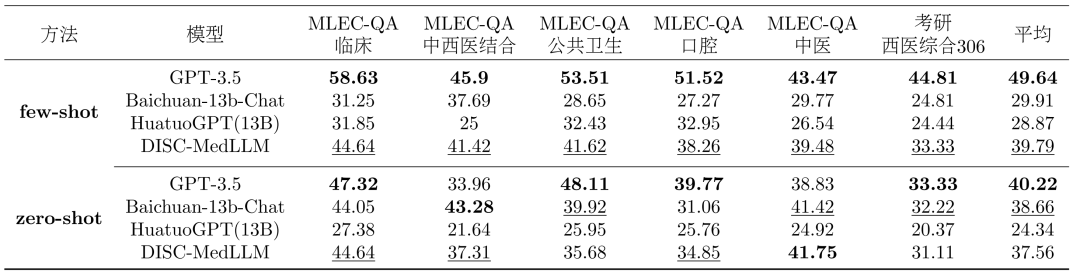
다양한 대화 결과. CMB-Clin 평가에서는 DISC-MedLLM이 가장 높은 종합 점수를 얻었고 HuatuoGPT가 그 뒤를 이었습니다. 우리 모델은 양성 기준에서 가장 높은 점수를 얻었으며 의료 행동 패턴을 편향시키는 훈련 접근 방식의 효율성을 강조했습니다. 결과를 표 3에 나타내었다. 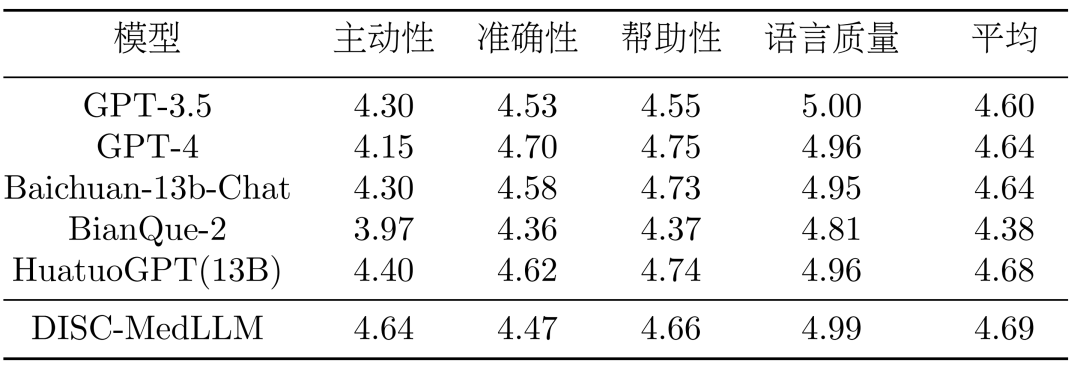
CMD 샘플에서는 그림 8과 같이 GPT-4가 가장 높은 점수를 얻었고 GPT-3.5가 그 뒤를 이었습니다. 의료 분야의 모델인 DISC-MedLLM과 HuatuoGPT는 전체 성능 점수가 동일하며 다양한 부서에서의 성능이 뛰어납니다. 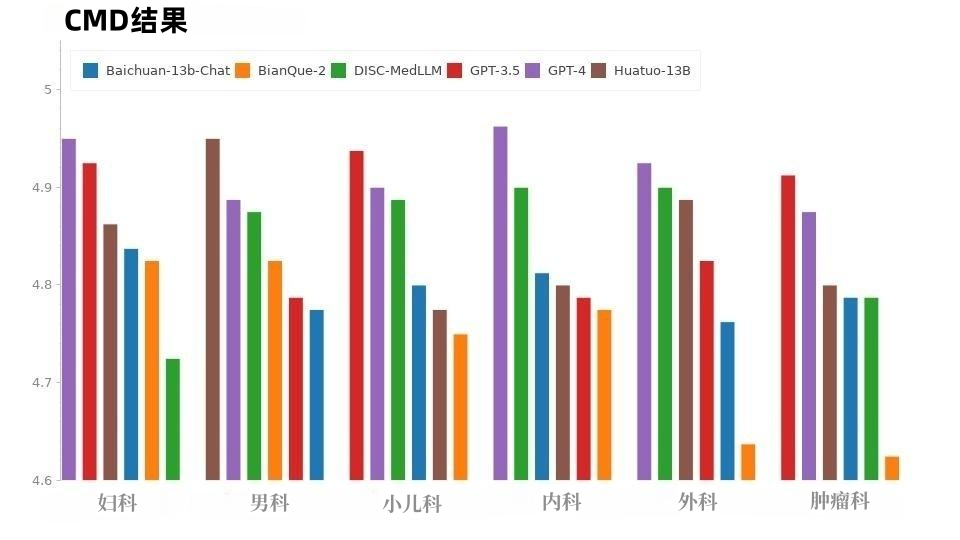
그림 9에 표시된 것처럼 CMID의 상황은 CMD와 유사하며 GPT-4와 GPT-3.5가 선두를 유지합니다. GPT 시리즈를 제외하면 DISC-MedLLM이 가장 좋은 성능을 보였습니다. 상태, 치료 요법, 약물 치료 등 세 가지 의도에서 HuatuoGPT를 능가했습니다. ㅋㅋㅋ CMD와 CMID에는 보다 명확한 질문 샘플이 포함되어 있으며 환자는 이미 진단을 받았고 증상을 설명할 때 명확한 요구 사항을 표현할 수 있으며 환자의 질문과 요구 사항은 개인 건강 상태와 아무런 관련이 없을 수도 있습니다. 여러 측면에서 탁월한 범용 모델 GPT-3.5 및 GPT-4가 이러한 상황을 더 잘 처리합니다. 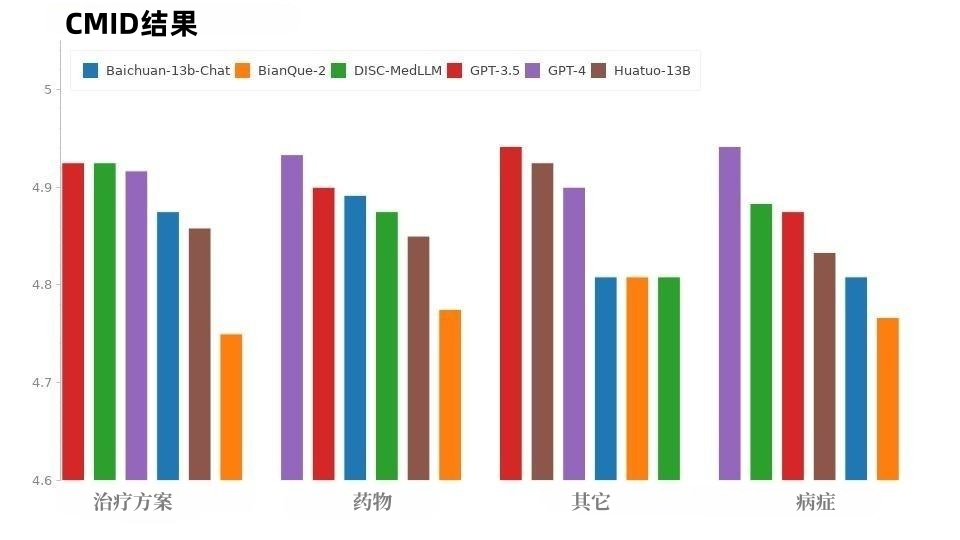 5. 요약
5. 요약
DISC-Med-SFT 데이터 세트는 실제 대화 및 일반 도메인 LLM의 장점과 기능을 활용하고 도메인 지식, 의료 대화 기술 및 인간 선호도, 고품질 데이터 세트를 통해 우수한 의료 대형 모델 DISC-MedLLM을 교육했으며, 이는 의료 상호 작용에서 상당한 개선을 달성하고 높은 유용성을 입증했으며 큰 응용 가능성을 보여주었습니다.
이 분야의 연구는 온라인 의료 비용 절감, 의료 자원 홍보 및 균형 달성에 대한 더 많은 전망과 가능성을 가져올 것입니다. DISC-MedLLM은 더 많은 사람들에게 편리하고 개인화된 의료서비스를 제공하고 국민건강 증진에 기여하겠습니다.
위 내용은 푸단대학교 팀은 중국 의료 및 건강 개인 비서를 출시하고 470,000개의 고품질 데이터 세트를 오픈 소스로 제공합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



