


7월 13일 뉴스에 따르면, 외신 세미애널리시스(Semianalytics)는 최근 올해 3월 OpenAI가 출시한 GPT-4 대형 모델을 공개했는데, GPT-4 모델 아키텍처, 학습 및 추론 인프라, 매개변수 볼륨, 학습 데이터가 포함되어 있습니다. 세트, 토큰 수, 비용, 전문가 혼합 및 기타 특정 매개변수 및 정보.
▲ 사진 출처 Semianalytic
외신에 따르면 GPT-4는 120개 레이어에 총 1조 8천억 개의 매개변수가 포함되어 있는 반면, GPT-3에는 약 1,750억 개의 매개변수만 포함되어 있습니다. 비용을 합리적으로 유지하기 위해 OpenAI는 하이브리드 전문가 모델을 사용하여 구축합니다.
IT 홈 참고: Mixture of Experts는 일종의 신경망입니다. 시스템은 데이터를 기반으로 여러 모델을 분리하고 훈련한 후 이러한 모델을 단일 작업으로 통합하여 출력합니다.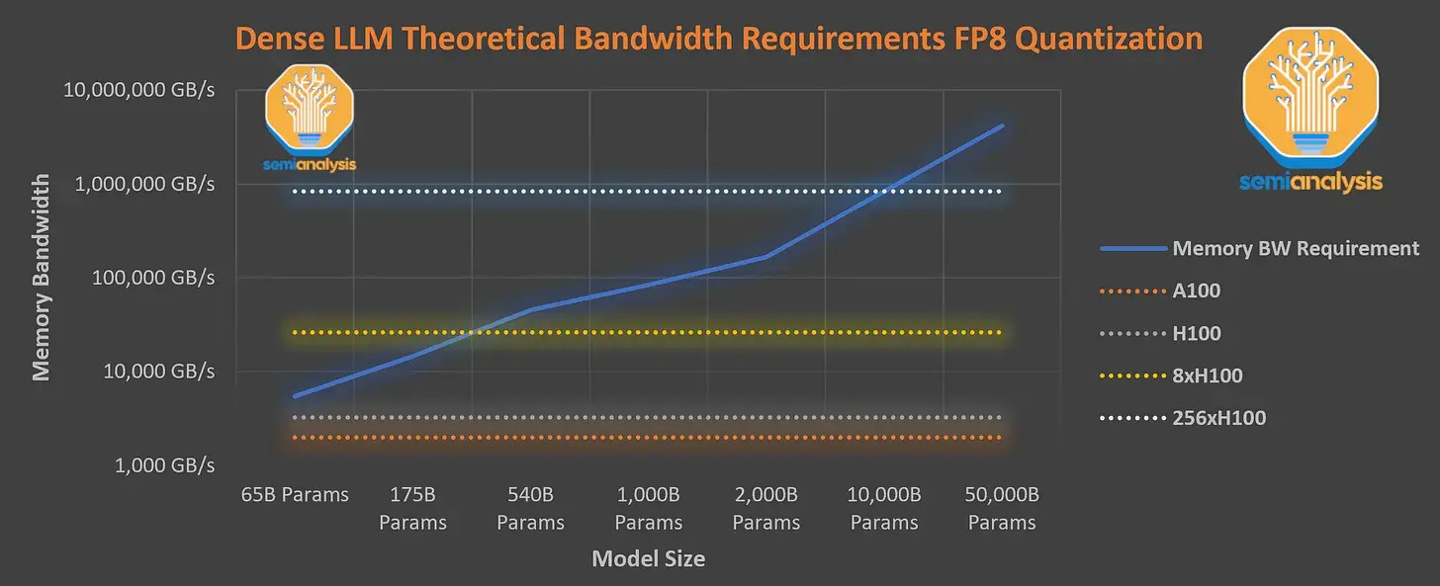
GPT-4는 각각 1,110억 개의 매개변수를 가진 16개의 혼합 전문가 모델(전문가의 혼합)을 사용하고 각 순방향 패스는 두 개의 전문가 모델을 통과한다고 합니다 .
또한 550억 개의 공유 주의 매개변수가 있으며 13조 개의 토큰이 포함된 데이터세트를 사용하여 훈련되었습니다. 토큰은 고유하지 않으며 반복 횟수에 따라 더 많은 토큰으로 계산됩니다. GPT-4 사전 훈련 단계의 컨텍스트 길이는 8k이고, 32k 버전은 8k를 미세 조정한 결과입니다. 외국 언론에서는8x H100이 필요한 밀도를 제공할 수 없다고 말했습니다. 초당 33.33 토큰의 속도를 제공하므로 이 모델을 훈련하려면 H100 물리적 기계의 경우 시간당 1달러로 계산하면 1회 훈련 비용이 6,300만 달러(약 4억 5,100만 위안)에 달합니다. ). 이와 관련하여
OpenAI는 클라우드에서 A100 GPU를 사용하여 모델을 훈련하기로 결정하여 최종 훈련 비용을 약 2,150만 달러(약 1억 5,400만 위안)로 줄였습니다. 이는 훈련 비용을 줄이는 데 약간 더 오랜 시간이 걸렸습니다.
위 내용은 GPT-4 모델 아키텍처 유출: 하이브리드 전문가 모델을 사용하여 1조 8천억 개의 매개변수 포함의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



