

대규모 언어 모델은 다양한 자연어 처리 작업에서 뛰어난 성능을 보여주었지만, 산술 문제는 현재 가장 강력한 GPT-4라도 기본적인 작업을 처리하기에는 여전히 어렵습니다.
최근 싱가포르 국립대학교 연구진이 산술 전용 모델인 Goat를 제안했습니다. LLaMA 모델을 기반으로 미세 조정한 끝에 GPT-4보다 훨씬 뛰어난 산술 성능을 달성했습니다.

논문 링크: https://arxiv.org/pdf/2305.14201.pdf
합성 산술 데이터 세트를 미세 조정하여 Goat는 BIG-bench 산술 하위 작업에서 좋은 성능을 발휘합니다. 최첨단 성능 달성
Goat는 감독된 미세 조정을 통해서만 큰 수 덧셈 및 뺄셈 연산에서 거의 완벽한 정확도를 달성할 수 있으며 Bloom, OPT, 그 중 GPT-NeoX는 샘플이 없는 Goat-7B가 몇 번의 학습 후에 PaLM-540을 능가하는 정확도를 달성한 것으로 연구원들은 LLaMA의 일관된 숫자 단어 분할 기술 덕분에 Goat의 뛰어난 성능을 꼽았습니다.
대수 곱셈, 나눗셈과 같은 더 어려운 작업을 해결하기 위해 연구원들은 산술의 학습 가능성에 따라 작업을 분류한 다음 기본 산술 원리를 사용하여 학습 불가능한 작업을 분류하는 방법도 제안했습니다. 여러 자리 곱셈과 나눗셈은 일련의 학습 가능한 작업으로 분류됩니다.
종합적인 실험 검증을 거친 후, 기사에서 제안한 분해 단계는 연산 성능을 효과적으로 향상시킬 수 있습니다.
그리고 Goat-7 B는 24GB VRAM GPU에서 LoRA를 사용하여 효율적으로 훈련할 수 있습니다. 다른 연구자들도 실험을 매우 쉽게 반복할 수 있습니다. 데이터 세트를 생성하는 데 필요한 모델, 데이터 세트 및 Python 스크립트는 곧 오픈 소스로 제공될 예정입니다.
셀 수 있는 언어 모델
언어 모델LLaMA은 공개적으로 사용 가능한 데이터 세트를 사용하여 수조 개의 토큰을 학습한 후 얻은 오픈 소스 사전 학습된 언어 모델 세트입니다. 여러 벤치마크에서 최고의 성능을 달성했습니다.
이전 연구 결과에 따르면 LLM의 산술 능력에는 토큰화가 중요하지만 일반적으로 사용되는 토큰화 기술로는 숫자를 잘 표현할 수 없습니다. 예를 들어 자릿수가 너무 많은 숫자는 분할될 수 있습니다.
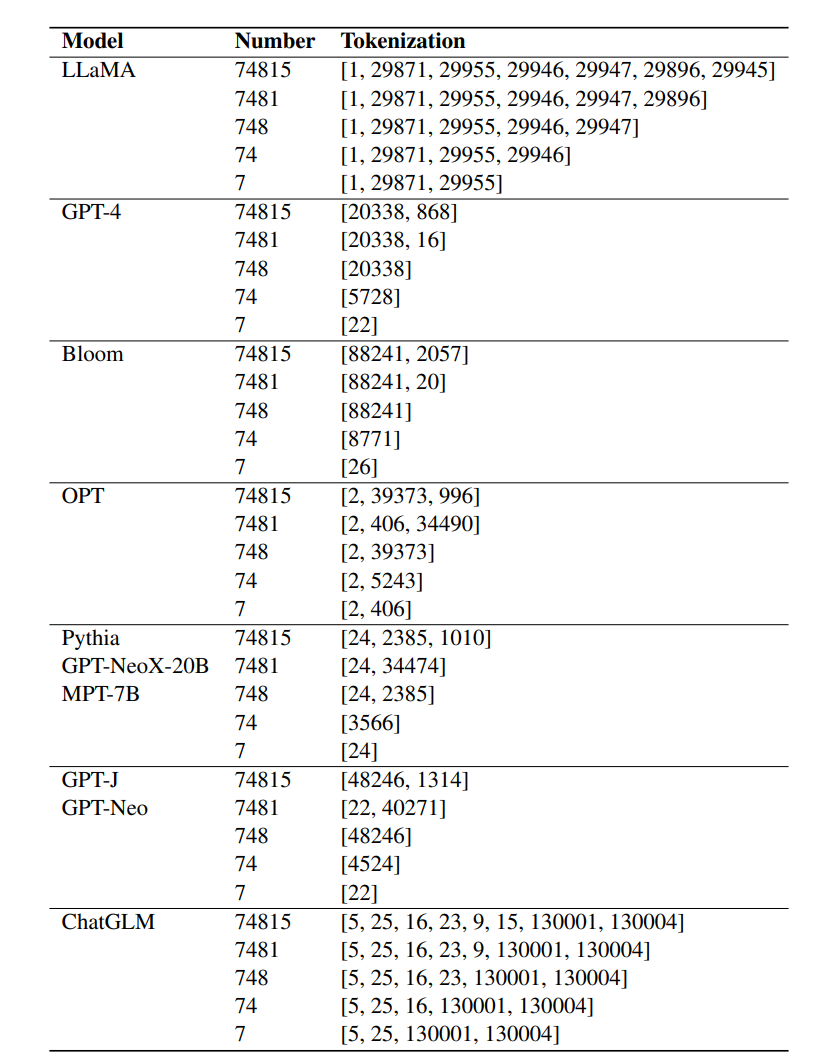 LLaMA는 디지털 표현의 일관성을 보장하기 위해 숫자를 여러 토큰으로 분할하기로 결정했습니다. 연구원들은 실험 결과에 나타난 뛰어난 산술 능력이 주로 LLaMA의 일관된 숫자 분할 때문이라고 믿습니다.
LLaMA는 디지털 표현의 일관성을 보장하기 위해 숫자를 여러 토큰으로 분할하기로 결정했습니다. 연구원들은 실험 결과에 나타난 뛰어난 산술 능력이 주로 LLaMA의 일관된 숫자 분할 때문이라고 믿습니다.
실험에서 Bloom, OPT, GPT-NeoX 및 Pythia와 같은 기타 미세 조정된 언어 모델은 LLaMA의 산술 기능과 일치하지 못했습니다.
산술 작업의 학습성
일부 연구자들은 이전에 중간 감독을 사용하여 복합 작업을 해결하는 것에 대한 이론적 분석을 수행했으며 결과에 따르면 이러한 종류의 작업은 학습할 수 없지만 간단한 하위 작업의 다항식 수.
즉, 학습 불가능한 복합 문제는 중간 감독 또는 CoT(Chain of Step)를 사용하여 학습할 수 있습니다.
이 분석을 바탕으로 연구자들은 먼저 학습 가능한 작업과 학습 불가능한 작업을 실험적으로 분류했습니다.
산술 컴퓨팅의 맥락에서 학습 가능한 작업은 일반적으로 모델이 성공적으로 훈련되어 답을 직접 생성할 수 있는 작업을 의미하며, 이를 통해 미리 정의된 훈련 시대 수 내에서 충분히 높은 정확도를 달성할 수 있습니다.
학습 불가능한 작업은 모델이 광범위한 훈련 후에도 올바르게 학습하고 직접적인 답변을 생성하는 데 어려움을 겪는 작업입니다.
작업 학습성이 변화하는 정확한 이유는 완전히 이해되지 않았지만 기본 패턴의 복잡성 및 작업을 완료하는 데 필요한 작업 메모리의 크기와 관련이 있다고 가정할 수 있습니다.
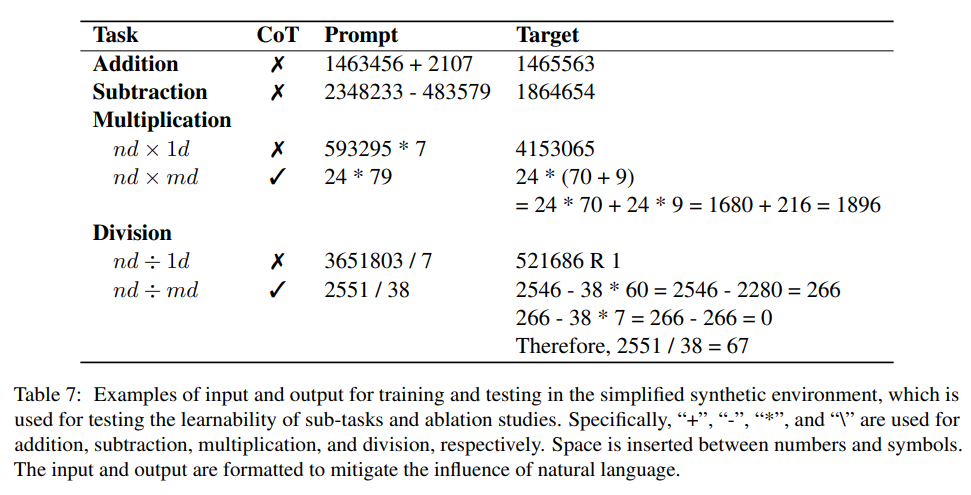
연구원들은 단순화된 합성 환경에서 각 작업에 맞게 모델을 구체적으로 미세 조정하여 이러한 작업의 학습 가능성을 실험적으로 조사했습니다.
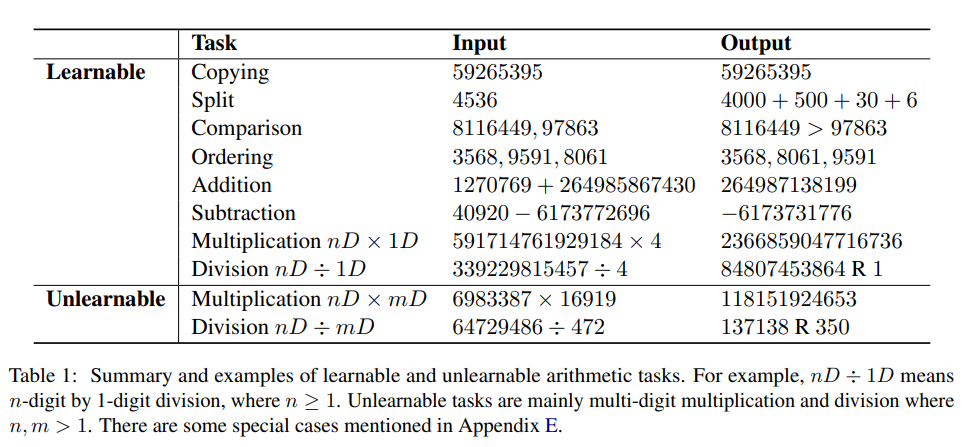
학습 가능한 작업과 학습 불가능한 작업
작업 분류의 결과도 인간의 인식과 동일합니다. 연습을 통해 인간은 마음속으로 두 개의 큰 숫자의 덧셈을 계산할 수 있습니다. 뺄셈의 경우, 손으로 계산할 필요 없이 왼쪽(최상위 숫자)에서 오른쪽(최하위 숫자)으로 직접 최종 숫자 답을 쓸 수 있습니다.
하지만 큰 수의 곱셈과 나눗셈을 푸는 암산은 어려운 작업입니다.
위의 작업 분류 결과도 GPT-4의 성능과 일치하는 것을 볼 수 있습니다. 특히 GPT-4는 다항식의 경우 큰 수 덧셈과 뺄셈에 대한 직접적인 답을 생성하는 데 능숙합니다. 숫자 곱셈 및 나눗셈 작업을 수행하면 정확도가 크게 떨어집니다.
GPT-4와 같은 강력한 모델이 학습 불가능한 작업을 직접 해결할 수 없다는 점은 광범위한 교육 후에도 이러한 작업에 대한 직접적인 답변을 생성하는 것이 극도로 어렵다는 것을 의미할 수도 있습니다.
LLaMA에서 학습 가능한 작업이 반드시 다른 LLM에서 학습 가능한 것은 아닐 수도 있다는 점은 주목할 가치가 있습니다.
또한 학습 불가능으로 분류된 모든 작업이 모델의 학습이 완전히 불가능한 것은 아닙니다.
예를 들어 두 자리 숫자를 두 자리 숫자로 곱하는 것은 학습 불가능한 작업으로 간주되지만 훈련 세트에 가능한 모든 두 자리 곱셈 열거 데이터가 포함되어 있으면 모델은 훈련 세트를 과적합하여 학습할 수 있습니다. . 직접 답변을 생성합니다.
그러나 약 90%의 정확도를 달성하려면 전체 프로세스에 거의 10세대가 필요합니다.
최종 답 앞에 기사에서 제안한 CoT를 삽입함으로써 모델은 1 에포크 훈련 후 두 자리 곱셈에서 상당히 좋은 정확도를 얻을 수 있으며 이는 이전 연구 결론, 즉 중간값과도 일치합니다. 감독이 있으면 학습 과정이 촉진됩니다.
더하기 및 빼기
이 두 가지 산술 연산은 학습 가능하며 감독된 미세 조정만으로도 모델은 직접적인 숫자 답을 정확하게 생성하는 놀라운 능력을 보여주었습니다.
모델은 매우 제한된 덧셈 데이터 하위 집합에 대해서만 학습되었지만 모델은 보이지 않는 테스트 세트에서 거의 완벽한 정확도를 달성했다는 사실에서 알 수 있듯이 산술 연산을 성공적으로 캡처합니다. CoT를 사용하여
Multiplication
연구원들은 n자리 곱셈과 1자리 곱셈은 학습 가능하지만 여러 자리 곱셈은 학습할 수 없다는 것을 실험적으로 확인했습니다.
이 문제를 극복하기 위해 연구원들은 답을 생성하기 전에 LLM을 미세 조정하여 CoT를 생성하고 여러 자리 곱셈을 학습 가능한 5개의 하위 작업으로 분해하기로 결정했습니다.
1 추출, 자연어에서 산술 표현식 추출. 지침
2. 둘 중 작은 값을 자릿수로 나눕니다
3. 분산 확장 및 합산 기반 확장
4. 각 항목을 동시에 계산
5. 이전 항을 추가하고, 나머지 항을 복사합니다. 최종 합계를 구합니다

각 작업은 학습 가능합니다.
Division
마찬가지로 n자리 숫자를 1자리 숫자로 나누는 것은 학습 가능하지만 여러 자리 나누기는 학습 가능하지 않다는 것을 실험적으로 관찰할 수 있습니다.
연구원들은 개선된 느린 나눗셈의 재귀 방정식을 사용하여 새로운 사고 체인 프롬프트를 설계했습니다.
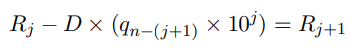
주요 아이디어는 나머지가 제수보다 작아질 때까지 피제수에서 제수의 배수를 빼는 것입니다.
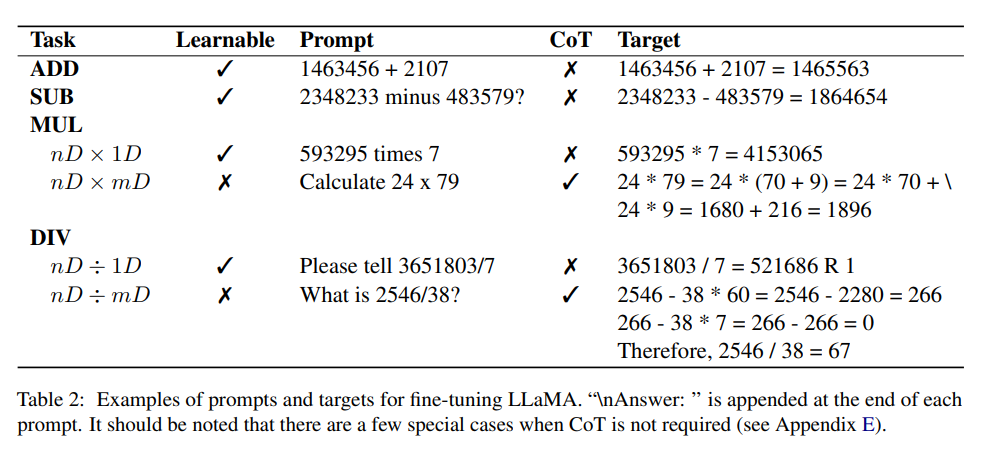
Dataset
문서에서 설계된 실험은 두 개의 양의 정수를 더하고 빼는 것입니다. 각 양의 정수는 최대 16자리를 포함하며 빼기 연산의 결과는 다음과 같습니다. 음수.
생성되는 최대 시퀀스 길이를 제한하기 위해 곱셈의 결과는 두 개의 양의 정수를 나눈 값이 12자리 이내이고 피제수는 12자리 미만이며 몫은 6자리 이내입니다.
연구원들은 Python 스크립트를 사용하여 데이터 세트를 합성하고 약 100만 개의 질문 및 답변 쌍을 생성했습니다. 답변에는 제안된 CoT와 최종 수치 출력이 포함되어 있어 반복 가능성이 보장됩니다. 인스턴스는 매우 낮지만 작은 숫자가 여러 번 샘플링될 수 있습니다.
Fine-tuning
모델이 지침을 기반으로 산술 문제를 해결하고 자연어 질문 응답을 용이하게 하기 위해 ChatGPT를 사용하여 수백 개의 지침 템플릿을 생성했습니다.
명령 조정 과정에서 훈련 세트의 각 산술 입력에 대해 템플릿이 무작위로 선택되고 Alpaca에서 사용되는 방법과 유사하게 LLaMA-7B가 미세 조정됩니다.

Goat-7B는 24GB VRAM GPU에서 LoRA를 사용하여 미세 조정할 수 있으며, A100 GPU에서 100,000개의 샘플을 완료하는 데 약 1.5시간밖에 걸리지 않고 거의 완벽한 정확도를 달성합니다.
GPT-4는 직접 답변을 생성하는 반면 Goat는 설계된 사고 체인에 의존하기 때문에 Goat와 GPT-4의 성능을 많은 수의 곱셈과 나눗셈 측면에서 비교하는 것은 불공평해 보입니다. GPT-4 평가 중에 각 프롬프트의 끝에 "단계별로 해결"도 추가되었습니다
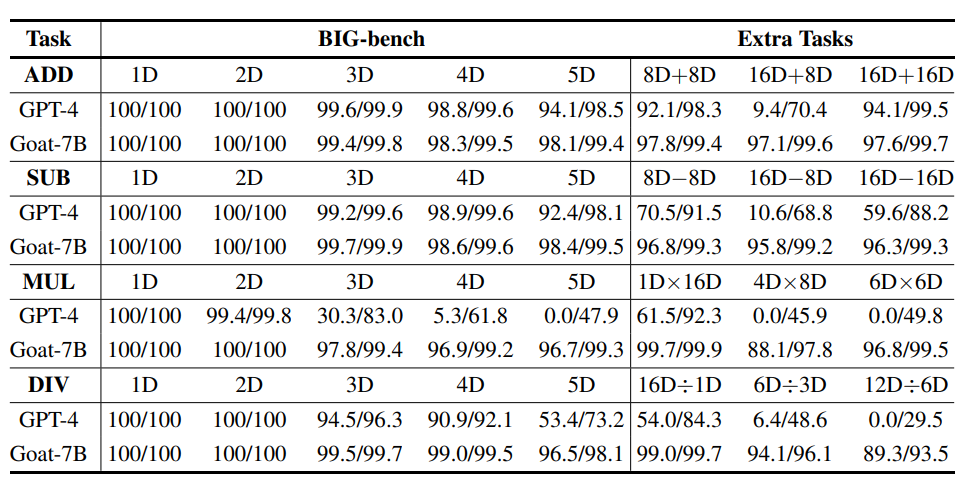
그러나 경우에 따라 GPT-4가 중간 단계를 수행하더라도 긴 곱셈과 나눗셈은 틀렸지만 최종 답은 여전히 정확합니다. 이는 GPT-4가 최종 출력을 개선하기 위해 사고 체인의 중간 감독을 사용하지 않음을 의미합니다.
GPT-4의 솔루션에서 최종적으로 확인된 3가지 일반적인 오류:
1 해당 숫자 정렬
2. 반복되는 숫자
3. n자리에 1자리를 곱한 중간 결과가 틀렸습니다
GPT-4가 8D+8D와 16D+에서 잘 작동하는 것을 볼 수 있습니다. 16D 작업 성능은 꽤 좋지만 대부분의 16D+8D 작업에서 계산 결과가 잘못되었습니다. 직관적으로는 16D+8D가 16D+16D보다 상대적으로 쉬울 것입니다.
이 문제의 정확한 원인은 알 수 없지만 한 가지 가능한 요인은 GPT-4의 일관되지 않은 숫자 분할 프로세스로 인해 두 숫자 사이를 정렬하기 어렵게 만드는 것일 수 있습니다.
위 내용은 산수능력은 만점에 가깝습니다! 싱가포르 국립대학교는 단 70억 개의 매개변수만으로 GPT-4를 죽이고 처음에는 16자리 곱셈과 나눗셈을 지원하는 Goat를 출시했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



