

얼마 전 Meta는 이미지나 비디오의 모든 객체에 대해 마스크를 생성할 수 있는 "SAM(Segment Everything)" AI 모델을 출시했고, 이로 인해 컴퓨터 비전(CV) 분야의 연구자들은 "CV는 그렇지 않습니다. 더 이상 존재합니다." 이후 이력서 분야에서는 '2차 창작'의 물결이 일었다. 분할을 기반으로 타겟 탐지, 이미지 생성 등의 기능을 순차적으로 결합한 작품도 있지만 대부분의 연구는 정적 이미지를 기반으로 했다.
이제 "Tracking Everything"이라는 새로운 연구에서는 물체의 움직임 궤적을 정확하고 완전하게 추적할 수 있는 동적 영상의 움직임 추정을 위한 새로운 방법을 제안합니다.

이 연구는 코넬 대학교, Google Research 및 UC Berkeley의 연구원들이 수행했습니다. 그들은 완전하고 전체적으로 일관된 모션 표현인 OmniMotion을 공동으로 제안했으며, 비디오의 모든 픽셀에 대해 정확하고 완전한 모션 추정을 수행하기 위한 새로운 테스트 시간 최적화 방법을 제안했습니다.

일부 네티즌들은 이 연구를 트위터에 올렸고, 단 하루 만에 3,500개 이상의 좋아요를 받았습니다. 연구 내용은 호평을 받았습니다.

연구에서 공개한 데모에 따르면 점프하는 캥거루의 동작 궤적을 추적하는 등 동작 추적 효과가 매우 좋습니다. 스윙:

동작 추적 상태를 대화식으로 볼 수도 있습니다.

개가 막는 등 물체가 막힌 경우에도 동작 궤적을 추적할 수 있습니다. 달리는 동안 나무:

컴퓨터 비전 분야에는 희소 특징 추적과 조밀한 광학 흐름이라는 두 가지 일반적으로 사용되는 동작 추정 방법이 있습니다. 그러나 두 방법 모두 고유한 단점이 있습니다. 희소 특징 추적은 모든 픽셀의 동작을 모델링할 수 없으며, 조밀한 광학 흐름은 오랫동안 동작 궤적을 캡처할 수 없습니다.
 본 연구에서 제안한 OmniMotion은 준3D 표준 볼륨을 사용하여 비디오를 표현하고 로컬 공간과 표준 공간 간의 전단사를 통해 각 픽셀을 추적합니다. 이 표현은 전역적 일관성을 가능하게 하고, 객체가 가려진 경우에도 동작 추적을 가능하게 하며, 카메라와 객체 동작의 모든 조합을 모델링합니다. 본 연구에서는 제안한 방법이 기존 SOTA 방법보다 훨씬 뛰어난 성능을 보인다는 것을 실험적으로 입증하였다.
본 연구에서 제안한 OmniMotion은 준3D 표준 볼륨을 사용하여 비디오를 표현하고 로컬 공간과 표준 공간 간의 전단사를 통해 각 픽셀을 추적합니다. 이 표현은 전역적 일관성을 가능하게 하고, 객체가 가려진 경우에도 동작 추적을 가능하게 하며, 카메라와 객체 동작의 모든 조합을 모델링합니다. 본 연구에서는 제안한 방법이 기존 SOTA 방법보다 훨씬 뛰어난 성능을 보인다는 것을 실험적으로 입증하였다.
이 연구에서는 전체 비디오의 완전하고 전 세계적으로 일관된 모션 표현을 형성하기 위해 쌍을 이루는 잡음 모션 추정(예: 광학 흐름 필드)이 있는 프레임 모음을 입력으로 사용합니다. 그런 다음 연구에서는 비디오 전체에서 부드럽고 정확한 모션 궤적을 생성하기 위해 모든 프레임의 모든 픽셀로 표현을 쿼리할 수 있는 최적화 프로세스를 추가했습니다. 특히, 이 방법은 프레임의 포인트가 언제 가려지는지 식별할 수 있으며, 가려진 지점을 추적할 수도 있습니다.
OmniMotion Characterization
기존 모션 추정 방법(예: 쌍별 광학 흐름)은 객체가 가려지면 객체 추적을 잃게 됩니다. 교합 상태에서도 정확하고 일관된 모션 궤적을 제공하기 위해 본 연구에서는 전역 모션 표현 OmniMotion을 제안합니다.
이 연구는 명시적인 동적 3D 재구성 없이 실제 동작을 정확하게 추적하려고 시도합니다. OmniMotion 표현은 비디오의 장면을 표준 3D 볼륨으로 표현하며, 이는 로컬-표준 전단사를 통해 각 프레임의 로컬 볼륨에 매핑됩니다. 로컬 표준 전단사는 신경망으로 매개변수화되며 둘을 분리하지 않고 카메라와 장면 모션을 캡처합니다. 이 접근 방식을 기반으로 비디오는 고정된 정적 카메라의 로컬 볼륨에서 렌더링된 결과로 볼 수 있습니다.
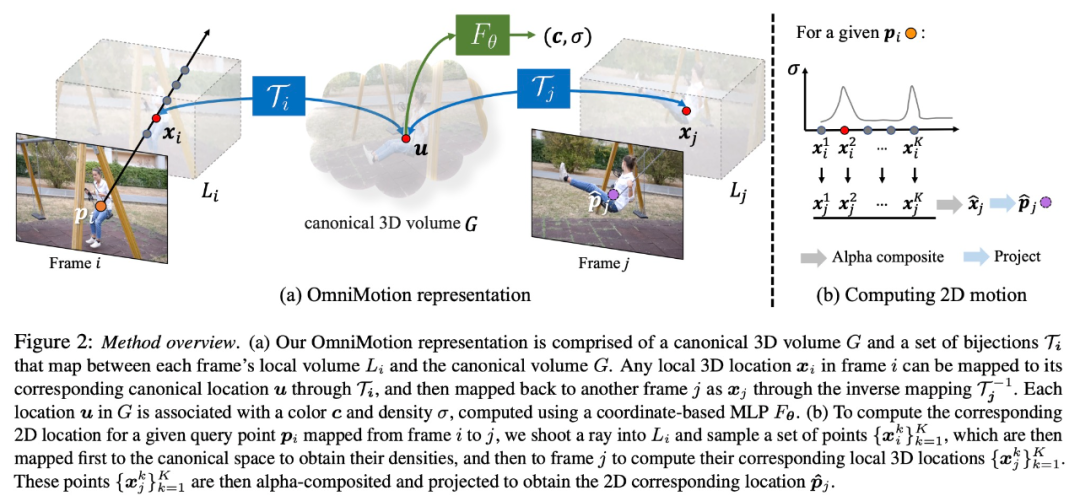
OmniMotion은 카메라 모션과 장면 모션을 명확하게 구분하지 않기 때문에 형성된 표현은 물리적으로 정확한 3D 장면 재구성이 아닙니다. 따라서 본 연구에서는 이를 준3D 특성화라고 부릅니다.
OmniMotion은 각 픽셀에 투영된 모든 장면 지점에 대한 정보와 상대 깊이 순서를 유지하므로 일시적으로 가려진 경우에도 프레임의 지점을 추적할 수 있습니다.

정량적 비교
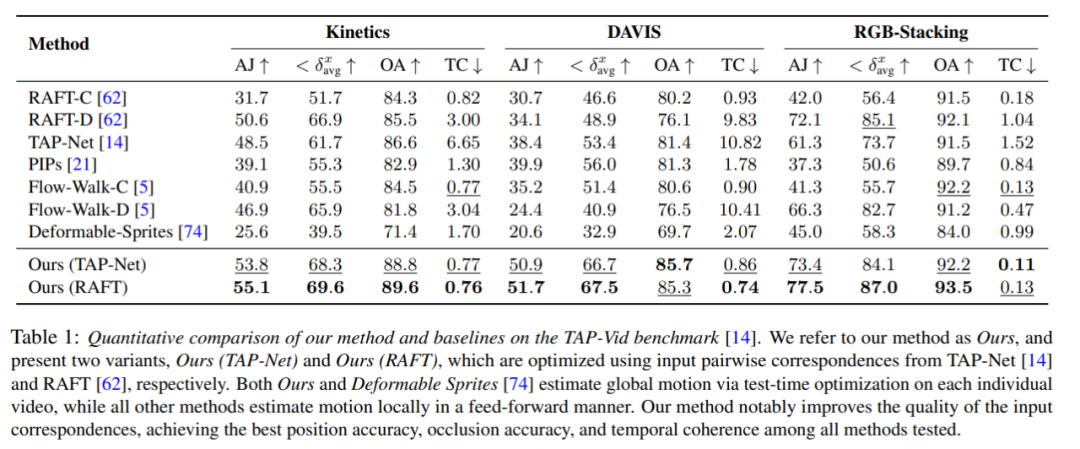
연구원들은 제안한 방법과 TAP-Vid 벤치마크를 비교하였고 그 결과를 Table 1에 나타내었다. 그들의 방법은 다양한 데이터 세트에서 최고의 위치 정확도, 폐색 정확도 및 타이밍 일관성을 일관되게 달성한다는 것을 알 수 있습니다. 그들의 방법은 RAFT 및 TAP-Net의 다양한 쌍별 대응 입력을 잘 처리하고 두 기본 방법에 비해 일관된 개선을 제공합니다.
정성적 비교
그림 3에서 볼 수 있듯이 연구원들은 자신의 방법과 기준 방법을 정성적으로 비교했습니다. 새로운 방법은 (긴) 폐색 이벤트 동안 탁월한 인식 및 추적 기능을 보여주며, 폐색 중 포인트에 대한 합리적인 위치를 제공하고 대규모 카메라 모션 시차를 처리합니다.

절제 실험 및 분석
연구원들은 절제 실험을 사용하여 설계 결정의 효율성을 검증했으며 결과는 표 2에 나와 있습니다.
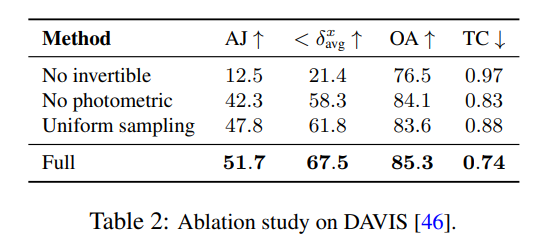
그림 4에서는 학습된 깊이 순위를 보여주기 위해 모델에서 생성된 의사 깊이 맵을 보여줍니다.

이 수치는 물리적 깊이와 일치하지 않지만 광도 측정 및 광학 흐름 신호만을 사용하여 서로 다른 표면 간의 상대적 순서를 효과적으로 결정하는 새로운 방법의 능력을 보여 주며 이는 중요한 폐색 추적에 유용합니다. 더 많은 절제 실험과 분석 결과는 보충 자료에서 확인할 수 있습니다.
위 내용은 언제 어디서나 모든 픽셀을 추적하고, 장애물도 두려워하지 않는 '모든 것을 추적하는' 비디오 알고리즘이 여기에 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



