


높은 동시성 및 응답 속도 빠름은 성능 최적화의 두 가지 핵심 지표에 해당합니다. 처리량 및 대기 시간

성능 문제의 본질은 시스템 리소스가 병목 현상에 도달했지만 요청 처리가 더 많은 요청을 지원할 만큼 빠르지 않다는 것입니다. 성능 분석은 실제로 애플리케이션이나 시스템의 병목 현상을 찾아 이를 피하거나 완화하려고 노력하는 것입니다.
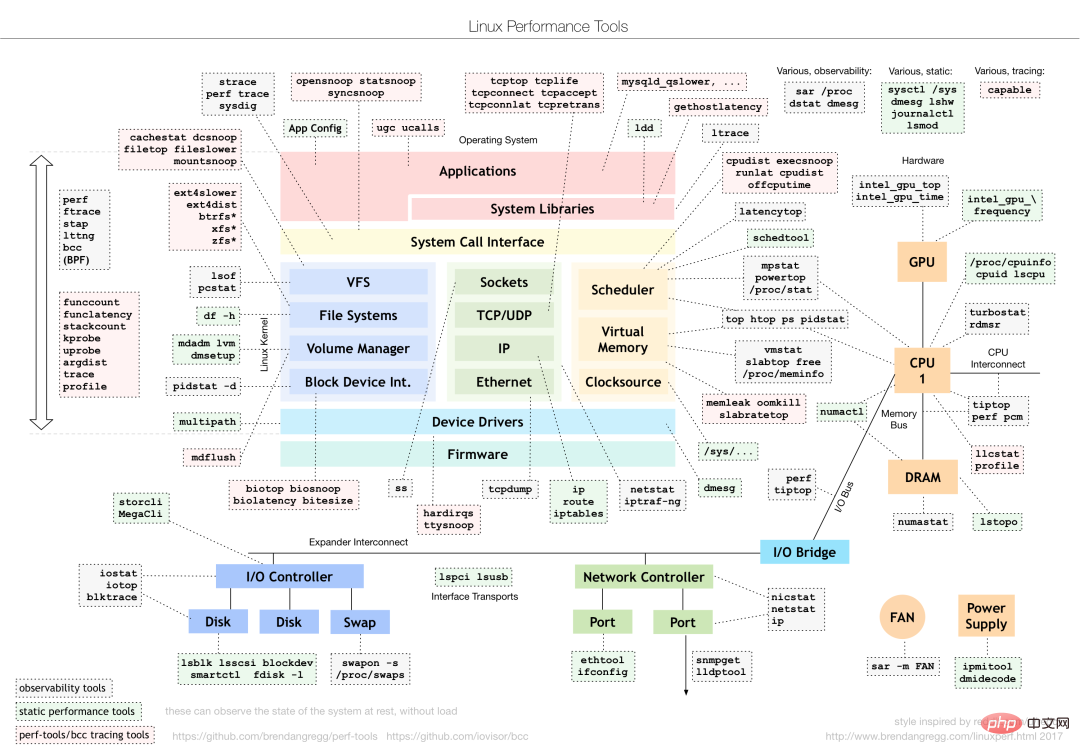
다양한 성능 문제에 대해 다양한 성능 분석 도구를 선택하십시오. 다음은 일반적으로 사용되는 Linux 성능 도구와 해당 유형의 성능 문제를 분석한 것입니다.
평균 부하: 단위 시간당 시스템의 실행 가능 및 중단 불가능 상태에 있는 프로세스의 평균 수입니다. 활성 프로세스의 평균 수입니다. 우리가 전통적으로 이해한 것처럼 CPU 사용량과 직접적인 관련이 없습니다.
무정전 프로세스는 커널 상태에서 중요한 프로세스(예: 장치를 기다리는 일반적인 I/O 응답)에 있는 프로세스입니다. 무정전 상태는 실제로 프로세스 및 하드웨어 장치에 대한 시스템의 보호 메커니즘입니다.
CPU 사용량이 많으면 평균 부하가 증가합니다. 이때 두 가지 모두
리눅스 프로세스는 프로세스의 실행 공간을 커널 공간과 사용자 공간으로 나눈다. 권한 수준. 사용자 모드에서 커널 모드로의 전환은 시스템 호출을 통해 완료되어야 합니다.
시스템 호출 프로세스는 실제로 두 가지 CPU 컨텍스트 전환을 수행합니다.
시스템 호출 프로세스에는 가상 메모리와 같은 사용자 모드 리소스 프로세스가 포함되지 않으며 프로세스를 전환하지도 않습니다. 이는 전통적인 의미의 프로세스 컨텍스트 전환과는 다릅니다. 따라서 시스템 호출을 종종 특권 모드 스위치 라고 합니다.
프로세스는 커널에 의해 관리되고 예약되며 프로세스 컨텍스트 전환은 커널 모드에서만 발생할 수 있습니다. 따라서 시스템 호출과 비교하여 현재 프로세스의 커널 상태와 CPU 레지스터를 저장하기 전에 프로세스의 가상 메모리와 스택을 먼저 저장해야 합니다. 새로운 프로세스의 커널 상태를 로딩한 후에는 해당 프로세스의 가상 메모리와 사용자 스택을 새로 고쳐야 합니다.
프로세스는 CPU에서 실행되도록 예약된 경우에만 컨텍스트를 전환하면 됩니다. 다음과 같은 시나리오가 있습니다. CPU 시간 분할이 차례로 할당되고, 시스템 리소스가 부족하여 프로세스가 중단되고, 프로세스가 절전 기능을 통해 적극적으로 중단됩니다. 및 우선순위가 높은 프로세스 선점 시간 하드웨어 인터럽트가 발생하면 CPU의 프로세스가 일시 중지되고 대신 커널에서 인터럽트 서비스가 실행됩니다.
스레드 컨텍스트 전환은 두 가지 유형으로 나뉩니다.
동일한 프로세스에서 스레드를 전환하면 리소스를 덜 소모하는데, 이는 멀티스레딩의 장점이기도 합니다.
인터럽트 컨텍스트 전환에는 프로세스의 사용자 모드가 포함되지 않으므로 인터럽트 컨텍스트에는 커널 모드 인터럽트 서비스 프로그램 실행에 필요한 상태만 포함됩니다(CPU 레지스터, 커널 스택, 하드웨어 인터럽트). 매개변수 등).
인터럽트 처리 우선순위가 프로세스보다 높으므로 인터럽트 컨텍스트 전환과 프로세스 컨텍스트 전환이 동시에 발생하지 않습니다
vmstat
vmstat 5 #每隔5s输出一组数据 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 103388 145412 511056 0 0 18 60 1 1 2 1 96 0 0 0 0 0 103388 145412 511076 0 0 0 2 450 1176 1 1 99 0 0 0 0 0 103388 145412 511076 0 0 0 8 429 1135 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 0 431 1132 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 10 467 1195 1 1 98 0 0 1 0 0 103388 145412 511076 0 0 0 2 426 1139 1 0 99 0 0 4 0 0 95184 145412 511108 0 0 0 74 500 1228 4 1 94 0 0 0 0 0 103512 145416 511076 0 0 0 455 723 1573 12 3 83 2 0
각 프로세스의 세부 정보를 보려면 이 경우 각 프로세스의 컨텍스트 전환을 보려면 pidstat를 사용해야 합니다
pidstat -w 5 14时51分16秒 UID PID cswch/s nvcswch/s Command 14时51分21秒 0 1 0.80 0.00 systemd 14时51分21秒 0 6 1.40 0.00 ksoftirqd/0 14时51分21秒 0 9 32.67 0.00 rcu_sched 14时51分21秒 0 11 0.40 0.00 watchdog/0 14时51分21秒 0 32 0.20 0.00 khugepaged 14时51分21秒 0 271 0.20 0.00 jbd2/vda1-8 14时51分21秒 0 1332 0.20 0.00 argusagent 14时51分21秒 0 5265 10.02 0.00 AliSecGuard 14时51分21秒 0 7439 7.82 0.00 kworker/0:2 14时51分21秒 0 7906 0.20 0.00 pidstat 14时51分21秒 0 8346 0.20 0.00 sshd 14时51分21秒 0 20654 9.82 0.00 AliYunDun 14时51分21秒 0 25766 0.20 0.00 kworker/u2:1 14时51分21秒 0 28603 1.00 0.00 python3
vmstat 1 1 #首先获取空闲系统的上下文切换次数 sysbench --threads=10 --max-time=300 threads run #模拟多线程切换问题 vmstat 1 1 #新终端观察上下文切换情况 此时发现cs数据明显升高,同时观察其他指标: r列: 远超系统CPU个数,说明存在大量CPU竞争 us和sy列:sy列占比80%,说明CPU主要被内核占用 in列: 中断次数明显上升,说明中断处理也是潜在问题
说明运行/等待CPU的进程过多,导致大量的上下文切换,上下文切换导致系统的CPU占用率高
pidstat -w -u 1 #查看到底哪个进程导致的问题
从结果中看出是sysbench导致CPU使用率过高,但是pidstat输出的上下文次数加起来也并不多。分析sysbench模拟的是线程的切换,因此需要在pidstat后加-t参数查看线程指标。
另外对于中断次数过多,我们可以通过/proc/interrupts文件读取
watch -d cat /proc/interrupts
发现次数变化速度最快的是重调度中断(RES),该中断用来唤醒空闲状态的CPU来调度新的任务运行。分析还是因为过多任务的调度问题,和上下文切换分析一致。
Linux는 멀티 태스킹 운영 체제로서 CPU 시간을 짧은 시간 조각으로 나누고 스케줄러를 통해 이를 각 작업에 차례로 할당합니다. CPU 시간을 유지하기 위해 Linux는 미리 정의된 비트 속도를 통해 시간 인터럽트를 트리거하고 글로벌 지피를 사용하여 부팅 이후 비트 수를 기록합니다. 이 값 + 1이 되면 시간 인터럽트가 발생합니다.
CPU 사용량 , 유휴 시간을 제외한 총 CPU 시간의 비율입니다. CPU 사용량은 /proc/stat의 데이터에서 계산할 수 있습니다. /proc/stat에서 부팅 후 비트 수의 누적 값은 부팅 후 평균 CPU 사용량으로 계산되기 때문에 일반적으로 별 의미가 없습니다. 일정 기간 간격으로 취한 두 값의 차이를 취하여 해당 기간 동안의 평균 CPU 사용량을 계산할 수 있습니다. 성능 분석 도구는 일정 기간 동안의 평균 CPU 사용량을 제공합니다. 간격 설정에 주의하세요.
CPU 사용량은 top이나 ps를 통해 볼 수 있습니다. 성능 이벤트 샘플링을 기반으로 하는 perf를 통해 프로세스의 CPU 문제를 분석할 수 있습니다. 시스템의 다양한 이벤트와 커널 성능을 분석할 수 있을 뿐만 아니라 특정 애플리케이션의 성능 문제를 분석하는 데에도 사용할 수 있습니다.
성능 최고 / 성능 기록 / 성능 보고서(-g는 호출 관계 샘플링을 켭니다)
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm ab -c 10 -n 100 http://XXX.XXX.XXX.XXX:10000/ #测试Nginx服务性能
发现此时每秒可承受请求给长少,此时将测试的请求数从100增加到10000。在另外一个终端运行top查看每个CPU的使用率。发现系统中几个php-fpm进程导致CPU使用率骤升。
接着用perf来分析具体是php-fpm中哪个函数导致该问题。
perf top -g -p XXXX #对某一个php-fpm进程进行分析
发现其中sqrt和add_function占用CPU过多, 此时查看源码找到原来是sqrt中在发布前没有删除测试代码段,存在一个百万次的循环导致。将该无用代码删除后发现nginx负载能力明显提升
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx:sp sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp ab -c 100 -n 1000 http://XXX.XXX.XXX.XXX:10000/ #并发100个请求测试
实验结果中每秒请求数依旧不高,我们将并发请求数降为5后,nginx负载能力依旧很低。
此时用top和pidstat发现系统CPU使用率过高,但是并没有发现CPU使用率高的进程。
出现这种情况一般时我们分析时遗漏的什么信息,重新运行top命令并观察一会。发现就绪队列中处于Running状态的进行过多,超过了我们的并发请求次数5. 再仔细查看进程运行数据,发现nginx和php-fpm都处于sleep状态,真正处于运行的却是几个stress进程。
下一步就利用pidstat分析这几个stress进程,发现没有任何输出。用ps aux交叉验证发现依旧不存在该进程。说明不是工具的问题。再top查看发现stress进程的进程号变化了,此时有可能时以下两种原因导致:
可以通过pstree来查找 stress的父进程,找出调用关系。
pstree | grep stress
发现是php-fpm调用的该子进程,此时去查看源码可以看出每个请求都会调用一个stress命令来模拟I/O压力。之前top显示的结果是CPU使用率升高,是否真的是由该stress命令导致的,还需要继续分析。代码中给每个请求加了verbose=1的参数后可以查看stress命令的输出,在中断测试该命令结果显示stress命令运行时存在因权限问题导致的文件创建失败的bug。
이것은 아직 추측일 뿐입니다. 다음 단계는 perf 도구를 통해 계속 분석하는 것입니다. 성능 보고서를 보면 스트레스가 실제로 CPU를 많이 차지하는 것으로 나타났는데, 이는 권한 문제를 해결하면 해결될 수 있습니다.
对于不可中断状态,一般都是在很短时间内结束,可忽略。但是如果系统或硬件发生故障,进程可能会保持不可中断状态很久,甚至系统中出现大量不可中断状态,此时需注意是否出现了I/O性能问题。
僵尸进程一般多进程应用容易遇到,父进程来不及处理子进程状态时子进程就提前退出,此时子进程就变成了僵尸进程。大量的僵尸进程会用尽PID进程号,导致新进程无法建立。
sudo docker run --privileged --name=app -itd feisky/app:iowait ps aux | grep '/app'
可以看到此时有多个app进程运行,状态分别时Ss+和D+。其中后面s表示进程是一个会话的领导进程,+号表示前台进程组。
其中进程组表示一组相互关联的进程,子进程是父进程所在组的组员。会话指共享同一个控制终端的一个或多个进程组。
用top查看系统资源发现:1)平均负载在逐渐增加,且1分钟内平均负载达到了CPU个数,说明系统可能已经有了性能瓶颈;2)僵尸进程比较多且在不停增加;3)us和sys CPU使用率都不高,iowait却比较高;4)每个进程CPU使用率也不高,但有两个进程处于D状态,可能在等待IO。
分析目前数据可知:iowait过高导致系统平均负载升高,僵尸进程不断增长说明有程序没能正确清理子进程资源。
用dstat来分析,因为它可以同时查看CPU和I/O两种资源的使用情况,便于对比分析。
dstat 1 10 #间隔1秒输出10组数据
可以看到当wai(iowait)升高时磁盘请求read都会很大,说明iowait的升高和磁盘的读请求有关。接下来分析到底时哪个进程在读磁盘。
之前top查看的处于D状态的进程号,用pidstat -d -p XXX 展示进程的I/O统计数据。发现处于D状态的进程都没有任何读写操作。在用pidstat -d 查看所有进程的I/O统计数据,看到app进程在进行磁盘读操作,每秒读取32MB的数据。进程访问磁盘必须使用系统调用处于内核态,接下来重点就是找到app进程的系统调用。
sudo strace -p XXX #对app进程调用进行跟踪
报错没有权限,因为已经时root权限了。所以遇到这种情况,首先要检查进程状态是否正常。ps命令查找该进程已经处于Z状态,即僵尸进程。
这种情况下top pidstat之类的工具无法给出更多的信息,此时像第5篇一样,用perf record -d和perf report进行分析,查看app进程调用栈。
看到app确实在通过系统调用sys_read()读取数据,并且从new_sync_read和blkdev_direct_IO看出进程时进行直接读操作,请求直接从磁盘读,没有通过缓存导致iowait升高。
레이어별 분석 결과 근본 원인은 앱 내부의 직접 디스크 I/O입니다. 그런 다음 최적화를 위한 특정 코드 위치를 찾습니다.
위의 최적화 이후 iowait는 크게 줄어들었지만 좀비 프로세스 수는 여전히 증가하고 있습니다. 먼저 좀비 프로세스의 상위 프로세스를 찾습니다. pstree -aps XXX를 사용하여 좀비 프로세스의 호출 트리를 인쇄하고 상위 프로세스가 앱 프로세스인지 확인합니다.
앱 코드를 확인하여 하위 프로세스의 끝이 올바르게 처리되었는지 확인하세요(wait()/waitpid() 호출 여부, SIGCHILD 신호 처리 함수 등록 여부 등).
iowait가 증가하면 먼저 dstat 및 pidstat와 같은 도구를 사용하여 디스크 I/O 문제가 있는지 확인한 다음 strace를 직접 사용할 수 없는 경우 어떤 프로세스가 I/O를 일으키는지 알아보세요. 프로세스 호출을 분석하려면 perf 도구를 사용하여 분석할 수 있습니다.
좀비 문제의 경우 pstree를 사용하여 상위 프로세스를 찾은 후 소스 코드를 보고 하위 프로세스 종료에 대한 처리 로직을 확인합니다.
CPU 사용량
평균 로드
이상적으로 평균 로드는 논리적 CPU 수와 동일합니다. CPU를 완전히 활용하면 시스템 부하가 더 커진다는 뜻입니다.
프로세스 컨텍스트 전환
자원을 확보할 수 없을 때의 자발적 전환과 시스템이 스케줄링을 강제할 때의 비자발적 전환을 포함합니다. 컨텍스트 전환 자체는 Linux의 정상적인 작동을 보장하는 핵심 기능입니다. 과도한 전환은 레지스터와 커널에서 원래 실행 중인 프로세스의 CPU 시간을 소비하게 됩니다. 가상 메모리 등의 데이터 저장 및 복원 측면에서는
CPU 캐시 적중률
CPU 캐시 재사용률이 높을수록 성능이 좋아지는데요. 그 중 싱글에서는 L1/L2가 많이 사용됩니다. 코어, L3는 멀티코어에 사용됩니다
다양한 성능 지표를 기반으로 적절한 도구를 찾으세요. 시스템에 이미 설치된 도구만 최대한 활용하십시오. 따라서 도구가 제공할 수 있는 지표 분석은 일부 주류에 대한 이해가 필요합니다.
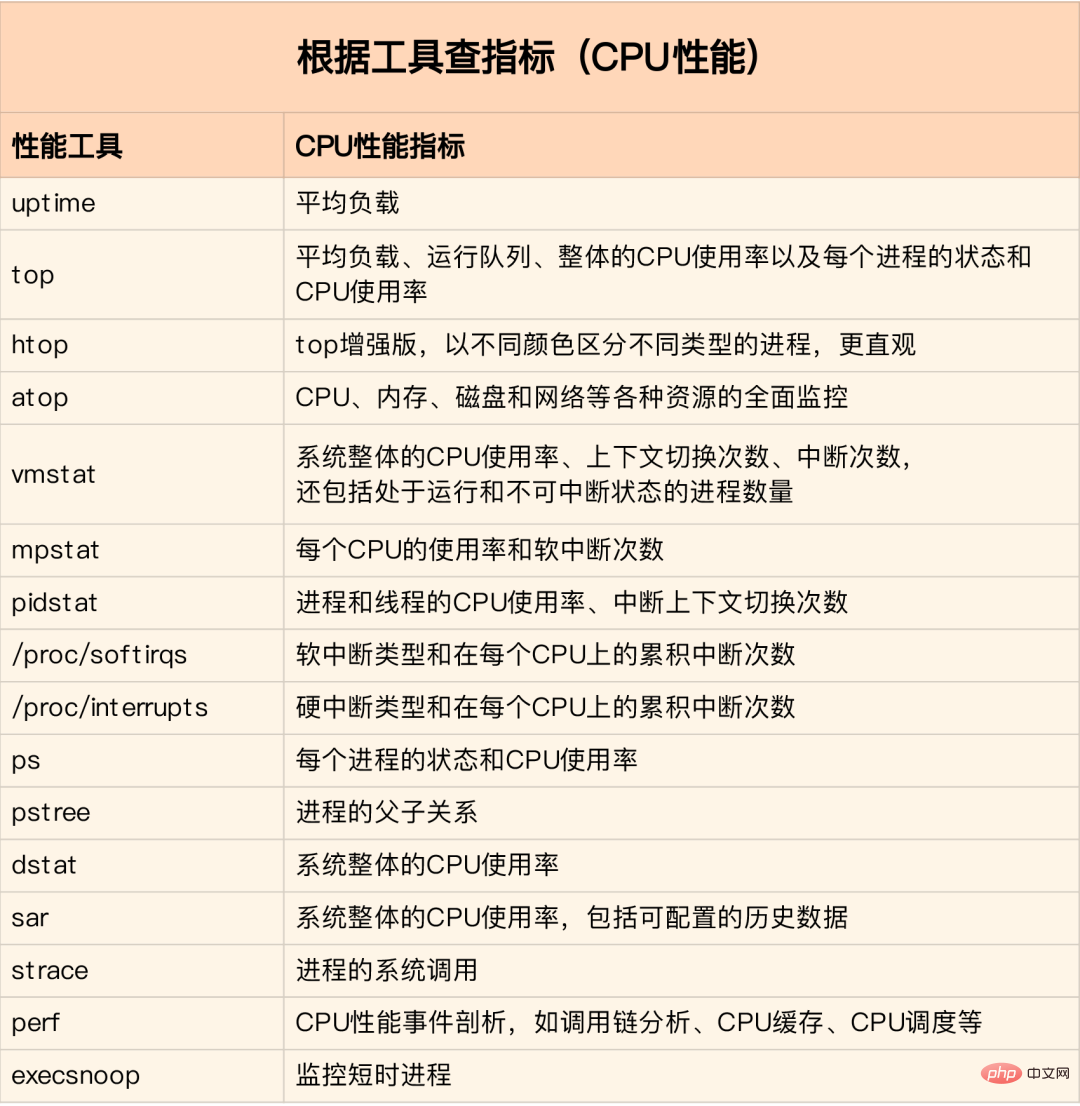
먼저 top/vmstat/pidstat와 같은 더 많은 표시기를 지원하는 몇 가지 도구를 실행해 보면 어떤 유형의 성능 문제인지 확인할 수 있습니다. process 그런 다음 추가 분석을 위해 호출 상황을 분석하기 위해 strace/perf를 사용합니다. 소프트 인터럽트로 인해 발생한 경우 /proc/softirqs
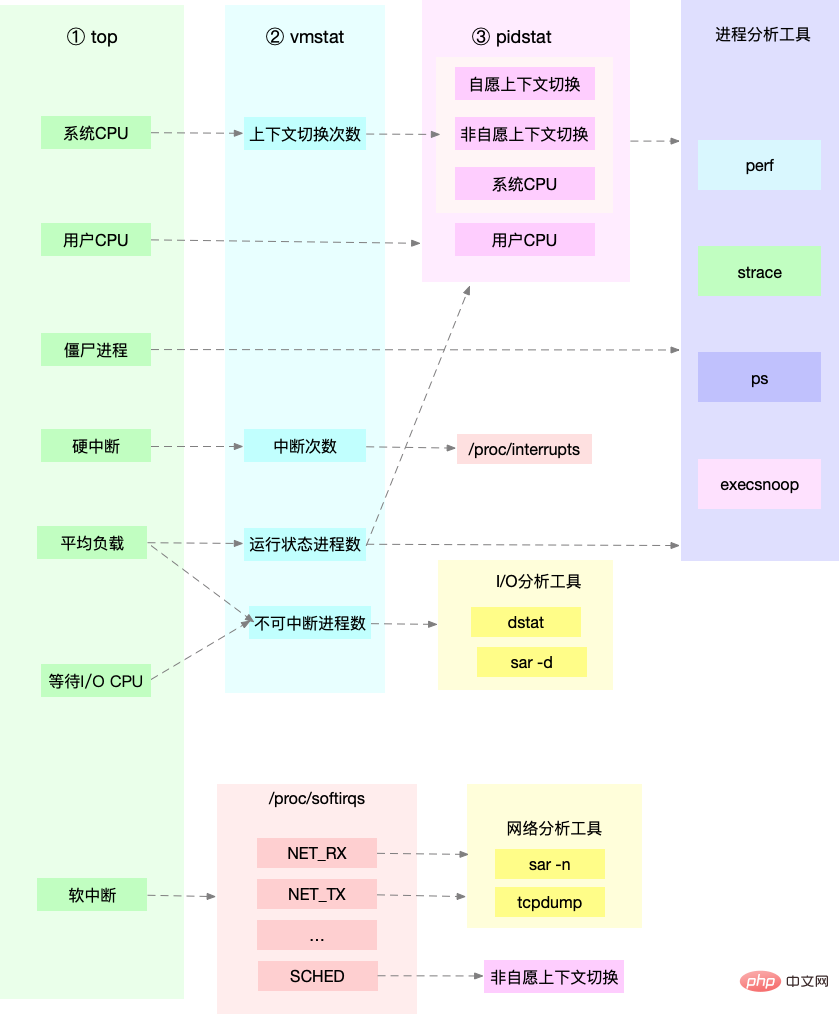
애플리케이션 최적화
시스템 최적화
TPS, QPS, 시스템 처리량의 차이와 이해
QPS (TPS)
동시 횟수
응답 시간
QPS(TPS)=동시 횟수/평균 응답 시간
사용자 요청 서버
내부 서버 처리
서버가 클라이언트로 돌아갑니다
QPS는 TPS와 유사하지만 페이지 방문이 TPS를 형성하지만 페이지 요청에는 서버에 대한 여러 요청이 포함될 수 있으며 이는 여러 QPS로 계산될 수 있습니다
QPS(초당 쿼리 수) 초당 쿼리 수, 서버가 초당 응답할 수 있는 쿼리 수
TPS(초당 트랜잭션 수), 소프트웨어 테스트 결과.
메모리 매핑
액세스 메모리(DRAM)만 커널은 물리적 메모리에 직접 액세스할 수 있습니다. Linux 커널은 각 프로세스에 대해 독립적인 가상 주소 공간을 제공하며 이 주소 공간은 연속적입니다. 이런 방식으로 프로세스는 메모리(가상 메모리)에 쉽게 접근할 수 있습니다. 🎜🎜가상 주소 공간의 내부는 커널 공간과 사용자 공간의 두 부분으로 나누어집니다. 서로 다른 단어 길이를 가진 프로세서의 주소 공간 범위가 다릅니다. 32비트 시스템 커널 공간은 1G를 차지하고 사용자 공간은 3G를 차지합니다. 64비트 시스템의 커널 공간과 사용자 공간은 모두 128T로 각각 메모리 공간의 가장 높은 부분과 가장 낮은 부분을 차지하고 중간 부분은 정의되지 않습니다. 🎜모든 가상 메모리에 실제 메모리가 할당되는 것은 아니며 실제 사용되는 메모리에만 할당됩니다. 할당된 물리적 메모리는 메모리 매핑을 통해 관리됩니다. 메모리 매핑을 완성하기 위해 커널은 각 프로세스별로 페이지 테이블을 유지하여 가상 주소와 물리적 주소 간의 매핑 관계를 기록합니다. 페이지 테이블은 실제로 CPU의 메모리 관리부인 MMU에 저장되며, 프로세서는 하드웨어를 통해 접근할 메모리를 직접 찾아낼 수 있다.
프로세스가 액세스한 가상 주소를 페이지 테이블에서 찾을 수 없으면 시스템은 페이지 폴트 예외를 생성하고 커널 공간에 들어가 물리적 메모리를 할당한 다음 프로세스 페이지 테이블을 업데이트한 다음 사용자 공간으로 돌아가 재개합니다. 프로세스의 작동.
MMU는 페이지 크기가 4KB인 페이지 단위로 메모리를 관리합니다. 너무 많은 페이지 테이블 항목 문제를 해결하기 위해 Linux는 다단계 페이지 테이블 및 HugePage 메커니즘을 제공합니다.
사용자 공간 메모리는 낮은 것부터 높은 것까지 다섯 가지 메모리 세그먼트로 나뉩니다.
malloc은 두 가지 방식으로 시스템 호출에 해당합니다.
전자의 캐시는 페이지 누락 예외 발생을 줄이고 메모리 액세스 효율성을 향상시킬 수 있습니다. 그러나 메모리가 시스템에 반환되지 않기 때문에 메모리 할당/해제를 자주 수행하면 메모리가 사용 중일 때 메모리 조각화가 발생합니다.
후자는 해제되면 시스템으로 직접 반환되므로 mmap이 발생할 때마다 페이지 폴트 예외가 발생합니다. 메모리 작업이 바쁜 경우 메모리를 자주 할당하면 페이지 오류 예외가 많이 발생하여 커널 관리 부담이 증가합니다.
위의 두 호출은 실제로 메모리를 할당하지 않습니다. 이 메모리는 처음 액세스할 때 페이지 오류 예외를 통해서만 커널에 들어가고
메모리가 부족할 때 할당됩니다. , 시스템은 다음과 같은 방법으로 메모리를 회수합니다.
回收缓存:LRU算法回收最近最少使用的内存页面;
回收不常访问内存:把不常用的内存通过交换分区写入磁盘
杀死进程:OOM内核保护机制 (进程消耗内存越大oom_score越大,占用CPU越多oom_score越小,可以通过/proc手动调整oom_adj)
echo -16 > /proc/$(pidof XXX)/oom_adj
free来查看整个系统的内存使用情况
top/ps来查看某个进程的内存使用情况
버퍼는 디스크 데이터의 캐시이고 캐시는 파일 데이터의 캐시이며 읽기 요청과 쓰기 요청 모두에 사용됩니다
캐시 적중률은 캐시를 통해 직접 데이터를 얻기 위한 요청 횟수를 말하며, 모든 요청의 비율입니다. 적중률이 높을수록 캐시가 가져오는 이점이 높아지고 애플리케이션 성능이 향상됩니다.
bcc 패키지를 설치한 후, 캐시 통계 및 캐시탑을 통해 캐시 읽기 및 쓰기 적중을 모니터링할 수 있습니다.
pcstat 설치 후 메모리에 있는 파일의 캐시 크기와 캐시 비율을 확인할 수 있습니다
#首先安装Go export GOPATH=~/go export PATH=~/go/bin:$PATH go get golang.org/x/sys/unix go ge github.com/tobert/pcstat/pcstat
dd if=/dev/sda1 of=file bs=1M count=512 #生产一个512MB的临时文件 echo 3 > /proc/sys/vm/drop_caches #清理缓存 pcstat file #确定刚才生成文件不在系统缓存中,此时cached和percent都是0 cachetop 5 dd if=file of=/dev/null bs=1M #测试文件读取速度 #此时文件读取性能为30+MB/s,查看cachetop结果发现并不是所有的读都落在磁盘上,读缓存命中率只有50%。 dd if=file of=/dev/null bs=1M #重复上述读文件测试 #此时文件读取性能为4+GB/s,读缓存命中率为100% pcstat file #查看文件file的缓存情况,100%全部缓存
cachetop 5 sudo docker run --privileged --name=app -itd feisky/app:io-direct sudo docker logs app #确认案例启动成功 #实验结果表明每读32MB数据都要花0.9s,且cachetop输出中显示1024次缓存全部命中
但是凭感觉可知如果缓存命中读速度不应如此慢,读次数时1024,页大小为4K,五秒的时间内读取了1024*4KB数据,即每秒0.8MB,和结果中32MB相差较大。说明该案例没有充分利用缓存,怀疑系统调用设置了直接I/O标志绕过系统缓存。因此接下来观察系统调用.
strace -p $(pgrep app) #strace 结果可以看到openat打开磁盘分区/dev/sdb1,传入参数为O_RDONLY|O_DIRECT
这就解释了为什么读32MB数据那么慢,直接从磁盘读写肯定远远慢于缓存。找出问题后我们再看案例的源代码发现flags中指定了直接IO标志。删除该选项后重跑,验证性能变化。
对应用程序来说,动态内存的分配和回收是核心又复杂的一个逻辑功能模块。管理内存的过程中会发生各种各样的“事故”:
가상 메모리 분배 낮음 위에서 아래로 읽기 전용 세그먼트, 데이터 세그먼트, 힙, 메모리 매핑 세그먼트 및 스택의 다섯 부분으로 구성됩니다. 그 중에서 메모리 누수를 일으킬 수 있는 것은 다음과 같습니다:
메모리 누수가 누적되어 시스템 메모리가 고갈될 수도 있습니다. 预先安装systat,docker,bcc 可以看到free在不断下降,buffer和cache基本保持不变。说明系统的内存一致在升高。但并不能说明存在内存泄漏。此时可以通过memleak工具来跟踪系统或进程的内存分配/释放请求 从memleak输出可以看到,应用在不停地分配内存,并且这些分配的地址并没有被回收。通过调用栈看到是fibonacci函数分配的内存没有释放。定位到源码后查看源码来修复增加内存释放函数即可. 系统内存资源紧张时通过内存回收和OOM杀死进程来解决。其中可回收内存包括: 프로그램에서 자동으로 할당한 힙 메모리의 경우 메모리 관리의 익명 페이지입니다. 이 메모리는 직접 해제할 수 없지만 Linux에서는 Swap 메커니즘을 제공합니다. 자주 액세스하지 않는 메모리는 디스크에 기록하여 메모리를 확보하고, 다음과 같은 경우 디스크에서 메모리를 읽을 수 있습니다. 다시 액세스했습니다. 스왑의 핵심은 스왑 인 및 스왑 아웃의 두 가지 프로세스를 포함하여 디스크 공간이나 로컬 파일을 메모리로 사용하는 것입니다. Linux는 메모리 리소스가 부족한지 어떻게 측정합니까? 직접 메모리 회수 새로운 대용량 블록 메모리 할당을 요청했지만 남은 메모리가 부족합니다. 이때 시스템은 메모리의 일부를 회수합니다. kswapd0 커널 스레드는 정기적으로 메모리를 회수합니다. 메모리 사용량을 측정하기 위해 페이지_분, 페이지_로우, 페이지_하이의 세 가지 임계값을 정의하고 이를 기반으로 메모리 재활용 작업을 수행합니다. 남은 메모리 < 페이지_min, 프로세스에 사용 가능한 메모리가 모두 소진되었습니다. 커널만 메모리를 할당할 수 있습니다. pages_min < 남은 메모리 < 남은 메모리 > Pages_high pages_low < 剩余内存 < pages_high,内存有一定压力,但可以满足新内存请求 剩余内存 > pages_high,说明剩余内存较多,无内存压力 pages_low = pages_min 5 / 4 pages_high = pages_min 3 / 2 很多情况下系统剩余内存较多,但SWAP依旧升高,这是由于处理器的NUMA架构。 在NUMA架构下多个处理器划分到不同的Node,每个Node都拥有自己的本地内存空间。在分析内存的使用时应该针对每个Node单独分析 内存三个阈值可以通过/proc/zoneinfo来查看,该文件中还包括活跃和非活跃的匿名页/文件页数。 当某个Node内存不足时,系统可以从其他Node寻找空闲资源,也可以从本地内存中回收内存。通过/proc/sys/vm/zone_raclaim_mode来调整。 在实际回收过程中Linux根据/proc/sys/vm/swapiness选项来调整使用Swap的积极程度,从0-100,数值越大越积极使用Swap,即更倾向于回收匿名页;数值越小越消极使用Swap,即更倾向于回收文件页。 注意:这只是调整Swap积极程度的权重,即使设置为0,当剩余内存+文件页小于页高阈值时,还是会发生Swap。 说明剩余内存和缓冲区的波动变化正是由于内存回收和缓存再次分配的循环往复。有时候Swap用的多,有时候缓冲区波动更多。此时查看swappiness值为60,是一个相对中和的配置,系统会根据实际运行情况来选去合适的回收类型. 시스템 메모리 표시기 프로세스 메모리 표시기 페이지 누락 예외 다양한 성능 지표를 기반으로 올바른 도구를 찾으세요. 메모리 분석 도구에 포함된 성능 지표: 보통 먼저 free, top, vmstat, pidstat 등과 같이 상대적으로 넓은 적용 범위를 갖는 여러 성능 도구를 실행하세요. 일반적인 최적화 아이디어: vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。 pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。 사용법: 1. 2、统计CPU使用情况 3、统计内存使用情况 4、查看具体进程使用情况如何检测内存泄漏
sudo docker run --name=app -itd feisky/app:mem-leak
sudo docker logs app
vmstat 3
로그인 후 복사/usr/share/bcc/tools/memleak -a -p $(pidof app)
로그인 후 복사为什么系统的Swap变高
스왑 원칙
NUMA 与 SWAP
numactl --hardware #查看处理器在Node的分布情况,以及每个Node的内存使用情况
로그인 후 복사swappiness
Swap升高时如何定位分析
free #首先通过free查看swap使用情况,若swap=0表示未配置Swap
#先创建并开启swap
fallocate -l 8G /mnt/swapfile
chmod 600 /mnt/swapfile
mkswap /mnt/swapfile
swapon /mnt/swapfile
free #再次执行free确保Swap配置成功
dd if=/dev/sda1 of=/dev/null bs=1G count=2048 #模拟大文件读取
sar -r -S 1 #查看内存各个指标变化 -r内存 -S swap
#根据结果可以看出,%memused在不断增长,剩余内存kbmemfress不断减少,缓冲区kbbuffers不断增大,由此可知剩余内存不断分配给了缓冲区
#一段时间之后,剩余内存很小,而缓冲区占用了大部分内存。此时Swap使用之间增大,缓冲区和剩余内存只在小范围波动
停下sar命令
cachetop5 #观察缓存
#可以看到dd进程读写只有50%的命中率,未命中数为4w+页,说明正式dd进程导致缓冲区使用升高
watch -d grep -A 15 ‘Normal’ /proc/zoneinfo #观察内存指标变化
#发现升级内存在一个小范围不停的波动,低于页低阈值时会突然增大到一个大于页高阈值的值
로그인 후 복사시스템 메모리 문제를 빠르고 정확하게 찾는 방법
메모리 성능 표시기
메모리 성능 도구
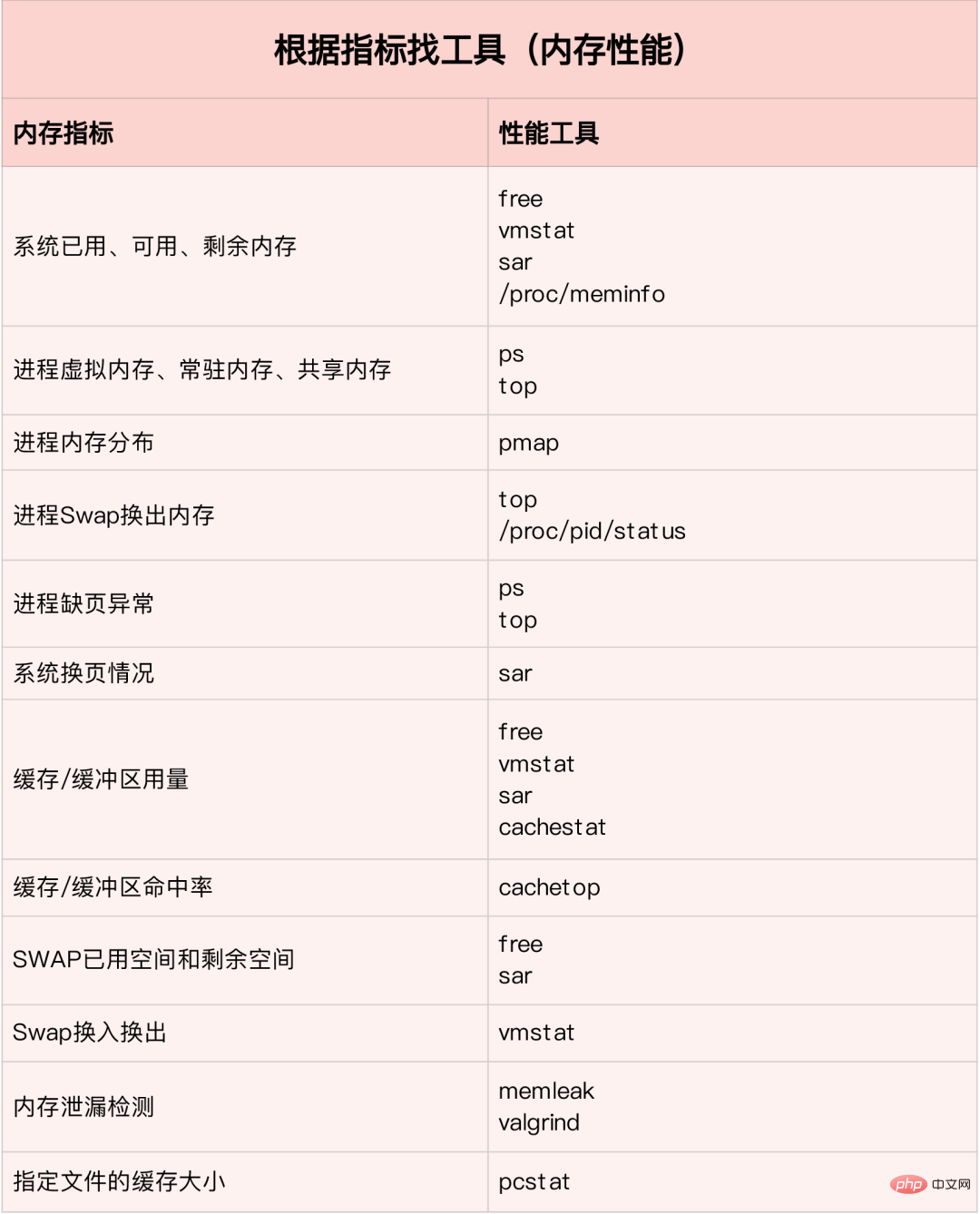
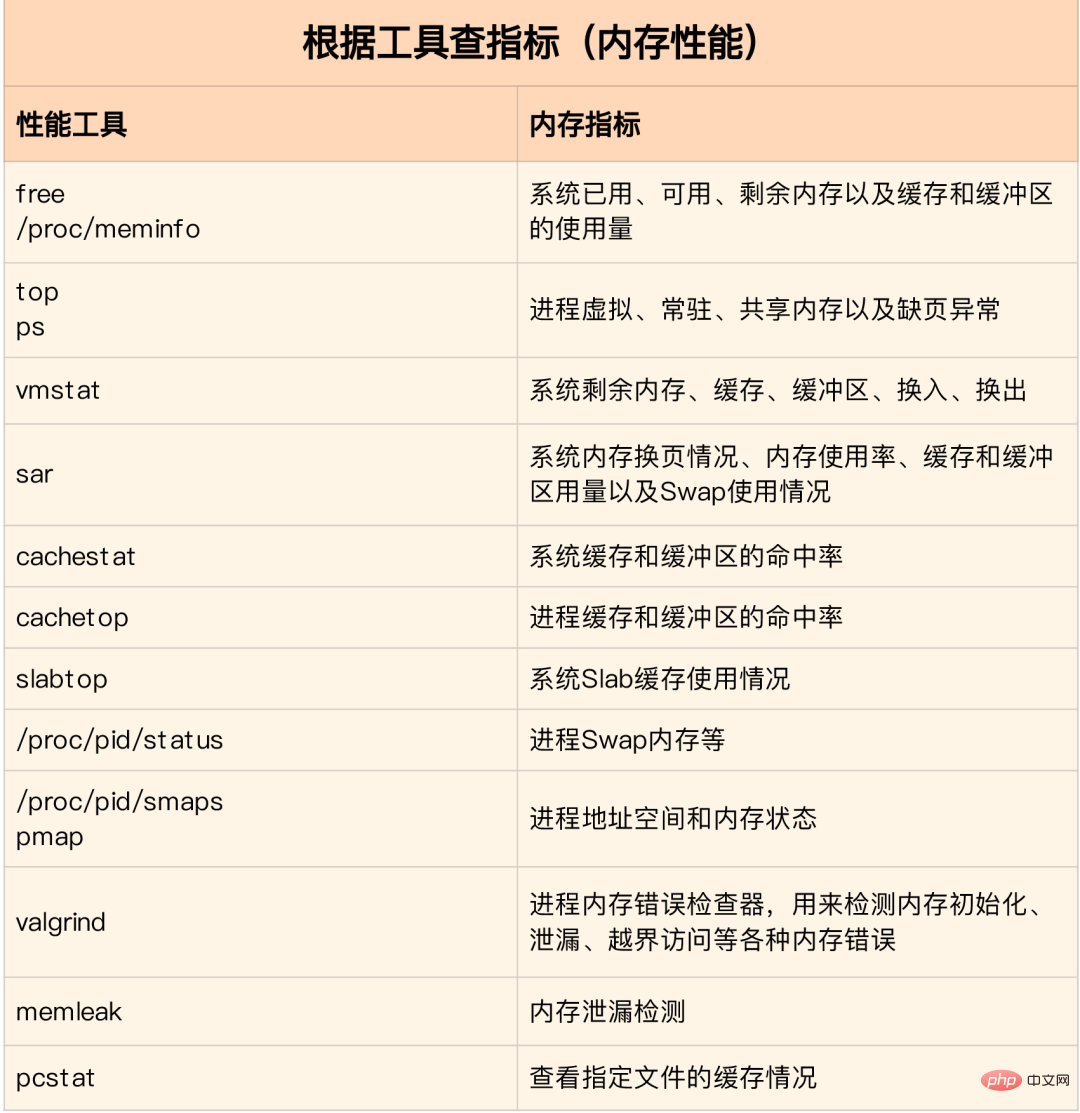
메모리 성능 병목 현상을 빠르게 분석하는 방법
vmstat使用详解
vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1379064 282244 11537528 0 0 3 104 0 0 3 0 97 0 0
0 0 0 1372716 282244 11537544 0 0 0 24 4893 8947 1 0 98 0 0
0 0 0 1373404 282248 11537544 0 0 0 96 5105 9278 2 0 98 0 0
0 0 0 1374168 282248 11537556 0 0 0 0 5001 9208 1 0 99 0 0
0 0 0 1376948 282248 11537564 0 0 0 80 5176 9388 2 0 98 0 0
0 0 0 1379356 282256 11537580 0 0 0 202 5474 9519 2 0 98 0 0
1 0 0 1368376 282256 11543696 0 0 0 0 5894 8940 12 0 88 0 0
1 0 0 1371936 282256 11539240 0 0 0 10554 6176 9481 14 1 85 1 0
1 0 0 1366184 282260 11542292 0 0 0 7456 6102 9983 7 1 91 0 0
1 0 0 1353040 282260 11556176 0 0 0 16924 7233 9578 18 1 80 1 0
0 0 0 1359432 282260 11549124 0 0 0 12576 5495 9271 7 0 92 1 0
0 0 0 1361744 282264 11549132 0 0 0 58 8606 15079 4 2 95 0 0
1 0 0 1367120 282264 11549140 0 0 0 2 5716 9205 8 0 92 0 0
0 0 0 1346580 282264 11562644 0 0 0 70 6416 9944 12 0 88 0 0
0 0 0 1359164 282264 11550108 0 0 0 2922 4941 8969 3 0 97 0 0
1 0 0 1353992 282264 11557044 0 0 0 0 6023 8917 15 0 84 0 0
# 结果说明
- r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
- b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
- swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
- buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
- cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
- si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
- so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
- bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
- bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
- in 每秒CPU的中断次数,包括时间中断
- cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- id 空闲CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
- wt 等待IO CPU时间
로그인 후 복사pidstat 使用详解
pidstat -d 1 10
03:02:02 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:03 PM 0 816 0.00 918.81 0.00 jbd2/vda1-8
03:02:03 PM 0 1007 0.00 3.96 0.00 AliYunDun
03:02:03 PM 997 7326 0.00 1904.95 918.81 java
03:02:03 PM 997 8539 0.00 3.96 0.00 java
03:02:03 PM 0 16066 0.00 35.64 0.00 cmagent
03:02:03 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:04 PM 0 816 0.00 1924.00 0.00 jbd2/vda1-8
03:02:04 PM 997 7326 0.00 11156.00 1888.00 java
03:02:04 PM 997 8539 0.00 4.00 0.00 java
로그인 후 복사# 统计CPU
pidstat -u 1 10
03:03:33 PM UID PID %usr %system %guest %CPU CPU Command
03:03:34 PM 0 2321 3.96 0.00 0.00 3.96 0 ansible
03:03:34 PM 0 7110 0.00 0.99 0.00 0.99 4 pidstat
03:03:34 PM 997 8539 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 984 15517 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 0 24406 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 0 32158 3.96 0.00 0.00 3.96 2 ansible
로그인 후 복사# 统计内存
pidstat -r 1 10
Average: UID PID minflt/s majflt/s VSZ RSS %MEM Command
Average: 0 1 0.20 0.00 191256 3064 0.01 systemd
Average: 0 1007 1.30 0.00 143256 22720 0.07 AliYunDun
Average: 0 6642 0.10 0.00 6301904 107680 0.33 java
Average: 997 7326 10.89 0.00 13468904 8395848 26.04 java
Average: 0 7795 348.15 0.00 108376 1233 0.00 pidstat
Average: 997 8539 0.50 0.00 8242256 2062228 6.40 java
Average: 987 9518 0.20 0.00 6300944 1242924 3.85 java
Average: 0 10280 3.70 0.00 807372 8344 0.03 aliyun-service
Average: 984 15517 0.40 0.00 6386464 1464572 4.54 java
Average: 0 16066 236.46 0.00 2678332 71020 0.22 cmagent
Average: 995 20955 0.30 0.00 6312520 1408040 4.37 java
Average: 995 20956 0.20 0.00 6093764 1505028 4.67 java
Average: 0 23936 0.10 0.00 5302416 110804 0.34 java
Average: 0 24406 0.70 0.00 10211672 2361304 7.32 java
Average: 0 26870 1.40 0.00 1470212 36084 0.11 promtail
로그인 후 복사pidstat -T ALL -r -p 20955 1 10
03:12:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
03:12:17 PM 995 20955 0.00 0.00 6312520 1408040 4.37 java
03:12:16 PM UID PID minflt-nr majflt-nr Command
03:12:17 PM 995 20955 0 0 java
로그인 후 복사
위 내용은 Linux 성능 최적화 지식 포인트 요약 · 실습 + 컬렉션 에디션의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



