

본문에 들어가기에 앞서 뮤직젠에서 생성된 음악 두 곡을 들어보겠습니다. "한 남자가 빗속을 걷다 아름다운 소녀를 만나 행복하게 춤을 춥니다"라는 텍스트 설명을 입력한 다음 Jay Chou의 "Qili Xiang" 가사 중 처음 두 줄 "참새"를 입력해 보겠습니다. 창밖 전신주 위에서 수다 떨고 계시는데, 이 문장이 여름 느낌이 난다고 하셨죠” (중국어 지원)
체험판 주소: https://huggingface.co/spaces/facebook/MusicGen
Text to Music은 주어진 텍스트의 텍스트를 "90년대 기타 리프 록 노래"와 같이 설명된 상황에서 음악 작곡으로 생성하는 작업을 의미합니다. 음악을 생성하려면 긴 시퀀스를 모델링하는 것이 어려운 작업입니다. 음성과 달리 음악은 전체 스펙트럼을 사용해야 합니다. 즉, 신호는 더 높은 속도로 샘플링됩니다. 즉, 음악 녹음의 표준 샘플링 속도는 44.1kHz 또는 48kHz인 반면 음성은 16kHz로 샘플링됩니다.
또한 음악에는 다양한 악기의 하모니와 멜로디가 포함되어 있어 음악에 복잡한 구조를 부여합니다. 그러나 인간 청취자는 불협화음에 매우 민감하기 때문에 생성된 음악의 멜로디에 대해 그다지 관용적이지 않습니다. 물론, 음악 창작자에게는 키, 악기, 멜로디, 장르 등 다양한 방식으로 생성 과정을 제어할 수 있는 능력이 필수적입니다.
자기 지도 오디오 표현 학습, 시퀀스 모델링 및 오디오 합성의 최근 발전은 이러한 모델을 개발하기 위한 조건을 제공합니다. 오디오 모델링을 더 쉽게 만들기 위해 최근 연구에서는 오디오 신호를 "동일한 신호를 나타내는" 개별 토큰의 스트림으로 나타낼 것을 제안합니다. 이를 통해 고품질 오디오 생성과 효율적인 오디오 모델링이 가능해집니다. 그러나 이를 위해서는 여러 병렬 종속성 흐름의 공동 모델링이 필요합니다.
Kharitonov et al.[2022] 및 Kreuk et al.[2022]은 여러 음성 토큰 스트림을 병렬로 모델링하기 위해 지연 방법을 사용할 것을 제안했습니다. 즉, 서로 다른 스트림 사이에 오프셋을 도입하는 것입니다. Agostinelli 등[2023]은 음악 조각을 표현하기 위해 서로 다른 세분성의 여러 개별 토큰 시퀀스를 사용하고 자동 회귀 모델의 계층 구조를 사용하여 이를 모델링할 것을 제안했습니다. 한편, Donahue et al.(2023)은 유사한 접근 방식을 채택했지만 반주 세대에 맞춰 노래하는 작업을 목표로 삼았습니다. 최근 Wang et al.[2023]은 이 문제를 두 단계로 해결하도록 제안했습니다. 즉, 모델링을 첫 번째 토큰 스트림으로 제한합니다. 그런 다음 사후 네트워크를 적용하여 자동 회귀가 아닌 방식으로 나머지 흐름을 공동으로 모델링합니다.
이 기사에서 Meta AI의 연구원들은 텍스트 설명을 통해 고품질 음악을 생성할 수 있는 간단하고 제어 가능한 음악 생성 모델인 MUSICGEN을 제안합니다.

논문 주소: https://arxiv.org/pdf/2306.05284.pdf
연구원은 다중 병렬 음향 토큰 스트림을 모델링하는 방법을 제안합니다. 일반 프레임워크는 이전 연구의 요약 역할을 합니다(아래 그림 1 참조). 생성된 샘플의 제어 가능성을 향상시키기 위해 이 논문에서는 비지도 멜로디 조건을 도입하여 모델이 주어진 하모니와 멜로디를 기반으로 구조적으로 일치하는 음악을 생성할 수 있도록 합니다. 본 논문에서는 MUSICGEN에 대한 광범위한 평가를 수행했으며, 제안된 방법은 평가 기준선보다 큰 차이로 성능이 뛰어납니다. MUSICGEN은 100점 만점에 84.8점의 주관적 점수를 얻었으며, 최고 기준선은 80.5점을 받았습니다. 또한 이 기사에서는 전체 모델 성능에 대한 각 구성 요소의 중요성을 설명하는 절제 연구를 제공합니다.
마지막으로 인간의 평가에 따르면 MUSICGEN은 텍스트 설명을 준수하고 주어진 하모니 구조와 멜로디적으로 더 잘 정렬되는 고품질 샘플을 생성합니다.
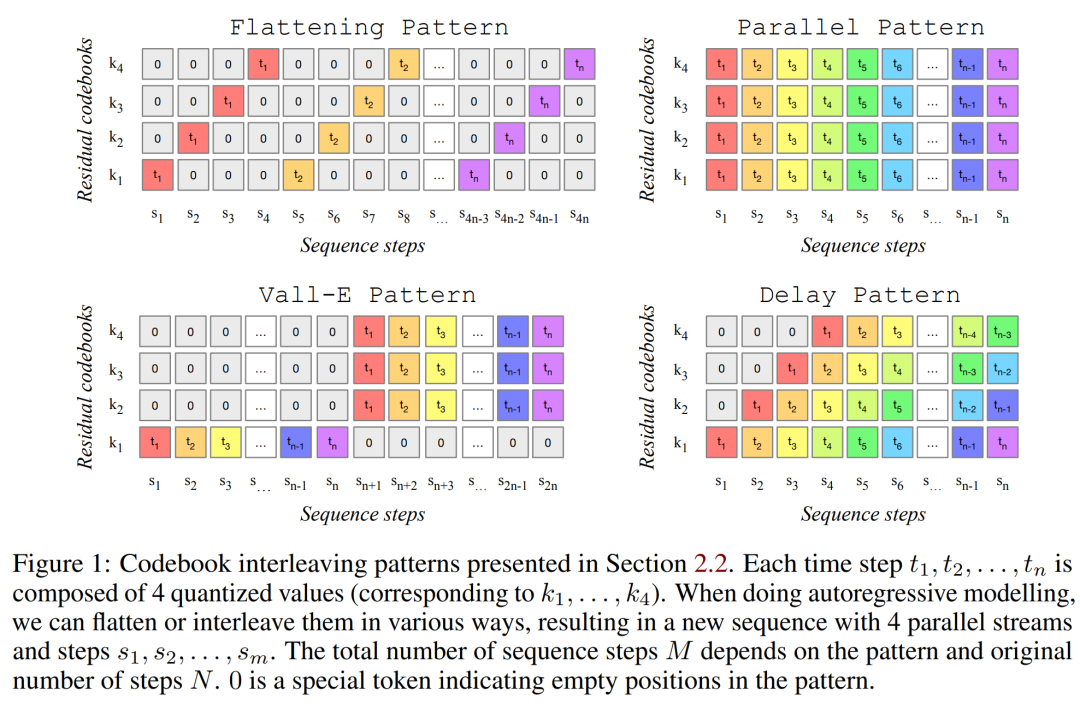
MUSICGEN에는 텍스트 또는 멜로디 표현에 따른 자동 회귀 변환기 기반 디코더가 포함되어 있습니다. (언어) 모델은 낮은 프레임의 이산 표현에서 충실도 높은 재구성을 제공하는 EnCodec 오디오 토크나이저의 양자화 단위를 기반으로 합니다. 또한 RVQ(잔차 벡터 양자화)를 배포하는 압축 모델은 여러 병렬 스트림을 생성합니다. 이 설정에서 각 스트림은 서로 다른 학습된 코드북의 개별 토큰으로 구성됩니다.
이전 작업에서는 이 문제를 해결하기 위해 몇 가지 모델링 전략을 제안했습니다. 연구원들은 다양한 코드북 인터리빙 모드로 일반화될 수 있는 새로운 모델링 프레임워크를 제안했습니다. 이 프레임워크에는 여러 가지 변형도 있습니다. 패턴을 기반으로 양자화된 오디오 토큰의 내부 구조를 활용할 수 있습니다. 마지막으로 MUSICGEN은 텍스트나 멜로디를 기반으로 한 조건부 생성을 지원합니다.
오디오 토큰화
연구원들은 RVQ 양자화 및 적대적 재구성 손실을 사용하는 잠재 공간이 있는 컨볼루셔널 오토인코더인 EnCodec을 사용했습니다. 참조 오디오 랜덤 변수 X ∈ R^d·f_s가 주어지면 d는 오디오 지속 시간을 나타내고 f_s는 샘플링 속도를 나타냅니다. EnCodec은 이 변수를 프레임 속도 f_r `` f_s로 연속 텐서로 인코딩한 다음 표현을 Q ∈ {1, , N}^K×d・f_r로 양자화합니다. 여기서 K는 RVQ Quantity에 사용되는 코드북을 나타냅니다. N은 코드북 크기를 나타낸다.
코드북 인터리브 모드
정확한 평면화된 자동 회귀 분해. 자기회귀 모델에는 이산 무작위 시퀀스 U ∈ {1, , N}^S 및 시퀀스 길이 S가 필요합니다. 관례적으로 연구자들은 시퀀스의 시작을 나타내는 결정론적 특수 토큰인 U_0 = 0을 사용합니다. 그런 다음 분포를 모델링할 수 있습니다.
부정확한 자기회귀 분해. 또 다른 가능성은 일부 코드북이 병렬 예측을 요구하는 자동회귀 분해를 고려하는 것입니다. 예를 들어, 다른 시퀀스 V_0 = 0, t∈ {1, . , K}, V_t,k = Q_t,k를 정의합니다. 코드북 인덱스 k가 제거되면(예: V_t) 이는 시간 t에서 모든 코드북의 연결을 나타냅니다.
모든 코드북 인터리빙 모드. 이러한 분해를 실험하고 부정확한 분해 사용의 영향을 정확하게 측정하기 위해 연구원들은 코드북 인터리빙 모드를 도입했습니다. 먼저 모든 시간 단계와 코드북 인덱스 쌍인 Ω = {(t, k) : {1, . , d・f_r}, k ∈ {1, . . 코드북 패턴은 시퀀스 P=(P_0, P_1, P_2,… P_0, P_1, P_T의 모든 위치를 조건으로 P_t의 모든 위치를 병렬로 예측하여 Q를 모델링합니다. 동시에 실제 효율성을 고려하여 "각 코드북은 모든 P_s에 최대 한 번 표시되는" 모드만 선택했습니다.
모델 조건화
텍스트 조건화. 입력 오디오와 일치하는 텍스트 설명이 제공됩니다.
멜로디 조절. 오늘날 조건부 생성 모델에 대한 지배적인 접근 방식은 텍스트이지만, 음악에 대한 보다 자연스러운 접근 방식은 다른 오디오 트랙이나 심지어 휘파람이나 윙윙거리는 소리의 멜로디 구조를 조건으로 하는 것입니다. 이 접근 방식을 사용하면 모델 출력을 반복적으로 최적화할 수도 있습니다. 이를 지원하기 위해 우리는 입력 크로마토그램과 텍스트 설명을 공동으로 변조하여 멜로디 구조를 제어하려고 시도했습니다. 초기 실험에서 그들은 원래 크로마토그램에 대한 컨디셔닝이 종종 원래 샘플을 재구성하여 과적합으로 이어지는 것을 관찰했습니다. 이를 위해 연구자들은 각 시간 단계에서 주요 시간-주파수 빈을 선택하여 정보 병목 현상을 도입합니다.
모델 아키텍처
코드북 투영 및 위치 임베딩. 코드북 패턴이 주어지면 각 패턴 단계 P_s에는 일부 코드북만 존재합니다. 연구자는 P_s의 인덱스에 해당하는 Q에서 값을 검색합니다. 각 코드북은 P_s에 최대 한 번 나타나거나 전혀 나타나지 않습니다.
변압기 디코더. 입력은 L 레이어와 D 차원의 변환기로 공급되며, 각 레이어는 원인이 되는 self-attention 블록으로 구성됩니다. 그런 다음 조정 신호 C에 의해 제공되는 교차 주의 블록이 사용됩니다. 멜로디 조건화를 사용할 때 연구원은 조건부 텐서 C를 변환기 입력 앞에 붙입니다.
로지트 예측. 패턴 단계 P_s에서 변환기 디코더의 출력은 Q 값의 로지트 예측으로 변환됩니다. 각 코드북은 P_s+1에 최대 한 번 나타납니다. 코드북이 존재하는 경우 D 채널부터 N 채널까지 코드북 특정 선형 레이어를 적용하여 로지트 예측을 얻습니다.
오디오 토큰화 모델. 이 연구에서는 스트라이드 640, 프레임 속도 50Hz, 모델의 5개 레이어 각각에서 두 배로 증가한 초기 숨겨진 크기 64를 갖춘 32kHz 모노 오디오용 비인과적 5계층 EnCodec 모델을 사용합니다. .
Transformer 모델, 다양한 크기(300M, 1.5B, 3.3B 매개변수)의 자동 회귀 Transformer 모델을 연구하고 훈련했습니다.
훈련 데이터 세트. MUSICGEN을 훈련시키기 위해 20,000시간의 라이선스 음악을 사용하여 공부하세요. 세부적으로, 이 연구에서는 10K 고품질 트랙이 포함된 내부 데이터세트와 각각 25K 및 365K 악기 전용 트랙이 포함된 ShutterStock 및 Pond5 음악 데이터세트를 사용했습니다.
평가 데이터세트. 이 연구에서는 제안된 방법을 MusicCaps 벤치마크에서 평가하고 이전 연구와 비교합니다. MusicCaps는 전문 뮤지션들이 준비한 5.5K 샘플(10초 길이)과 장르 전반에 걸쳐 균형 잡힌 1K 하위 세트로 구성됩니다.
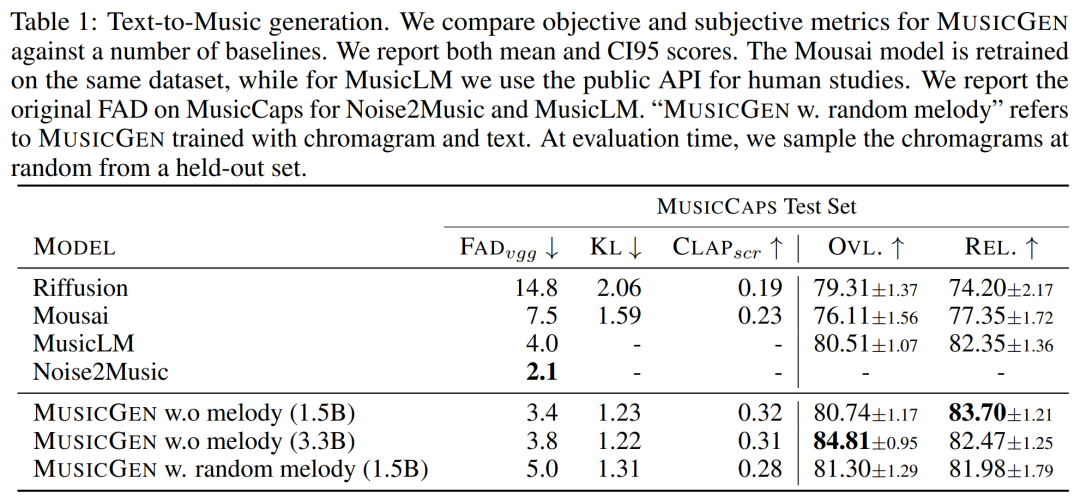
아래 표 1은 제안된 방법을 Mousai, Riffusion, MusicLM 및 Noise2Music과 비교한 것입니다. 결과는 MUSICGEN이 오디오 품질 및 제공된 텍스트 설명과의 일관성 측면에서 인간 청취자가 평가한 기준을 능가한다는 것을 보여줍니다. Noise2Music은 MusicCaps의 FAD에서 가장 잘 수행되며 그 다음은 텍스트 조건으로 훈련된 MUSICGEN입니다. 흥미롭게도 멜로디 조건을 추가하면 객관적 지표가 저하되었지만 사람의 평가에는 큰 영향을 미치지 않았으며 평가된 기준선보다 여전히 더 좋았습니다.
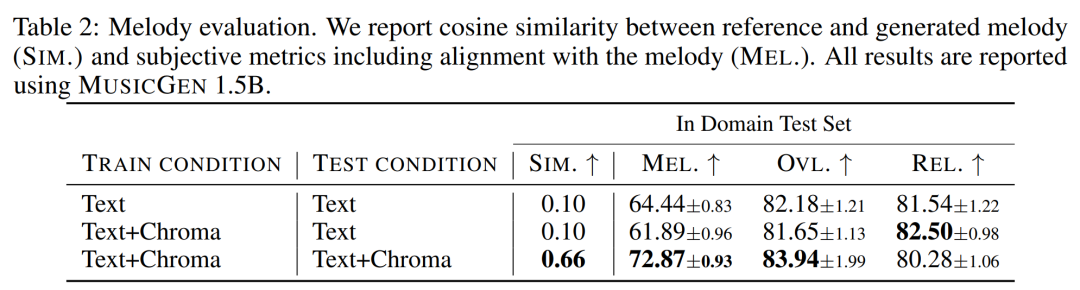
연구원들은 주어진 평가 세트에 대해 객관적이고 주관적인 척도를 사용하여 텍스트 및 멜로디 표현의 공통 조건에서 MUSICGEN을 평가했습니다. 결과는 아래 표 2와 같습니다. 결과는 크로마토그램 조건화로 훈련된 MUSICGEN이 주어진 멜로디를 따르는 음악을 성공적으로 생성하여 생성된 출력을 더 잘 제어할 수 있음을 보여줍니다. MUSICGEN은 OVL 및 REL을 사용하여 추론 시 채도를 떨어뜨리는 데 강력합니다.
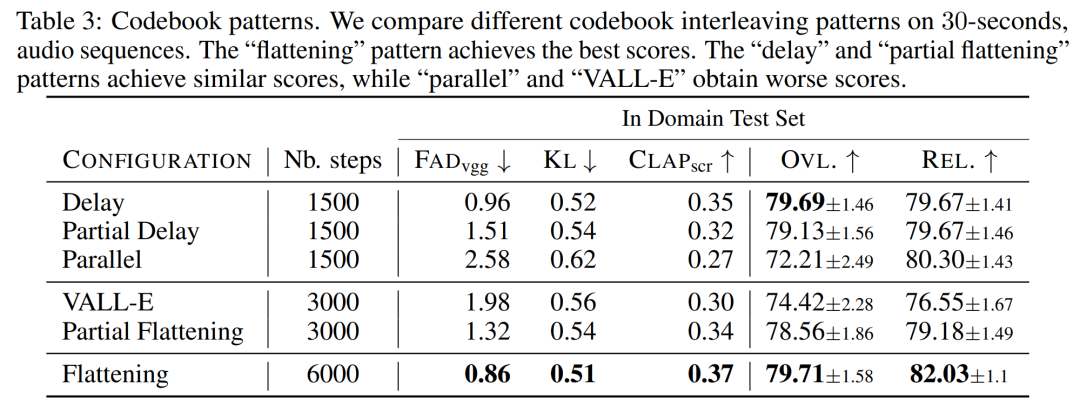
코드북 인터리빙 모드의 영향. 우리는 오디오 토큰화 모델에 의해 제공된 섹션 2.2, K = 4의 프레임워크를 사용하여 다양한 코드북 패턴을 평가했습니다. 본 기사는 아래 표 3에 객관적인 평가와 주관적인 평가를 보고하고 있습니다. 평탄화는 생성을 향상시키지만 계산 비용이 많이 듭니다. 간단한 연기 방법을 사용하면 적은 비용으로 비슷한 성능을 얻을 수 있습니다.
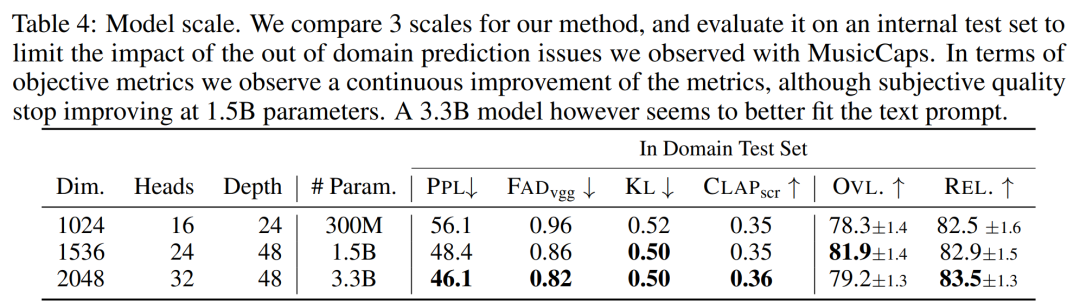
모델 사이즈의 영향. 아래 표 4는 다양한 모델 크기, 즉 300M, 1.5B 및 3.3B 매개변수 모델에 대한 결과를 보고합니다. 예상한 대로 모델 크기를 확장하면 점수가 더 좋아지지만 훈련 및 추론 시간이 길어집니다. 주관적인 평가로 볼 때 전반적인 품질은 1.5B에서 최적이지만 더 큰 모델은 텍스트 프롬프트를 더 잘 이해할 수 있습니다.
위 내용은 메타 오픈소스 텍스트는 'Qilixiang'의 가사로 큰 음악 모델을 생성해 보았습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



