



사전 교육의 효과는 직접적이며 필요한 리소스가 엄청나게 많은 경우가 있습니다. 이러한 사전 훈련 방법이 존재하는 경우 시작에는 컴퓨팅 성능, 데이터 및 인적 자원이 거의 필요하지 않으며 심지어 한 사람과 단일 카드의 원래 코퍼스만 필요합니다. 비지도 데이터 처리 및 사전 훈련을 통해 자신의 도메인으로 이전하면 제로 샘플 NLG, NLG 및 벡터 표현 추론 기능을 얻을 수 있습니다. 다른 벡터 표현의 리콜 기능은 BM25를 초과합니다.

무언가를 하고 싶은지는 입력과 출력을 측정하여 결정해야 합니다. 사전 훈련은 큰 일이며 구현하기 전에 몇 가지 전제 조건과 리소스는 물론 충분한 예상 이점이 필요합니다. 일반적으로 요구되는 조건은 다음과 같습니다. 충분한 말뭉치 구축 일반적으로 말뭉치의 품질은 양보다 더 드물기 때문에 말뭉치의 품질은 완화될 수 있지만 두 번째로 그에 상응하는 인재 예비와 인력 예산이 있어야 합니다. 비교하자면, 작은 모델은 훈련하기 쉽고 장애물이 적은 반면, 큰 모델은 더 많은 문제에 직면하게 됩니다. 마지막으로 컴퓨팅 리소스는 사람에 따라 다릅니다. 대용량 메모리 그래픽 카드. 사전 학습을 통해 얻을 수 있는 이점도 매우 직관적입니다. 모델을 마이그레이션하면 효과 개선이 직접적으로 나타날 수 있습니다. 개선 정도는 사전 학습 투자 및 도메인 차이와 직접적인 관련이 있습니다. 모델 개선 및 비즈니스 규모에 따라 최종 이점을 얻을 수 있습니다. .
저희 시나리오에서는 데이터 분야가 일반 분야와 많이 다르고, 어휘까지 대폭 교체해야 하고, 사업 규모도 충분합니다. 사전 훈련되지 않은 경우 모델은 각 다운스트림 작업에 맞게 특별히 미세 조정됩니다. 사전 훈련을 통해 기대되는 이점은 확실합니다. 우리 말뭉치의 질은 낮지만 양은 충분합니다. 컴퓨팅 파워 자원은 매우 제한되어 있으며 해당 인재 보유량을 일치시켜 보상할 수 있습니다. 이때 사전 훈련 조건은 이미 충족되었습니다.
사전 훈련을 시작하는 방법을 직접적으로 결정하는 요인은 유지 관리해야 할 다운스트림 모델이 너무 많고, 특히 기계와 인적 자원을 많이 차지한다는 것입니다. 각 작업마다 전용 모델을 교육하기 위한 거버넌스의 복잡성이 크게 증가했습니다. 따라서 우리는 모든 다운스트림 모델에 도움이 되는 통합된 사전 학습 작업을 구축하기를 희망하면서 사전 학습을 탐색합니다. 이를 수행하면 유지 관리해야 하는 모델이 많아진다는 것은 자기 지도 학습, 대조 학습, 다중 작업 학습 등을 포함한 여러 이전 프로젝트의 경험과 결합되어 더 많은 모델 경험을 의미합니다. 반복적인 실험과 반복 끝에 Fusion이 탄생했습니다.
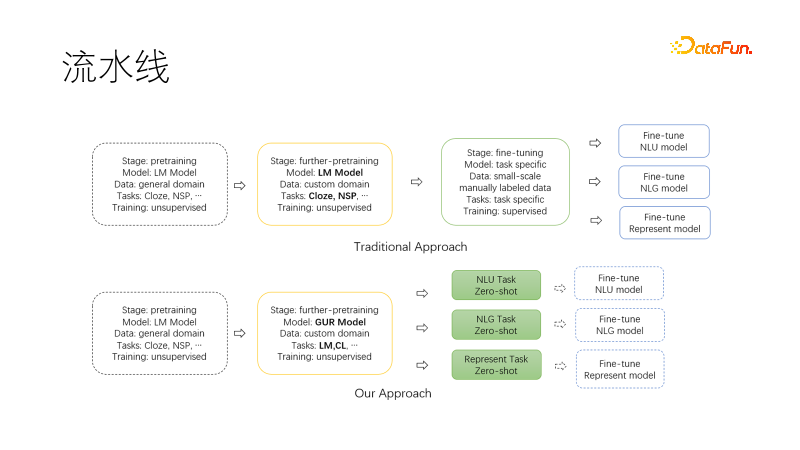
위 그림은 기존 일반 사전 학습 모델을 기반으로 하는 전통적인 nlp 파이프라인 패러다임입니다. 선택적 마이그레이션 사전 학습이 완료된 후 각 다운스트림 작업에 대한 데이터 세트가 수집됩니다. 훈련을 조정하고 여러 다운스트림 모델과 서비스를 유지하려면 많은 노동력과 그래픽 카드가 필요합니다.
아래 그림은 사전 학습을 계속하기 위해 우리 분야로 마이그레이션할 때 공동 언어 모델링 작업과 비교 학습 작업을 사용하여 출력 모델에 제로 샘플 NLU, NLG, 및 벡터 표현. 이러한 기능은 모델링되었으며 요청 시 액세스할 수 있습니다. 이런 방식으로 유지 관리해야 할 모델이 줄어들고, 특히 프로젝트가 시작될 때 추가 미세 조정이 필요한 경우 연구에 직접 사용할 수 있어 필요한 데이터의 양도 크게 줄어듭니다.
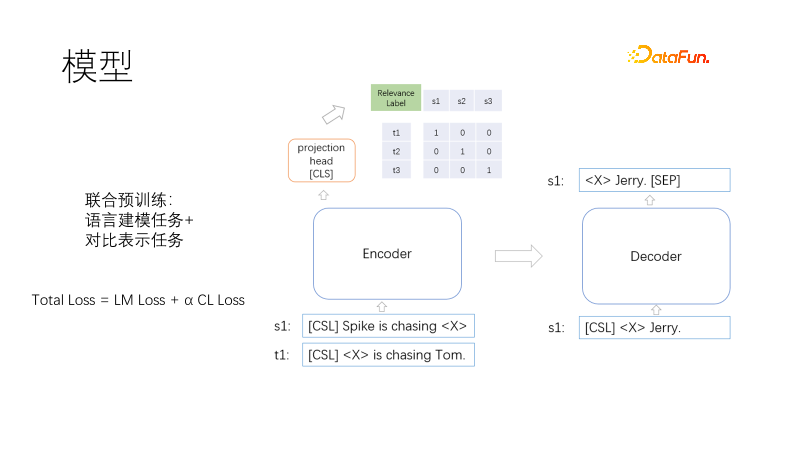
이것은 Transformer의 인코더, 디코더 및 벡터 표현 헤드를 포함한 사전 훈련 모델 아키텍처입니다.
사전 학습의 목표에는 언어 모델링과 대조 표현이 포함됩니다. 손실 함수는 총 손실 = LM 손실 + α CL 손실입니다. 여기서 α는 가중치 계수를 나타냅니다. 언어 모델링은 마스크 부분만 디코딩하는 T5와 유사한 마스크 모델을 사용합니다. 대조 표현 작업은 배치 내에서 한 쌍의 관련 훈련 양성 샘플과 기타 비음수 샘플이 있습니다. 각 샘플 쌍(i, I) i에는 양성 샘플 I이 있고 다른 하나는 있습니다. 샘플은 대칭 교차 엔트로피 손실을 사용하여 양수 샘플의 표현을 가깝게 하고 음수 샘플의 표현을 멀리 떨어지게 하는 음수 샘플입니다. T5 디코딩을 사용하면 디코딩 길이가 단축될 수 있습니다. 비선형 벡터 표현은 헤드 로딩 인코더 위에 배치됩니다. 하나는 벡터 표현이 시나리오에서 더 빨라야 한다는 것이고, 다른 하나는 표시된 두 기능이 훈련 대상 충돌을 방지하기 위해 멀리 작동한다는 것입니다. 그렇다면 Cloze 작업은 매우 일반적이며 샘플이 필요하지 않습니다. 그렇다면 유사한 샘플 쌍은 어떻게 생성됩니까?

물론, 사전 훈련 방법으로 샘플 쌍은 비지도 알고리즘에 의해 채굴되어야 합니다. 일반적으로 정보 검색 분야에서 양성 샘플을 마이닝하는 데 사용되는 기본 방법은 역 클로즈(Reverse Cloze)로, 문서 내 여러 조각을 마이닝하고 서로 연관되어 있다고 가정합니다. 여기서는 문서를 문장으로 분할한 다음 문장 쌍을 열거합니다. 두 문장이 서로 관련되어 있는지 확인하기 위해 가장 긴 공통 부분 문자열을 사용합니다. 그림과 같이 두 개의 긍정문과 부정문 쌍을 취하고, 가장 긴 공통 부분 문자열이 어느 정도 길면 유사하다고 판단하고, 그렇지 않으면 유사하지 않다고 판단합니다. 임계값은 스스로 선택합니다. 예를 들어 긴 문장에는 한자가 3개 필요하고, 짧은 문장에는 더 많은 문자가 필요합니다.
두 목표가 상충되기 때문에 의미론적 동등성 대신 상관관계를 샘플 쌍으로 사용합니다. 위 그림에서 볼 수 있듯이, 고양이가 쥐를 잡는 것과 쥐가 고양이를 잡는다는 의미는 반대이지만 관련이 있습니다. 우리의 시나리오 검색은 주로 관련성에 중점을 둡니다. 더욱이 상관관계는 의미론적 동등성보다 넓으며, 상관관계를 기반으로 지속적인 미세 조정에 의미론적 동등성이 더 적합합니다.
여러번 필터링되는 문장도 있고, 필터링되지 않는 문장도 있습니다. 우리는 선택되는 문장의 빈도를 제한합니다. 실패한 문장의 경우 양성 샘플로 복사하거나 선택한 문장에 연결하거나 역 클로즈를 양성 샘플로 사용할 수 있습니다.
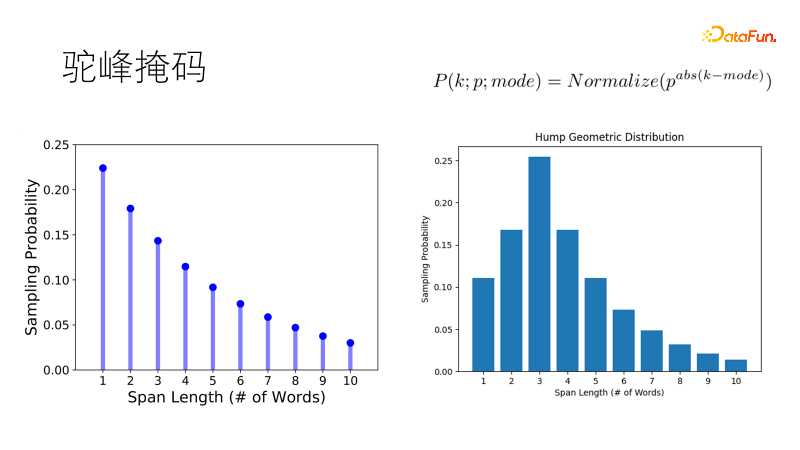
SpanBert와 같은 전통적인 마스킹 방법은 기하학적 분포를 사용하여 마스크 길이를 샘플링합니다. 짧은 마스크는 확률이 높고 긴 마스크는 확률이 낮으므로 긴 문장에 적합합니다. 그러나 우리의 코퍼스는 단편화되어 있습니다. 한 단어 또는 스무 단어로 구성된 짧은 문장에 직면하면 전통적인 경향은 하나의 이중 단어가 아닌 두 개의 단일 단어를 가리는 경향이 있는데 이는 우리의 기대에 미치지 못합니다. 그래서 우리는 이 분포를 개선하여 최적의 길이를 샘플링할 확률이 가장 높고, 다른 길이의 확률은 낙타의 혹처럼 점차 감소하여 짧은 문장에서 더 견고한 낙타혹의 기하학적 분포가 되도록 개선했습니다. 풍부한 시나리오.
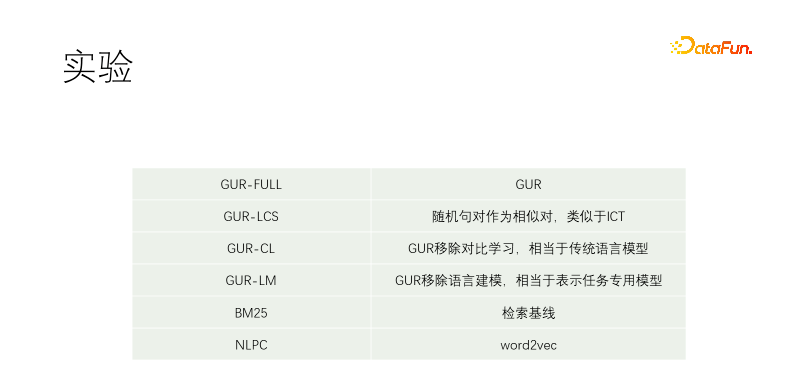
통제된 실험을 실시했습니다. 언어 모델링 및 벡터 대비 표현을 사용하는 GUR-CLS 샘플 쌍은 LCS에 의해 필터링되지 않습니다. 이는 기존 언어 모델과 동일한 GUR-LM입니다. 언어 모델링 학습이 없는 대조 표현 학습은 특히 다운스트림 작업을 위한 미세 조정과 동일합니다. NLPC는 Baidu의 word2vec 연산자입니다.
실험은 T5-small로 시작하여 사전 훈련을 계속했습니다. 교육 말뭉치에는 Wikipedia, Wikisource, CSL 및 자체 말뭉치가 포함됩니다. 우리 자신의 코퍼스는 재료 라이브러리에서 캡처되며 품질이 가장 좋지 않은 부분은 재료 라이브러리의 제목입니다. 따라서 다른 문서에서 긍정적인 샘플을 파헤칠 때 거의 모든 텍스트 쌍이 선별되는 반면, 우리 코퍼스에서는 제목이 텍스트의 모든 문장과 일치하는 데 사용됩니다. LCS에서 GUR-LCS를 선택하지 않은 경우 샘플 쌍이 너무 나빠집니다. 이렇게 하면 GUR-FULL과의 차이가 훨씬 작아집니다.
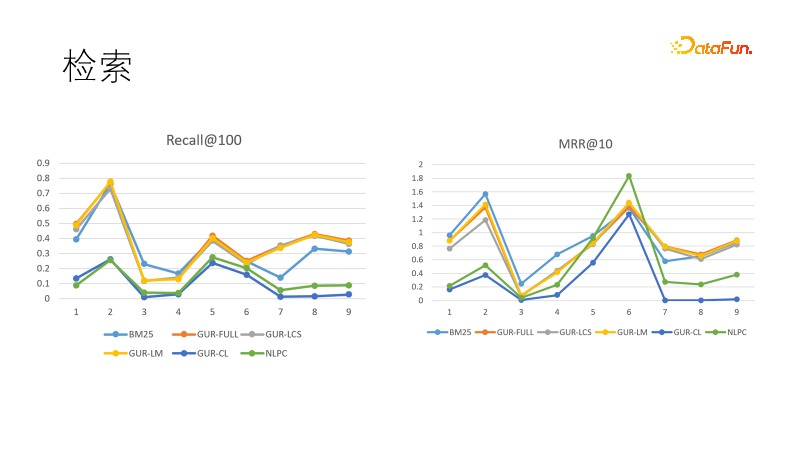
여러 검색 작업에 대한 모델의 벡터 표현 효과를 평가합니다. 왼쪽 그림은 재현율에 있는 여러 모델의 성능을 보여줍니다. 벡터 표현을 통해 학습한 모델이 BM25보다 성능이 가장 좋은 것으로 나타났습니다. 순위 대상도 비교했는데 이번에는 BM25가 승리를 거두며 돌아왔습니다. 이는 밀집 모델은 일반화 능력이 강하고 희소 모델은 결정성이 강하며, 둘이 서로 보완할 수 있음을 보여줍니다. 실제로 정보 검색 분야의 다운스트림 작업에서는 밀집 모델과 희소 모델이 함께 사용되는 경우가 많습니다.
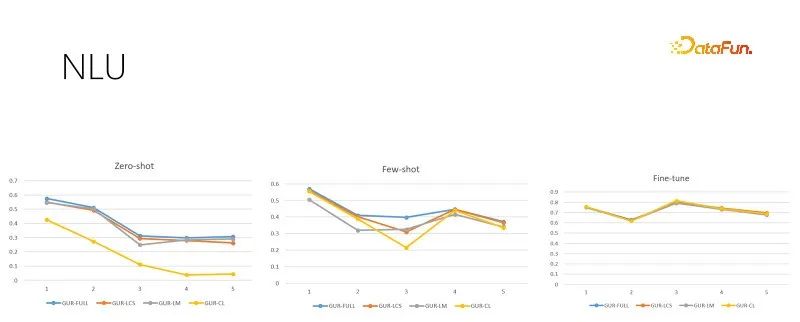
위 그림은 훈련 샘플 크기가 다른 NLU 평가 작업입니다. 각 작업에는 수십에서 수백 개의 범주가 있으며 ACC 점수를 사용하여 효과를 평가합니다. GUR 모델은 또한 분류 레이블을 벡터로 변환하여 각 문장에 대해 가장 가까운 레이블을 찾습니다. 위 그림은 왼쪽부터 오른쪽으로 훈련 표본 크기의 증가에 따른 제로 샘플, 작은 샘플 및 충분한 미세 조정 평가를 보여줍니다. 오른쪽 그림은 충분한 미세 조정 후의 모델 성능으로, 각 하위 작업의 난이도를 보여주며, 영표본 및 소표본 성능의 상한선이기도 합니다. GUR 모델은 벡터 표현에 의존하여 일부 분류 작업에서 제로 샘플 추론을 달성할 수 있음을 알 수 있습니다. 그리고 GUR 모델의 작은 샘플 기능이 가장 뛰어납니다.
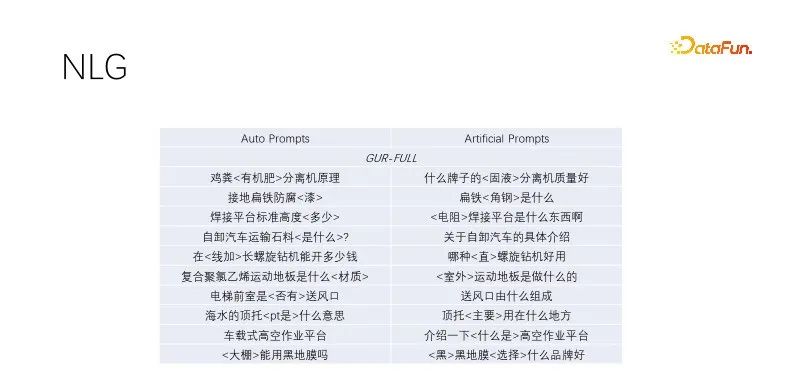
이것은 NLG의 제로 샘플 성능입니다. 제목 생성 및 쿼리 확장을 수행할 때 고품질 트래픽으로 제목을 마이닝하고 키워드를 유지하며 키워드가 아닌 단어를 무작위로 마스킹합니다. 언어 모델링으로 훈련된 모델은 잘 수행됩니다. 이 자동 프롬프트 효과는 수동으로 구성된 타겟 효과와 유사하며 다양성이 더 넓고 대량 생산이 가능합니다. 언어 모델링 작업을 거친 여러 모델은 유사하게 수행됩니다. 위 그림에서는 GUR 모델 예제를 사용합니다.
이 글은 새로운 사전 훈련 패러다임을 제안합니다. 위의 제어 실험은 공동 훈련이 목표 충돌을 일으키지 않는다는 것을 보여줍니다. GUR 모델이 계속해서 사전 학습되면 언어 모델링 기능을 유지하면서 벡터 표현 기능을 향상시킬 수 있습니다. 한 번만 사전 훈련하면 어디에서나 원본 샘플이 전혀 없는 추론이 가능합니다. 비즈니스 부서의 저렴한 사전 교육에 적합합니다.

위 링크에는 교육 세부 정보가 기록되어 있습니다. 자세한 내용은 논문 인용문을 참조하세요. 코드 버전은 논문보다 약간 최신입니다. AI 민주화에 작은 기여라도 하고 싶습니다. 크고 작은 모델에는 고유한 적용 시나리오가 있으며 다운스트림 작업에 직접 사용되는 것 외에도 GUR 모델은 대규모 모델과 결합하여 사용할 수도 있습니다. 파이프라인에서는 먼저 인식을 위해 소형 모델을 사용한 다음 작업을 지시하기 위해 대형 모델을 사용합니다. 대형 모델은 소형 모델에 대한 샘플을 생성할 수도 있고 GUR 소형 모델은 대형 모델에 대한 벡터 검색을 제공할 수 있습니다.
논문의 모델은 여러 실험을 탐색하기 위해 선택한 작은 모델입니다. 실제로 더 큰 모델을 선택하면 이득이 분명해집니다. 우리의 탐색만으로는 충분하지 않으며 추가 작업이 필요합니다. 원한다면 laohur@gmail.com으로 연락하여 모두와 함께 발전할 수 있기를 기대합니다.
위 내용은 가난이 나를 준비시킨다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



