

6월 14일, Tencent Robotics가 크게 개선되었습니다.
로봇 개를 인간이나 동물처럼 유연하고 안정적으로 만드는 것은 로봇공학 연구 분야의 장기적인 목표였습니다. 딥 러닝 기술의 지속적인 발전을 통해 기계는 '학습'을 통해 관련 능력을 습득하고 복잡하고 복잡한 문제에 대처하는 방법을 배울 수 있습니다. 변화하는 환경이 가능해집니다.
사전 훈련 및 강화 학습 소개: 로봇 개를 더 민첩하게 만들기
Tencent Robotics 다시 학습할 필요는 없지만, 이미 배운 자세, 환경 인식, 전략 기획 등 다단계 지식을 재사용하고 하나의 사례에서 추론을 도출하여 복잡한 환경에 유연하게 대처할 수 있습니다


이 일련의 학습은 세 단계로 구분됩니다.
첫 번째 단계에서는 게임 기술에서 자주 사용되는 모션 캡처 시스템을 통해 연구원은 걷기, 달리기, 점프, 서기 및 기타 동작을 포함한 실제 개들의 움직임 자세 데이터를 수집하고 이 데이터를 사용하여 모방 학습 과제를 구성했습니다. 그런 다음 이 데이터의 정보는 심층 신경망 모델로 추상화되고 압축됩니다. 이러한 모델은 수집된 동물의 움직임 자세 정보를 정확하게 포괄할 수 있을 뿐만 아니라 해석 가능성도 높습니다.
텐센트 로봇공학 이러한 기술과 데이터는 물리적 시뮬레이션 기반 에이전트 교육 및 실제 로봇 전략 배포에서 일정한 보조 역할을 합니다.
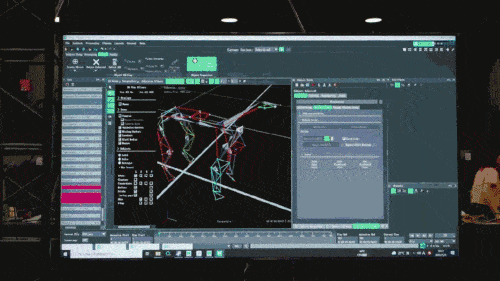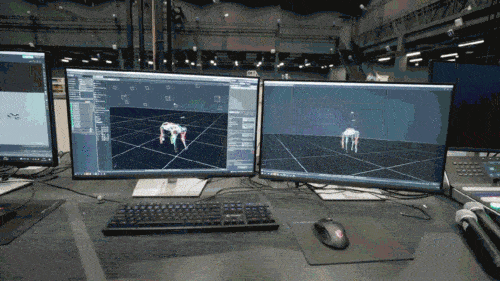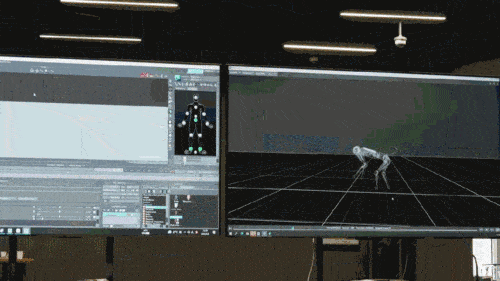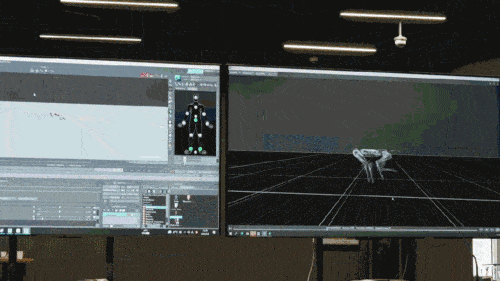

신경망 모델은 로봇개의 고유 감각 정보(예: 운동 상태)만 입력으로 받아들이고 모방 학습 방식으로 훈련됩니다. 다음 단계에서 모델은 다른 센서를 사용하여 발 밑의 장애물을 감지하는 등 주변 환경의 감각 데이터를 통합합니다.
2단계에서는 추가 네트워크 매개변수를 사용하여 1단계에서 마스터한 로봇개의 스마트 자세를 외부 인식과 연결하고, 로봇개가 학습한 스마트 자세를 통해 외부 환경에 반응할 수 있도록 합니다. 로봇개가 다양하고 복잡한 환경에 적응하게 되면 스마트한 자세와 외부 인식을 연결하는 지식도 신경망 구조에 굳어져 저장될 것이다.



세 번째 단계에서는 위의 두 가지 사전 훈련 단계에서 얻은 신경망을 활용하여 로봇개는 최상위 수준의 정책 학습 문제를 해결하는 데 집중할 수 있는 전제 조건과 기회를 갖게 되며, 최종적으로 복잡한 작업을 해결할 수 있는 능력을 갖추게 됩니다. -끝으로. 세 번째 단계에서는 게임 내 상대 및 깃발에 대한 정보를 얻는 등 복잡한 작업과 관련된 데이터를 수집하기 위해 추가 네트워크가 추가됩니다. 또한, 모든 정보를 종합적으로 분석하여 전략 학습을 담당하는 신경망은 어느 방향으로 달릴지, 상대의 행동을 예측하여 계속 추격할지 결정하는 등 작업에 대한 높은 수준의 전략을 학습하게 됩니다.
위의 각 단계에서 학습한 지식은 재학습 없이 확장, 조정이 가능하므로 지속적으로 축적, 학습이 가능합니다.
로봇개 장애물 추적 대회: 자율적인 의사결정 및 제어 능력 보유
맥스가 습득한 이러한 새로운 기술을 테스트하기 위해 연구원은 장애물 추적 게임 "World Chase Tag"에서 영감을 받아 두 마리의 개 장애물 추적 게임을 디자인했습니다. 월드 체이스 태그(World Chase Tag)는 2014년 영국에서 설립된 장애물 추적 경쟁 단체입니다. 민속 어린이 추적 게임을 표준화한 것입니다. 일반적으로 장애물 추격 경기의 각 라운드에는 두 명의 선수가 서로 경쟁합니다. 한 선수는 공격자라고 하며 다른 선수는 다저(수비자라고 함)입니다. 추격 라운드(즉, 20초) 동안 상대를 성공적으로 회피하면(즉, 접촉이 발생하지 않을 때) 1점. 미리 정해진 횟수의 추격 라운드에서 가장 많은 점수를 얻은 팀이 게임에서 승리합니다.
로봇개 장애물 추적 대회의 경기장 크기는 4.5m x 4.5m이며, 그 위에 일부 장애물이 흩어져 있습니다. 게임 시작 시 MAX 로봇견 2마리가 필드 내 무작위 위치에 배치되며, 로봇견 1마리는 추적자 역할, 다른 로봇견은 회피자 역할을 무작위로 할당하는 동시에 깃발이 배치됩니다. 필드의 무작위 위치에서.
다저스의 목표는 추격자에게 잡히지 않고 깃발에 최대한 가까이 다가가는 것입니다. 추적자의 임무는 회피자를 잡는 것입니다. 다저스가 잡히기 전에 깃발에 성공적으로 닿으면 두 로봇견의 역할이 즉시 바뀌고 깃발은 다른 무작위 위치에 다시 나타납니다. 현재 추적자에게 다저가 잡히고 추적자 역할을 하는 로봇개가 승리하면 게임이 종료됩니다. 모든 게임에서 두 로봇견의 평균 전진 속도는 0.5m/s로 제한됩니다.
이 게임에서 사전 훈련된 모델을 기반으로 하는 로봇 개는 이미 심층 강화 학습을 통해 특정 추론 및 의사 결정 능력을 갖추고 있습니다.
예를 들어, 추적자가 깃발에 닿기 전에 더 이상 따라잡을 수 없다는 것을 알게 되면 추적자는 추적을 포기하고 대신 다음 재설정을 기다리기 위해 다저에게서 멀어지게 됩니다. .
또한, 추적자가 마지막 순간에 다저를 잡으려고 할 때 뛰어올라 다저를 향해 '덤벼드는' 행동을 하는 것을 좋아하는데, 이는 먹이를 잡을 때나, 다저스를 잡을 때의 동물의 행동과 매우 유사합니다. 다저도 깃발을 건드리려고 하면 같은 행동을 보일 것입니다. 이는 모두 로봇 개가 승리를 보장하기 위해 취하는 적극적인 가속 조치입니다.
보고에 따르면 게임 속 로봇 개들의 모든 제어 전략은 시뮬레이션과 제로샷 전달(Zero-Adjustment Transfer)을 통해 학습되며, 신경망이 인간의 추론 방법을 시뮬레이션하여 식별할 수 있습니다. 지금까지 본 적 없는 새로운 것을 발견하고, 이 지식을 실제 로봇개에게 적용해보세요. 예를 들어, 아래 그림과 같이 Chase Tag Game의 가상 세계에서는 장애물이 있는 장면을 훈련하지 않더라도 사전 훈련 모델에서 로봇견이 학습한 장애물 회피 지식을 게임에 활용하게 된다. 가상 세계에서만 평지에서 게임 장면을 훈련한 후 로봇 개도 작업을 성공적으로 완료할 수 있습니다.
Tencent Robotics 로봇 분야에 이를 도입하면 로봇의 제어 능력이 향상되고 유연성이 향상됩니다. 이는 또한 로봇이 실생활에 진출하여 인간에게 봉사할 수 있는 견고한 기반을 마련합니다.
위 내용은 Tencent의 로봇 개 진화: 딥 러닝을 통해 자율적 의사 결정 능력 습득의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



