


Pacemaker는 Linux와 같은 운영 체제에 적합한 고가용성 클러스터 소프트웨어입니다. Pacemaker는 "클러스터 리소스 관리자"로 알려져 있으며 클러스터 노드 간의 리소스 장애 조치를 통해 클러스터 리소스의 최대 가용성을 제공합니다. Pacemaker는 클러스터 구성 요소 간의 하트비트 및 내부 통신에 Corosync를 사용합니다. Corosync는 클러스터의 투표(쿼럼)도 담당합니다.
시작하기 전에 다음이 있는지 확인하세요.
事不宜迟,让我们深入了解这些步骤。
在两个节点上的 /etc/hosts 文件中添加以下条目:
192.168.1.6node1.example.com192.168.1.7node2.example.com
在 RHEL 9/8 的默认包仓库中无法获取 Pacemaker 和其他必要的软件包。因此,我们必须启用高可用仓库。在两个节点上运行以下订阅管理器命令。
对于 RHEL 9 服务器:
$ sudo subscription-manager repos --enable=rhel-9-for-x86_64-highavailability-rpms
对于 RHEL 8 服务器:
$ sudo subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
启用仓库后,运行命令在两个节点上安装 pacemaker 包:
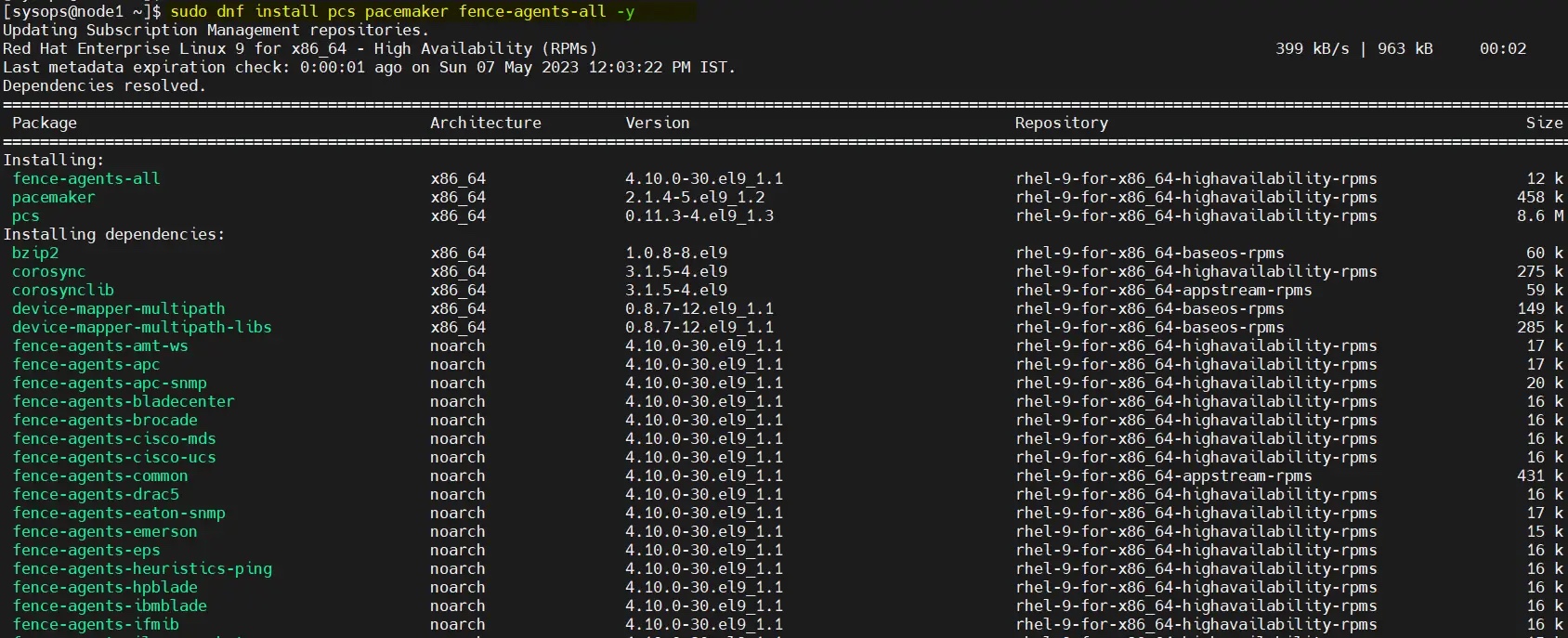
$ sudo dnf install pcs pacemaker fence-agents-all -y
要允许防火墙中的高可用端口,请在每个节点上运行以下命令:
$ sudo firewall-cmd --permanent --add-service=high-availability$ sudo firewall-cmd --reload
在两台服务器上为 hacluster 用户设置密码,运行以下 echo 命令:
$ echo "<Enter-Password>" | sudo passwd --stdin hacluster
执行以下命令在两台服务器上启动并启用集群服务:
$ sudo systemctl start pcsd.service$ sudo systemctl enable pcsd.service
使用 pcs 命令对两个节点进行身份验证,从任何节点运行以下命令。在我的例子中,我在 node1 上运行它:
$ sudo pcs host auth node1.example.com node2.example.com
使用 hacluster 用户进行身份验证。

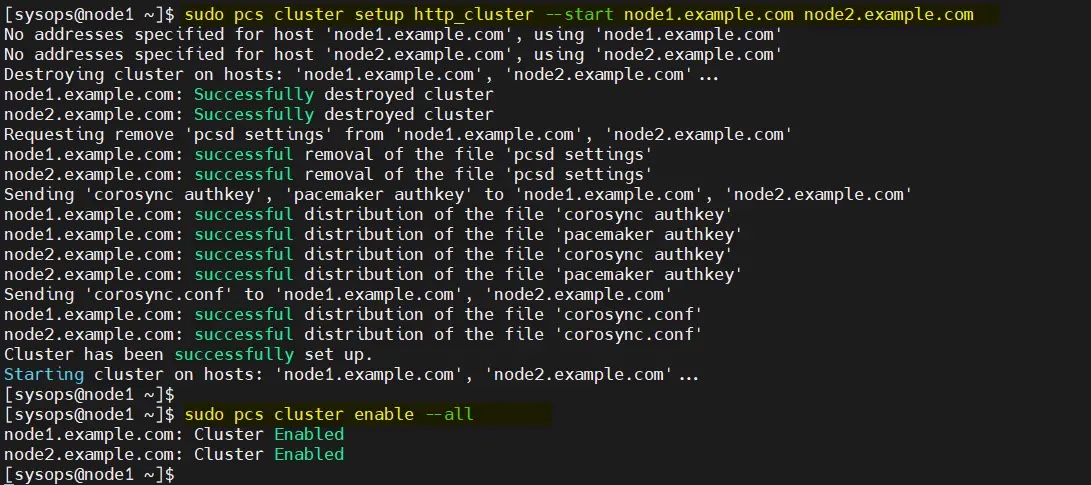
使用下面的 pcs cluster setup 命令将两个节点添加到集群,这里我使用的集群名称为 http_cluster。仅在 node1
/dev/sdb (2GB) 🎜🎜🎜더 이상 고민하지 않고 단계를 살펴보겠습니다. 🎜🎜1. 두 노드 모두에서 /etc/hosts 파일 🎜🎜을 업데이트합니다. /etc/hosts 파일에 다음 항목을 추가합니다: 🎜$ sudo pcs cluster setup http_cluster --start node1.example.com node2.example.com$ sudo pcs cluster enable --all
$ sudo pcs cluster status
$ sudo pcs property set stonith-enabled=false$ sudo pcs property set no-quorum-policy=ignore
pacemaker 패키지: 🎜$ sudo sed -i 's/# system_id_source = "none"/ system_id_source = "uname"/g' /etc/lvm/lvm.conf
 🎜
🎜$ sudo pvcreate /dev/sdb$ sudo vgcreate --setautoactivation n vg01 /dev/sdb$ sudo lvcreate -L1.99G -n lv01 vg01$ sudo lvs /dev/vg01/lv01$ sudo mkfs.xfs /dev/vg01/lv01
hacluster 다음 echo 명령: 🎜[sysops@node2 ~]$ sudo lvmdevices --adddev /dev/sdb
$ sudo dnf install -y httpd wget
pcs 명령 모든 노드에서 다음 명령을 실행하십시오. 내 경우에는 node1에서 실행: 🎜$ sudo firewall-cmd --permanent --zone=public --add-service=http$ sudo firewall-cmd --permanent --zone=public --add-service=https$ sudo firewall-cmd --reload
hacluster 사용자가 인증됩니다. 🎜🎜🎜🎜다음 pcs Cluster setup 명령은 클러스터에 두 개의 노드를 추가합니다. 여기서 사용하는 클러스터 이름은 http_cluster node1에서 명령을 실행합니다. 🎜$ sudo bash -c 'cat <<-END > /etc/httpd/conf.d/status.conf<Location /server-status>SetHandler server-statusRequire local</Location>END'$
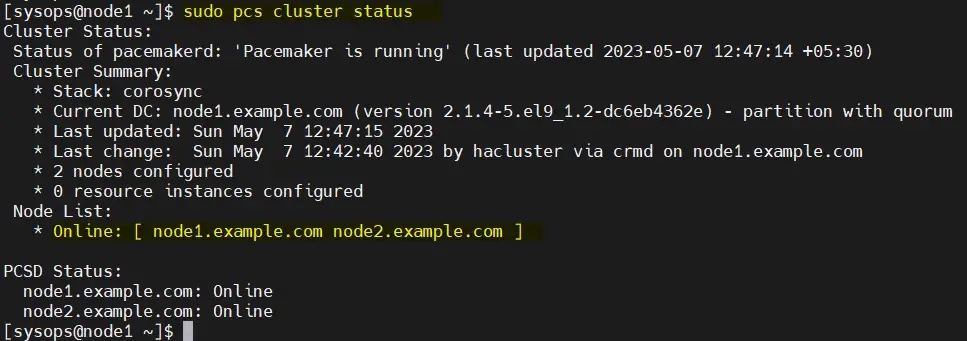
从任何节点验证初始集群状态:
$ sudo pcs cluster status
注意:在我们的实验室中,我们没有任何防护设备,因此我们将其禁用。但在生产环境中,强烈建议配置防护。
$ sudo pcs property set stonith-enabled=false$ sudo pcs property set no-quorum-policy=ignore
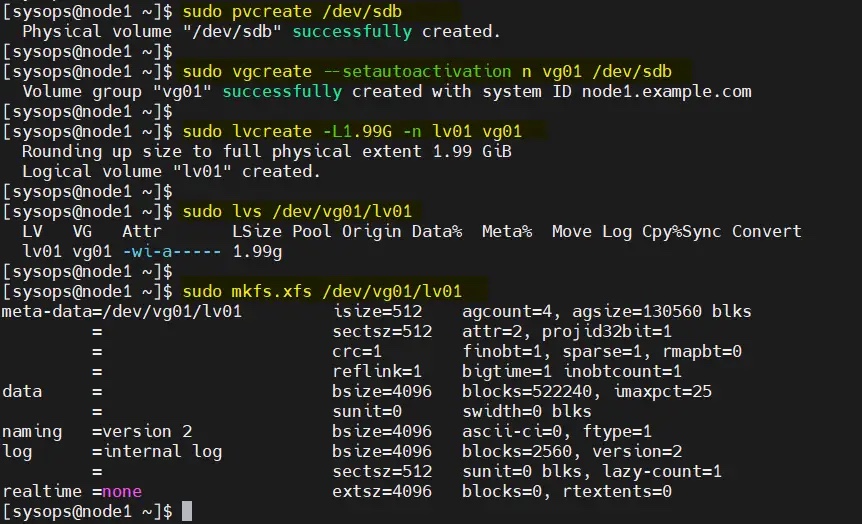
在服务器上,挂载了一个大小为 2GB 的共享磁盘(/dev/sdb)。因此,我们将其配置为 LVM 卷并将其格式化为 XFS 文件系统。
在开始创建 LVM 卷之前,编辑两个节点上的 /etc/lvm/lvm.conf 文件。
将参数 #system_id_source = "none" 更改为 system_id_source = "uname":
$ sudo sed -i 's/# system_id_source = "none"/ system_id_source = "uname"/g' /etc/lvm/lvm.conf
在 node1 上依次执行以下一组命令创建 LVM 卷:
$ sudo pvcreate /dev/sdb$ sudo vgcreate --setautoactivation n vg01 /dev/sdb$ sudo lvcreate -L1.99G -n lv01 vg01$ sudo lvs /dev/vg01/lv01$ sudo mkfs.xfs /dev/vg01/lv01
将共享设备添加到集群第二个节点(node2.example.com)上的 LVM 设备文件中,仅在 node2 上运行以下命令:
[sysops@node2 ~]$ sudo lvmdevices --adddev /dev/sdb
在两台服务器上安装 Apache web 服务器(httpd),运行以下 dnf 命令:
$ sudo dnf install -y httpd wget
并允许防火墙中的 Apache 端口,在两台服务器上运行以下 firewall-cmd 命令:
$ sudo firewall-cmd --permanent --zone=public --add-service=http$ sudo firewall-cmd --permanent --zone=public --add-service=https$ sudo firewall-cmd --reload
在两个节点上创建 status.conf 文件,以便 Apache 资源代理获取 Apache 的状态:
$ sudo bash -c 'cat <<-END > /etc/httpd/conf.d/status.conf<Location /server-status>SetHandler server-statusRequire local</Location>END'$
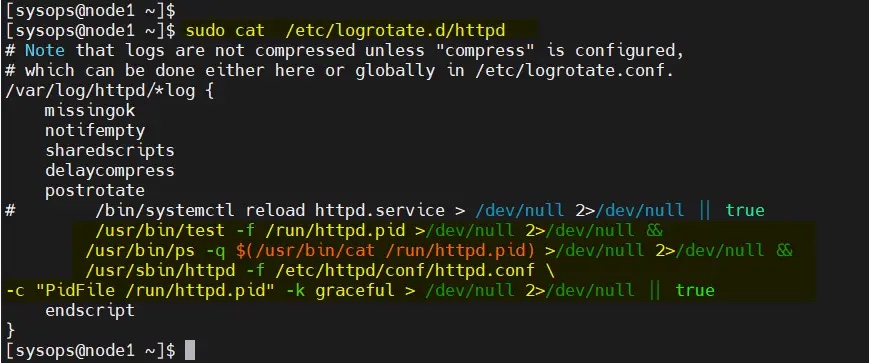
修改两个节点上的 /etc/logrotate.d/httpd:
替换下面的行
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
为
/usr/bin/test -f /run/httpd.pid >/dev/null 2>/dev/null &&/usr/bin/ps -q $(/usr/bin/cat /run/httpd.pid) >/dev/null 2>/dev/null &&/usr/sbin/httpd -f /etc/httpd/conf/httpd.conf \-c "PidFile /run/httpd.pid" -k graceful > /dev/null 2>/dev/null || true
保存并退出文件。
仅在 node1 上执行以下命令:
$ sudo lvchange -ay vg01/lv01$ sudo mount /dev/vg01/lv01 /var/www/$ sudo mkdir /var/www/html$ sudo mkdir /var/www/cgi-bin$ sudo mkdir /var/www/error$ sudo bash -c ' cat <<-END >/var/www/html/index.html<html><body>High Availability Apache Cluster - Test Page </body></html>END'$$ sudo umount /var/www
注意:如果启用了 SElinux,则在两台服务器上运行以下命令:
$ sudo restorecon -R /var/www
为集群定义资源组和集群资源。在我的例子中,我们使用 webgroup 作为资源组。
web_lvm 是共享 LVM 卷的资源名称(/dev/vg01/lv01)web_fs 是将挂载在 /var/www 上的文件系统资源的名称VirtualIP 是网卡 enp0s3 的 VIP(IPadd2)资源Website 是 Apache 配置文件的资源。从任何节点执行以下命令集。
$ sudo pcs resource create web_lvm ocf:heartbeat:LVM-activate vgname=vg01 vg_access_mode=system_id --group webgroup$ sudo pcs resource create web_fs Filesystem device="/dev/vg01/lv01" directory="/var/www" fstype="xfs" --group webgroup$ sudo pcs resource create VirtualIP IPaddr2 ip=192.168.1.81 cidr_netmask=24 nic=enp0s3 --group webgroup$ sudo pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group webgroup

现在验证集群资源状态,运行:
$ sudo pcs status
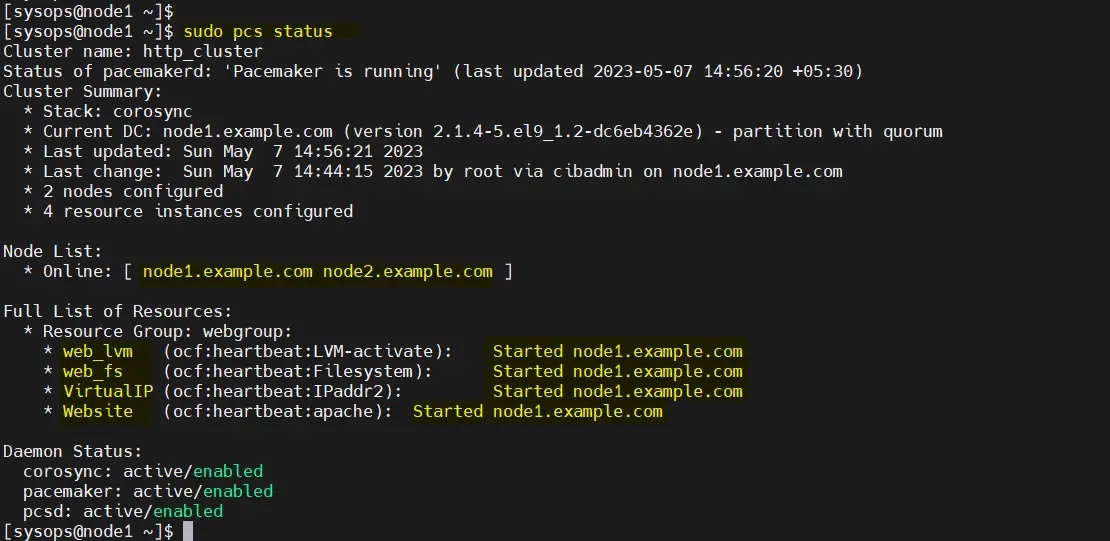
很好,上面的输出显示所有资源都在 node1 上启动。
尝试使用 VIP(192.168.1.81)访问网页。
使用 curl 命令或网络浏览器访问网页:
$ curl http://192.168.1.81

或者
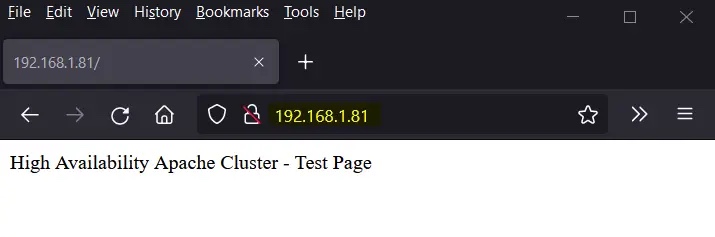
完美!以上输出确认我们能够访问我们高可用 Apache 集群的网页。
让我们尝试将集群资源从 node1 移动到 node2,运行:
$ sudo pcs node standby node1.example.com$ sudo pcs status

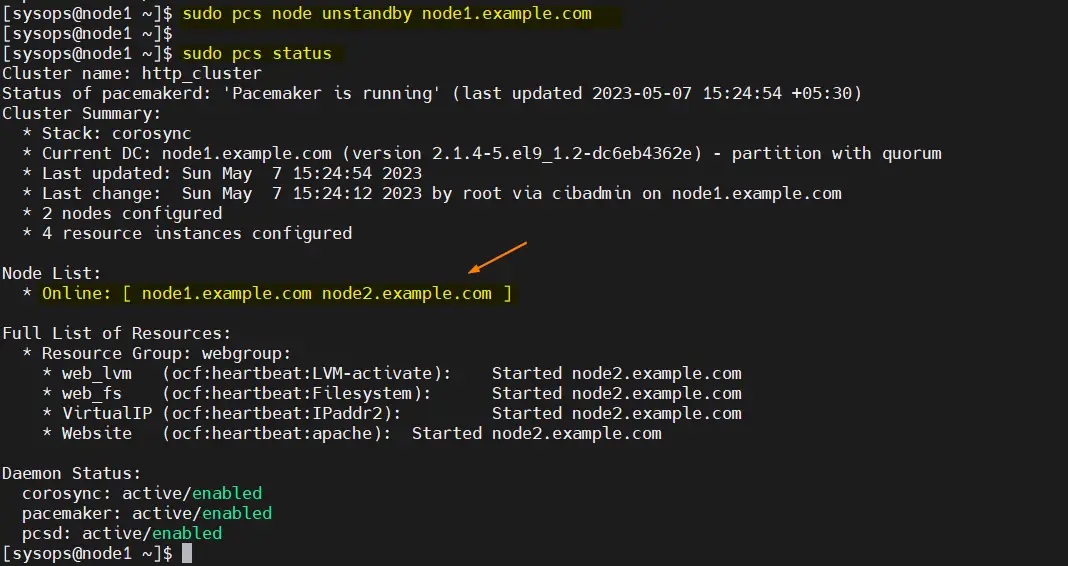
完美,以上输出确认集群资源已从 node1 迁移到 node2。
要从备用节点(node1.example.com)中删除节点,运行以下命令:
$ sudo pcs node unstandby node1.example.com
위 내용은 RHEL 9/8에서 고가용성 Apache(HTTP) 클러스터를 설정하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



