

 кё°мҲ мЈјліҖкё°кё°
мқјмІҙ нҸ¬н•Ё
Fudan, 'лүҙмҠӨ 추мІң мғқнғңкі„ мӢң뮬л Ҳмқҙн„°' SimuLine м¶ңмӢң: лӢЁмқј мӢңмҠӨн…ңмңјлЎң лҸ…мһҗ 10,000лӘ…, мһ‘м„ұмһҗ 1,000лӘ…, 추мІң 100нҡҢ мқҙмғҒ м§Җмӣҗ
кё°мҲ мЈјліҖкё°кё°
мқјмІҙ нҸ¬н•Ё
Fudan, 'лүҙмҠӨ 추мІң мғқнғңкі„ мӢң뮬л Ҳмқҙн„°' SimuLine м¶ңмӢң: лӢЁмқј мӢңмҠӨн…ңмңјлЎң лҸ…мһҗ 10,000лӘ…, мһ‘м„ұмһҗ 1,000лӘ…, 추мІң 100нҡҢ мқҙмғҒ м§Җмӣҗ
Fudan, 'лүҙмҠӨ 추мІң мғқнғңкі„ мӢң뮬л Ҳмқҙн„°' SimuLine м¶ңмӢң: лӢЁмқј мӢңмҠӨн…ңмңјлЎң лҸ…мһҗ 10,000лӘ…, мһ‘м„ұмһҗ 1,000лӘ…, 추мІң 100нҡҢ мқҙмғҒ м§Җмӣҗ

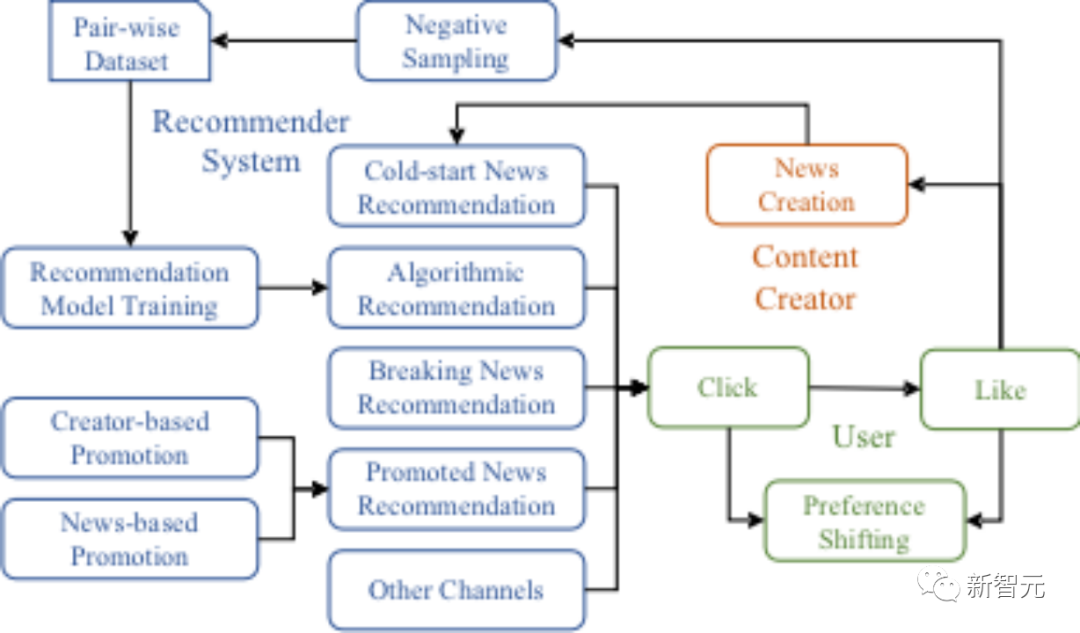
лҚ” нҡЁкіјм Ғмқё лүҙмҠӨ 추мІң мӢңмҠӨн…ңмқ„ м„Өкі„н•ҳл Өл©ҙ мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°мқҳ 진нҷ”лҘј мқҙн•ҙн•ҳлҠ” кІғмқҙ мӨ‘мҡ”н•ҳм§Җл§Ң, м Ғм Ҳн•ң лҚ°мқҙн„° м„ёнҠёмҷҖ н”Ңлһ«нҸјмқҙ л¶ҖмЎұн•ҳм—¬ 추мІң мӢңмҠӨн…ңмқҙ м»Өл®ӨлӢҲнӢ° 진нҷ”м—җ м–ҙл–»кІҢ мҳҒн–Ҙмқ„ лҜём№ҳлҠ”м§Җ мқҙн•ҙн•ҳлҠ” лҚ° кё°мЎҙ м—°кө¬лҠ” м ңн•ңлҗҳм–ҙ мһҲмңјл©°, мқҙлЎң мқён•ҙ мһҘкё°к°„м—җ кұём№ң л¬ём ңк°Җ л°ңмғқн• мҲҳ мһҲмҠөлӢҲлӢӨ. мҡ©м–ҙ кІ°кіј мң нӢёлҰ¬нӢ°м—җ лҢҖн•ң м°Ём„ мұ… мӢңмҠӨн…ң м„Өкі„.
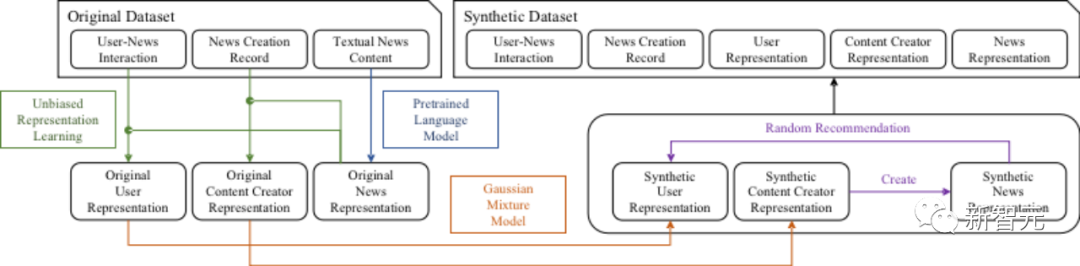
мқҙ л¬ём ңм—җ лҢҖмқ‘н•ҳкё° мң„н•ҙ н‘ёлӢЁлҢҖн•ҷкөҗ м»ҙн“Ён„°кіөн•ҷл¶Җ CISL м—°кө¬нҢҖмқҖ лүҙмҠӨ 추мІң мғқнғңкі„ 진нҷ” мӢң뮬л Ҳмқҙм…ҳ н”Ңлһ«нҸјмқё SimuLineмқ„ к°ңл°ңн–ҲмҠөлӢҲлӢӨ.
SimuLineмқҖ мӮ¬м „ нӣҲл Ёлҗң м–ём–ҙ лӘЁлҚёкіј м—ӯм„ұн–Ҙм җмҲҳлҘј кё°л°ҳмңјлЎң мӢӨм ң лҚ°мқҙн„°лЎңл¶Җн„° мқёк°„ н–үлҸҷмқ„ л°ҳмҳҒн•ҳлҠ” мһ мһ¬ кіөк°„мқ„ кө¬м¶•н•ң нӣ„ м—җмқҙм „нҠё кё°л°ҳ лӘЁлҚёл§Ғмқ„ мӮ¬мҡ©н•ҳм—¬ лүҙмҠӨ 추мІң мғқнғңкі„мқҳ 진нҷ” м—ӯн•ҷмқ„ мӢң뮬л Ҳмқҙм…ҳн•©лӢҲлӢӨ.
SimuLineмқҖ лӢЁмқј м„ңлІ„(256G л©”лӘЁлҰ¬, мҶҢ비мһҗкёү к·ёлһҳн”Ҫ м№ҙл“ң)м—җм„ң 10,000лӘ… мқҙмғҒмқҳ лҸ…мһҗмҷҖ 1,000лӘ… мқҙмғҒмқҳ м ңмһ‘мһҗлҘј лҢҖмғҒмңјлЎң 100нҡҢ мқҙмғҒмқҳ мғқм„ұ-추мІң-мғҒнҳёмһ‘мҡ© мӢң뮬л Ҳмқҙм…ҳмқ„ м§Җмӣҗн•ҳлҠ” лҸҷмӢңм—җ м •лҹүм Ғ м§Җн‘ң, мӢңк°Ғнҷ” л°Ҹ нҸ¬кҙ„м Ғмқё 분м„қ н”„л Ҳмһ„мӣҢнҒ¬лҘј м ңкіөн•©лӢҲлӢӨ. м—¬кё°м—җлҠ” н…ҚмҠӨнҠё н•ҙм„қмқҙ нҸ¬н•Ёлҗ©лӢҲлӢӨ.
кҙ‘лІ”мң„н•ң мӢң뮬л Ҳмқҙм…ҳ мӢӨн—ҳмқ„ нҶөн•ҙ SimuLineмқҖ м»Өл®ӨлӢҲнӢ° 진нҷ” н”„лЎңм„ёмҠӨлҘј мқҙн•ҙн•ҳкі м¶”мІң м•Ңкі лҰ¬мҰҳмқ„ н…ҢмҠӨнҠён•ҳлҠ” лҚ° нҒ° мһ мһ¬л Ҙмқ„ к°Җм§Җкі мһҲмқҢмқҙ лӮҳнғҖлӮ¬мҠөлӢҲлӢӨ.

м Җмһҗ: Zhang Guangping, Li Dongsheng, Gu Hansu, Lu Xun, Shang Li, Gu Ning
л…јл¬ё мЈјмҶҢ: https://arxiv.org/abs/2305.14103
лүҙмҠӨ 추мІң мғқнғңкі„ 진нҷ” мӢң뮬л Ҳмқҙм…ҳ н”Ңлһ«нҸј
мҶҢм…ң лҜёл””м–ҙ(Social Media)мқҳ мқёкё°лЎң мқён•ҙ мӮ¬лһҢл“ӨмқҖ лүҙмҠӨлҘј кІҢмӢңн•ҳкі м–»кё° мң„н•ҙ м җм җ лҚ” мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°м—җ мқҳмЎҙн•ҳкі мһҲмҠөлӢҲлӢӨ. л§Өмқј мҲҳл°ұл§Ң к°ңмқҳ лүҙмҠӨк°Җ мғқм„ұлҗ©лӢҲлӢӨ. м ҖмһҗлҠ” лӢӨм–‘н•ң мң нҳ•мқҳ мҳЁлқјмқём—җ кІҢмӢңн•©лӢҲлӢӨ. лүҙмҠӨ м»Өл®ӨлӢҲнӢ°лҠ” 추мІң мӢңмҠӨн…ңмқҳ л°°нҸ¬лҘј нҶөн•ҙ л§ҺмқҖ мӮ¬мҡ©мһҗк°Җ мқҪмҠөлӢҲлӢӨ.
лүҙмҠӨ мҪҳн…җмё мқҳ мғқмӮ°кіј мҶҢ비мҷҖ н•Ёк»ҳ мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°лҠ” м§ҖмҶҚм ҒмңјлЎң м—ӯлҸҷм Ғмқё 진нҷ” кіјм •мқ„ кұ°м№ҳкі мһҲмҠөлӢҲлӢӨ.
лӢӨлҘё мң нҳ•мқҳ мҳЁлқјмқё м»Өл®ӨлӢҲнӢ°мҷҖ л§Ҳм°¬к°Җм§ҖлЎң мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°мқҳ л°ңм „лҸ„ мң лӘ…н•ң мҲҳлӘ…мЈјкё° мқҙлЎ мқ„ л”°лҰ…лӢҲлӢӨ. мҰү, 'м°Ҫм—…' - 'м„ұмһҘ' - 'м„ұмҲҷ' - 'мҮ нҮҙ'мқҳ лӢЁкі„лҘј кұ°м№©лӢҲлӢӨ. " мҲңмңјлЎң.
мғқлӘ…мЈјкё° мқҙлЎ мқҳ кҙҖм җмқ„ нҶөн•ҙ мҳЁлқјмқё м»Өл®ӨлӢҲнӢ°мқҳ 진нҷ” лӘЁлҚёмқ„ нғҗкө¬н•ҳкі мғқлӘ…мЈјкё°мқҳ к°Ғ лӢЁкі„мқҳ мҡҙмҳҒм—җ лҢҖн•ң л§ҺмқҖ м—°кө¬ мһ‘м—…мқҙ мқҙлЈЁм–ҙмЎҢмҠөлӢҲлӢӨ.
к·ёлҹ¬лӮҳ мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°мқҳ к°ҖмһҘ мӨ‘мҡ”н•ң кё°мҲ мқён”„лқј мӨ‘ н•ҳлӮҳмқё 추мІң мӢңмҠӨн…ңмқҙ мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°мқҳ 진нҷ”м—җ лҜём№ҳлҠ” мҳҒн–ҘмқҖ м—¬м „нһҲ вҖӢвҖӢмҲҳмҲҳк»ҳлҒјм—җ мӢём—¬ мһҲмҠөлӢҲлӢӨ.
мқҙ мҲҳмҲҳк»ҳлҒјлҘј н’Җкё° мң„н•ҙ н‘ёлӢЁлҢҖн•ҷкөҗ м»ҙн“Ён„°кіјн•ҷкіј CISL м—°кө¬нҢҖмқҖ лӢӨмқҢ м„ё к°Җм§Җ м—°кө¬ м§Ҳл¬ём—җ 집мӨ‘н•ҳкі мӢң뮬л Ҳмқҙм…ҳ мӢӨн—ҳмқ„ нҶөн•ҙ к·ё лӢөмқ„ м°ҫмңјл Өкі л…ёл Ҙн–ҲмҠөлӢҲлӢӨ.
1) лүҙмҠӨ 추мІң мғқнғңкі„ (лүҙмҠӨ 추мІң мғқнғңкі„, NRE) лқјмқҙн”„ мӮ¬мқҙнҒҙмқҳ к°Ғ лӢЁкі„мқҳ нҠ№м§•мқҖ л¬ҙм—Үмһ…лӢҲк№Ң?
2) NREмқҳ 진нҷ”лҘј мқҙлҒ„лҠ” н•өмӢ¬ мҡ”мҶҢлҠ” л¬ҙм—Үмқҙл©°, мқҙлҹ¬н•ң мҡ”мҶҢл“ӨмқҖ м–ҙл–»кІҢ мғҒнҳё мһ‘мҡ©н•ҳм—¬ 진нҷ” кіјм •м—җ мҳҒн–Ҙмқ„ лҜём№ҳлӮҳмҡ”?
3) 추мІң мӢңмҠӨн…ңмқҳ м„Өкі„ м „лһөмқ„ нҶөн•ҙ лҚ” лӮҳмқҖ мһҘкё°м Ғ лӢӨмһҗк°„ нҡЁмңЁм„ұмқ„ лӢ¬м„ұн•ҳм—¬ м»Өл®ӨлӢҲнӢ°к°Җ "мҮ нҮҙ"н•ҳлҠ” кІғмқ„ л°©м§Җн•ҳлҠ” л°©лІ•мқҖ л¬ҙм—Үмһ…лӢҲк№Ң?
мқҙ м„ё к°Җм§Җ м—°кө¬ м§Ҳл¬ём—җ лӢөн•ҳкё° мң„н•ҙ CISL м—°кө¬нҢҖмқҖ лүҙмҠӨ 추мІң мғқнғңкі„ 진нҷ” мӢң뮬л Ҳмқҙм…ҳ н”Ңлһ«нҸјмқё SimuLineмқ„ к°ңл°ңн–ҲмҠөлӢҲлӢӨ.
SimuLineмқҖ лЁјм Җ мӢӨм ң лҚ°мқҙн„° м„ёнҠёлҘј кё°л°ҳмңјлЎң н•©м„ұ лҚ°мқҙн„°лҘј мғқм„ұн•©лӢҲлӢӨ. мӣҗліё лҚ°мқҙн„° м„ёнҠём—җ лӮҙмһ¬лҗң л…ём¶ң нҺён–Ҙ л¬ём ң(Exposure Bias)лҘј н•ҙкІ°н•ҳкё° мң„н•ҙ SimuLineмқҖ нҺён–Ҙмқ„ м ңкұ°н•ҳкё° мң„н•ҙ м—ӯм„ұн–Ҙ м җмҲҳ(Inverse Propensity Score)лҘј лҸ„мһ…н–ҲмҠөлӢҲлӢӨ.
мқёк°„мқҳ мқҳмӮ¬кІ°м • кіјм •м—җ к°Җк№Ңмҡҙ мһ мһ¬ кіөк°„мқ„ кө¬м¶•н•ҳкё° мң„н•ҙ SimuLineмқҖ лҢҖк·ңлӘЁ л§җлӯүм№ҳлҘј кё°л°ҳмңјлЎң мӮ¬м „ н•ҷмҠөлҗң м–ём–ҙ лӘЁлҚё(Pretrained Language Models)мқ„ лҸ„мһ…н•ҳм—¬ мһ мһ¬ кіөк°„мқ„ кө¬м¶•н•©лӢҲлӢӨ. л§Ҳм§Җл§үмңјлЎң SimuLineмқҖ м—җмқҙм „нҠё кё°л°ҳ мӢң뮬л Ҳмқҙм…ҳмқ„ мӮ¬мҡ©н•©лӢҲлӢӨ. лӘЁлҚёл§Ғ)мқҖ лүҙмҠӨ 추мІң мғқнғңкі„м—җм„ң мӮ¬мҡ©мһҗ, мҪҳн…җмё м ңмһ‘мһҗ л°Ҹ 추мІң мӢңмҠӨн…ңмқҳ н–үлҸҷкіј мғҒнҳё мһ‘мҡ©мқ„ мӢң뮬л Ҳмқҙм…ҳн•©лӢҲлӢӨ.
н•©м„ұ лҚ°мқҙн„° мғқм„ұ
мӮ¬мҡ©мһҗлҘј лҢҖн‘ңн•ҳлҠ” мӢң뮬л Ҳмқҙн„°лҘј л§Ңл“Өл Өкі н• л•Ң к°ҖмһҘ лЁјм Җ л– мҳӨлҘҙлҠ” м§Ҳл¬ёмқҖ "мӮ¬мҡ©мһҗмқҳ лӢӨм–‘н•ң н–үлҸҷмқ„ м–ҙл–»кІҢ нҠ№м„ұнҷ”н•ҙм•ј н•ҳлҠ”к°Җ?"мһ…лӢҲлӢӨ.
мӢӨм ңлЎң мқҙм—җ лҢҖн•ң м§Ҳл¬ёмқҙ н•ҳлӮҳ мһҲмҠөлӢҲлӢӨ. м§Ҳл¬ё 추мІң мӢңмҠӨн…ң 분야м—җм„ң л„җлҰ¬ мӮ¬мҡ©лҗҳлҠ” л§Өмҡ° к°„лӢЁн•ң мҶ”лЈЁм…ҳмқҖ мһ мһ¬ кіөк°„мқ„ кө¬м¶•н•ң лӢӨмқҢ мӮ¬мҡ©мһҗмқҳ кҙҖмӢ¬мӮ¬мҷҖ лүҙмҠӨ мҪҳн…җмё лҘј мқҙ кіөк°„м—җ л§Өн•‘н•ҳлҠ” кІғмһ…лӢҲлӢӨ.
мқҙлҹ° л°©мӢқмңјлЎң мһ мһ¬ кіөк°„мқҳ лІЎн„° мң мӮ¬м„ұмқ„ нҶөн•ҙ лүҙмҠӨм—җ лҢҖн•ң мӮ¬мҡ©мһҗмқҳ м„ нҳёлҸ„лҘј мёЎм •н•ң нӣ„ мқјл Ёмқҳ н–үлҸҷ л…јлҰ¬мҷҖ к·ңм№ҷмқ„ м •мқҳн•ҳлҠ” кІғмқҙ л§Өмҡ° нҺёлҰ¬н•©лӢҲлӢӨ.
Construction
к·ёлҹ¬л©ҙ мқҙ мҲЁкІЁм§„ кіөк°„мқ„ м–ҙл–»кІҢ л§Ңл“Өк№Ңмҡ”?
м–ҙл–Ө н•ҷмғқл“ӨмқҖ "мқҙкІҢ лӯҗк°Җ к·ёл ҮкІҢ м–ҙл ӨмҡҙлҚ°!? 추мІң м•Ңкі лҰ¬мҰҳмқ„ м“°лҠ” кұ° м•„лӢҢк°Җмҡ”? 추мІң м•Ңкі лҰ¬мҰҳмқ„ мқҙмҡ©н•ҙм„ң н•ҳлӮҳ л°°мӣҢліҙлҠ” кұҙ м–ҙл–Ёк№Ңмҡ”?"
м •л§җ мўӢмқҖ мғқк°Ғмқҙм—җмҡ”. м ‘к·ј л°©мӢқмқҙм§Җл§Ң лӘҮ к°Җм§Җ лӘ…л°ұн•ң л¬ём ңк°Җ мһҲмҠөлӢҲлӢӨ.
CISC м—°кө¬нҢҖмқҙ к°ҖмһҘ лӢ№нҷ©н•ң м җмқҖ "м•Ңкі лҰ¬мҰҳ көҗлһҖ"мқҙлқјлҠ” л…јлҰ¬м Ғ м·Ём•Ҫм җмһ…лӢҲлӢӨ. мҰү, 추мІң м•Ңкі лҰ¬мҰҳ AлҘј мӮ¬мҡ©н•ҳм—¬ мһ мһ¬ кіөк°„мқ„ кө¬м¶•н•ҳкі мӮ¬мҡ©мһҗмҷҖ лүҙмҠӨлҘј мӢӨм ң н–үлҸҷ кІ°м •мңјлЎң л§Өн•‘н•ҳлҠ” кІҪмҡ°мһ…лӢҲлӢӨ. к·ёл ҮлӢӨл©ҙ мқҙнӣ„мқҳ мӢң뮬л Ҳмқҙм…ҳ кіјм •м—җм„ң мӮ¬мҡ©лҗҳлҠ” м•Ңкі лҰ¬мҰҳ BлҠ” н”јнҢ… м•Ңкі лҰ¬мҰҳ Aк°Җ лҗҳм§Җ м•Ҡмқ„к№Ңмҡ”? (мқҙкІғмқҖ мҰқлҘҳ н•ҷмҠөмқ„ м–ҙлҠҗ м •лҸ„ м•„лҠ” н•ҷмғқл“Өм—җкІҢлҠ” м№ңмҲҷн•ҳкІҢ ліҙмқјк№Ңмҡ”?)
к·ёлҰ¬кі нҳ„мһ¬ 추мІң м•Ңкі лҰ¬мҰҳмқҳ лҢҖл¶Җ분мқҖ м—¬м „нһҲ вҖӢвҖӢлё”лһҷл°•мҠӨ лӘЁлҚёмһ…лӢҲлӢӨ. лҲҲмқ„ к°җкі м•Ңкі лҰ¬мҰҳ нҳјлһҖмқ„ л¬ҙмӢңн•ҳлҚ”лқјлҸ„ мӢң뮬л Ҳмқҙм…ҳ лҚ°мқҙн„°лҘј 분м„қн• л•Ң м—¬м „нһҲ нҳјлһҖмҠӨлҹ¬мҡё кІғмһ…лӢҲлӢӨ(мқҙ м°Ёмӣҗмқҙ м җм җ м»Өм§Җкі мһҲм§Җл§Ң л¬ҙм—Үмһ…лӢҲк№Ң? мқҙ м°ЁмӣҗмқҖ л¬ҙм—Үмқ„ мқҳлҜён•©лӢҲк№Ң?
м—°кө¬нҢҖмқҙ лӢ№нҷ©н•ҳлҚҳ м°°лӮҳ, н•ҳм–Җ 섬кҙ‘мқҙ лІҲм©ҚмҳҖлӢӨ: лҢҖк·ңлӘЁ мҪ”нҚјмҠӨлҘј кё°л°ҳмңјлЎң нӣҲл Ёлҗң м–ём–ҙ лӘЁлҚёмқҙ мһҲлӢӨкі л§җн•ҳкё° м „м—җ кё°мӮ¬лҘј ліё кІғ к°ҷм•ҳлӢӨ(м—¬м „нһҲ лІ лҘҙнҠёмқҳ м„ёкі„мҳҖлӢӨ) лӢ№мӢңм—җлҠ” ChatGPTк°Җ м•„м§Ғ нғ„мғқн•ҳм§Җ м•Ҡм•ҳмқҢ)мқҖ кё°ліём Ғмқё мқёк°„ мқёмӢқ(мҰү, мң лӘ…н•ң мҷ• вҖ“ лӮЁм„ұ + м—¬м„ұ = м—¬мҷ•)мқ„ мҲҳн–үн• мҲҳ мһҲм—ҲмҠөлӢҲлӢӨ.
к·ёл ҮлӢӨл©ҙ мқҙкІғмқҖ мһ мһ¬ кіөк°„ кө¬м¶•м—җ л§Өмҡ° м Ғн•©н•ҳм§Җ м•Ҡмқ„к№Ңмҡ”?
1. мӮ¬мҡ©мһҗмҷҖ лүҙмҠӨлҘј мқёмҪ”л”©н• мҲҳ мһҲмҠөлӢҲлӢӨ.
2. мІҙнҷ”лҗң мқёк°„мқҳ мқёмӢқмқҖ кё°ліём Ғмқҙкі ліҙнҺём Ғмқҙм–ҙм•ј н•ҳлҜҖлЎң м•Ңкі лҰ¬мҰҳ нҳјлһҖ л¬ём ңлҘј н”јн•ҙм•ј н•©лӢҲлӢӨ.
3. мҲЁкІЁм§„ кіөк°„мқҳ к°Ғ м°Ёмӣҗмқҙ л¬ҙм—Үмқ„ лӮҳнғҖлӮҙлҠ”м§ҖлҠ” нҷ•мӢӨн•ҳм§Җ м•Ҡм§Җл§Ң мқҙлҠ” кіөк°„м—җ мҳҒн–Ҙмқ„ лҜём№ҳм§Җ м•ҠмҠөлӢҲлӢӨ. мң мӮ¬м„ұ лІЎн„° кІҖмғүмқ„ нҶөн•ҙ кіөк°„ лӮҙ к°Ғ м§Җм җм—җ лҢҖн•ң н…ҚмҠӨнҠём—җ лҢҖн•ң лҢҖлһөм Ғмқё м„ӨлӘ…мқ„ м ңкіөн•©лӢҲлӢӨ.
м •л§җ нӣҢлҘӯн•ҙмҡ”! кІ°м •мқҖ лӢ№мӢ мқҳ кІғмһ…лӢҲлӢӨ!
Mapping
лӢӨмқҢ лӢЁкі„лҠ” мӮ¬мҡ©мһҗмҷҖ лүҙмҠӨлҘј мқҙ кіөк°„м—җ л§Өн•‘н•ҳлҠ” кІғмһ…лӢҲлӢӨ.
лүҙмҠӨлҠ” мқҙм•јкё°н•ҳкё° мүҪмҠөлӢҲлӢӨ. лүҙмҠӨм—җлҠ” н’Қл¶Җн•ң н…ҚмҠӨнҠё м •ліҙк°Җ мһҲм–ҙм•ј н•ҳл©° м§Ғм ‘ мқёмҪ”л”©н• мҲҳ мһҲм–ҙм•ј н•©лӢҲлӢӨ. к·ёлҹ°лҚ° мӮ¬мҡ©мһҗлҠ” мқҙлҘј м–ҙл–»кІҢ мІҳлҰ¬н•ҙм•ј н• к№Ңмҡ”? мӮ¬мҡ©мһҗк°Җ мўӢм•„н•ҳлҠ” лүҙмҠӨлҘј нһҲмҠӨнҶ лҰ¬м—җм„ң нҸүк· мқ„ кө¬н•ҳлҠ” кІғмқҙ к°ҖлҠҘн•ңк°Җмҡ”?
м•ҲлҸј!
к°ҖмҰқмҠӨлҹ¬мҡҙ көҗлһҖ м•Ңкі лҰ¬мҰҳмқҙ мқҙлІҲм—җлҠ” л…ём¶ң нҺён–ҘмқҙлқјлҠ” мқҙлҰ„мңјлЎң лҸҢм•„мҷ”мҠөлӢҲлӢӨ. мқҙлҠ” мӮ¬мҡ©мһҗк°Җ мўӢм•„н•ҳлҠ” лүҙмҠӨлҠ” мӮ¬мҡ©мһҗк°Җ лҙҗм•ј н•ҳкё° л•Ңл¬ём—җ мӮ¬мҡ©мһҗмқҳ мўӢм•„мҡ” кё°лЎқмқҙ л°ҳл“ңмӢң мӮ¬мҡ©мһҗмқҳ кҙҖмӢ¬мқ„ мҷ„м „нһҲ л°ҳмҳҒн•ҳм§ҖлҠ” м•ҠлҠ”лӢӨлҠ” мқҳлҜёмһ…лӢҲлӢӨ. мӮ¬мҡ©мһҗк°Җ ліҙлҠ” лүҙмҠӨлҠ” 추мІң мӢңмҠӨн…ңм—җ мқҳн•ҙ н•„н„°л§Ғлҗҳм—Ҳкё° л•Ңл¬ём—җ мӮ¬мҡ©мһҗк°Җ мўӢм•„н•ҳм§Җ м•Ҡм•ҳмқ„ к°ҖлҠҘм„ұмқҙ мһҲмҠөлӢҲлӢӨ.
лӢӨн–үнһҲлҸ„ мҲҳл…„к°„мқҳ кёүмҶҚн•ң л°ңм „ лҒқм—җ 추мІң мӢңмҠӨн…ң 분야мқҳ л¬ҙкё°кі лҠ” 충분합лӢҲлӢӨ. м—°кө¬нҢҖмқҖ Unbiased Recommendation Warehouseм—җм„ң мқҙ л¬ём ңлҘј н•ҙкІ°н•ҳкё° мң„н•ң нҺёлҰ¬н•ң л¬ҙкё°мқё Inverse Propensity Score(IPS)лҘј л°ңкІ¬н–ҲмҠөлӢҲлӢӨ.
к°„лӢЁнһҲ л§җн•ҳл©ҙ 추мІң мғҳн”Ңмқҳ л…ём¶ң л°ҖлҸ„лҘј м¶”м •н•ҳм—¬ к°ҖмӨ‘м№ҳлҘј л¶Җм—¬н•ЁмңјлЎңмҚЁ лӘЁлҚё н•ҷмҠө кіјм •м—җм„ң л°ңмғқн•ҳлҠ” нҺён–Ҙмқ„ мғҒмҮ„н•ҳм—¬ мӮ¬мҡ©мһҗмқҳ мҪ”л”© л¬ём ңлҘј н•ҙкІ°н•ҳлҠ” кІғмһ…лӢҲлӢӨ.
мөңмў… мҪҳн…җмё м ңмһ‘мһҗмқҳ мҪҳн…җмё кІҢмӢң н–үмң„лҠ” л…ём¶ң нҺён–Ҙмқҳ мҳҒн–Ҙмқ„ л°ӣм§Җ м•Ҡмңјл©°, кіјкұ° кё°лЎқм—җ м§Ғм ‘м Ғмқё к°ҖмӨ‘м№ҳк°Җ л¶Җм—¬лҗ©лӢҲлӢӨ. мӢӨм ңлЎң мң„мқҳ мһ‘м—…мқ„ л§Ҳм№ң нӣ„ лҚ°мқҙн„° мӨҖ비 мһ‘м—…мқҖ кё°ліём ҒмңјлЎң мҷ„лЈҢлҗҳм—Ҳм§Җл§Ң м—¬м „нһҲ л‘җ к°Җм§Җ л¶ҖмЎұн•ң м җмқҙ мһҲмҠөлӢҲлӢӨ.
В· мІ«м§ё, лҚ°мқҙн„° к·ңлӘЁк°Җ мЎ°м •лҗҳм§Җ м•Ҡм•ҳмңјл©° м»ҙн“ЁнҢ… лҰ¬мҶҢмҠӨм—җ м Ғн•©н•ҳм§Җ м•Ҡмқ„ мҲҳ мһҲмҠөлӢҲлӢӨ( мһ‘мқҖ лӢ№лӮҳк·Җк°Җ нҒ° лӢ№лӮҳк·ҖлҘј лӢ№кёҙлӢӨ/нҒ° лӢ№лӮҳк·Җ лӘЁм–‘кіө)
В· л‘ҳм§ё, мӮ¬мҡ©мһҗмқҳ мӮ¬мғқнҷңмқҙ мЎҙмӨ‘лҗҳм§Җ м•ҠмҠөлӢҲлӢӨ. л”°лқјм„ң м—°кө¬нҢҖмқҖ мӣҗліё лҚ°мқҙн„° м„ёнҠёмқҳ мӮ¬мҡ©мһҗ мҪ”л”©мқ„ кё°л°ҳмңјлЎң мғқм„ұ лӘЁлҚё л Ҳмқҙм–ҙлҘј 추к°Җн–ҲмҠөлӢҲлӢӨ.
лүҙмҠӨ н”Ңлһ«нҸјмқҖ н•ӯмғҒ нҢҢнӢ°м…ҳ нғҗмғү(кёҲмңө, мҠӨнҸ¬мё , кё°мҲ л“ұ)мңјлЎң м„Өкі„лҗҳм–ҙ мһҲкі лӢӨм–‘н•ң нҢҢнӢ°м…ҳм—җ мӮ¬мҡ©мһҗк°Җ нҒҙлҹ¬мҠӨн„°л§ҒлҗҳлҠ” кІғлҸ„ лӢ№м—°н•ҳлӢӨлҠ” м җмқ„ кі л Өн•ҳм—¬ м—°кө¬нҢҖмқҖ GMM(Gaussian Mixture Model)мқ„ лӢӨмқҢкіј к°ҷмқҙ нҷҚліҙн–ҲмҠөлӢҲлӢӨ. мқҙ мһ‘м—…мқ„ лӢҙлӢ№н•©лӢҲлӢӨ.
м—җмқҙм „нҠё лӘЁлҚёл§Ғ
мӮ¬м „ лҚ°мқҙн„° мӨҖ비 мһ‘м—…мқҙ мҷ„лЈҢлҗҳл©ҙ мӮ¬мҡ©мһҗ н–үлҸҷ лӘЁлҚёл§Ғмқ„ мӢңмһ‘н• мҲҳ мһҲмҠөлӢҲлӢӨ.
м—°кө¬нҢҖмқҖ к°ңмқёмқҳ н–үлҸҷкіј к°ңмқё к°„мқҳ мғҒнҳёмһ‘мҡ©мқ„ лӘЁлҚёл§Ғн•ң нӣ„, лӢӨмҲҳмқҳ м—җмқҙм „нҠёлҘј л°°м№ҳн•ҳм—¬ к·ёлЈ№мқҳ м—ӯн•ҷмқ„ мӢң뮬л Ҳмқҙм…ҳн•ҳлҠ” м—җмқҙм „нҠё кё°л°ҳ лӘЁлҚёл§Ғ л°©мӢқмқ„ мұ„нғқн–ҲмҠөлӢҲлӢӨ.
лӢЁмҲңнһҲ мӮ¬мҡ©мһҗмқҳ мҳЁлқјмқё лүҙмҠӨ мқҪкё° кіјм •(мҳҲ: мҳӨлҠҳ ToutiaoлҘј мқҪмқ„ л•Ң)мқ„ мғҒкё°н•ҳл©ҙ мӮ¬мҡ©мһҗлҠ” лЁјм Җ нҠ№м • нҺҳмқҙм§Җмқҳ 추мІң мӢңмҠӨн…ңм—җм„ң 추мІңн•ҳлҠ” мқјл Ёмқҳ лүҙмҠӨлҘј ліҙкІҢ лҗҳл©°, к·ёлҹ° лӢӨмқҢ мӮ¬мҡ©мһҗлҠ” к°Ғ лүҙмҠӨмқҳ м ңлӘ©, мӮ¬м§„ л°Ҹ мҡ”м•Ҫмқ„ нғҗмғүн•ҳм—¬ нҠ№м • лүҙмҠӨк°Җ мӮ¬мҡ©мһҗмқҳ кҙҖмӢ¬мқ„ л¶Ҳлҹ¬мқјмңјнӮӨл©ҙ лүҙмҠӨлҘј мқҪмқҖ нӣ„ н•ҙлӢ№ лӮҙмҡ©мқҙ л¬ҙм—Үмқём§Җ нҷ•мқён•ҳкё° мң„н•ҙ нҒҙлҰӯн•©лӢҲлӢӨ. лүҙмҠӨк°Җ мўӢкі , мқҪмқ„ к°Җм№ҳк°Җ мһҲкұ°лӮҳ мһҗмӢ мқҳ кІ¬н•ҙмҷҖ мқјм№ҳн•ҳл©ҙ мӮ¬мҡ©мһҗлҠ” мўӢм•„мҡ” л°Ҹ кё°нғҖ л°©лІ•мқ„ нҶөн•ҙ лүҙмҠӨм—җ лҢҖн•ң лҸҷмқҳлҘј н‘ңнҳ„н•©лӢҲлӢӨ.
Definition
мқҙ кіјм •м—җм„ң мӮ¬мҡ©мһҗмҷҖ лүҙмҠӨмқҳ мғҒнҳёмһ‘мҡ©мқҖ м„ё к°Җм§Җ мҲҳмӨҖ(л…ём¶ң, нҒҙлҰӯ, мўӢм•„мҡ”)мңјлЎң лӮҳлҲҢ мҲҳ мһҲмңјл©°, к·ё мӨ‘ нҒҙлҰӯкіј мўӢм•„мҡ”к°Җ мӮ¬мҡ©мһҗмқҳ м Ғк·№м Ғмқё н–үлҸҷмқҙл©°, мқҙлҘј мң„н•ҙм„ңлҠ” мӮ¬мҡ©мһҗ м—җмқҙм „нҠём—җм„ң м •мқҳлҗҳм–ҙм•ј н•©лӢҲлӢӨ.
м—¬кё°м„ң м—°кө¬нҢҖмқҖ мӮ¬мҡ©мһҗмқҳ нҒҙлҰӯ н–үлҸҷмқ„ нҷ•лҘ м Ғ м„ нғқ н–үлҸҷмңјлЎң мҡ”м•Ҫн•©лӢҲлӢӨ. мӮ¬мҡ©мһҗлҠ” нҠ№м • нҷ•лҘ мқ„ к°Җм§Җкі мһҲмҠөлӢҲлӢӨ. лӘ©лЎқм—җм„ң кҙҖмӢ¬ мһҲлҠ” лүҙмҠӨлҘј м„ нғқн•ҳкі нҒҙлҰӯн•ҳм—¬ мқҪмңјм„ёмҡ”.
мқҙ м •мқҳлҠ” к°ҖмһҘ мқјм№ҳн•ҳлҠ” лүҙмҠӨлҘј м§Ғм ‘ нҒҙлҰӯн•ҳлҠ” кІғліҙлӢӨ лҚ” мң м—°н•©лӢҲлӢӨ. мҰү, л°ҳл“ңмӢң мқјм№ҳлҸ„к°Җ лҶ’лӢӨлҠ” мқҳлҜёлҠ” м•„лӢҲл©° мӢӨм ң мғҒнҷ©м—җ лҚ” л¶Җн•©н•©лӢҲлӢӨ.
мўӢм•„мҡ”мқҳ н–үлҸҷм—җ кҙҖн•ҙм„ңлҠ” лӢЁмҲңнһҲ лүҙмҠӨмқҳ мқјм№ҳ м •лҸ„лҘј кі л Өн• мҲҳлҠ” м—ҶмҠөлӢҲлӢӨ. кІ°көӯ мҡ°лҰ¬ лӘЁл‘җ м•Ңкі мһҲл“Ҝмқҙ лүҙмҠӨм—җм„ңлҠ” н—Өл“ңлқјмқёмқ„ м°Ём§Җн•ҳлҠ” нҳ„мғҒмқҙ м—¬м „нһҲ нқ”н•©лӢҲлӢӨ.
л”°лқјм„ң м—°кө¬нҢҖмқҖ лүҙмҠӨ ліҙлҸ„мқҳ к°Җм№ҳлҘј мқјл°ҳм ҒмңјлЎң лӮҳнғҖлӮҙкё° мң„н•ҙ 'лүҙмҠӨ н’Ҳм§Ҳ'мқҙлқјлҠ” 추мғҒм Ғмқё к°ңл…җмқ„ лҸ„мһ…н–ҲмҠөлӢҲлӢӨ. мқҙмҷҖ к°ҷмқҙ мӮ¬мҡ©мһҗмқҳ мң мӮ¬ н–үмң„лҠ” мЈјкҙҖм Ғмқё кҙҖмӢ¬лҸ„мҷҖ к°қкҙҖм Ғмқё н’Ҳм§ҲлЎң нҠ№м§•м§Җм–ҙм§Ҳ мҲҳ мһҲмҠөлӢҲлӢӨ.
м—°кө¬нҢҖмқҖ м—җмқҙм „нҠёмқҳ мң мӮ¬ н–үлҸҷмқ„ м ңм–ҙн•ҳкё° мң„н•ҙ кё°лҢҖ лӘЁлҚёмқ„ мӮ¬мҡ©н•©лӢҲлӢӨ. кө¬мІҙм ҒмңјлЎң, лЁјм Җ кҙҖмӢ¬ л§Өм№ӯ м •лҸ„мҷҖ лүҙмҠӨ н’Ҳм§Ҳмқ„ кё°л°ҳмңјлЎң нҠ№м • лүҙмҠӨлҘј мқҪлҠ” мӮ¬мҡ©мһҗмқҳ нҡЁмҡ©(Utility)мқ„ кі„мӮ°н•©лӢҲлӢӨ. кё°лҢҖ(м—°кө¬ нҢҖмқҖ мқҙ кё°лҢҖмқҳ нҠ№м • к°’мқ„ лӮҳнғҖлӮҙкё° мң„н•ҙ н•ҳмқҙнҚјнҢҢлқјлҜён„° мһ„кі„к°’мқ„ мӮ¬мҡ©н•Ё)мҷҖ мң мӮ¬н•ң лҸҷмһ‘мқҙ нҠёлҰ¬кұ°лҗ©лӢҲлӢӨ.
мқҙ л””мһҗмқём—җ лҢҖн•ң м§ҒкҙҖм Ғмқё м„ӨлӘ…мқҖ, к·ёкІғмқҙ лӮҳм—җкІҢ м Ғн•©н•ҳкё° л•Ңл¬ёмқҙл“ ліҙкі м„ң мһҗмІҙк°Җ л§Өмҡ° к°қкҙҖм Ғмқҙкі нҸ¬кҙ„м Ғмқҙкё° л•Ңл¬ём—җ м–ҙл–Ө лүҙмҠӨк°Җ лӮҳлҘј н–үліөн•ҳкІҢ н•ңлӢӨл©ҙ мЈјм Җн•ҳм§Җ м•Ҡкі мўӢм•„н• кІғмқҙлқјлҠ” кІғмһ…лӢҲлӢӨ.
лҳҗн•ң лүҙмҠӨлҘј мқҪлҠ” кіјм •м—җм„ң мӮ¬мҡ©мһҗмқҳ кҙҖмӢ¬мқҙлӮҳ мқҳкІ¬мқҖ 분лӘ…нһҲ кі м •лҗҳм–ҙ мһҲм§Җ м•ҠмҠөлӢҲлӢӨ.
мҳҲлҘј л“Өм–ҙ мӮ¬мҡ©мһҗк°Җ л§Өмҡ° мўӢм•„н•ҳлҠ” лүҙмҠӨ ліҙлҸ„лҘј ліё кІҪмҡ° кҙҖл Ё лүҙмҠӨлҘј лҚ” к№Ҡмқҙ нҢҢкі л“ңлҠ” мӮ¬мҡ©мһҗмқҳ мҡ•кө¬лҘј мһҗк·№н• мҲҳ мһҲмҠөлӢҲлӢӨ. л°ҳлҢҖлЎң ліҙлҸ„к°Җ мӮ¬мҡ©мһҗм—җкІҢ мҷ„м „нһҲ мҡ°мҠӨкҪқмҠӨлҹҪлӢӨкі лҠҗлҒјкІҢ н•ңлӢӨл©ҙ, мӮ¬мҡ©мһҗлҠ” м•һмңјлЎң мң мӮ¬н•ң ліҙкі м„ңлҘј ліј л•Ң ліҙкі м„ңмқҳ м„ёл¶Җ мӮ¬н•ӯмқ„ ліҙкё° мң„н•ҙ н•ҙлӢ№ ліҙкі м„ңлҘј нҒҙлҰӯн• к°ҖлҠҘм„ұмқҙ мӨ„м–ҙл“Ө кІғмһ…лӢҲлӢӨ.
мқҙ нҳ„мғҒмқҖ м—°кө¬нҢҖм—җм„ң мӮ¬мҡ©мһҗ л“ңлҰ¬н”„нҠё лӘЁлҚёлЎң лӘЁлҚёл§Ғн–ҲмҠөлӢҲлӢӨ.
м°Ҫмқҳм Ғ н–үлҸҷ лӘЁлҚёл§Ғ
лӢӨмқҢмқҖ лүҙмҠӨ м ңмһ‘мһҗмқҳ м°Ҫмқҳм Ғ н–үлҸҷмқ„ лӘЁлҚёл§Ғн•©лӢҲлӢӨ.
нҳ„мӢӨ м„ёкі„мқҳ лүҙмҠӨ м°Ҫмһ‘мқҖ лӢӨм–‘н•ң мҡ”мқём—җ мқҳн•ҙ мҳҒн–Ҙмқ„ л°ӣкІҢ лҗ©лӢҲлӢӨ. м—°кө¬нҢҖмқҖ мқҙлҘј нғҗмҡ•мҠӨлҹ¬мҡҙ кіјм •мңјлЎң лӢЁмҲңнҷ”н•©лӢҲлӢӨ. мҰү, м ҖмһҗлҠ” н•ӯмғҒ мһҗмӢ мқҙ л§Ңл“ңлҠ” лүҙмҠӨк°Җ лҚ” л§ҺмқҖ лҸ…мһҗл“Өм—җкІҢ мқёмӢқлҗ мҲҳ мһҲкё°лҘј л°”лһҚлӢҲлӢӨ.
нҠ№м • м—җмқҙм „нҠё н–үлҸҷм ңм–ҙ м—°кө¬нҢҖмқҖ мӮ¬мҡ©мһҗ нҒҙлҰӯкіј мң мӮ¬н•ң мҶ”лЈЁм…ҳмқ„ мұ„нғқн•©лӢҲлӢӨ. нҒ¬лҰ¬м—җмқҙн„°лҠ” мқҙм „ лқјмҡҙл“ңм—җм„ң мғқм„ұн•ң лүҙмҠӨмқҳ мўӢм•„мҡ”лҘј кё°л°ҳмңјлЎң нҷ•лҘ мғҳн”Ңл§Ғмқ„ мҲҳн–үн•ҳкі мғҲлЎңмҡҙ мғқм„ұ лқјмҡҙл“ңмқҳ мЈјм ңлҘј м„ нғқн•ң нӣ„ 집мӨ‘н•©лӢҲлӢӨ. лүҙмҠӨ м ңмһ‘мқ„ мң„н•ң мЈјм ңм—җ кҙҖн•ң кІғмһ…лӢҲлӢӨ. лүҙмҠӨ мғқм„ұ кіјм •мқҖ мһ мһ¬ кіөк°„мқҳ мЈјм ң мӨ‘мӢ¬ к°Җмҡ°мҠӨ 분нҸ¬м—җм„ң мғҳн”Ңл§Ғн•ҳлҠ” кіјм •кіј мң мӮ¬н•ҳкІҢ лӘЁлҚёл§Ғлҗ©лӢҲлӢӨ.
лүҙмҠӨмқҳ лӮҙмҡ©(мһ мһ¬ кіөк°„ н‘ңнҳ„) мҷём—җлҸ„ лүҙмҠӨмқҳ н’Ҳм§ҲлҸ„ лӘЁлҚёл§Ғлҗҳм–ҙм•ј н•©лӢҲлӢӨ. мқҙлҠ” нҳ„мӢӨмқҳ лІ•м№ҷкіј мқјм№ҳн•ҳлҠ” л‘җ к°Җм§Җ кё°ліё к°Җм •мқ„ кё°л°ҳмңјлЎң н•©лӢҲлӢӨ.
1. мһ‘м„ұмһҗк°Җ л°ӣлҠ” мўӢм•„мҡ” мҲҳмҷҖ мҲҳмһ… к°„м—җлҠ” кёҚм •м Ғмқё мғҒкҙҖкҙҖкі„к°Җ м•Ҫк°„ к°җмҶҢн•©лӢҲлӢӨ. мҰү, мһ‘м„ұмһҗк°Җ л°ӣлҠ” мўӢм•„мҡ” мҲҳк°Җ л§Һ아집лӢҲлӢӨ. , мқҪмқ„мҲҳлЎқ мҲҳмһ…мқҙ лҠҳм–ҙлӮҳм§Җл§Ң мўӢм•„мҡ” мҲҳк°Җ лҠҳм–ҙлӮ мҲҳлЎқ лӢЁмқј мўӢм•„мҡ”лЎң мқён•ң мҲҳмһ…мқҖ м җм°Ё к°җмҶҢн•©лӢҲлӢӨ.
2. мҳҲмӮ°мқҙ лҚ” 충분합лӢҲлӢӨ. мқҙлҘј л°”нғ•мңјлЎң мқҙм „ лқјмҡҙл“ңмқҳ мўӢм•„мҡ” мҲҳлҘј лӢӨмқҢ лқјмҡҙл“ңмқҳ лүҙмҠӨ н’Ҳм§ҲлЎң л§Өн•‘н•ҳлҠ” кё°лҠҘмқ„ кө¬м¶•н•ҳм—¬ лүҙмҠӨ мғқм„ұмқҳ н’Ҳм§Ҳмқ„ м ңм–ҙн• мҲҳ мһҲмҠөлӢҲлӢӨ.
추мІң мӢңмҠӨн…ң лӘЁлҚёл§Ғ
л§Ҳм§Җл§үмңјлЎң 추мІң мӢңмҠӨн…ңмқҳ лҸҷмһ‘мқ„ лӘЁлҚёл§Ғн•©лӢҲлӢӨ.
м•Ңкі лҰ¬мҰҳ 추мІңкіј мҪңл“ң мҠӨнғҖнҠё вҖӢвҖӢ추мІңмқҖ лүҙмҠӨ 추мІң мӢңмҠӨн…ңмқҳ л‘җ к°Җм§Җ кё°ліё кө¬м„ұ мҡ”мҶҢмһ…лӢҲлӢӨ. к°ңмқёнҷ”лҗң м•Ңкі лҰ¬мҰҳ 추мІңмқ„ м ңкіөн•ҳкё° мң„н•ҙ 추мІң мӢңмҠӨн…ңмқҖ лЁјм Җ BPR л“ұмқҳ 추мІң м•Ңкі лҰ¬мҰҳмқ„ мӮ¬мҡ©н•ҳм—¬ кіјкұ° мғҒнҳё мһ‘мҡ© лҚ°мқҙн„°лЎңл¶Җн„° мһ„лІ л”© кіөк°„мқҳ мӮ¬мҡ©мһҗ л°Ҹ лүҙмҠӨ н‘ңнҳ„мқ„ н•ҷмҠөн•©лӢҲлӢӨ. 추мІң м•Ңкі лҰ¬мҰҳм—җ мқҳн•ҙ н•ҷмҠөлҗң кіөк°„мқ„ м°ёмЎ°н•ҳкё° мң„н•ҙ мһ„лІ л”© кіөк°„мқ„ мӮ¬мҡ©н•ҳкі м¶”мІң лӘ©лЎқмқ„ мғқм„ұн•ҳлҠ” лҚ° мӮ¬мҡ©лҗҳлҠ” мӢӨм ң мӮ¬мҡ©мһҗ кҙҖмӢ¬ кіөк°„мқ„ мқёмҪ”л”©н•ҳлҠ” лҢҖк·ңлӘЁ м–ём–ҙ лӘЁлҚё).
к·ёлҹ¬лӮҳ мӮ¬мҡ©мһҗмқҳ мң мӮ¬ н–үлҸҷм—җ лҢҖн•ң л¶Ҳнҷ•мӢӨм„ұкіј лүҙмҠӨ мң нҡЁм„ұ м°Ҫмқҳ м ңн•ңмңјлЎң мқён•ҙ м•Ңкі лҰ¬мҰҳ 추мІңмқҖ лӢЁмҲң л¬ҙмһ‘мң„ 추мІңмқ„ нҶөн•ҙ лӘЁл“ мӮ¬мҡ©мһҗлҘј нҸ¬кҙ„н• мҲҳ мһҲлӢӨкі ліҙмһҘн• мҲҳ м—ҶмҠөлӢҲлӢӨ.
кіјкұ° мғҒнҳёмһ‘мҡ© кё°лЎқмқҙ л¶ҖмЎұн•ҳм—¬ мғҲлЎң мғқм„ұлҗң лүҙмҠӨлҠ” м•Ңкі лҰ¬мҰҳ 추мІңм—җ м°ём—¬н• мҲҳ м—ҶмҠөлӢҲлӢӨ. SimuLineмқҖ л¬ҙмһ‘мң„ 추мІң, кІҪн—ҳм Ғ 추мІң м•Ңкі лҰ¬мҰҳ(мҳҲ: кіјкұ°м—җ мўӢм•„н–ҲлҚҳ нҒ¬лҰ¬м—җмқҙн„°мқҳ мғҲлЎңмҡҙ ліҙкі м„ң)кіј к°ҷмқҖ м „лһөмқ„ м Ғмҡ©н•ҳм—¬ мҪңл“ң мҠӨнғҖнҠё вҖӢвҖӢлүҙмҠӨлҘј 추мІңн•©лӢҲлӢӨ.
лҳҗн•ң SimuLineмқҖ мҶҚліҙ, мҪҳн…җмё м ңмһ‘мһҗ кё°л°ҳ н”„лЎңлӘЁм…ҳ, мЈјм ң кё°л°ҳ н”„лЎңлӘЁм…ҳ л“ұ лӢӨлҘё кІҪн—ҳм Ғ лүҙмҠӨ 추мІң м „лһөлҸ„ м§Җмӣҗн•©лӢҲлӢӨ.
лӘЁл“ 추мІң м „лһөм—җлҠ” лҸ…лҰҪм Ғмқё н‘ёмӢң н• лӢ№лҹүмқҙ мһҲмҠөлӢҲлӢӨ. 추мІң мӢңмҠӨн…ңмқҖ лӘЁл“ мұ„л„җмқҳ лүҙмҠӨ 추мІңмқ„ кІ°н•©н•ҳм—¬ мөңмў… 추мІң лӘ©лЎқмқ„ кө¬м„ұн•©лӢҲлӢӨ.
мӢң뮬л Ҳмқҙм…ҳ мӢӨн—ҳ
лҚ°мқҙн„°лҠ” к·ёлҢҖлЎң! лӘЁлҚёмқҙ л§Ңл“Өм–ҙмЎҢмҠөлӢҲлӢӨ! лӢӨмқҢмқҖ лӘҮ к°Җм§Җ нқҘлҜёлЎңмҡҙ мӢӨн—ҳмһ…лӢҲлӢӨ!
м—°кө¬нҢҖмқҖ лүҙмҠӨ 추мІң 분야м—җм„ң л„җлҰ¬ мӮ¬мҡ©лҗҳлҠ” Adressa лҚ°мқҙн„° м„ёнҠёлҘј м„ нғқн–ҲмҠөлӢҲлӢӨ. мқҙ лҚ°мқҙн„° м„ёнҠёлҠ” 2017л…„ 2мӣ” нҠ№м • мЈјк°„мқҳ л…ёлҘҙмӣЁмқҙ лүҙмҠӨ мӣ№мӮ¬мқҙнҠё www.adressa.noмқҳ м „мІҙ мӣ№ лЎңк·ёлҘј м ңкіөн•©лӢҲлӢӨ. лӢӨлҘё мҡ°мҲҳн•ң лүҙмҠӨ 추мІң лҚ°мқҙн„°мҷҖ н•Ёк»ҳ лӢӨлҘё лүҙмҠӨ 컬л үм…ҳ(мҳҲ: Microsoftмқҳ MIND)кіј 비көҗн•ҳм—¬ кё°ліём ҒмңјлЎң л§Өмҡ° мӨ‘мҡ”н•ң лүҙмҠӨ мһ‘м„ұмһҗ м •ліҙлҘј м ңкіөн•©лӢҲлӢӨ. мқҙм—җ л”°лқј м–ём–ҙ лӘЁлҚёмқҖ кё°ліём ҒмңјлЎң л…ёлҘҙмӣЁмқҙм–ҙлҘј м§Җмӣҗн•ҳлҠ” BPEmbлҘј мӮ¬мҡ©н•©лӢҲлӢӨ. л°°нҸ¬м—җ лҢҖн•ң мһҗм„ён•ң лӮҙмҡ©мқҖ мқҙ л¬ём„ңмқҳ 4мһҘ мІ« лІҲм§ё м„№м…ҳмқ„ м°ёмЎ°н•ҳм„ёмҡ”.
к·ёлҹј SimuLineмқҳ мӢң뮬л Ҳмқҙм…ҳ кІ°кіјлҘј 분м„қн•ҳлҠ” л°©лІ•мқҖ л¬ҙм—Үмқјк№Ңмҡ”? SimuLineмқҖ м°ёмЎ°н• мҲҳ мһҲлҸ„лЎқ лӢӨм–‘н•ң кҙҖм җм—җм„ң нҸ¬кҙ„м Ғмқё 분м„қ н”„л Ҳмһ„мӣҢнҒ¬лҘј м ңкіөн•©лӢҲлӢӨ.
мІ« лІҲм§ёлҠ” к°ҖмһҘ мқјл°ҳм ҒмңјлЎң мӮ¬мҡ©лҗҳлҠ” м •лҹүм Ғ м§Җн‘ң нҸүк°Җ мӢңмҠӨн…ңмһ…лӢҲлӢӨ.
лүҙмҠӨ 추мІң мғқнғңкі„мқҳ 진нҷ” кіјм •мқ„ 충분нһҲ л°ҳмҳҒн•ҳкё° мң„н•ҙ м—°кө¬нҢҖмқҖ кё°мЎҙ л¬ён—Ңм—җ л“ұмһҘн•ҳлҠ” м •лҹүм Ғ м§Җн‘ңлҘј мҡ”м•Ҫн•ҳкі лӢӨмқҢ 5к°Җм§Җ мёЎл©ҙм—җм„ң 비көҗм Ғ мҷ„м „н•ң нҸүк°Җ мӢңмҠӨн…ңмқ„ кө¬м¶•н–ҲмҠөлӢҲлӢӨ.
1 ) мўӢм•„мҡ” мҲҳ л°Ҹ Gini м§ҖмҲҳлҘј нҸ¬н•Ён•ң мғҒнҳёмһ‘мҡ©. Gini м§ҖмҲҳк°Җ лӮ®мқ„мҲҳлЎқ лҚ” лӮҳмқҖ кіөм •м„ұмқ„ лӮҳнғҖлғ…лӢҲлӢӨ.
2) м•Ңкі лҰ¬мҰҳ 추мІңмқҙ м Ғмҡ©лҗҳлҠ” мӮ¬мҡ©мһҗ мҲҳ л°Ҹ лүҙмҠӨлҘј нҸ¬н•Ён•ң м Ғмҡ© лІ”мң„; м ңн•ң мӢңк°„ лҸҷм•Ҳ лүҙмҠӨмқҳ нҸүк· н’Ҳм§Ҳ, мўӢм•„мҡ” мҲҳм—җ л”°лқј к°ҖмӨ‘м№ҳк°Җ л¶Җм—¬лҗң лүҙмҠӨ н’Ҳм§Ҳ, лүҙмҠӨ н’Ҳм§Ҳкіј мўӢм•„мҡ” мҲҳ мӮ¬мқҙмқҳ Pearson мғҒкҙҖ кі„мҲҳ
4) JaccardлҘј нҸ¬н•Ён•ң к· м§Ҳнҷ” мӮ¬мҡ©мһҗ к°„ м§ҖмҲҳ, к°’мқҙ лҶ’мқ„мҲҳлЎқ мӮ¬мҡ©мһҗ к°„ лүҙмҠӨ мқҪкё°мқҳ мӨ‘ліө м •лҸ„к°Җ лҶ’아집лӢҲлӢӨ.
5) мӮ¬мҡ©мһҗмҷҖ мўӢм•„н•ҳлҠ” лүҙмҠӨ к°„мқҳ мһ мһ¬ кіөк°„ н‘ңнҳ„ мҪ”мӮ¬мқё мң мӮ¬м„ұмқ„ нҸ¬н•Ён•ң мқјм№ҳ м •лҸ„.
1. лқјмқҙн”„ мӮ¬мқҙнҒҙ
лӢӨмқҢ м„ё к·ёлҰјмқҖ к°Ғк°Ғ лӢӨм–‘н•ң Agent н•ҳмқҙнҚјнҢҢлқјлҜён„° мЎ°кұҙм—җм„ң мӮ¬мҡ©мһҗ, м°Ҫмһ‘мһҗ, 추мІң мӢңмҠӨн…ңмқҳ м •лҹүм Ғ нҸүк°Җ кІ°кіјлҘј ліҙм—¬мӨҚлӢҲлӢӨ. simulation мӢң뮬л Ҳмқҙм…ҳ н”„лЎңм„ёмҠӨмҷҖ кІ°кіјлҠ” лӢӨм–‘н•ң н•ҳмқҙнҚј нҢҢлқјлҜён„°м—җм„ң, лҢҖлһө 10 лқјмҡҙл“ңмҷҖ 20 м„ёкё°м—җ 비көҗм Ғ м•Ҳм •м Ғмһ„мқ„ м•Ң мҲҳ мһҲмҠөлӢҲлӢӨ. лқјмҡҙл“ңлҠ” кө¬л¶„м„ (лӢӨм–‘н•ң м§Җн‘ңлҠ” м–ҙлҠҗ м •лҸ„ ліҖлҸҷн•Ё)мқҙл©° мӢңмҠӨн…ңмқҳ 진нҷ”лҠ” лӘ…нҷ•н•ң лӢЁкі„лҘј ліҙм—¬мӨҚлӢҲлӢӨ(лӢЁкі„ м „нҷҳмқҙ л°ңмғқн•ҳлҠ” лқјмҡҙл“ңлҠ” к·ёлҰјм—җм„ң нҢҢлһҖмғү мҲҳм§Ғм„ мңјлЎң н‘ңмӢңлҗЁ). мһҳ м•Ңл Ө진 мҲҳлӘ…мЈјкё° мқҙлЎ .
мІ« лІҲм§ё л°ңкІ¬мқҖ лӢӨмқҢкіј к°ҷмҠөлӢҲлӢӨ. 추мІң мӢңмҠӨн…ңмңјлЎң кө¬лҸҷлҗҳлҠ” мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°лҠ” лӢӨм–‘н•ң мӮ¬мҡ©мһҗ к·ёлЈ№м—җм„ң мһҗм—°мҠӨлҹҪкІҢ "м°Ҫм—…" - "м„ұмһҘ" - "м„ұмҲҷ л°Ҹ мҮ нҮҙ"мқҳ мҲҳлӘ…мЈјкё°лҘј ліҙм—¬мӨҚлӢҲлӢӨ.
2. мӮ¬мҡ©мһҗ м°Ёлі„нҷ”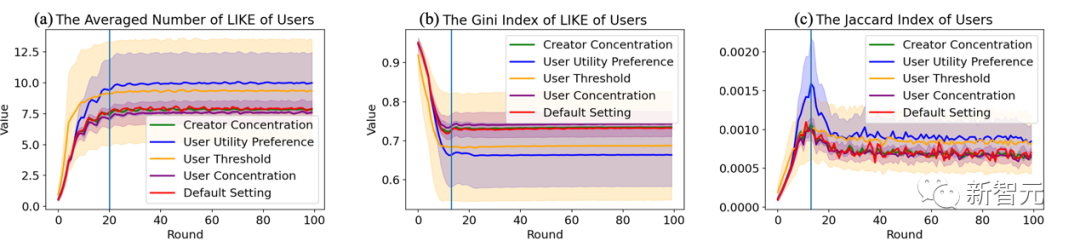
м •лҹүм Ғ м§Җн‘ң мҷём—җлҸ„ мӢңк°Ғнҷ”лҸ„ м»Өл®ӨлӢҲнӢ° л°ңм „ кіјм •мқ„ мқҙн•ҙн•ҳлҠ” лҚ° лҸ„мӣҖмқҙ лҗҳлҠ” мӨ‘мҡ”н•ң лҸ„кө¬мһ…лӢҲлӢӨ. 
м—°кө¬нҢҖмқҖ PCA м°Ёмӣҗ 축мҶҢ мӢңк°Ғнҷ”лҘј нҶөн•ҙ лӢӨмқҢкіј к°ҷмқҖ мӢңмҠӨн…ң 진нҷ” кіјм •мқҳ мҠӨлғ…мғ· м„ёнҠёлҘј м–»м—ҲмҠөлӢҲлӢӨ. (лүҙмҠӨлҠ” нҢҢлһҖмғүмңјлЎң н‘ңмӢңлҗҳкі , кё°лЎқмқҙ 비мҠ·н•ң мӮ¬мҡ©мһҗлҠ” л…№мғүмңјлЎң, кё°лЎқмқҙ м—ҶлҠ” мӮ¬мҡ©мһҗлҠ” л№Ёк°„мғүмңјлЎң н‘ңмӢңлҗ©лӢҲлӢӨ. л…ёл“ң size мўӢм•„мҡ”/мўӢм•„мҡ” мҲҳлҘј лӮҳнғҖлғ…лӢҲлӢӨ.

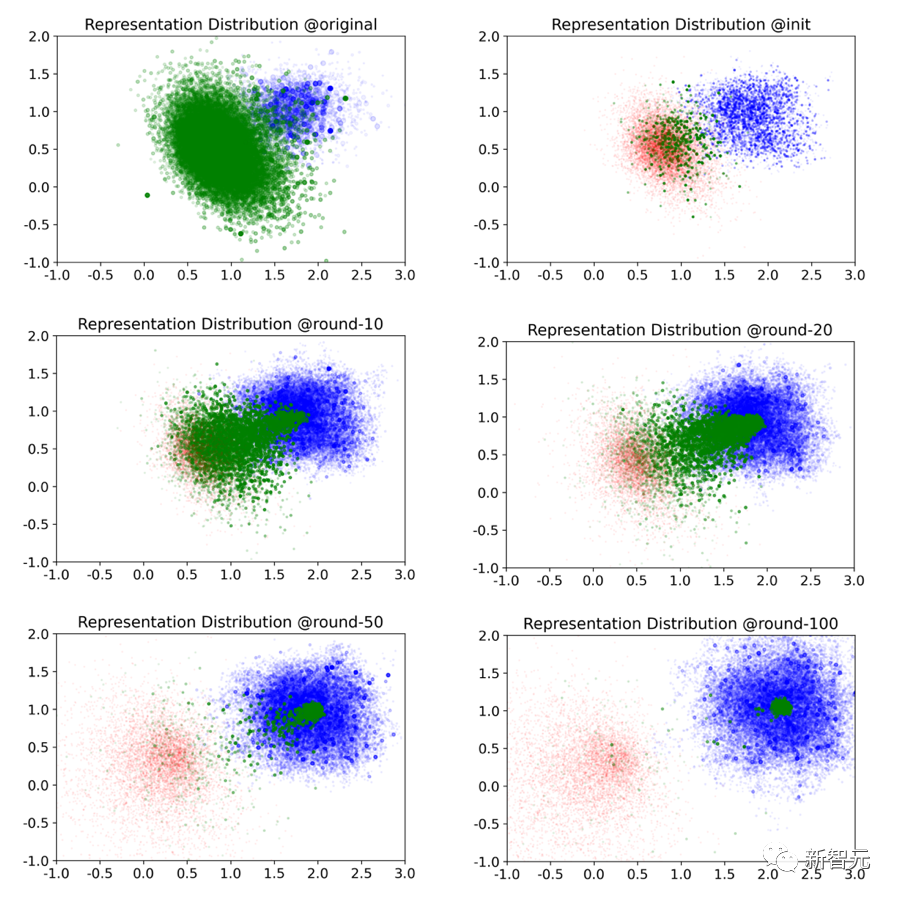
м •лҹүм Ғ м§Җн‘ңлҠ” лӢӨлӢЁкі„ нҢЁн„ҙмқ„ ліҙм—¬мЈјм§Җл§Ң мһ мһ¬кіөк°„ н‘ңнҳ„мқҳ 진нҷ” 추세лҠ” мқјкҙҖлҗЁмқ„ м•Ң мҲҳ мһҲлӢӨ. - лЈЁн”„ мӮ¬мҡ©мһҗ) л°Ҹ лЈЁн”„ мҷёл¶Җ мӮ¬мҡ©мһҗ.
м„ңнҒҙ лӮҙ мӮ¬мҡ©мһҗлҠ” кҙҖмӢ¬л¶„м•јк°Җ 집мӨ‘лҗҳм–ҙ м•Ҳм •м Ғмқё м»Өл®ӨлӢҲнӢ°лҘј нҳ•м„ұн•ҳлҠ” л°ҳл©ҙ, м„ңнҒҙ мҷёл¶Җ мӮ¬мҡ©мһҗлҠ” 분мӮ°лҗң кҙҖмӢ¬л¶„м•јлҘј ліҙмһ…лӢҲлӢӨ.
10лқјмҡҙл“ңм—җм„ң 20лқјмҡҙл“ң мӮ¬мқҙмқҳ 진нҷ” кіјм •м—җм„ң мӮ¬мҡ©мһҗлҠ” кё°ліём ҒмңјлЎң м°Ёлі„нҷ”лҘј мҷ„м„ұн–ҲлҠ”лҚ°, мқҙлҠ” м„ұмһҘ лӢЁкі„к°Җ мӮ¬мҡ©мһҗ м°ём—¬м—җ кІ°м •м Ғмқё м—ӯн• мқ„ н•ңлӢӨлҠ” кІғмқ„ ліҙм—¬мӨҚлӢҲлӢӨ.
мқҙкІғмқҖ л‘җ лІҲм§ё л°ңкІ¬мңјлЎң мқҙм–ҙ집лӢҲлӢӨ. 추мІң мӢңмҠӨн…ңм—җ мқҳн•ҙ кө¬лҸҷлҗҳлҠ” мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°лҠ” н•„м—°м ҒмңјлЎң м»Өл®ӨлӢҲнӢ° мЈјм ңмқҳ мңөн•©мқ„ лӮікі мӮ¬мҡ©мһҗмқҳ м°Ёлі„нҷ”лЎң мқҙм–ҙм§Ҳ кІғмһ…лӢҲлӢӨ. мӮ¬мҡ©мһҗ м°ём—¬лҘј кІ°м •н•ҳлҠ” мӨ‘мҡ”н•ң мӢңкё°лҠ” м„ұмһҘ лӢЁкі„мһ…лӢҲлӢӨ.
3. кҙҖмӢ¬ лҸҷнҷ”
м•һм„ң м–ёкёүн–Ҳл“Ҝмқҙ SimuLineмқҖ лҢҖк·ңлӘЁ мӮ¬м „ н•ҷмҠө м–ём–ҙ лӘЁлҚёмқ„ нҶөн•ҙ мһ мһ¬ кіөк°„мқ„ кө¬м¶•н•ҳлҜҖлЎң кіөк°„мқҳ к°Ғ лІЎн„°лҘј м „лӢ¬н• мҲҳ мһҲмҠөлӢҲлӢӨ. н…ҚмҠӨнҠё н•ҙм„қмқ„ мң„н•ң мң мӮ¬ лӢЁм–ҙ кІҖмғүмқ„ нҶөн•ҙ мӮ¬лЎҖ м—°кө¬лҘј нҶөн•ҙ к°ңлі„ мӮ¬мҡ©мһҗмқҳ 진нҷ”лҘј мқҙн•ҙн•ҳлҠ” лҚ° лҸ„мӣҖмқ„ мӨҚлӢҲлӢӨ.
м—°кө¬нҢҖмқҖ м„ңнҒҙ лӮҙ мӮ¬мҡ©мһҗмҷҖ м„ңнҒҙ мҷёл¶Җ мӮ¬мҡ©мһҗ мӨ‘м—җм„ң к°Ғк°Ғ 3лӘ…мқҳ мӮ¬мҡ©мһҗлҘј л¬ҙмһ‘мң„лЎң м„ нғқн–ҲмҠөлӢҲлӢӨ. м•„лһҳ н‘ңлҠ” мқҙл“Өмқҳ кҙҖмӢ¬л¶„м•ј ліҖнҷ”лҘј ліҙм—¬мӨҚлӢҲлӢӨ.
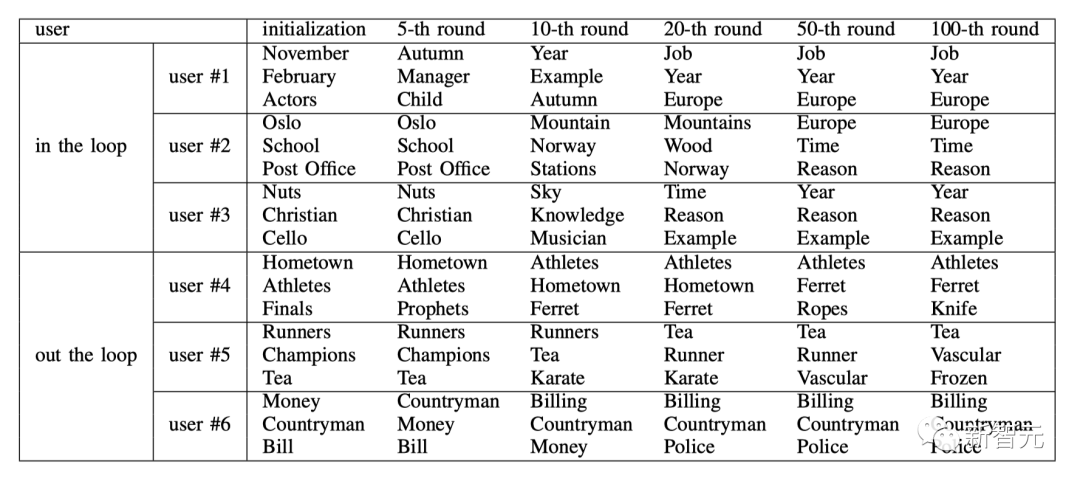
м„ңнҒҙм—җ мҶҚн•ң мӮ¬мҡ©мһҗмқҳ кҙҖмӢ¬мӮ¬лҠ” 'л°°мҡ°'м—җм„ң 'мқј'лЎң, 'мҳӨмҠ¬лЎң'м—җм„ң 'л…ёлҘҙмӣЁмқҙ'м—җм„ң 'мң лҹҪ'мңјлЎң м җм җ 추мғҒнҷ”лҗҳкі кҙ‘лІ”мң„н•ҙм§Җкі мқјл°ҳнҷ”лҗ©лӢҲлӢӨ. " ". мӮ¬мҡ©мһҗл§ҲлӢӨ 진нҷ” мҶҚлҸ„лҠ” лӢӨлҘҙм§Җл§Ң лӘЁл‘җ 50лқјмҡҙл“ңм—җм„ң мҲҳл ҙлҗ©лӢҲлӢӨ. мқҙлҹ¬н•ң нҳ„мғҒмқҖ 추мІң мӢңмҠӨн…ңкіјмқҳ м§ҖмҶҚм Ғмқё мғҒнҳё мһ‘мҡ©мқҳ кІ°кіјлЎң мӮ¬мҡ©мһҗмқҳ м„ нҳёлҸ„к°Җ к°ңмқёнҷ”лҗң нӢҲмғҲ мЈјм ңм—җм„ң н”Ңлһ«нҸјм—җм„ң л„җлҰ¬ л…јмқҳлҗҳлҠ” нҠёл Ңл“ң мЈјм ңлЎң м җ진м ҒмңјлЎң мқҙлҸҷн•ҳлҠ” кІғмқ„ л°ҳмҳҒн•©лӢҲлӢӨ.
м„ңнҒҙ мҷёл¶Җ мӮ¬мҡ©мһҗмқҳ кІҪмҡ° кҙҖмӢ¬л¶„м•јк°Җ мЎ°кёҲм”© л°”лҖҢм§Җл§Ң н•ӯмғҒ кө¬мІҙм Ғмқҙкі к°ңмқёнҷ”лҗң мЈјм ңм—җ 집мӨ‘н•©лӢҲлӢӨ. мҳҲлҘј л“Өм–ҙ, мӮ¬мҡ©мһҗ 4лІҲкіј 6лІҲмқҖ мӢң뮬л Ҳмқҙм…ҳ н”„лЎңм„ёмҠӨ м „л°ҳм—җ кұёміҗ к°Ғк°Ғ "мҡҙлҸҷм„ мҲҳ", "м°Ё" л°Ҹ "мІӯкө¬м„ң"м—җ кҙҖмӢ¬мқ„ мң м§Җн–ҲмҠөлӢҲлӢӨ.
мқҙкІғмқҖ м„ё лІҲм§ё л°ңкІ¬мңјлЎң мқҙм–ҙ집лӢҲлӢӨ. 추мІң мӢңмҠӨн…ңм—җ мқҳн•ҙ кө¬лҸҷлҗҳлҠ” мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°м—җм„ңлҠ” 추мІң мӢңмҠӨн…ңкіјмқҳ м§ҖмҶҚм Ғмқё мғҒнҳё мһ‘мҡ©мқ„ нҶөн•ҙ мӮ¬мҡ©мһҗмқҳ к°ңмқёнҷ”лҗң кҙҖмӢ¬мӮ¬к°Җ лҸҷнҷ”лҗ©лӢҲлӢӨ.
4. мӢңмһ‘ лӢЁкі„
мң„мқҳ м„ё к°Җм§Җ к°•л Ҙн•ң лҸ„кө¬мқё м •лҹүм Ғ м§Җн‘ң, мӢңк°Ғнҷ” л°Ҹ н…ҚмҠӨнҠё лІҲм—ӯмқ„ мӮ¬мҡ©н•ҳм—¬ SimuLineмқҖ мӢңмҠӨн…ңмқҳ 진нҷ” кіјм •м—җ лҢҖн•ң нҸ¬кҙ„м Ғмқё л¬јлҰ¬м Ғ кІҖмӮ¬лҘј мҲҳн–үн• мҲҳ мһҲмҠөлӢҲлӢӨ. .
추мІңм ңлҸ„лҘј мӨ‘мӢ¬мңјлЎң н•ң мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°мқҳ 진нҷ”кіјм •мқҖ мғқм• мЈјкё°мқҙлЎ кіј мқјл§ҘмғҒнҶөн•ҳлҜҖлЎң, мғқм• мЈјкё°мқҳ кҙҖм җм—җм„ң мғқм• лӢЁкі„лі„лЎң м»Өл®ӨлӢҲнӢ°к°Җ м–ҙл–»кІҢ 진нҷ”н•ҳлҠ”м§Җ 분м„қн•ҙ ліҙмһҗ.
мҡ°м„ лҢҖлһө мІҳмқҢ 10лқјмҡҙл“ңм—җ н•ҙлӢ№н•ҳлҠ” мӢңмһ‘ лӢЁкі„лҘј 분м„қн•ҙ ліҙкІ мҠөлӢҲлӢӨ.
мӢңмҠӨн…ңмқҙ мІҳмқҢл¶Җн„° кө¬м¶•лҗҳм—Ҳкё° л•Ңл¬ём—җ 추мІң мӢңмҠӨн…ңм—җлҠ” мҙҲкё° лӢЁкі„м—җм„ң 추мІң м•Ңкі лҰ¬мҰҳмқ„ нӣҲл ЁмӢңнӮӨкё° мң„н•ң лҚ°мқҙн„°к°Җ л¶ҖмЎұн•©лӢҲлӢӨ. мқҙм—җ л”°лқј мқҙ лӢЁкі„м—җм„ңлҠ” мӮ¬мҡ©мһҗмқҳ мҪңл“ң мҠӨнғҖнҠё вҖӢвҖӢл¬ём ңлҘј н•ҙкІ°н•ҳкё° мң„н•ҙ л¬ҙмһ‘мң„ 추мІңкіј нңҙлҰ¬мҠӨнӢұ 추мІңмқ„ мӮ¬мҡ©н•ҳлҠ” кІғмқҙ мөңмҡ°м„ мһ…лӢҲлӢӨ.
추мІңмқ„ мң„н•ҙ лҚ” м •нҷ•н•ң м•Ңкі лҰ¬мҰҳмқ„ мӮ¬мҡ©н• мҲҳ м—Ҷкё° л•Ңл¬ём—җ мқҙ лӢЁкі„мқҳ 추мІң кІ°кіјлҠ” кҙҖмӢ¬ л§Өм№ӯ мёЎл©ҙм—җм„ң л§ҢмЎұмҠӨлҹҪм§Җ лӘ»н•ң кІҪмҡ°к°Җ л§ҺмҠөлӢҲлӢӨ. л”°лқјм„ң мқҙ лӢЁкі„мқҳ мң мӮ¬н•ң н–үлҸҷмқҖ мЈјлЎң лүҙмҠӨмқҳ н’Ҳм§Ҳм—җ мқҳн•ҙ мўҢмҡ°лҗ©лӢҲлӢӨ. мқҙлҠ” м •лҹүм Ғ м§Җн‘ңм—җ л°ҳмҳҒлҗ©лӢҲлӢӨ. мқҙлҠ” м—ҙкіјмқҳ к°•н•ң м–‘мқҳ мғҒкҙҖкҙҖкі„мһ…лӢҲлӢӨ.
н•ң лӢЁкі„ лҚ” лӮҳм•„к°Җ мҠӨнғҖнҠём—… лӢЁкі„м—җм„ң м»Өл®ӨлӢҲнӢ° л°ңм „мқҳ л‘җ к°Җм§Җ мЈјмҡ” мӣҗлҸҷл Ҙмқ„ м°ҫмқ„ мҲҳ мһҲмҠөлӢҲлӢӨ.
1) н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„, мҰү н’Ҳм§Ҳкіј мқёкё°лҠ” кёҚм •м Ғмқё мғҒкҙҖ кҙҖкі„лҘј кё°л°ҳмңјлЎң м„ңлЎңлҘј нҷҚліҙн•©лӢҲлӢӨ. мҰү, мўӢмқҖ кІғмқҙ мўӢмқ„мҲҳлЎқ лҚ” л§ҺмқҖ мӮ¬лһҢл“Өмқҙ мўӢм•„н• кІғмқҙкі , лҚ” л§ҺмқҖ мӮ¬лһҢл“Өмқҙ мўӢм•„н• мҲҳлЎқ мһ‘к°Җмқҳ нҳёк°җлҸ„к°Җ лҶ’아집лӢҲлӢӨ. мһ‘м„ұмһҗмқҳ мҶҢл“қмқҙ лҶ’мқ„мҲҳлЎқ лҚ” лӮҳмқҖ н’Ҳм§Ҳмқҳ лүҙмҠӨ ліҙлҸ„лҘј мһ‘м„ұн•ҳл ӨлҠ” лҸҷкё°к°Җ лҶ’아집лӢҲлӢӨ.
2) кҙҖмӢ¬ н’Ҳм§Ҳмқҳ нҳјлһҖ, мҰү мӮ¬мҡ©мһҗ кҙҖмӢ¬мқ„ м •нҷ•н•ҳкІҢ м¶”м •н•ҳкё° мң„н•ң 충분н•ң м–‘мқҳ лҚ°мқҙн„°лҘј 축м Ғн•ҳкё° м „; , 추мІң м•Ңкі лҰ¬мҰҳмқҖ н’Ҳм§Ҳ кё°л°ҳ нҸ¬мқёнҠёлҘј мӮ¬мҡ©н•©лӢҲлӢӨ. л§Ҳм№ҳ мӮ¬мҡ©мһҗмқҳ кҙҖмӢ¬ л•Ңл¬ём—җ н–үлҸҷмқҙ мң л°ңлҗң н–үлҸҷмңјлЎң нҳјлҸҷлҗҳлҠ” кІғмІҳлҹј л§җмһ…лӢҲлӢӨ. мқҙ л‘җ к°Җм§Җ мӣҗлҸҷл ҘмқҖ м„ңлЎңлҘј мҙү진н•ҳм—¬ мқёкё° мҪҳн…җмё м ңмһ‘мһҗк°Җ м җм°Ё мҰқк°Җн•ҳлҠ” кіјмһү л…ём¶ңмқ„ м–»мқ„ мҲҳ мһҲкІҢ н•ҳл©°(нҒ¬лҰ¬м—җмқҙн„° л°Ҹ лүҙмҠӨ м§ҖлӢҲ м§ҖмҲҳмқҳ мғҒмҠ№м—җ л°ҳмҳҒ), мӮ¬мҡ©мһҗмқҳ к°ңмқёнҷ”лҗң кҙҖмӢ¬м—җ лҢҖн•ң л§ҢмЎұлҸ„лҘј лҚ”мҡұ м••л°•н•©лӢҲлӢӨ(мӮ¬мҡ©мһҗмқҳ к°җмҶҢм—җ л°ҳмҳҒ). мўӢм•„н•ҳлҠ” лүҙмҠӨ мӮ¬мқҙмқҳ мһ мһ¬м Ғмқё кіөк°„м Ғ мң мӮ¬м„ұ). к·ёлҹ¬лӮҳ лҢҖл¶Җ분мқҳ мӮ¬мҡ©мһҗлҠ” м—¬м „нһҲ н–ҘмғҒлҗң лүҙмҠӨ н’Ҳм§Ҳмқҳ нҳңнғқмқ„ лҲ„лҰҙ мҲҳ мһҲмҠөлӢҲлӢӨ(мӮ¬мҡ©мһҗ мң мӮ¬ н–үлҸҷмқҳ м§ҖлӢҲ м§ҖмҲҳ к°җмҶҢлЎң л°ҳмҳҒ).
мҡ”м•Ҫн•ҳмһҗл©ҙ л„Ө лІҲм§ё л°ңкІ¬мқ„ м–»мқ„ мҲҳ мһҲмҠөлӢҲлӢӨ. мӢңмһ‘ лӢЁкі„м—җм„ң мӢңмҠӨн…ңмқҖ л¬ҙмһ‘мң„ 추мІңкіј кі н’Ҳм§Ҳ лүҙмҠӨлЎңл¶Җн„° мӮ¬мҡ©мһҗ кҙҖмӢ¬лҸ„лҘј м¶”м •н•ҳкё° мң„н•ң лҚ°мқҙн„°лҘј 축м Ғн•ҳм—¬ мҙҲкё° мӢңмһ‘ мӮ¬мҡ©мһҗ л¬ём ңлҘј н•ҙкІ°н•©лӢҲлӢӨ. н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„мҷҖ кҙҖмӢ¬ н’Ҳм§Ҳ нҳјлһҖмқҖ кіјлӢӨ л…ём¶ңмқ„ нҶөн•ҙ л§Өмҡ° мқёкё° мһҲлҠ” мҪҳн…җмё м ңмһ‘мһҗмқҳ м¶ңнҳ„м—җ кё°м—¬н•©лӢҲлӢӨ.
5. м„ұмһҘ лӢЁкі„
мӮ¬мҡ©мһҗ кҙҖмӢ¬лҸ„м—җ лҢҖн•ң 추мІң м•Ңкі лҰ¬мҰҳмқҳ м¶”м •мқҖ м җм җ лҚ” м •нҷ•н•ҙм§Җл©°, мқҙмҷҖ к°ҷмқҖ н–үмң„лҠ” м җм°Ё н’Ҳм§Ҳ мӨ‘мӢ¬м—җм„ң кҙҖмӢ¬ мӨ‘мӢ¬, н’Ҳм§Ҳ мқёкё°мҷҖмқҳ мғҒкҙҖкҙҖкі„лҠ” м җм°Ё м•Ҫн•ҙ집лӢҲлӢӨ. мӢң뮬л Ҳмқҙм…ҳ лқјмҡҙл“ң мҲҳк°Җ мҰқк°Җн•Ём—җ л”°лқј мҠӨнғҖнҠём—… кё°к°„ лҸҷм•Ҳ мғқм„ұлҗң лүҙмҠӨлҠ” м җм°Ё л§ҢлЈҢлҗҳкі м¶”мІң нӣ„ліҙм—җм„ң мІ нҡҢлҗ©лӢҲлӢӨ. лЁјм Җ кҙҖмӢ¬-н’Ҳм§Ҳ нҳјлһҖмқҙ мӮ¬лқјм§Җкё° мӢңмһ‘н•ҳкі м җм°Ё н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„к°Җ мөңмў… мў…лЈҢлҗ©лӢҲлӢӨ.
м„ұмһҘ лӢЁкі„м—җм„ңлҠ” к°Ғ м„ңнҒҙмқҳ мӮ¬мҡ©мһҗ мҳҒм—ӯм—җм„ң лүҙмҠӨ л°ҖлҸ„к°Җ кі лҘҙм§Җ м•ҠмҠөлӢҲлӢӨ. мЈјлҘҳ лүҙмҠӨ мЈјм ң л°©н–Ҙм—җм„ңлҠ” л°ҖлҸ„к°Җ лҶ’мқҖ л°ҳл©ҙ, лӢӨлҘё л°©н–Ҙм—җм„ңлҠ” л°ҖлҸ„к°Җ мғҒлҢҖм ҒмңјлЎң лӮ®мҠөлӢҲлӢӨ.
к·ё кІ°кіј, мӮ¬мҡ©мһҗк°Җ мўӢм•„н•ҳлҠ” лүҙмҠӨлҠ” нҶөкі„м ҒмңјлЎң мЈјлҘҳ лүҙмҠӨ мЈјм ңм—җ лҚ” к°Җк№Ңмҡё к°ҖлҠҘм„ұмқҙ лҶ’мҠөлӢҲлӢӨ. мқҙмҷҖ к°ҷмқҖ мң мӮ¬н•ң н–үлҸҷмқҳ лҜёл¬ҳн•ң нҺём°ЁлҠ” кі„мҶҚн•ҙм„ң лӮҳнғҖлӮҳл©°, м§ҖмҶҚм Ғмқё к°•нҷ” нҡЁкіјлЎң мӮ¬мҡ©мһҗ кҙҖмӢ¬лҸ„к°Җ м җм°Ё мЈјлҘҳ лүҙмҠӨ мЈјм ңлЎң мқҙлҸҷн•ҳкі мһҲмҠөлӢҲлӢӨ. .
л°ҳлҢҖлЎң, м„ңнҒҙ л°–мқҳ мӮ¬мҡ©мһҗлҠ” "мўӢм•„мҡ” м—ҶмқҢ - м•Ңкі лҰ¬мҰҳ 추мІңмқҙ мІҳлҰ¬н• мҲҳ м—ҶмқҢ - лӮ®мқҖ 추мІң м •нҷ•лҸ„ - мўӢм•„мҡ”лҠ” лҚ”мҡұ м ҒмқҢ"мқҙлқјлҠ” көҗм°© мғҒнғңм—җ л№ м§ҖкІҢ лҗ©лӢҲлӢӨ. лүҙмҠӨмқҳ н’Ҳм§Ҳ л•Ңл¬ём—җ л•Ңл•ҢлЎң лүҙмҠӨлҘј мўӢм•„н•ҳм§Җл§Ң 추мІң м•Ңкі лҰ¬мҰҳмқҖ лҚ°мқҙн„° мӢңк°„ м ңн•ң лӮҙм—җ кҙҖмӢ¬лҸ„лҘј м¶”м •н• л§ҢнҒј 충분н•ң лҚ°мқҙн„°лҘј 축м Ғн• мҲҳ м—ҶмҠөлӢҲлӢӨ. мўӢм•„мҡ” мҲҳм—җ л”°лҘё лүҙмҠӨ н’Ҳм§ҲмқҖ м–‘м§Ҳмқҳ лүҙмҠӨм—җ лҢҖн•ң мқёкё°к°Җ л–Ём–ҙм§Җл©ҙм„ң м „л°ҳм ҒмңјлЎң м•Ҳм •м ҒмңјлЎң мң м§Җлҗҳм—ҲмҠөлӢҲлӢӨ.
н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„к°Җ мў…лЈҢлҗҳл©ҙ мҪҳн…җмё м ңмһ‘мһҗлҠ” лҚ” мқҙмғҒ кіјлҸ„н•ң кҙҖмӢ¬мқ„ л°ӣмқ„ мҲҳ м—ҶкІҢ лҗҳм–ҙ м Җл„җлҰ¬мҰҳмқҳ м§Ҳмқҙ м Җн•ҳлҗ©лӢҲлӢӨ. н’Ҳм§Ҳм—җ лҜјк°җн•ң мӮ¬мҡ©мһҗлҠ” лҚ” мқҙмғҒ мўӢм•„н•ҳм§Җ м•Ҡмқ„ мҲҳ мһҲмңјл©° мқҙлЎң мқён•ҙ мӮ¬мҡ©мһҗ м Ғмҡ© лІ”мң„к°Җ к°җмҶҢн• мҲҳ мһҲмҠөлӢҲлӢӨ.
кІ°лЎ м ҒмңјлЎң лӢӨм„Ҝ лІҲм§ё л°ңкІ¬мқ„ м–»мқ„ мҲҳ мһҲмҠөлӢҲлӢӨ. м„ұмһҘ лӢЁкі„м—җм„ңлҠ” мӣҗ м•Ҳмқҳ мӮ¬мҡ©мһҗк°Җ 분нҸ¬ нҺём°Ёмқҳ мҳҒн–Ҙмқ„ л°ӣм•„ кіөнҶө мЈјм ңлЎң 진нҷ”н•ҳлҠ” л°ҳл©ҙ, мӣҗ мҷёл¶Җмқҳ мӮ¬мҡ©мһҗлҠ” көҗм°© мғҒнғңм—җ л№ м ё мӮ¬мҡ©мһҗк°Җ 분нҷ”. м җм җ лҚ” м •нҷ•н•ң м•Ңкі лҰ¬мҰҳ к¶ҢмһҘ мӮ¬н•ӯмңјлЎң мқён•ҙ н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„к°Җ мў…лЈҢлҗҳкі кІ°кіјм ҒмңјлЎң м»Өл®ӨлӢҲнӢ°лҠ” н’Ҳм§Ҳм—җ лҜјк°җн•ң мқјл¶Җ мӮ¬мҡ©мһҗлҘј мһғмҠөлӢҲлӢӨ.
6. м„ұмҲҷ л°Ҹ мҮ нҮҙ лӢЁкі„
м»Өл®ӨлӢҲнӢ°лҠ” лҢҖл¶Җ분мқҳ мЈјмҡ” м§Җн‘ңк°Җ м•Ҳм •нҷ”лҗҳлҠ” м„ұмҲҷ л°Ҹ мҮ нҮҙ лӢЁкі„м—җ л“Өм–ҙк°‘лӢҲлӢӨ.
мқҙ лӢЁкі„м—җм„ң м„ңнҒҙмқҳ мӮ¬мҡ©мһҗлҠ” кіөнҶө мЈјм ңмқҳ лІ„лё”м—җ лҸҷм ҒмңјлЎң мң м§Җлҗ©лӢҲлӢӨ. 비лЎқ лӢӨлҘё лүҙмҠӨлҘј нҒҙлҰӯн•ҳл©ҙ кҙҖмӢ¬мқҙ лІ„лё”мқҳ к°ҖмһҘмһҗлҰ¬лЎң мҳ®кІЁм§Ҳ мҲҳ мһҲм§Җл§Ң л°ҖлҸ„лЎң мқён•ҙ кі§ мӮ¬лқјм§Ҳ кІғмһ…лӢҲлӢӨ. м°Ёмқҙк°Җ мһҲмҠөлӢҲлӢӨ. мӨ‘м•ҷмңјлЎң лҸҢм•„к°‘лӢҲлӢӨ.
лүҙмҠӨм—җ лҢҖн•ң м§ҖлӢҲ м§ҖмҲҳлҠ” лҶ’мқҖ л°ҳл©ҙ, мҪҳн…җмё м°Ҫмһ‘мһҗмқҳ м§ҖлӢҲ м§ҖмҲҳлҠ” лӮ®мҠөлӢҲлӢӨ. мқҙлҠ” лҸҷмқјн•ң м°Ҫмһ‘мһҗк°Җ л§Ңл“ лүҙмҠӨлқјлҸ„ мқёкё°лҸ„м—җ нҒ° м°Ёмқҙк°Җ мһҲмқҢмқ„ ліҙм—¬мӨҚлӢҲлӢӨ.
нғҗмҡ•мҠӨлҹ¬мҡҙ мғқм„ұ л©”м»ӨлӢҲмҰҳ мҷём—җлҸ„ лүҙмҠӨ мғқм„ұ кіјм • мһҗмІҙк°Җ л§Өмҡ° л¬ҙмһ‘мң„м ҒмқҙлҜҖлЎң кұ°н’ҲлҸ„ мһҗм—°мҠӨлҹҪкІҢ нҷ•мһҘлҗҳлҠ” кІҪн–Ҙмқ„ ліҙмһ…лӢҲлӢӨ.
лІ„лё” нҷ•мһҘмңјлЎң мқён•ҙ лүҙмҠӨ нӣ„ліҙмһҗк°Җ лҚ”мҡұ лӢӨм–‘н•ҙм§Җкі , мЈјм ңм—җ лҜјк°җн•ң мқјл¶Җ мӮ¬мҡ©мһҗмқҳ нғҲнҮҙлҸ„ м җм°Ё л°ңмғқн•©лӢҲлӢӨ.
м—¬кё°м„ң м—¬м„Ҝ лІҲм§ё л°ңкІ¬мқ„ м–»мқ„ мҲҳ мһҲмҠөлӢҲлӢӨ. м„ұмҲҷ л°Ҹ мҮ нҮҙ лӢЁкі„м—җм„ң м„ңнҒҙмқҳ мӮ¬мҡ©мһҗлҠ” кіөнҶө мЈјм ңлҘј кіөмң н•ҳкі мҪҳн…җмё м ңмһ‘мһҗлҠ” мқҙлҹ¬н•ң мЈјм ңм—җ лҢҖн•ң лӢӨм–‘н•ң лүҙмҠӨлҘј кІҢмӢңн•©лӢҲлӢӨ. м»Өл®ӨлӢҲнӢ°лҠ” м•Ҳм •м Ғмқҙкі лҠҗлҰ° нҷ•мһҘмқ„ мң м§Җн•ҙмҷ”м§Җл§Ң лҸҷмӢңм—җ кҙҖмӢ¬л¶„м•јм—җ лҜјк°җн•ң мқјл¶Җ мӮ¬мҡ©мһҗлҘј мһғм—ҲмҠөлӢҲлӢӨ.
7. 진нҷ”лҠ” м–ҙл–»кІҢ мқјм–ҙлӮҳлҠ” кұёк№Ңмҡ”?
Discovery 1л¶Җн„° Discovery 6к№Ңм§Җ м—°кө¬нҢҖмқҙ 집мӨ‘н•ң мІ« лІҲм§ё м—°кө¬ м§Ҳл¬ём—җ лӢөн•ҳм„ёмҡ”. лүҙмҠӨ 추мІң мғқнғңкі„(NRE)мқҳ мҲҳлӘ… мЈјкё° к°Ғ лӢЁкі„мқҳ нҠ№м§•мқҖ л¬ҙм—Үмқёк°Җмҡ”?
лӢӨмқҢмңјлЎң лӘЁл“ м§ҖмӢқмқ„ мў…н•©н•ҳм—¬ л‘җ лІҲм§ё м—°кө¬ м§Ҳл¬ёмқё NREмқҳ 진нҷ”лҘј мқҙлҒ„лҠ” н•өмӢ¬ мҡ”мҶҢлҠ” л¬ҙм—Үмқҙл©° мқҙлҹ¬н•ң мҡ”мҶҢк°Җ м–ҙл–»кІҢ мғҒнҳё мһ‘мҡ©н•ҳм—¬ 진нҷ” кіјм •м—җ мҳҒн–Ҙмқ„ лҜём№ҳлҠ”к°Җм—җ лҢҖн•ҙ лӢөн•ҙ ліҙкІ мҠөлӢҲлӢӨ.
лӢӨмқҢ к·ёлҰјмқҖ мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ° 진нҷ”мқҳ н•өмӢ¬ мҡ”мҶҢмҷҖ мҳҒн–Ҙ л©”м»ӨлӢҲмҰҳмқ„ мҡ”м•Ҫн•©лӢҲлӢӨ. л…ём¶ң нҺён–Ҙкіј көҗм°© мғҒнғңмқҳ мһ¬м¶ңнҳ„мқҙ н•ҙлӢ№ м„ңнҒҙ лӮҙ мӮ¬мҡ©мһҗмқҳ лӢӨм–‘н•ң 진нҷ” 추세мқҳ м§Ғм ‘м Ғмқё мӣҗмқёмһ„мқ„ м•Ң мҲҳ мһҲмҠөлӢҲлӢӨ. к·ёлҰ¬кі мқҙлҠ” м„ңнҒҙ л°–мқҳ мӮ¬мҡ©мһҗлЎң мқҙм–ҙм§Җл©°, мқҙлҠ” лҚ”мҡұ мӮ¬мҡ©мһҗмқҳ м°Ёлі„нҷ”мҷҖ мЈјм ңмқҳ мңөн•©мңјлЎң мқҙм–ҙ집лӢҲлӢӨ.
лӢӨмӢң лӮҳнғҖлӮҳлҠ” л…ём¶ң нҺён–ҘмқҖ м—¬лҹ¬ мҡ”мқёмқҳ мЎ°н•©мңјлЎң мқён•ҙ л°ңмғқн•©лӢҲлӢӨ.
мҡ°м„ , м •ліҙ мқҙлЎ мқҳ кҙҖм җм—җм„ң 추мІң м•Ңкі лҰ¬мҰҳмқҖ м •ліҙ 압축 кіјм •мңјлЎң м„ӨлӘ…н• мҲҳ мһҲмңјл©°, мқҙлҠ” н•„м—°м ҒмңјлЎң лҚ°мқҙн„° м„ёнҠём—җ мһҗмЈј л“ұмһҘн•ҳлҠ” лүҙмҠӨ(мҰү, лүҙмҠӨ)к°Җ мқёкё° нҺён–ҘмңјлЎң мқҙм–ҙ집лӢҲлӢӨ. мўӢм•„мҡ”к°Җ л§Һмқ„мҲҳлЎқ) 추мІң м„ұлҠҘмқ„ н–ҘмғҒмӢңнӮӨкё° мң„н•ҙ лҚ” нҡЁмңЁм ҒмңјлЎң мҪ”л”©лҗ©лӢҲлӢӨ. м»Өл®ӨлӢҲнӢ°мқҳ 진нҷ” кіјм •мқ„ л°ҳмҳҒн•ҳл©ҙ, л„җлҰ¬ л…јмқҳлҗҳлҠ” кіөнҶө мЈјм ңк°Җ м•Ңкі лҰ¬мҰҳ 추мІң мұ„л„җм—җм„ң к°ңмқёнҷ”лҗң мЈјм ңмқҳ л…ём¶ң мһҗмӣҗмқ„ мһҘм•…н•ҳкІҢ лҗ кІғмқҙлқјлҠ” м җмқ„ л°ҳмҳҒн•©лӢҲлӢӨ.
л‘ҳм§ё, мҪҳн…җмё м°Ҫмһ‘мһҗмқҳ мҳҒлҰ¬ 추кө¬ м„ұкІ©мңјлЎң мқён•ҙ кіөмқөм Ғмқё мЈјм ңлҘј мӨ‘мӢ¬мңјлЎң лүҙмҠӨлҘј л§Ңл“ңлҠ” лҚ° лҚ” л§ҺмқҖ мқҳмҡ•мқҙ мһҲмңјл©°, мқҙлҠ” мһҗм—°мҠӨлҹҪкІҢ мқёкё° мһҲлҠ” мЈјм ңм—җм„ң к°ңмқёнҷ”лҗң мЈјм ңлЎң ліҙлҸ„ л°ҖлҸ„к°Җ к°җмҶҢн•ҳкІҢ лҗ©лӢҲлӢӨ. мқҙлҹ° мқҳлҜём—җм„ң, н”„лЎңм„ёмҠӨ м „л°ҳм—җ кұёміҗ л¬ҙмһ‘мң„ 추мІңмқҙ мӮ¬мҡ©лҗҳлҚ”лқјлҸ„ 분нҸ¬ нҺём°ЁлЎң мқён•ҙ м»Өл®ӨлӢҲнӢ°к°Җ мЈјм ң мҲҳл ҙ л°©н–ҘмңјлЎң л°ңм „н• мҲҳ мһҲмҠөлӢҲлӢӨ.
л§Ҳм§Җл§үмңјлЎң н•„н„° лІ„лё”кіј л…ём¶ң нҺён–ҘмқҖ м„ңлЎңлҘј мҙү진н•ҳм—¬ мӮ¬мҡ©мһҗ кҙҖмӢ¬лҸ„м—җ лҜёл¬ҳн•ң ліҖнҷ”лҘј к°Җм ёмҳөлӢҲлӢӨ. м•Ңкі лҰ¬мҰҳмқҖ мӮ¬мҡ©мһҗк°Җ кіјкұ°м—җ мўӢм•„н–ҲлҚҳ лүҙмҠӨлҘј кё°л°ҳмңјлЎң мң мӮ¬н•ң ліҙлҸ„лҘј 추мІңн•©лӢҲлӢӨ. лүҙмҠӨ л…ём¶ңмқҙ м ңн•ңлҗҳм–ҙ мһҲм–ҙ мӮ¬мҡ©мһҗк°Җ л…ём¶ң нҺён–Ҙмқ„ мқём§Җн•ҳкё°к°Җ лҚ” м–ҙл өмҠөлӢҲлӢӨ.
лҳҗн•ң, мқёкё° лүҙмҠӨм—җ лҢҖн•ң 추мІң мӢңмҠӨн…ңмқҳ нҺён–ҘмқҖ лӢӨм–‘н•ң 진нҷ” лӢЁкі„м—җм„ң лӢӨм–‘н•ң мҳҒн–Ҙмқ„ ліҙм—¬мӨҚлӢҲлӢӨ.
м°Ҫм—… лӢЁкі„м—җм„ңлҠ” кҙҖмӢ¬м§Ҳ нҳјлһҖмқҙ мһҲкі , лүҙмҠӨ н’Ҳм§Ҳкіј мқёкё° мӮ¬мқҙм—җ к°•н•ң мғҒкҙҖкҙҖкі„к°Җ мһҲмңјл©°, мқёкё° нҺён–ҘмқҖ нҠ№нһҲ кі н’Ҳм§Ҳ лүҙмҠӨ л…ём¶ң к°•нҷ”м—җ л°ҳмҳҒлҗ©лӢҲлӢӨ.
лҚ°мқҙн„°к°Җ 축м Ғлҗҳкі м•Ңкі лҰ¬мҰҳ 추мІң м„ұлҠҘмқҙ н–ҘмғҒлҗҳл©ҙм„ң мң мӮ¬ н–үмң„к°Җ н’Ҳм§Ҳ мӨ‘мӢ¬ліҙлӢӨ кҙҖмӢ¬ мӨ‘мӢ¬мңјлЎң ліҖн•ҙ кҙҖмӢ¬-н’Ҳм§Ҳ нҳјлһҖкіј н’Ҳм§Ҳ-мқёкё° мғҒкҙҖ кҙҖкі„к°Җ м•Ҫнҷ”лҗ©лӢҲлӢӨ. мқёкё°нҺён–ҘлҸ„ м§Ҳ лҶ’мқҖ лүҙмҠӨлҘј 추мІңн•ҳлҠ” кІғм—җм„ң лӢЁмҲңнһҲ мқёкё°к°Җ лҶ’мқҖ лүҙмҠӨлҘј 추мІңн•ҳлҠ” кІғмңјлЎң м җм°Ё 진нҷ”н–ҲлӢӨ.
мқҙлҹ¬н•ң кё°мЎҙ 추진л Ҙкіј мғҲлЎңмҡҙ 추진л Ҙмқҳ м „нҷҳ кіјм •м—җм„ң мқёкё°к°Җ лҶ’кі мҲҳмӨҖ лҶ’мқҖ лүҙмҠӨ мЈјм ңлҘј мңЎм„ұн•ҳлҠ” кІғмқҖ мӮ¬мҡ©мһҗ м°ём—¬лҘј мҙү진н•ҳлҠ” лҚ° мӨ‘мҡ”н•ң м—ӯн• мқ„ н•©лӢҲлӢӨ.
кІ°лЎ м ҒмңјлЎң мқјкіұ лІҲм§ё л°ңкІ¬мқ„ м–»мқ„ мҲҳ мһҲмҠөлӢҲлӢӨ. мқёкё° нҺён–Ҙ, лүҙмҠӨ л°°нҸ¬ нҺён–Ҙ, н•„н„° лІ„лё”мқҙ н•Ёк»ҳ л…ём¶ң нҺён–ҘмңјлЎң мқҙм–ҙм§Җл©°, мқҙлҠ” мӮ¬мҡ©мһҗ м°Ёлі„нҷ”мҷҖ мЈјм ң мҲҳл ҙм—җ мҳҒн–Ҙмқ„ лҜём№ҳлҠ” н•өмӢ¬ мҡ”мҶҢмһ…лӢҲлӢӨ. мқёкё°к°Җ лҶ’мқҖ кі н’Ҳм§Ҳ лүҙмҠӨлҠ” м„ңнҒҙ мҷёл¶Җ мӮ¬мҡ©мһҗ к°„мқҳ көҗм°© мғҒнғңлҘј к№ЁлҠ” лҚ° мӨ‘мҡ”н•©лӢҲлӢӨ.
8. м»Өл®ӨлӢҲнӢ° мҮ нҮҙлҘј н”јн•ҳлҠ” л°©лІ•мқҖ л¬ҙм—Үмқёк°Җмҡ”?
л§Ҳм§Җл§үмңјлЎң SimuLineмқҳ к°•л Ҙн•ң мӢң뮬л Ҳмқҙм…ҳ л°Ҹ 분м„қ кё°лҠҘмқ„ мӮ¬мҡ©н•ҳм—¬ м„ё лІҲм§ё м—°кө¬ м§Ҳл¬ёмқё 추мІң мӢңмҠӨн…ңмқҳ м„Өкі„ м „лһөмқ„ нҶөн•ҙ лҚ” лӮҳмқҖ мһҘкё°м Ғ лӢӨмһҗк°„ нҡЁмңЁм„ұмқ„ лӢ¬м„ұн•ҳлҠ” л°©лІ•мқ„ нғҗмғүн•©лӢҲлӢӨ. к·ёлЎң мқён•ҙ м»Өл®ӨлӢҲнӢ°лҘј н”јн•ҳм—¬ "мҮ нҮҙ"н•ҳкІҢ лҗ©лӢҲк№Ң?
м—°кө¬нҢҖмқҖ к°ҖмһҘ кё°ліём Ғмқҙкі мқјл°ҳм Ғмқё нңҙлҰ¬мҠӨнӢұ 추мІң л°©лІ•мқё кө¬лҸ… кё°л°ҳ лүҙмҠӨ мҪңл“ң мҠӨнғҖнҠё, н•« кІҖмғү лӘ©лЎқ, мЈјм ң нҷҚліҙ, м°Ҫмһ‘мһҗ нҷҚліҙ л“ұ 4к°Җм§Җ л°©лІ•мқ„ н…ҢмҠӨнҠён–ҲмҠөлӢҲлӢӨ. лӢӨмқҢ м„ё к°Җм§Җ к·ёлҰјмқҖ мң„мқҳ л„Ө к°Җм§Җ л°©лІ•мқ„ кё°ліё 추мІң мӢңмҠӨн…ңм—җ м Ғмҡ©н•ң м»Өл®ӨлӢҲнӢ° 진нҷ” кІ°кіјлҘј лӮҳнғҖлғ…лӢҲлӢӨ.


(1) кө¬лҸ… кё°л°ҳ лүҙмҠӨ мҪңл“ң лҹ°м№ӯмқҖ мӮ¬мҡ©мһҗмҷҖ мҪҳн…җмё м°Ҫмһ‘мһҗ к°„мқҳ м•Ҳм •м Ғмқё көҗм°Ё л…ём¶ң кҙҖкі„лҘј нҳ•м„ұн•ҳм—¬ м¶ңмӢң лӢЁкі„лҘј н–ҘмғҒмӢңнӮӨл ӨлҠ” мӢңлҸ„мһ…лӢҲлӢӨ. н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„к°Җ лӮҳнғҖлӮ©лӢҲлӢӨ.
к·ёлҹ¬лӮҳ мқҙлҹ¬н•ң м ‘к·ј л°©мӢқмқҖ мӢ¬к°Ғн•ң лҸ…м җмқ„ мҙҲлһҳн–ҲмҠөлӢҲлӢӨ. м„ м җ мҡ°мң„лҘј лӢ¬м„ұн•ҳм§Җ лӘ»н•ң мҪҳн…җмё м ңмһ‘мһҗлҠ” н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„м—җ мқҳн•ҙ м–өм••лҗҳм–ҙ м•Ңкі лҰ¬мҰҳ м Ғмҡ© лІ”мң„мҷҖ лүҙмҠӨмқҳ нҸүк· н’Ҳм§Ҳмқ„ нҢҢкҙҙн•ҳм—¬ лүҙмҠӨмқҳ лӢӨм–‘м„ұмқ„ к°җмҶҢмӢңнӮөлӢҲлӢӨ. м „мІҙ м§Җм—ӯмӮ¬нҡҢ мғқнғңкі„к°Җ мӢ¬к°Ғн•ҳкІҢ мң„нҳ‘л°ӣкі мһҲмҠөлӢҲлӢӨ.
(2) н•« кІҖмғү лӘ©лЎқмқҖ к°ҖмһҘ мқјл°ҳм Ғмқё мҳЁлқјмқё м»Өл®ӨлӢҲнӢ° кө¬м„ұ мҡ”мҶҢлЎң, лүҙмҠӨ н’Ҳм§Ҳкіј мқёкё°лҸ„ к°„мқҳ кёҚм •м Ғмқё мғҒкҙҖ кҙҖкі„м—җ мқҳмЎҙн•©лӢҲлӢӨ. мқҙ л°©лІ•мқ„ мӮ¬мҡ©н•ҳл©ҙ мӮ¬мҡ©мһҗм—җкІҢ лҚ” лҶ’мқҖ н’Ҳм§Ҳмқҳ лүҙмҠӨ 추мІңмқ„ м ңкіөн• мҲҳ мһҲмҠөлӢҲлӢӨ. лҸҷмӢңм—җ нҷңмҡ©кіј нғҗкө¬мқҳ кҙҖм җм—җм„ң мҶҚліҙлҘј мқҪлҠ” кІғмқҖ мӮ¬мҡ©мһҗмқҳ кё°мЎҙ кҙҖмӢ¬мқҳ н•ңкі„лҘј лӣ°м–ҙл„ҳлҠ” мқјмў…мқҳ мӮ¬мҡ©мһҗ нғҗмғүмңјлЎң к°„мЈјлҗ мҲҳ мһҲмңјл©° мқҙлҠ” н•„н„° лІ„лё”мқҳ л¶Җм •м Ғмқё мҳҒн–Ҙмқ„ мӨ„мқҙлҠ” лҚ° лҸ„мӣҖмқҙ лҗ©лӢҲлӢӨ.
к·ёлҹ¬лӮҳ мқҙлҹ¬н•ң м ‘к·ј л°©мӢқмңјлЎңлҠ” мқҙм „ кё°мӮ¬м—җм„ң л…јмқҳн•ң мқёкё°мҷҖ н’Ҳм§Ҳмқҳ мғҒкҙҖ кҙҖкі„к°Җ 붕кҙҙлҗҳлҠ” кІғмқ„ л§үмқ„ мҲҳ м—Ҷмңјл©°, мқҙлҠ” мҶҚліҙ 추мІңмқҳ нҡЁмңЁм„ұмқҙ к°җмҶҢн•ҳлҠ” кІ°кіјлҘј лӮімҠөлӢҲлӢӨ.
(3) л§Ҳм§Җл§үмңјлЎң н”Ңлһ«нҸј нҷҚліҙк°Җ мһҲмҠөлӢҲлӢӨ. нҠ№м • мЈјм ңлӮҳ нҠ№м • мһ‘к°Җм—җ лҢҖн•ң 추к°Җ л…ём¶ңмқ„ м ңкіөн•ЁмңјлЎңмҚЁ н”Ңлһ«нҸјмқҖ 추мІң мҪҳн…җмё лҘј м Ғк·№м ҒмңјлЎң к·ңм ңн• мҲҳлҸ„ мһҲмҠөлӢҲлӢӨ. мҪҳн…җмё м°Ҫмһ‘мһҗлҘј нҷҚліҙн•ҳл©ҙ м•Ҳм •м Ғмқё л…ём¶ң кҙҖкі„лҘј кө¬м¶•н• мҲҳ мһҲкі , н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„лҘј нҷңмҡ©н•ҙ мқёкё°к°Җ лҶ’мқҖ кі н’Ҳм§Ҳ лүҙмҠӨлҘј мңЎм„ұн• мҲҳ мһҲмҠөлӢҲлӢӨ.
к·ёлҹ¬лӮҳ кө¬лҸ… кё°л°ҳ лүҙмҠӨ мҪңл“ң мҠӨнғҖнҠё вҖӢвҖӢм „лһөкіј лӢ¬лҰ¬ нҳ„мһ¬мқҳ н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„к°Җ н•ҙлЎңмҡҙ лҸ…м җмқ„ мЎ°м„ұн•ҳкё° м „м—җ н”„лЎңлӘЁм…ҳмқ„ м Ғк·№м ҒмңјлЎң мў…лЈҢн• мҲҳ мһҲмңјлҜҖлЎң мӮ¬мҡ©мһҗ кІҪн—ҳкіј м°Ҫмһ‘мһҗмқҳ м°Ҫмқҳм„ұмқҙ ліҙмһҘлҗ©лӢҲлӢӨ. кҙҖмӢ¬ л§Өм№ӯкіј л¬ҙкҙҖн•ң лүҙмҠӨ м „нҢҢ мұ„л„җлЎңм„ң н•„н„° лІ„лё”мқҳ л¶Җм •м Ғмқё мҳҒн–Ҙмқ„ мҷ„нҷ”н• мҲҳлҸ„ мһҲмҠөлӢҲлӢӨ. лҳҗн•ң н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„лҘј мһ¬кө¬м„ұн•ЁмңјлЎңмҚЁ мқёкё° лүҙмҠӨм—җ лҢҖн•ң 추мІң мӢңмҠӨн…ңмқҳ нҺён–Ҙмқ„ кі н’Ҳм§Ҳ лүҙмҠӨм—җ лҢҖн•ң мң мқөн•ң 추мІңмңјлЎң мң лҸ„н•©лӢҲлӢӨ.
SimuLineмқҖ нҠ№м • мЈјм ң нҷҚліҙлҘј лҢҖмғҒмңјлЎң н•ң мӢӨн—ҳм—җм„ң л¬ҙмһ‘мң„лЎң мЈјм ңлҘј м„ нғқн•ҳлҠ”лҚ°, мқҙлҠ” мқёкё° мЈјм ңмҷҖ л§һм¶Ө мЈјм ңк°Җ нҷҚліҙлҗ нҷ•лҘ мқҙ лҸҷмқјн•ҳлӢӨлҠ” кІғмқ„ мқҳлҜён•ҳлҜҖлЎң мғҒлҢҖм ҒмңјлЎң л…ём¶ңмқҙ м ҒмқҖ л§һм¶Ө мЈјм ңмқҳ кІҪмҡ° нҷҚліҙмқҳ мҳҒн–Ҙмқҙ мғҒлҢҖм ҒмңјлЎң мһ‘мҠөлӢҲлӢӨ.
мқҙ л°©лІ•мқҖ мқҙлЎ м ҒмңјлЎң м„ңнҒҙ мҷёл¶Җмқҳ мӮ¬мҡ©мһҗ м°ём—¬лҘј лҶ’мқҙлҠ” лҚ° мӮ¬мҡ©н• мҲҳ мһҲмҠөлӢҲлӢӨ. к·ёлҹ¬лӮҳ нҷҚліҙлҗң лүҙмҠӨмқҳ н’Ҳм§Ҳмқ„ ліҙмһҘн• мҲҳ м—Ҷкі л…ём¶ңлҹүмқ„ мўӢм•„мҡ” мҲҳлЎң нҷҳмӮ°н•ҳкё°к°Җ м–ҙл өкё° л•Ңл¬ём—җ мқҙ нҡЁкіјлҠ” лӢӨмқҢкіј к°ҷмҠөлӢҲлӢӨ. л°©лІ•мқҙ м ңн•ңлҗҳм–ҙ мһҲмҠөлӢҲлӢӨ.
кІ°лЎ м ҒмңјлЎң м—¬лҚҹ лІҲм§ё кІ°кіјлҘј м–»мқ„ мҲҳ мһҲмҠөлӢҲлӢӨ. мқјл°ҳм Ғмқё 추мІң мӢңмҠӨн…ң м„Өкі„ м „лһө мӨ‘ мҪҳн…җмё м ңмһ‘мһҗлҘј мң„н•ң мЈјкё°м Ғмқё н”„лЎңлӘЁм…ҳмқҙ к°ҖмһҘ нҡЁкіјм Ғмһ…лӢҲлӢӨ. кі н’Ҳм§Ҳ н”јл“ңл°ұ лЈЁн”„лҘј м Ғк·№м ҒмңјлЎң кө¬м¶•н•ЁмңјлЎңмҚЁ м»Өл®ӨлӢҲнӢ° м „мІҙм—җ мқёкё° мһҲкі кі н’Ҳм§Ҳ лүҙмҠӨ мЈјм ңмқҳ л¬јкІ°мқ„ л§Ңл“Ө мҲҳ мһҲмңјл©° н”Ңлһ«нҸјмқҖ м •кё°м Ғмқё мһ¬м„Өм •мқ„ нҶөн•ҙ лҸ…м җмқ„ м ңм–ҙн• мҲҳ мһҲмҠөлӢҲлӢӨ.
мҡ”м•Ҫ
ліё кёҖм—җм„ң CISL м—°кө¬м§„мқҖ лүҙмҠӨ 추мІң мғқнғңкі„мқҳ 진нҷ” кіјм •мқ„ 분м„қн•ҳкё° мң„н•ң мӢң뮬л Ҳмқҙм…ҳ н”Ңлһ«нҸјмқё SimuLineмқ„ м„Өкі„ л°Ҹ к°ңл°ңн–Ҳмңјл©°, мқҙлҘј кё°л°ҳмңјлЎң мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ°мқҳ 진нҷ” кіјм •мқ„ мғҒм„ён•ҳкІҢ 분м„қн–ҲлӢӨ. SimuLineм—җм„ң.
SimuLineмқҖ мқёк°„мқҳ н–үлҸҷмқ„ мһҳ л°ҳмҳҒн•ҳлҠ” мқҙн•ҙ к°ҖлҠҘн•ң мһ мһ¬ кіөк°„мқ„ кө¬м¶•н•ҳкі , мқҙлҘј кё°л°ҳмңјлЎң м—җмқҙм „нҠё кё°л°ҳ лӘЁлҚёл§Ғмқ„ нҶөн•ҙ лүҙмҠӨ 추мІң мғқнғңкі„м—җ лҢҖн•ң мғҒм„ён•ң мӢң뮬л Ҳмқҙм…ҳмқ„ мҲҳн–үн•©лӢҲлӢӨ.
м—°кө¬нҢҖмқҖ мҠӨнғҖнҠём—…, м„ұмһҘ, м„ұмҲҷ, мҮ нҮҙ лӢЁкі„лҘј нҸ¬н•Ён•ҳм—¬ мҳЁлқјмқё лүҙмҠӨ м»Өл®ӨлӢҲнӢ° 진нҷ”мқҳ м „мІҙ лқјмқҙн”„мӮ¬мқҙнҒҙмқ„ 분м„қн•ҳкі к°Ғ лӢЁкі„мқҳ нҠ№м„ұмқ„ 분м„қн•ҳлҠ” лҸҷмӢңм—җ, лүҙмҠӨ м»Өл®ӨлӢҲнӢ°мқҳ н•өмӢ¬ мҡ”мҶҢмҷҖ мҳҒн–Ҙмқ„ м„ӨлӘ…н•ҳлҠ” кҙҖкі„лҸ„лҘј м ңм•Ҳн–ҲмҠөлӢҲлӢӨ. 진нҷ” кіјм • л©”м»ӨлӢҲмҰҳ.
л§Ҳм§Җл§үмңјлЎң м—°кө¬нҢҖмқҖ кө¬лҸ… кё°л°ҳ лүҙмҠӨ мҪңл“ң мҠӨнғҖнҠё, н•« лүҙмҠӨ л°Ҹ н”Ңлһ«нҸј н”„лЎңлӘЁм…ҳ мӮ¬мҡ©мқ„ нҸ¬н•Ён•ҳм—¬ 추мІң мӢңмҠӨн…ң м„Өкі„ м „лһөмқҙ м»Өл®ӨлӢҲнӢ° 진нҷ”м—җ лҜём№ҳлҠ” мҳҒн–Ҙмқ„ мЎ°мӮ¬н–ҲмҠөлӢҲлӢӨ.
м•һмңјлЎң CISL м—°кө¬нҢҖмқҖ ліҙлӢӨ к°•л Ҙн•ҳкі нҳ„мӢӨм Ғмқё мӢң뮬л Ҳмқҙм…ҳмқ„ мҲҳн–үн•ҳкё° мң„н•ҙ лүҙмҠӨмқҳ н…ҚмҠӨнҠё мҪҳн…җмё мғқм„ұкіј мҶҢм…ң л„ӨнҠёмӣҢнҒ¬ нҷңлҸҷмқҳ н–үлҸҷ лӘЁлҚёл§Ғмқ„ кі л Өн• кІғмһ…лӢҲлӢӨ.
м—°кө¬нҢҖмқҖ SimuLineмқҙ лҚ°мқҙн„° м„ёнҠёлҘј кё°л°ҳмңјлЎң н•ң мҳЁлқјмқё мӮ¬мҡ©мһҗ мӢӨн—ҳ л°Ҹ мҳӨн”„лқјмқё мӢӨн—ҳ мҷём—җ м„ё лІҲм§ё мҳөм…ҳмқ„ м ңкіөн•ҳм—¬ 추мІң мӢңмҠӨн…ң нҸүк°ҖлҘј мң„н•ң нӣҢлҘӯн•ң лҸ„кө¬лЎңлҸ„ мӮ¬мҡ©лҗ мҲҳ мһҲлӢӨкі лҜҝмҠөлӢҲлӢӨ(мқҙкІғмқҙ SimuLineмқҙлқјлҠ” мқҙлҰ„мқ„ л¶ҷмқё мЈјлҗң мқҙмң мқҙкё°лҸ„ н•©лӢҲлӢӨ). .
м—°кө¬нҢҖмқҖ лҳҗн•ң 추мІң мӢңмҠӨн…ң м—°кө¬ м»Өл®ӨлӢҲнӢ°к°Җ мӮ¬мҡ©мһҗ м°Ёлі„нҷ”мҷҖ мЈјм ң мҲҳл ҙмқҳ м§Ғм ‘м Ғмқё мӣҗмқёмқҙкё°лҸ„ н•ң 추мІңмқҳ л…ём¶ң нҺён–Ҙ л¬ём ңлҘј н•ҙкІ°н•ҳкё° мң„н•ҙ мөңк·ј мқјл Ёмқҳ нҺён–Ҙ ліҙм • 추мІң м•Ңкі лҰ¬мҰҳмқ„ м ңм•Ҳн–ҲлӢӨлҠ” мӮ¬мӢӨм—җ мЈјлӘ©н–ҲмҠөлӢҲлӢӨ. .
ліё кёҖмқҖ кө¬мІҙм Ғмқё 추мІң м•Ңкі лҰ¬мҰҳліҙлӢӨлҠ” 추мІң мӢңмҠӨн…ңмқҳ мӢңмҠӨн…ң м„Өкі„м—җ лҢҖн•ҙ л…јмқҳн•ҳлҠ” лҚ° мҙҲм җмқҙ л§һм¶°м ё мһҲкё° л•Ңл¬ём—җ м—°кө¬нҢҖм—җм„ңлҠ” мқҙ л¬ём ңлҘј м—ҙлҰ° мЈјм ңлЎң лӮЁкІЁл‘җкі SimuLineмқҙ мқҙлҹ¬н•ң л°©н–Ҙмқҳ н–Ҙнӣ„ м—°кө¬лҘј м¶”м§„н• мҲҳ мһҲкё°лҘј л°”лһҚлӢҲлӢӨ.
мң„ лӮҙмҡ©мқҖ Fudan, 'лүҙмҠӨ 추мІң мғқнғңкі„ мӢң뮬л Ҳмқҙн„°' SimuLine м¶ңмӢң: лӢЁмқј мӢңмҠӨн…ңмңјлЎң лҸ…мһҗ 10,000лӘ…, мһ‘м„ұмһҗ 1,000лӘ…, 추мІң 100нҡҢ мқҙмғҒ м§Җмӣҗмқҳ мғҒм„ё лӮҙмҡ©мһ…лӢҲлӢӨ. мһҗм„ён•ң лӮҙмҡ©мқҖ PHP мӨ‘көӯм–ҙ мӣ№мӮ¬мқҙнҠёмқҳ кё°нғҖ кҙҖл Ё кё°мӮ¬лҘј м°ёмЎ°н•ҳм„ёмҡ”!

н•« AI лҸ„кө¬

Undresser.AI Undress
мӮ¬мӢӨм Ғмқё лҲ„л“ң мӮ¬м§„мқ„ л§Ңл“Өкё° мң„н•ң AI кё°л°ҳ м•ұ

AI Clothes Remover
мӮ¬м§„м—җм„ң мҳ·мқ„ м ңкұ°н•ҳлҠ” мҳЁлқјмқё AI лҸ„кө¬мһ…лӢҲлӢӨ.

Undress AI Tool
л¬ҙлЈҢлЎң мқҙлҜём§ҖлҘј лІ—лӢӨ

Clothoff.io
AI мҳ· м ңкұ°м ң

AI Hentai Generator
AI HentaiлҘј л¬ҙлЈҢлЎң мғқм„ұн•ҳмӢӯмӢңмҳӨ.

мқёкё° кё°мӮ¬
лңЁкұ°мҡҙ лҸ„кө¬

л©”лӘЁмһҘ++7.3.1
мӮ¬мҡ©н•ҳкё° мү¬мҡҙ л¬ҙлЈҢ мҪ”л“ң нҺём§‘кё°

SublimeText3 мӨ‘көӯм–ҙ лІ„м „
мӨ‘көӯм–ҙ лІ„м „, мӮ¬мҡ©н•ҳкё° л§Өмҡ° мүҪмҠөлӢҲлӢӨ.

мҠӨнҠңл””мҳӨ 13.0.1 ліҙлӮҙкё°
к°•л Ҙн•ң PHP нҶөн•© к°ңл°ң нҷҳкІҪ

л“ңлҰјмң„лІ„ CS6
мӢңк°Ғм Ғ мӣ№ к°ңл°ң лҸ„кө¬

SublimeText3 Mac лІ„м „
мӢ мҲҳмӨҖмқҳ мҪ”л“ң нҺём§‘ мҶҢн”„нҠёмӣЁм–ҙ(SublimeText3)
лңЁкұ°мҡҙ мЈјм ң
 1630
1630
 14
1357
52
1268
25
1216
29
14
1357
52
1268
25
1216
29

 ddrescueлҘј мӮ¬мҡ©н•ҳм—¬ Linuxм—җм„ң лҚ°мқҙн„° ліөкө¬
Mar 20, 2024 pm 01:37 PM
ddrescueлҘј мӮ¬мҡ©н•ҳм—¬ Linuxм—җм„ң лҚ°мқҙн„° ліөкө¬
Mar 20, 2024 pm 01:37 PM
DDREASEлҠ” н•ҳл“ң л“ңлқјмқҙлёҢ, SSD, RAM л””мҠӨнҒ¬, CD, DVD л°Ҹ USB м ҖмһҘ мһҘм№ҳмҷҖ к°ҷмқҖ нҢҢмқј лҳҗлҠ” лё”лЎқ мһҘм№ҳм—җм„ң лҚ°мқҙн„°лҘј ліөкө¬н•ҳкё° мң„н•ң лҸ„кө¬мһ…лӢҲлӢӨ. н•ң л