어제 메타는 연구 및 상업적 목적으로 무료로 사용할 수 있는 코드 생성 전문 기본 모델인 Code Llama을 오픈소스화했습니다. Code Llama 시리즈 모델에는 세 가지 매개변수 버전이 있으며 매개변수 양은 각각 7B, 13B, 34B입니다. 또한 Python, C++, Java, PHP, Typescript(Javascript), C# 및 Bash를 포함한 여러 프로그래밍 언어를 지원합니다. Meta는 다음을 포함한 Code Llama 버전을 제공합니다.
Code Llama, 기본 코드 모델
Code Sheep-Python, Python의 미세 조정 버전; 미세 조정된 자연어 교육 버전
효율성 측면에서 HumanEval 및 MBPP 데이터 세트의 다양한 버전의 Code Llama에 대한 일회성 통과율(pass@1)이 GPT-3.5를 초과합니다.
또한 HumanEval 데이터세트의 Code Llama의 "Unnatural" 34B 버전 pass@1은 GPT-4에 가깝습니다(62.2% 대 67.0%). 그러나 Meta는 이 버전을 출시하지 않았지만 소규모 고품질 인코딩 데이터 세트에 대한 교육을 통해 상당한 성능 개선을 달성했습니다.
이미지 출처: https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/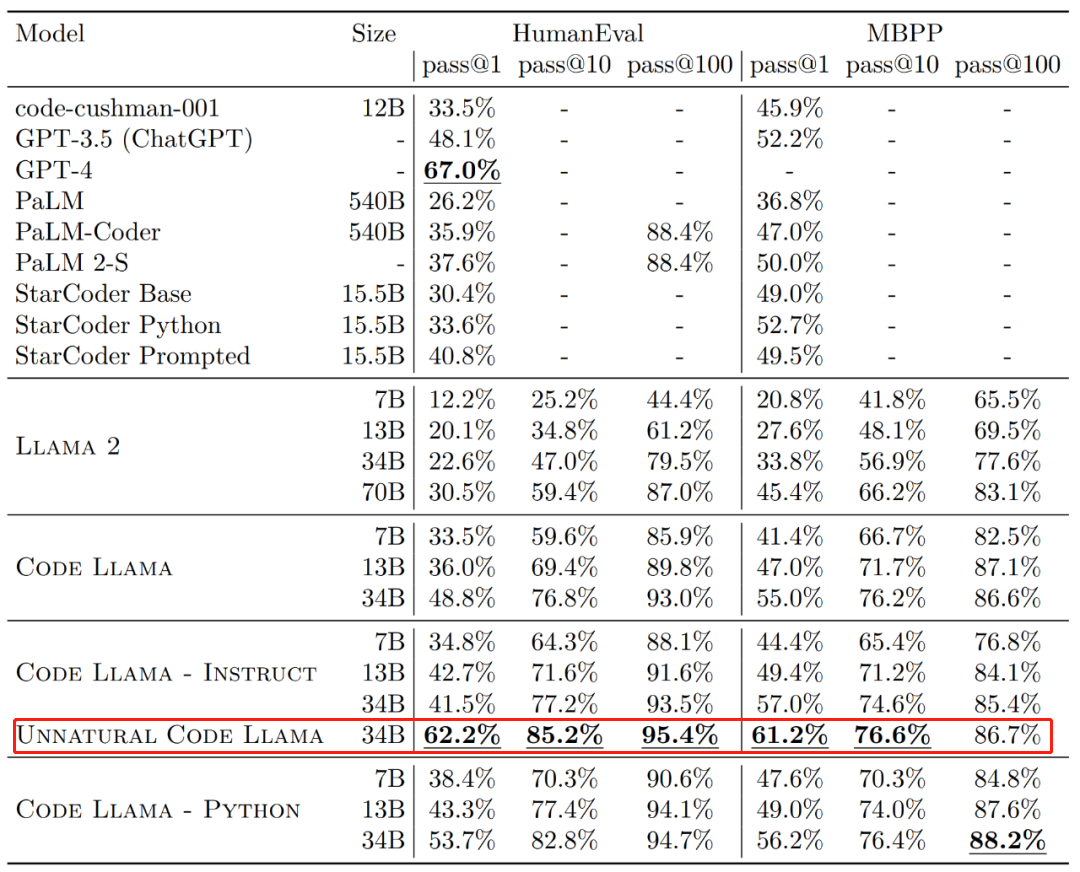 하루가 지나고 한 연구원이 GPT-4에 보고했습니다. 챌린지가 시작되었습니다. 개발자를 위한 AI 검색 엔진 구축을 목표로 하는 조직인 Phind에서 나온 것이며, 연구에서는 세밀하게 조정된 Code Llama-34B를 사용하여 HumanEval 평가에서 GPT-4를 이겼습니다.
하루가 지나고 한 연구원이 GPT-4에 보고했습니다. 챌린지가 시작되었습니다. 개발자를 위한 AI 검색 엔진 구축을 목표로 하는 조직인 Phind에서 나온 것이며, 연구에서는 세밀하게 조정된 Code Llama-34B를 사용하여 HumanEval 평가에서 GPT-4를 이겼습니다.
Phind 공동 창립자 Michael Royzen은 다음과 같이 말했습니다. "이것은 메타 논문에서 "부자연스러운 코드 라마" 결과를 재현(및 능가)하는 것을 목표로 하는 초기 실험일 뿐입니다. 앞으로는 실제 워크플로에서 경쟁력을 가질 수 있는 다양한 CodeLlama 모델로 구성된 전문 포트폴리오를 갖게 될 것입니다. ”
두 모델 모두 오픈 소스였습니다.

연구원들이 Huggingface에 이 두 모델을 공개했습니다. 가서 확인해 보세요.
Phind-CodeLlama-34B-v1: https://huggingface.co/Phind/Phind-CodeLlama-34B-v1
- Phind-CodeLlama-34B-Python-v1: https://huggingface.co /Phind/Phind-CodeLlama-34B-Python-v1
- 다음으로 이 연구가 어떻게 구현되었는지 살펴보겠습니다.
GPT-4를 이길 수 있도록 미세 조정된 코드 Llama-34B
먼저 결과를 살펴보겠습니다. 이 연구에서는 Phind 내부 데이터 세트를 사용하여 Code Llama-34B 및 Code Llama-34B-Python을 미세 조정하여 각각 Phind-CodeLlama-34B-v1 및 Phind-CodeLlama-34B-Python-v1 두 가지 모델을 만들었습니다.
새롭게 획득한 두 모델은 HumanEval에서 각각 67.6%와 69.5% pass@1을 달성했습니다.
비교를 위해 CodeLlama-34B pass@1은 48.8%이고, CodeLlama-34B-Python pass@1은 53.7%입니다.
그리고 HumanEval에서 GPT-4의 pass@1은 67%입니다(올해 3월에 발표된 "GPT-4 기술 보고서"에서 OpenAI가 발표한 데이터).
이미지 출처: https://ai.meta.com/blog/code-llama-large-언어-model-coding/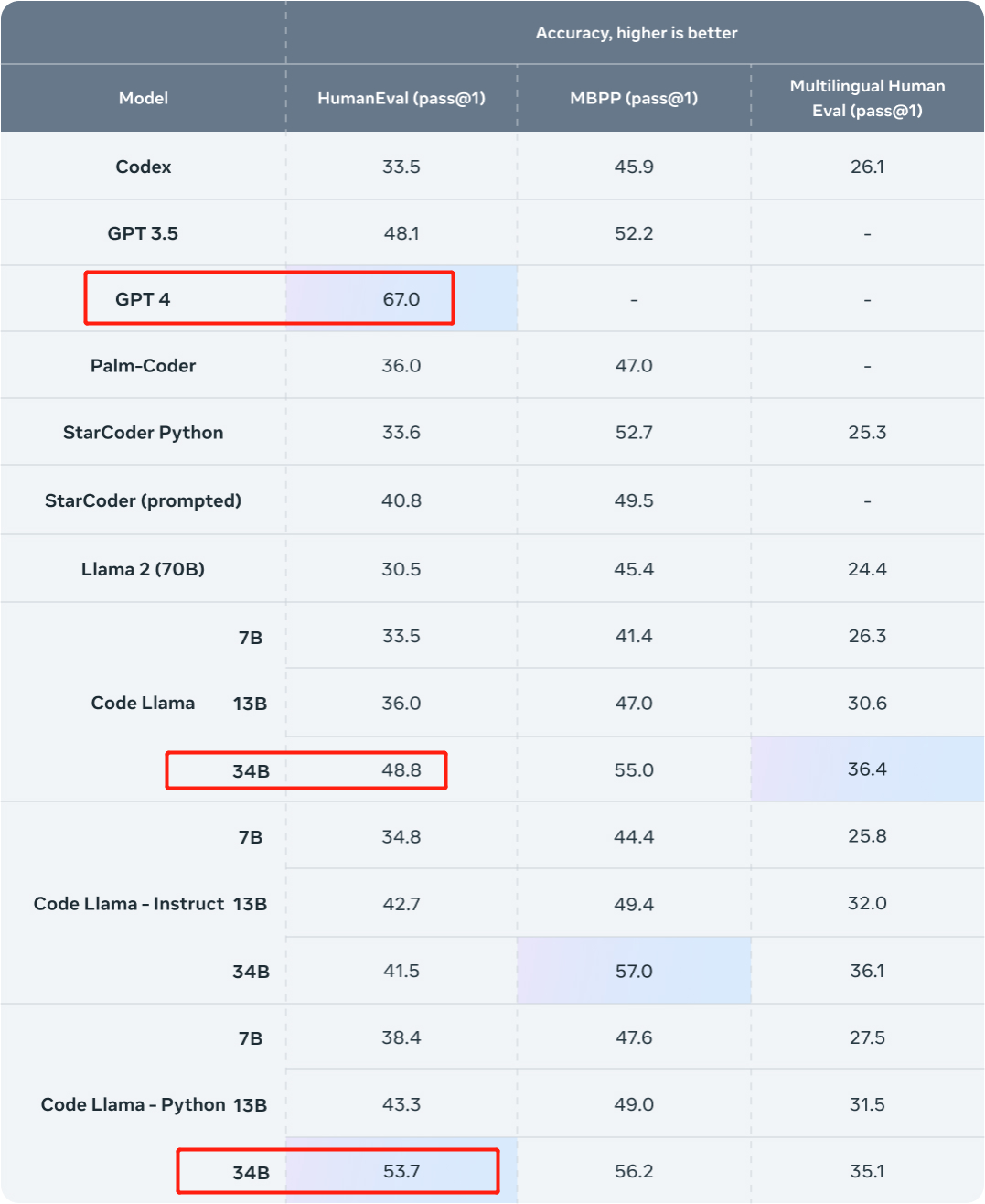
이미지 출처: https://cdn. openai.com/papers/gpt-4.pdf미세 조정에 대해 말하자면, 물론 데이터 세트는 필수입니다. 이번 연구에서는 약 80,000개의 고품질 프로그래밍 문제와 솔루션이 포함된 독점 데이터 세트에서 Code Llama-34B 및 Code Llama-34B-Python을 미세 조정했습니다. 이 데이터 세트는 코드 완성 예시가 아닌 명령-답변 쌍을 취하며 이는 HumanEval 데이터 구조와 다릅니다. 그런 다음 연구에서는 총 약 160,000개의 사례를 사용하여 두 시대에 대해 Phind 모델을 훈련했습니다. 연구진은 이번 훈련에는 LoRA 기술을 사용하지 않고 국지적 미세 조정(Fine-Tuning)을 활용했다고 밝혔다. 또한 연구에서는 DeepSpeed ZeRO 3 및 Flash Attention 2 기술을 사용하여 32개의 A100-80GB GPU에서 4096개의 토큰 시퀀스 길이로 이러한 모델을 훈련했습니다. 또한 연구에서는 모델 결과를 더욱 효과적으로 만들기 위해 OpenAI의 오염 제거 방법을 데이터 세트에 적용했습니다. 매우 강력한 GPT-4조차도 데이터 오염의 딜레마에 직면할 것이라는 것은 잘 알려져 있습니다. 일반인의 관점에서 보면 훈련된 모델은 평가 데이터에 대해 훈련을 받았을 수도 있습니다. 이 문제는 LLM에서는 매우 어렵습니다. 예를 들어 모델의 성능을 평가하는 과정에서 과학적으로 신뢰할 수 있는 평가를 하기 위해서는 연구자가 평가에 사용된 문제가 훈련에 있는지 확인해야 합니다. 모델의 데이터. 그렇다면 모델은 이러한 문제를 기억할 수 있으며 모델을 평가할 때 이러한 특정 문제에 대해 분명히 더 나은 성능을 발휘할 것입니다. 사람이 시험을 보기 전에 시험 문제를 아는 것과 같습니다. 이 문제를 해결하기 위해 OpenAI는 공개 GPT-4 기술 문서 "GPT-4 기술 보고서"에서 GPT-4가 데이터 오염을 평가하는 방법을 공개했습니다. 그들은 이러한 데이터 오염을 정량화하고 평가하기 위한 전략을 공개합니다. 구체적으로 OpenAI는 부분 문자열 매칭을 사용하여 평가 데이터 세트와 사전 훈련 데이터 간의 교차 오염을 측정합니다. 평가 및 훈련 데이터 모두 공백과 기호를 모두 제거하고 문자(숫자 포함)만 남기는 방식으로 처리됩니다. 각 평가 예시에 대해 OpenAI는 50자 하위 문자열 3개를 무작위로 선택합니다(50자 미만인 경우 전체 예시가 사용됩니다). 세 개의 샘플링된 평가 하위 문자열 중 하나라도 처리된 훈련 예제의 하위 문자열이면 일치가 결정됩니다. 이렇게 하면 OpenAI가 삭제하고 다시 실행하여 오염되지 않은 점수를 얻는 오염된 예제 목록이 생성됩니다. 그러나 이 필터링 방법에는 몇 가지 제한 사항이 있습니다. 부분 문자열 일치는 거짓 부정(평가 데이터와 훈련 데이터 사이에 작은 차이가 있는 경우) 및 거짓 긍정으로 이어질 수 있습니다. 결과적으로 OpenAI는 평가 예시의 정보 중 일부만 사용하고 질문, 맥락 또는 이에 상응하는 데이터만 활용하고 답변, 답변 또는 이에 상응하는 데이터는 무시합니다. 경우에 따라 객관식 옵션도 제외됩니다. 이러한 제외로 인해 오탐지가 증가할 수 있습니다. 이 부분에 대해 관심 있는 독자들은 논문을 참조하여 자세히 알아볼 수 있습니다. 논문 주소: https://cdn.openai.com/papers/gpt-4.pdf그러나 Phind가 GPT-4를 벤치마킹할 때 사용한 HumanEval 점수에 대해 논란이 있습니다. 어떤 사람들은 최근 GPT-4 시험 점수가 85%에 이르렀다고 합니다. 하지만 핀드는 이 점수를 도출한 관련 연구는 오염 연구를 수행하지 않았으며, GPT-4가 새로운 테스트를 받았을 때 HumanEval의 테스트 데이터를 봤는지 여부를 판단하는 것은 불가능하다고 대답했습니다. "GPT-4 goes dumb"에 대한 최근 연구를 고려하면 원본 기술 보고서의 데이터를 사용하는 것이 더 안전합니다.

그러나 대형 모델 평가의 복잡성을 고려할 때 이러한 평가 결과가 모델의 진정한 성능을 반영할 수 있는지 여부는 여전히 논란의 여지가 있는 문제입니다. 모델을 다운받아 직접 체험해 보실 수 있습니다. 다시 작성한 내용은 다음과 같습니다. 참조 링크:
다시 작성해야 하는 내용은 다음과 같습니다: https://benjaminmarie.com/the-decontaminating-evaluation-of-gpt-4/
다시 작성해야 하는 콘텐츠는 다음과 같습니다. 콘텐츠는 다음과 같습니다: https://www.phind.com/blog/code-llama-beats-gpt4
위 내용은 코드 라마(Code Llama)의 코딩 능력이 폭등했고, 미세 조정된 휴먼에발(HumanEval) 버전이 GPT-4보다 좋은 점수를 받아 하루 만에 출시됐다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



