

Transformer 아키텍처는 자연어 처리, 컴퓨터 비전, 음성, 다중 양식 등 다양한 분야를 휩쓸었습니다. 그러나 현재 실험 결과는 매우 인상적이며 Transformer의 작동 원리에 대한 관련 연구는 여전히 매우 제한적입니다. .
가장 큰 미스터리는 Transformer가 "단순 예측 손실"에만 의존하여 경사 훈련 역학에서 효율적인 표현을 도출할 수 있는 이유입니다.
최근 Tian Yuandong 박사는 수학적으로 엄격한 방식으로 1계층 Transformer(Self-Attention 계층과 디코더 계층)의 SGD 훈련 역학을 분석한 팀의 최신 연구 결과를 발표했습니다. 다음 토큰 예측 작업.

문서 링크: https://arxiv.org/abs/2305.16380
이 문서는 self-attention 레이어가 입력 토큰의 동적 프로세스를 결합하는 방법에 대한 블랙박스를 엽니다. 잠재적인 귀납적 편향의 본질을 드러냅니다.
구체적으로 위치 인코딩이 없고 긴 입력 시퀀스가 있으며 디코더 레이어가 self-attention 레이어보다 빠르게 학습한다는 가정 하에서 연구원들은 self-attention이 차별적 스캐닝 알고리즘 알고리즘임을 증명했습니다.
균등한 관심에서 시작하여 특정 다음 토큰을 예측하기 위해 모델은 점차적으로 다른 키 토큰에 초점을 맞추고 여러 다음 토큰 창에 나타나는 토큰에는 덜 주의를 기울입니다. 공통 토큰
다른 토큰의 경우, 모델은 훈련 세트의 키 토큰과 쿼리 토큰 간의 동시 발생 빈도가 낮은 순서에서 높은 순서에 따라 점차적으로 주의 가중치를 줄입니다.
흥미롭게도 이 프로세스는 승자 독식으로 이어지지는 않지만 2계층 학습 속도에 의해 제어되는 단계 전환으로 인해 속도가 느려지고 최종적으로 두 합성 모두에서 (거의) 고정 토큰 조합이 됩니다. 실제 데이터 이 역학도 검증되었습니다.
Tian Yuandong 박사는 메타 인공 지능 연구소의 연구원이자 연구 관리자이며 Go AI 프로젝트의 리더입니다. 그의 연구 방향은 심층 강화 학습과 게임에서의 응용, 심층 강화 학습입니다. 학습 모델. 그는 2005년과 2008년 상하이자오퉁대학교에서 학사 및 석사학위를 취득했고, 2013년에는 미국 카네기멜론대학교 로봇공학연구소에서 박사학위를 취득했다.
2013 International Conference on Computer Vision (ICCV) Marr Prize Honorable Mentions (Marr Prize Honorable Mentions) 및 ICML2021 Outstanding Paper Honorable Mention Award를 수상했습니다.
박사 학위를 졸업한 후, 연구 방향 선택, 박사 과정에 대한 생각과 경험을 정리한 "박사 학위 5년 요약" 시리즈를 출판했습니다. 독서 축적, 시간 관리, 업무 태도, 소득 및 지속 가능한 경력 개발.
Transformer 아키텍처를 기반으로 한 사전 학습 모델에는 일반적으로 다음 단어 예측, 빈칸 채우기 등과 같은 매우 간단한 감독 작업만 포함되지만 매우 풍부한 기능을 제공할 수 있습니다. 정말 인상적인 다운스트림 작업에 대한 표현입니다.
이전 연구에서는 Transformer가 본질적으로 보편적 근사기라는 것이 입증되었지만 kNN, 커널 SVM, 다층 퍼셉트론 등과 같이 이전에 일반적으로 사용되는 기계 학습 모델은 실제로 보편적 근사기입니다. 이 이론으로는 설명할 수 없습니다. 이 두 가지 유형의 모델 사이에는 성능 차이가 큽니다.
연구원들은 Transformer의 훈련 역학, 즉 훈련 과정에서 학습 가능한 매개변수가 시간에 따라 어떻게 변하는지 이해하는 것이 중요하다고 믿습니다.
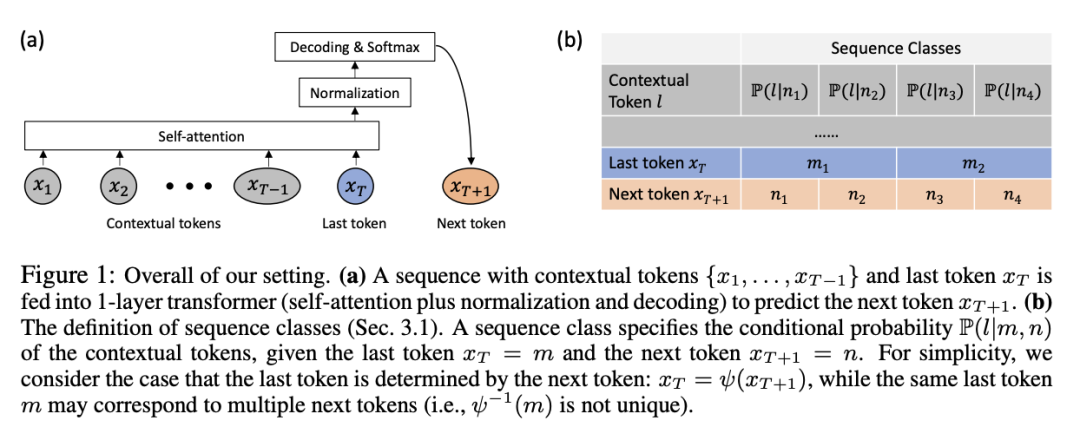
이 기사에서는 먼저 엄격한 수학적 정의를 사용하여 다음 토큰 예측(GPT 시리즈 모델에 일반적으로 사용되는 교육 패러다임)에 대한 위치 없는 코딩 Transformer 레이어를 사용하여 SGD의 교육 역학을 공식적으로 설명합니다.
레이어 1의 Transformer에는 Softmax self-attention 레이어와 다음 토큰을 예측하는 디코더 레이어가 포함되어 있습니다.
시퀀스가 길고 디코더가 self-attention 계층보다 빠르게 학습한다는 가정하에 훈련 중 self-attention의 동적 동작이 시연됩니다.
1. Bias
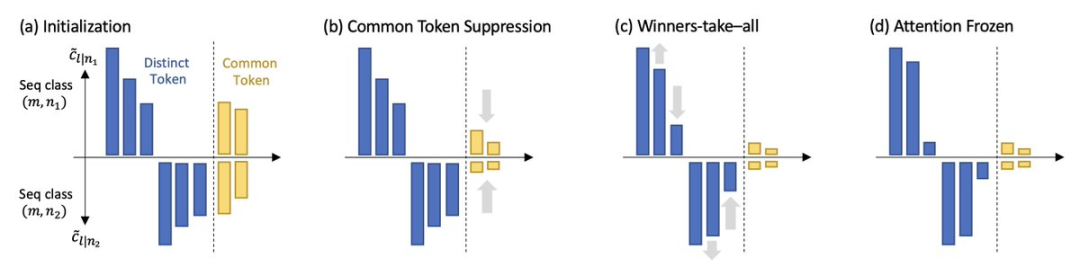
모델은 쿼리 토큰과 함께 많이 발생하는 키 토큰에 점차적으로 주의를 기울이고, 동시에 발생하는 토큰이 적은 토큰에는 주의를 기울입니다.
2. 차별적 편향
모델은 예측할 다음 토큰에만 나타나는 고유 토큰에 더 많은 관심을 기울이고 여러 다음 토큰 관심에 나타나는 공통 토큰에는 잃습니다.
이 두 가지 특성은 self-attention이 암묵적으로 차별적 스캐닝 알고리즘을 실행하고 귀납적 편향을 가지고 있음을 나타냅니다. 즉, 쿼리 토큰과 함께 자주 나타나는 고유한 기능에 편향됩니다.
비록 self-attention 레이어가 훈련 중에 더 희박해지는 경향이 있지만, 주파수 편차에서 알 수 있듯이 모델은 훈련 역학의 위상 전환으로 인해 붕괴되지 않습니다.

학습의 마지막 단계는 기울기가 0인 안장점으로 수렴되지 않고 주의가 천천히(예: 시간이 지남에 따라 대수적으로) 변화하고 매개변수가 동결되고 학습되는 영역으로 들어갑니다.
연구 결과는 단계 전환의 시작이 학습 속도에 의해 제어된다는 것을 추가로 보여줍니다. 학습 속도가 크면 희박한 주의 패턴이 생성되는 반면, 고정된 self-attention 학습 속도에서는 큰 디코더 학습 속도가 생성됩니다. 더 빠른 단계 전환과 집중적인 주의 패턴.
연구원들은 작업 스캔 및 스냅에서 발견한 SGD 역학을 다음과 같이 명명했습니다.
스캔 단계: Self-attention은 핵심 토큰, 즉 다르며 종종 다음 예측 토큰과 관련되는 토큰에 중점을 둡니다. 동시에 나타나면 다른 모든 토큰은 주의를 잃습니다.
스냅 단계: 주의가 거의 정지되었으며, 토큰 조합이 고정되었습니다.

이 현상은 간단한 실제 데이터 실험에서도 확인되었습니다. SGD를 사용하여 WikiText에서 훈련된 1계층 및 3계층 변환기의 가장 낮은 self-attention 계층을 관찰하면 다음과 같습니다. 학습 속도는 훈련 전반에 걸쳐 일정하게 유지되며 훈련 중 특정 시점에 주의가 멈추고 희박해진다는 사실을 발견했습니다.
위 내용은 Tian Yuandong의 신작: Transformer 블랙박스의 첫 번째 레이어를 열면 주의 메커니즘이 그리 신비롭지 않습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



