

上周,我写了一篇关于抓取网页以收集元数据的介绍,并提到不可能抓取《纽约时报》网站。 《纽约时报》付费墙会阻止您收集基本元数据的尝试。但有一种方法可以使用纽约时报 API 来解决这个问题。
最近我开始在 Yii 平台上构建一个社区网站,我将在以后的教程中发布该网站。我希望能够轻松添加与网站内容相关的链接。虽然人们可以轻松地将 URL 粘贴到表单中,但提供标题和来源信息却非常耗时。
因此,在今天的教程中,我将扩展我最近编写的抓取代码,以在添加《纽约时报》链接时利用《纽约时报》API 来收集头条新闻。
请记住,我参与了下面的评论主题,所以请告诉我您的想法!您还可以通过 Twitter @lookahead_io 与我联系。

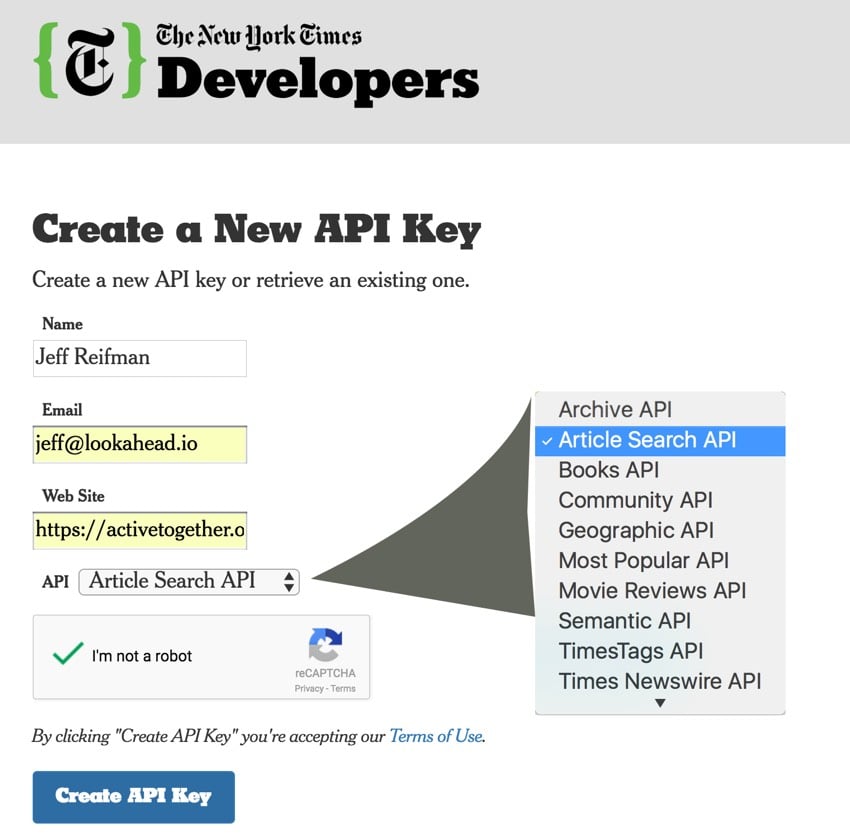
首先,让我们注册并请求 API 密钥:
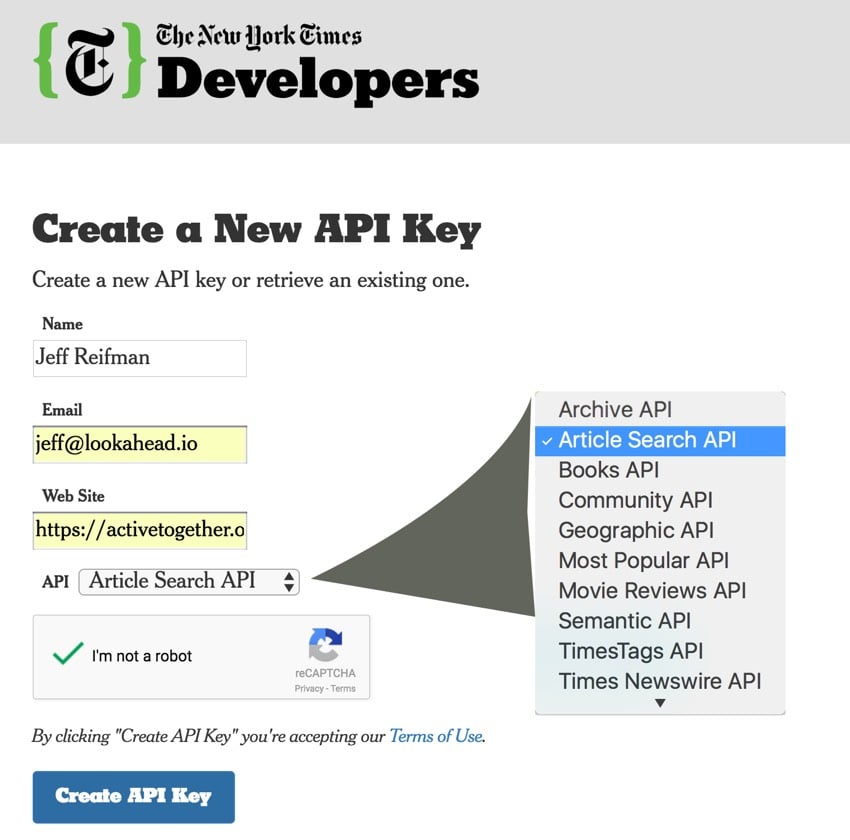
提交表单后,您将通过电子邮件收到密钥:
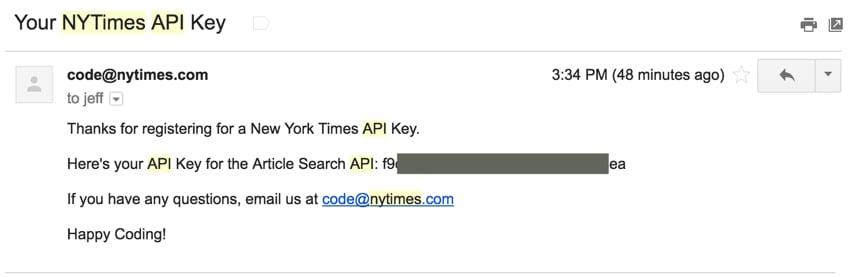

The Times 提供以下类别的 API:
很多。并且,在“图库”页面中,您可以单击任何主题来查看各个 API 类别文档:
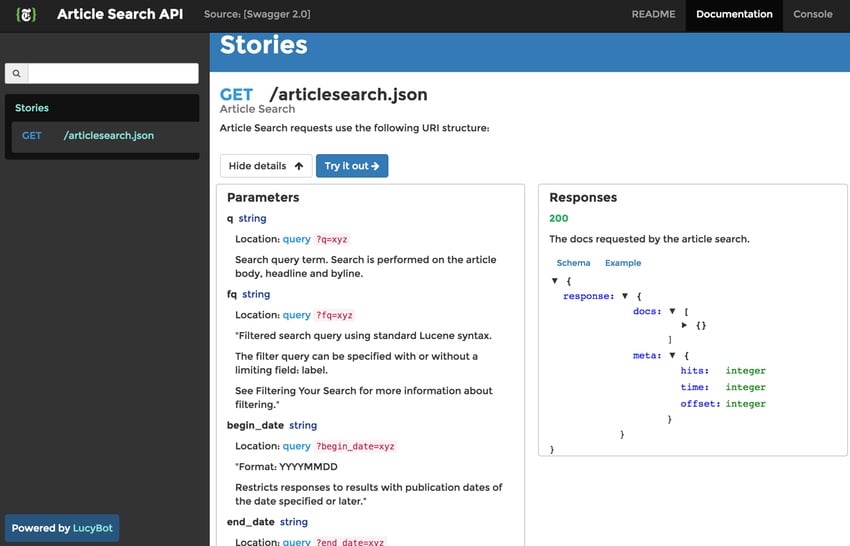
《纽约时报》使用 LucyBot 为其 API 文档提供支持,并且有一个有用的常见问题解答:

他们甚至向您展示如何快速获取 API 使用限制(您需要插入密钥):
curl --head
https://api.nytimes.com/svc/books/v3/lists/overview.json?api-key=<your-api-key>
2>/dev/null | grep -i "X-RateLimit"
X-RateLimit-Limit-day: 1000
X-RateLimit-Limit-second: 5
X-RateLimit-Remaining-day: 180
X-RateLimit-Remaining-second: 5
我最初很难理解该文档 - 它是基于参数的规范,而不是编程指南。不过,我在纽约时报 API GitHub 页面上发布了一些问题,这些问题很快就得到了有用的解答。
在今天的节目中,我将重点介绍如何使用《纽约时报》文章搜索。基本上,我们将扩展上一个教程中的创建链接表单:
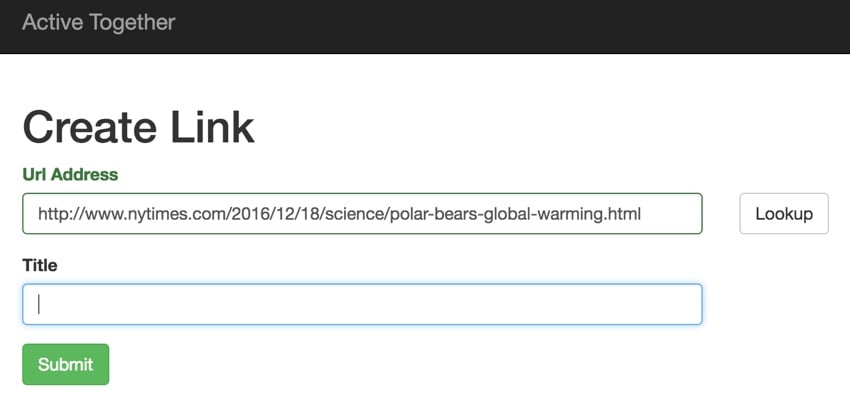
当用户点击查找时,我们将向 链接::grab($url)。这是 jQuery:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
这是控制器和模型方法:
// Controller call via AJAX Lookup request
public static function actionGrab($url) {
Yii::$app->response->format = Response::FORMAT_JSON;
return Link::grab($url);
}
...
// Link::grab() method
public static function grab($url) {
//clean up url for hostname
$source_url = parse_url($url);
$source_url = $source_url['host'];
$source_url=str_ireplace('www.','',$source_url);
$source_url = trim($source_url,' \\');
// use the NYT API when hostname == nytimes.com
if ($source_url=='nytimes.com') {
...
接下来,让我们使用 API 密钥发出文章搜索请求:
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com
/svc/search/v2/articlesearch.json?fl=headline&fq=web_url:%22'.
$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
$title = $result->response->docs[0]->headline->main;
} else {
// not NYT, use the standard metatag scraper from last episode
...
}
}
return $title;
}
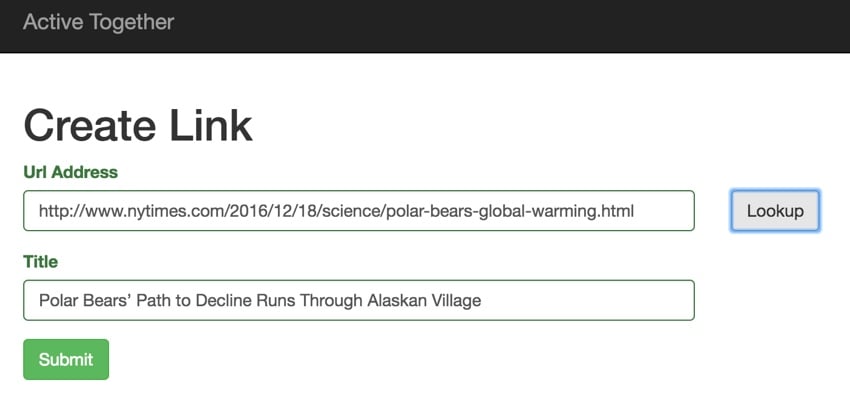
它的工作原理非常简单 - 这是生成的标题(顺便说一句,气候变化正在杀死北极熊,我们应该关心):
如果您想了解 API 请求的更多详细信息,只需向 ?fl 添加其他参数即可=headline 请求例如 关键字 和 lead_paragraph:
Yii::$app->response->format = Response::FORMAT_JSON; $nytKey=Yii::$app->params['nytapi']; $curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'. 'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey; $curl = curl_init(); curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); curl_setopt($curl, CURLOPT_URL,$curl_dest); $result = json_decode(curl_exec($curl)); var_dump($result);
结果如下:

也许我会在接下来的剧集中编写一个 PHP 库来更好地解析 NYT API,但此代码打破了关键字和引导段落:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
echo $result->response->docs[0]->headline->main.'<br />'.'<br />';
echo $result->response->docs[0]->lead_paragraph.'<br />'.'<br />';
foreach ($result->response->docs[0]->keywords as $k) {
echo $k->value.'<br/>';
}
以下是本文显示的内容:
Polar Bears’ Path to Decline Runs Through Alaskan Village The bears that come here are climate refugees, on land because the sea ice they rely on for hunting seals is receding. Polar Bears Greenhouse Gas Emissions Alaska Global Warming Endangered and Extinct Species International Union for Conservation of Nature National Snow and Ice Data Center Polar Bears International United States Geological Survey
希望这能开始扩展您对如何使用这些 API 的想象力。现在可能实现的事情非常令人兴奋。
纽约时报 API 非常有用,我很高兴看到他们向开发者社区提供它。通过 GitHub 获得如此快速的 API 支持也令人耳目一新——我只是没想到会这样。请记住,它适用于非商业项目。如果您有一些赚钱的想法,请给他们留言,看看他们是否愿意与您合作。出版商渴望新的收入来源。
이 웹 스크래핑 조각이 도움이 되기를 바라며 프로젝트에 구현해 보시기 바랍니다. 오늘의 쇼를 보고 싶다면 내 웹사이트 Active Together에서 웹 스크래핑을 시도해 볼 수 있습니다.
댓글로 의견이나 피드백을 공유해주세요. 언제든지 Twitter @lookahead_io를 통해 저에게 직접 연락하실 수도 있습니다. 제 강사 페이지와 기타 시리즈인 PHP로 스타트업 구축 및 Yii2로 프로그래밍을 확인해 보세요.
위 내용은 New York Times API를 사용한 메타데이터 스크래핑의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



