

최근 몇 년 동안 이미지 생성 분야, 특히 텍스트-이미지 생성 분야에서 큰 발전이 있었습니다. 텍스트를 사용하여 생각을 설명하는 한 AI는 참신하고 현실적인 이미지를 생성할 수 있습니다.
그러나 실제로는 한 단계 더 나아갈 수 있습니다. 마음 속의 생각을 텍스트로 변환하는 단계는 생략할 수 있고, 이미지 생성은 뇌 활동(예: EEG(뇌전도) 기록)을 통해 직접 제어할 수 있습니다.
이 "생각을 이미지로" 생성 방법은 광범위한 응용 가능성을 가지고 있습니다. 예를 들어, 예술 창작의 효율성을 크게 향상시키고 사람들이 순간적인 영감을 포착하는 데 도움을 줄 수 있으며, 밤에 사람들의 꿈을 시각화하는 것도 가능할 수 있으며, 자폐아와 언어 장애 환자를 돕기 위한 심리 치료에도 사용될 수 있습니다.
최근 Tsinghua University Shenzhen International Graduate School, Tencent AI Lab 및 Pengcheng Laboratory의 연구원들은 사전 훈련된 텍스트-이미지 모델(예: Stable Diffusion)을 사용하여 "Thinking to Image"에 관한 연구 논문을 공동으로 발표했습니다. 의 강력한 생성 기능은 EEG 신호에서 직접 고품질 이미지를 생성합니다.
 Pictures
Pictures
논문 주소: https://arxiv.org/pdf/2306.16934.pdf
프로젝트 주소: https://github.com/bbaaii/DreamDiffusion
최근 일부 관련 연구(예: MinD-Vis)에서는 fMRI(기능적 자기 공명 영상 신호)를 기반으로 시각 정보를 재구성하려고 시도합니다. 그들은 뇌 활동을 사용하여 고품질 결과를 재구성하는 타당성을 입증했습니다. 그러나 이러한 방법은 빠르고 효율적인 생성을 위한 뇌 신호의 이상적인 사용과는 여전히 거리가 멀습니다. 이는 주로 두 가지 이유에 기인합니다:
첫째, fMRI 장비는 휴대가 불가능하고 전문가가 작동해야 하므로 fMRI 신호를 캡처하는 것이 매우 어렵습니다. 어렵습니다;
둘째, fMRI 데이터 수집 비용이 높기 때문에 실제 예술 창작에 이 방법을 사용하는 데 큰 방해가 됩니다.
반면 EEG는 뇌 전기 활동을 기록하는 비침습적, 저비용 방법이며 현재 EEG 신호를 얻을 수 있는 휴대용 상용 제품이 시중에 나와 있습니다.
그러나 "생각을 이미지로" 생성하는 데에는 여전히 두 가지 주요 과제가 있습니다.
1) EEG 신호는 비침습적 방법을 통해 캡처되므로 본질적으로 잡음이 많습니다. 또한 뇌파 데이터는 제한적이어서 개인차도 무시할 수 없습니다. 그렇다면 수많은 제약 조건 하에서 EEG 신호로부터 효과적이고 견고한 의미 표현을 얻는 방법은 무엇일까요?
2) CLIP을 사용하고 수많은 텍스트-이미지 쌍에 대한 학습으로 인해 Stable Diffusion의 텍스트와 이미지 공간이 잘 정렬됩니다. 그러나 EEG 신호는 고유한 특성을 가지며 그 공간은 텍스트 및 이미지와 상당히 다릅니다. 제한적이고 시끄러운 EEG 이미지 쌍에서 EEG, 텍스트 및 이미지 공간을 정렬하는 방법은 무엇입니까?
첫 번째 과제를 해결하기 위해 이 연구에서는 희귀한 EEG 이미지 쌍 대신 대량의 EEG 데이터를 사용하여 EEG 표현을 훈련하는 것을 제안합니다. 본 연구에서는 마스킹된 신호 모델링 방법을 사용하여 상황별 단서를 기반으로 누락된 토큰을 예측합니다.
입력을 2차원 이미지로 처리하고 공간 정보를 마스크하는 MAE 및 MinD-Vis와 달리, 본 연구에서는 EEG 신호의 시간적 특성을 고려하고 인간 두뇌의 시간적 변화 뒤에 숨은 의미를 깊이 파고듭니다. . 본 연구에서는 토큰의 일부를 무작위로 차단한 다음 차단된 토큰을 시간 영역에서 재구성했습니다. 이러한 방식으로 사전 훈련된 인코더는 다양한 개인과 다양한 뇌 활동의 EEG 데이터에 대한 깊은 이해를 개발할 수 있습니다.
두 번째 과제의 경우, 이전 솔루션은 일반적으로 훈련을 위해 소수의 시끄러운 데이터 쌍을 사용하여 안정 확산 모델을 직접 미세 조정했습니다. 그러나 최종 이미지 재구성 손실을 통해 SD end-to-end를 미세 조정하는 것만으로는 뇌 신호(예: EEG 및 fMRI)와 텍스트 공간 간의 정확한 정렬을 학습하기 어렵습니다. 따라서 연구팀은 EEG, 텍스트 및 이미지 공간의 정렬을 달성하는 데 도움이 되도록 추가적인 CLIP 감독을 사용할 것을 제안했습니다.
구체적으로 SD 자체는 CLIP의 텍스트 인코더를 사용하여 텍스트 임베딩을 생성하는데, 이는 이전 단계의 Masked Pre-trained EEG 임베딩과는 매우 다릅니다. CLIP의 이미지 인코더를 활용하여 CLIP의 텍스트 임베딩과 잘 정렬된 풍부한 이미지 임베딩을 추출하세요. 그런 다음 이러한 CLIP 이미지 임베딩을 사용하여 EEG 임베딩 표현을 더욱 구체화했습니다. 따라서 개선된 EEG 특징 임베딩은 CLIP의 이미지 및 텍스트 임베딩과 잘 정렬될 수 있으며 SD 이미지 생성에 더 적합하므로 생성된 이미지의 품질이 향상됩니다.
위의 세심하게 설계된 두 가지 솔루션을 기반으로 본 연구에서는 새로운 방법인 DreamDiffusion을 제안합니다. DreamDiffusion은 뇌전도(EEG) 신호로부터 고품질의 사실적인 이미지를 생성합니다.
 Pictures
Pictures
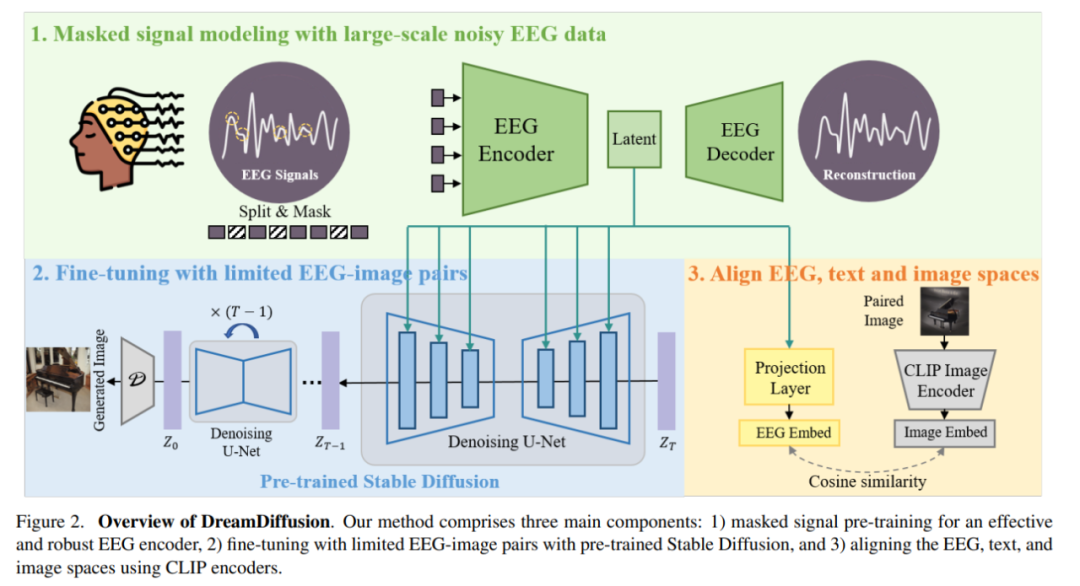
특히 DreamDiffusion은 주로 세 부분으로 구성됩니다.
1) 효과적이고 견고한 EEG 인코더를 달성하기 위한 마스크 신호 사전 훈련
2) 사전 훈련된 Stable 사용 미세 조정을 위한 확산 및 제한된 EEG 이미지 쌍
3) CLIP 인코더를 사용하여 EEG, 텍스트 및 이미지 공간을 정렬합니다.
먼저, 연구진은 노이즈가 많은 뇌파 데이터를 사용하고 마스크 신호 모델링을 사용하여 뇌파 인코더를 훈련시키고 상황별 지식을 추출했습니다. 그런 다음 결과 EEG 인코더는 교차 주의 메커니즘을 통해 Stable Diffusion에 대한 조건부 기능을 제공하는 데 사용됩니다.
 Pictures
Pictures
Stable Diffusion과 EEG 기능의 호환성을 높이기 위해 연구진은 미세 조정 중에 EEG 임베딩과 CLIP 이미지 임베딩 사이의 거리를 줄여 EEG, 텍스트, 이미지를 더욱 정렬했습니다. 프로세스. 임베디드 공간.
Brain2Image와의 비교
연구원들은 이 기사의 방법을 Brain2Image와 비교했습니다. Brain2Image는 EEG를 이미지로 변환하기 위해 VAE(Variational Autoencoder) 및 GAN(Generative Adversarial Network)이라는 전통적인 생성 모델을 사용합니다. 그러나 Brain2Image는 일부 범주에 대한 결과만 제공하고 참조 구현을 제공하지 않습니다.
이를 염두에 두고 본 연구에서는 Brain2Image 논문에 제시된 여러 범주(예: 비행기, 잭오랜턴, 팬더)에 대한 질적 비교를 수행했습니다. 공정한 비교를 보장하기 위해 연구원들은 Brain2Image 논문에 설명된 것과 동일한 평가 전략을 사용하고 아래 그림 5에 다양한 방법으로 생성된 결과를 보여줍니다.
아래 그림의 첫 번째 행은 Brain2Image로 생성된 결과이고, 마지막 행은 연구진이 제안한 방법인 DreamDiffusion으로 생성된 결과입니다. DreamDiffusion에 의해 생성된 이미지 품질이 Brain2Image에 의해 생성된 이미지 품질보다 훨씬 높다는 것을 알 수 있으며, 이는 또한 이 방법의 효율성을 검증합니다.
 Pictures
Pictures
절제 실험
사전 훈련의 역할: 대규모 EEG 데이터 사전 훈련의 효과를 입증하기 위해 이 연구에서는 훈련되지 않은 인코더를 사용하여 훈련했습니다. 여러 모델을 검증합니다. 모델 중 하나는 전체 모델과 동일했고, 다른 모델에는 데이터 과적합을 방지하기 위해 두 개의 EEG 코딩 레이어만 있었습니다. 훈련 과정에서 두 모델은 각각 CLIP 감독 유무에 따라 훈련되었으며 결과는 표 1의 모델 열 1~4에 나와 있습니다. 사전 훈련을 하지 않은 모델의 정확도가 떨어지는 것을 볼 수 있습니다.
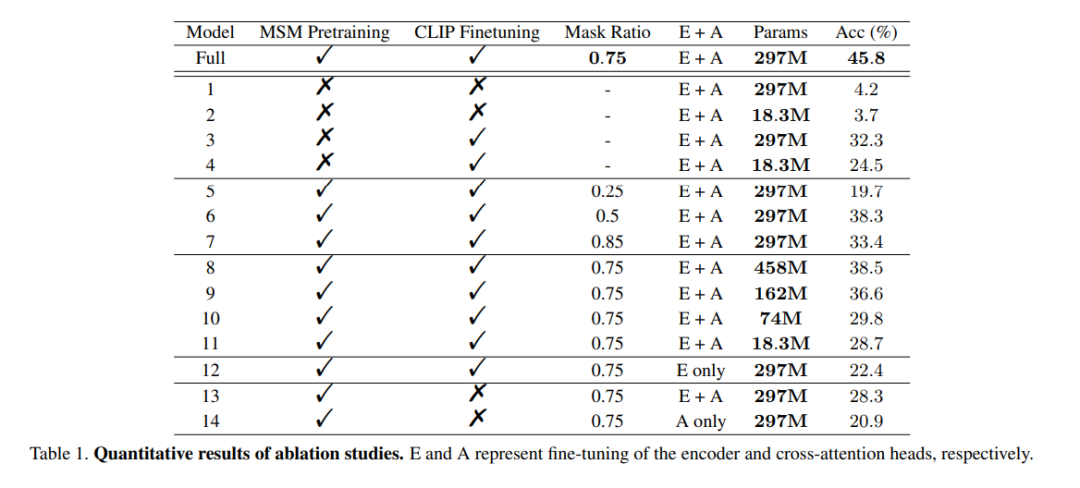
마스크 비율: 이 문서에서는 또한 MSM 사전 훈련을 위한 최적의 마스크 비율을 결정하기 위해 EEG 데이터의 사용을 조사합니다. 표 1 모델의 5~7열에 표시된 것처럼 마스크 비율이 너무 높거나 낮으면 모델 성능에 부정적인 영향을 미칠 수 있습니다. 마스크 비율이 0.75일 때 전체 정확도가 가장 높습니다. 이 발견은 일반적으로 낮은 마스크 비율을 사용하는 자연어 처리와 달리 EEG에서 MSM을 수행할 때 높은 마스크 비율이 더 나은 선택임을 시사하기 때문에 중요합니다.
CLIP 정렬: 이 방법의 핵심 중 하나는 CLIP 인코더를 통해 EEG 표현을 이미지에 정렬하는 것입니다. 본 연구에서는 이 방법의 유효성을 검증하기 위해 실험을 수행하였고, 그 결과를 Table 1에 나타내었다. CLIP 감시를 사용하지 않으면 모델의 성능이 크게 저하되는 것을 볼 수 있습니다. 실제로 그림 6의 오른쪽 하단에 표시된 것처럼 CLIP을 사용하여 EEG 기능을 정렬하면 사전 교육 없이도 여전히 합리적인 결과를 얻을 수 있으며, 이는 이 방법에서 CLIP 감독의 중요성을 강조합니다.
 사진
사진
위 내용은 이제 당신의 두뇌 속 그림을 고화질로 복원할 수 있습니다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



