

때때로 어렵고 복잡한 질병에 직면하게 되는데, 모니터링 플러그인으로는 문제의 근본 원인을 한눈에 바로 찾을 수 없습니다. 이때 문제의 근본 원인을 자세히 분석하려면 서버에 로그인해야 합니다. 그러면 문제를 분석하려면 어느 정도의 기술적 경험 축적이 필요하고, 어떤 문제는 문제를 찾아내기 위해 매우 넓은 영역을 포함합니다. 그러므로 문제를 분석하고 함정에 빠져드는 것은 개인의 성장과 자기계발을 위한 훌륭한 훈련입니다. 좋은 분석 도구 세트가 있다면 절반의 노력으로 두 배의 결과를 얻을 수 있으며, 모든 사람이 문제를 신속하게 찾을 수 있도록 돕고 더 심층적인 작업을 수행하는 데 많은 시간을 절약할 수 있습니다.

이 글에서는 주로 다양한 문제 위치 파악 도구를 소개하고 사례별로 문제를 분석합니다.
애플리케이션의 경우 일반적으로 커널 CPU 스케줄러 기능 및 성능에 중점을 둡니다.
스레드 상태 분석은 주로 스레드 시간이 사용되는 곳을 분석하며 스레드 상태의 분류는 일반적으로
on-CPU: 실행으로 나뉘며, 실행되는 시간은 일반적으로 사용자 모드 시간 사용자와 시스템 상태 시간 sys.
off-CPU: 다음 CPU 라운드를 기다리거나 I/O, 잠금, 페이지 변경 등을 기다리는 중입니다. 상태는 실행 가능, 익명 페이지 변경, 절전, 잠금, 유휴, 등. .
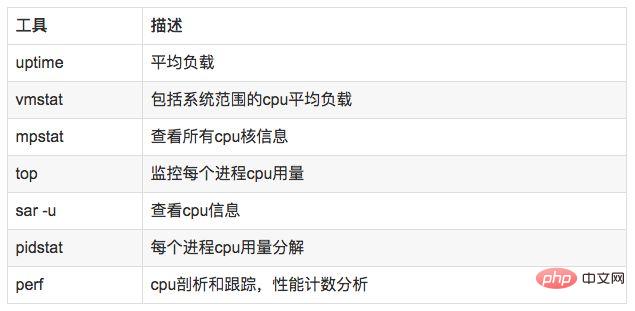
//查看系统cpu使用情况top //查看所有cpu核信息mpstat -P ALL 1 //查看cpu使用情况以及平均负载vmstat 1 //进程cpu的统计信息pidstat -u 1 -p pid //跟踪进程内部函数级cpu使用情况 perf top -p pid -e cpu-clock
牛逼啊!接私活必备的 N 个开源项目!赶快收藏
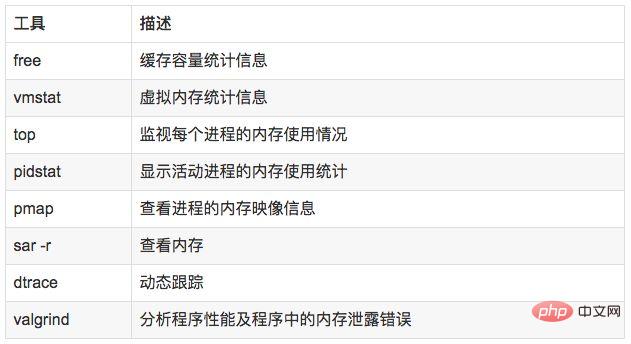
说明:
free,vmstat,top,pidstat,pmap只能统计内存信息以及进程的内存使用情况。
valgrind 可以分析内存泄漏问题。
dtrace 动态跟踪。需要对内核函数有很深入的了解,通过D语言编写脚本完成跟踪。
//查看系统内存使用情况free -m//虚拟内存统计信息vmstat 1//查看系统内存情况top//1s采集周期,获取内存的统计信息pidstat -p pid -r 1//查看进程的内存映像信息pmap -d pid//检测程序内存问题valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
在理解磁盘IO之前,同样我们需要理解一些概念,例如:
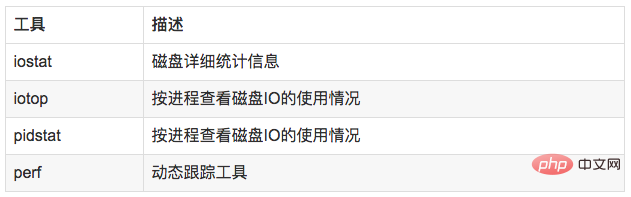
//查看系统io信息iotop//统计io详细信息iostat -d -x -k 1 10//查看进程级io的信息pidstat -d 1 -p pid//查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常perf record -e block:block_rq_issue -ag^Cperf report

//显示网络统计信息netstat -s//显示当前UDP连接状况netstat -nu//显示UDP端口号的使用情况netstat -apu//统计机器中网络连接各个状态个数netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'//显示TCP连接ss -t -a//显示sockets摘要信息ss -s//显示所有udp socketsss -u -a//tcp,etcp状态sar -n TCP,ETCP 1//查看网络IOsar -n DEV 1//抓包以包为单位进行输出tcpdump -i eth1 host 192.168.1.1 and port 80 //抓包以流为单位显示数据内容tcpflow -cp host 192.168.1.1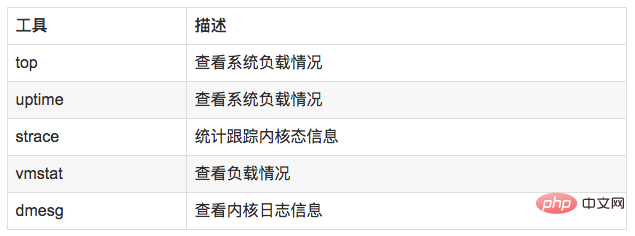
//查看负载情况uptimetopvmstat//统计系统调用耗时情况strace -c -p pid//跟踪指定的系统操作例如epoll_waitstrace -T -e epoll_wait -p pid//查看内核日志信息dmesg
常见的火焰图类型有 On-CPU、Off-CPU、Memory、Hot/Cold、Differential等等。
//安装systemtap,默认系统已安装yum install systemtap systemtap-runtime//内核调试库必须跟内核版本对应,例如:uname -r 2.6.18-308.el5kernel-debuginfo-2.6.18-308.el5.x86_64.rpmkernel-devel-2.6.18-308.el5.x86_64.rpmkernel-debuginfo-common-2.6.18-308.el5.x86_64.rpm//安装内核调试库debuginfo-install --enablerepo=debuginfo search kerneldebuginfo-install --enablerepo=debuginfo search glibc
git clone https://github.com/lidaohang/quick_location.gitcd quick_location
cpu占用过高,或者使用率提不上来,你能快速定位到代码的哪块有问题吗?
一般的做法可能就是通过日志等方式去确定问题。现在我们有了火焰图,能够非常清晰的发现哪个函数占用cpu过高,或者过低导致的问题。另外,搜索公众号Linux就该这样学后台回复“猴子”,获取一份惊喜礼包。
//on-CPU usersh ngx_on_cpu_u.sh pid//进入结果目录 cd ngx_on_cpu_u//on-CPU kernelsh ngx_on_cpu_k.sh pid//进入结果目录 cd ngx_on_cpu_k//开一个临时端口 8088 python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
DEMO:
#include <stdio.h>#include <stdlib.h>
void foo3(){ }
void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();}
void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();}
int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); }}DEMO火焰图:

cpu过低,利用率不高。等待下一轮CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡眠、锁、空闲等状态。
使用方式:
// off-CPU usersh ngx_off_cpu_u.sh pid//进入结果目录cd ngx_off_cpu_u//off-CPU kernelsh ngx_off_cpu_k.sh pid//进入结果目录cd ngx_off_cpu_k//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
官网DEMO:
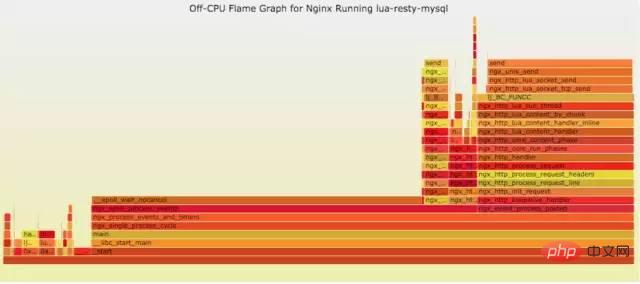
如果线上程序出现了内存泄漏,并且只在特定的场景才会出现。这个时候我们怎么办呢?有什么好的方式和工具能快速的发现代码的问题呢?同样内存级别火焰图帮你快速分析问题的根源。
使用方式:
sh ngx_on_memory.sh pid//进入结果目录cd ngx_on_memory//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
官网DEMO:
你能快速定位CPU性能回退的问题么?如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。主要可以用到每次构建中,每次上线做对比看,如果损失严重可以立马解决修复。
通过抓取了两张普通的火焰图,然后进行对比,并对差异部分进行标色:红色表示上升,蓝色表示下降。差分火焰图是以当前(“修改后”)的profile文件作为基准,形状和大小都保持不变。因此你通过色彩的差异就能够很直观的找到差异部分,且可以看出为什么会有这样的差异。
使用方式:
cd quick_location//抓取代码修改前的profile 1文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks1//抓取代码修改后的profile 2文件perf record -F 99 -p pid -g -- sleep 30perf script > out.stacks2//生成差分火焰图:./FlameGraph/stackcollapse-perf.pl ../out.stacks1 > out.folded1./FlameGraph/stackcollapse-perf.pl ../out.stacks2 > out.folded2./FlameGraph/difffolded.pl out.folded1 out.folded2 | ./FlameGraph/flamegraph.pl > diff2.svg
DEMO:
//test.c#include <stdio.h>#include <stdlib.h>
void foo3(){ }
void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();}
void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();}
int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); }}
//test1.c#include <stdio.h>#include <stdlib.h>
void foo3(){
}
void foo2(){ int i; for(i=0 ; i < 10; i++) foo3();}
void foo1(){ int i; for(i = 0; i< 1000; i++) foo3();}
void add(){ int i; for(i = 0; i< 10000; i++) foo3();}
int main(void){ int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); add(); }}DEMO红蓝差分火焰图:

a) **nginx 요청 트래픽 분석:
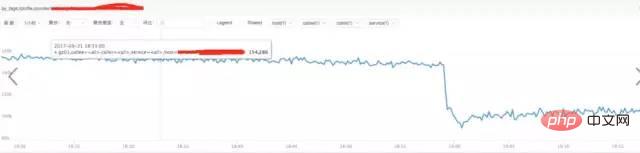
결론:
위 그림을 통해 트래픽이 증가하지 않음을 확인했습니다. 갑자기, 대신 감소, 팔로우 요청 트래픽이 갑자기 증가해도 문제가 되지 않습니다.
b) **nginx 응답 시간 분석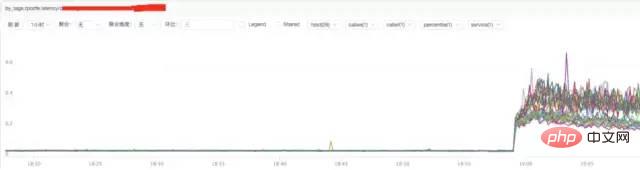
결론:
위 그림에서 nginx 응답 시간의 증가는 nginx 자체 또는 백엔드와 관련이 있을 수 있음을 알 수 있습니다. 업스트림 응답 시간.
c) **nginx 업스트림 응답 시간 분석
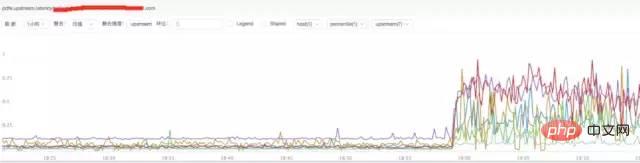
결론:
위 그림을 보면 nginx 업스트림 응답 시간이 증가한 것으로 추측됩니다. 백엔드 업스트림 응답 시간으로 인해 nginx가 지연되어 nginx에 비정상적인 요청 트래픽이 발생할 수 있습니다.
a) **상단을 통해 시스템 표시 관찰
상단top
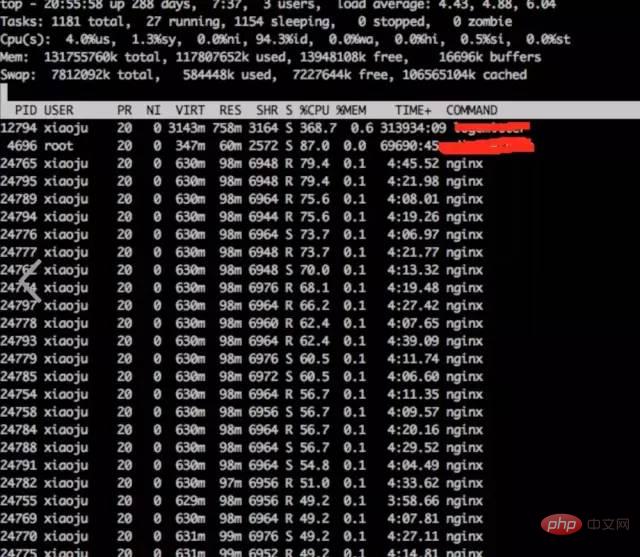
结论:
发现nginx worker cpu比较高
b) **分析nginx进程内部cpu情况
perf top -p pid
🎜🎜🎜결론:🎜🎜🎜🎜nginx 작업자 CPU가 상대적으로 높다는 것을 발견했습니다🎜🎜🎜🎜 b) 🎜**🎜nginx 프로세스의 내부 CPU 상황 분석🎜🎜🎜perf top -p pid🎜结论:
发现主要开销在free,malloc,json解析上面
10.4 火焰图分析cpu
a) **生成用户态cpu火焰图
//on-CPU usersh ngx_on_cpu_u.sh pid//进入结果目录cd ngx_on_cpu_u//开一个临时端口8088python -m SimpleHTTPServer 8088//打开浏览器输入地址127.0.0.1:8088/pid.svg
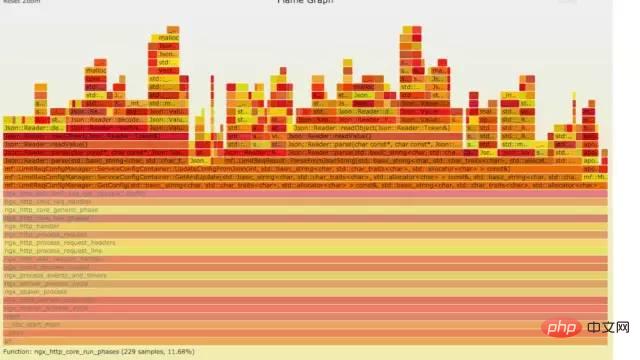
结论:
发现代码里面有频繁的解析json操作,并且发现这个json库性能不高,占用cpu挺高。
a) 分析请求流量异常,得出nginx upstream后端机器响应时间拉长
b) nginx 프로세스의 높은 CPU를 분석한 결과, nginx 내부 모듈 코드에는 json 구문 분석 및 메모리 할당 및 재활용 작업에 시간이 많이 걸리는 것으로 결론지었습니다.
위의 두 가지 사항에 대한 분석을 바탕으로 결론을 내리고, 더 심층적으로 분석합니다.
백엔드 업스트림 응답이 확장되어 nginx의 처리 기능에 기껏해야 영향을 미칠 수 있습니다. 그러나 너무 많은 CPU 작업을 차지하는 nginx 내부 모듈에는 영향을 미치지 않을 것입니다. 그리고 당시 CPU를 많이 점유하고 있던 모듈들은 요청이 있을 때만 실행되었습니다. 업스트램 백엔드가 nginx를 보류하여 CPU의 시간 소모적인 작업을 트리거할 가능성은 거의 없습니다.
이런 종류의 문제가 발생하면 알려지고 매우 명확한 문제를 해결하는 데 우선 순위를 둘 것입니다. CPU가 높을수록 문제가 됩니다. 해결 방법은 CPU를 너무 많이 소모하는 모듈을 다운그레이드하고 닫은 후 관찰하는 것입니다. 모듈을 다운그레이드하고 종료한 후 CPU가 저하되고 nginx 요청 트래픽이 정상화되었습니다. 업스트림 시간이 길어지는 이유는 업스트림 백엔드 서비스에서 호출한 인터페이스가 루프가 되어 다시 nginx로 돌아갈 수 있기 때문입니다.
http://www.brendangregg.com/index.html
http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
http://www.brendangregg.com/FlameGraphs/memoryflamegraphs.html
http://www.brendangregg.com/FlameGraphs/offcpuflamegraphs.html
http://www.brendangregg. com/blog/2014-11-09/ Differential-flame-graphs.html
https://github.com/openresty/openresty-systemtap-toolkit
https://github.com com/brendangregg/FlameGraph
위 내용은 Linux 운영 및 유지보수 문제 해결 아이디어는 이 글이면 충분합니다~의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



