

대형 모델 기능이 등장하고 있습니다. 매개변수 규모가 클수록 좋습니다.
그러나 점점 더 많은 연구자들이 10B보다 작은 모델도 GPT-3.5와 비슷한 성능을 달성할 수 있다고 주장합니다.
정말 그런가요?
GPT-4를 출시하는 OpenAI 블로그에서는 다음과 같이 언급했습니다.
일상적인 대화에서는 GPT-3.5와 GPT-4의 차이가 매우 미묘할 수 있습니다. 작업의 복잡성이 충분한 임계값에 도달하면 차이점이 나타납니다. GPT-4는 GPT-3.5보다 더 안정적이고 창의적이며 더 미묘한 지침을 처리할 수 있습니다.
Google 개발자도 PaLM 모델에 대해 비슷한 관찰을 했습니다. 그들은 대형 모델의 사고 연쇄 추론 능력이 소형 모델의 그것보다 훨씬 더 강력하다는 것을 발견했습니다.
이러한 관찰은 모두 복잡한 작업을 수행하는 능력이 대형 모델의 역량을 구현하는 핵심임을 보여줍니다.
모델도 프로그래머도 마찬가지다. "쓸데없는 소리 그만하고 논리를 보여라"라는 옛말처럼요.

에든버러 대학교, 워싱턴 대학교, Allen AI 연구소의 연구원들은 복잡한 추론 능력이 미래에 대규모 모델을 더욱 지능적인 도구로 개발하기 위한 기초라고 믿습니다.
기본적인 텍스트 요약 능력, 대형 모델의 실행은 그야말로 "과녁으로 닭 죽이기"입니다.
이러한 기본 능력에 대한 평가는 향후 대형 모델의 발전을 연구하기에는 다소 비전문적이라고 생각됩니다.
논문 주소: https://arxiv.org/pdf/2305.17306.pdf
이것이 바로 연구자들이 복잡한 추론 작업 목록인 사고 사슬 허브를 작성하여 까다로운 추론 작업에서 모델의 성능을 측정한 이유입니다.
시험 항목에는 수학(GSM8K)), 과학(MATH, 정리 QA), 기호(BBH), 지식(MMLU, C-Eval), 코딩(HumanEval)이 포함됩니다.
이러한 테스트 프로젝트나 데이터 세트는 모두 대형 모델의 복잡한 추론 기능을 목표로 합니다. 누구나 정확하게 답할 수 있는 간단한 작업은 없습니다.
연구원들은 여전히 COT 프롬프트 방법을 사용하여 모델의 추론 능력을 평가합니다.
추론 능력 테스트에서 연구자들은 최종 답변의 성능만을 유일한 측정 기준으로 사용하며, 중간 추론 단계는 판단의 기초로 사용되지 않습니다.
아래 그림에 표시된 것처럼 다양한 추론 작업에 대한 현재 주류 모델의 성능입니다.
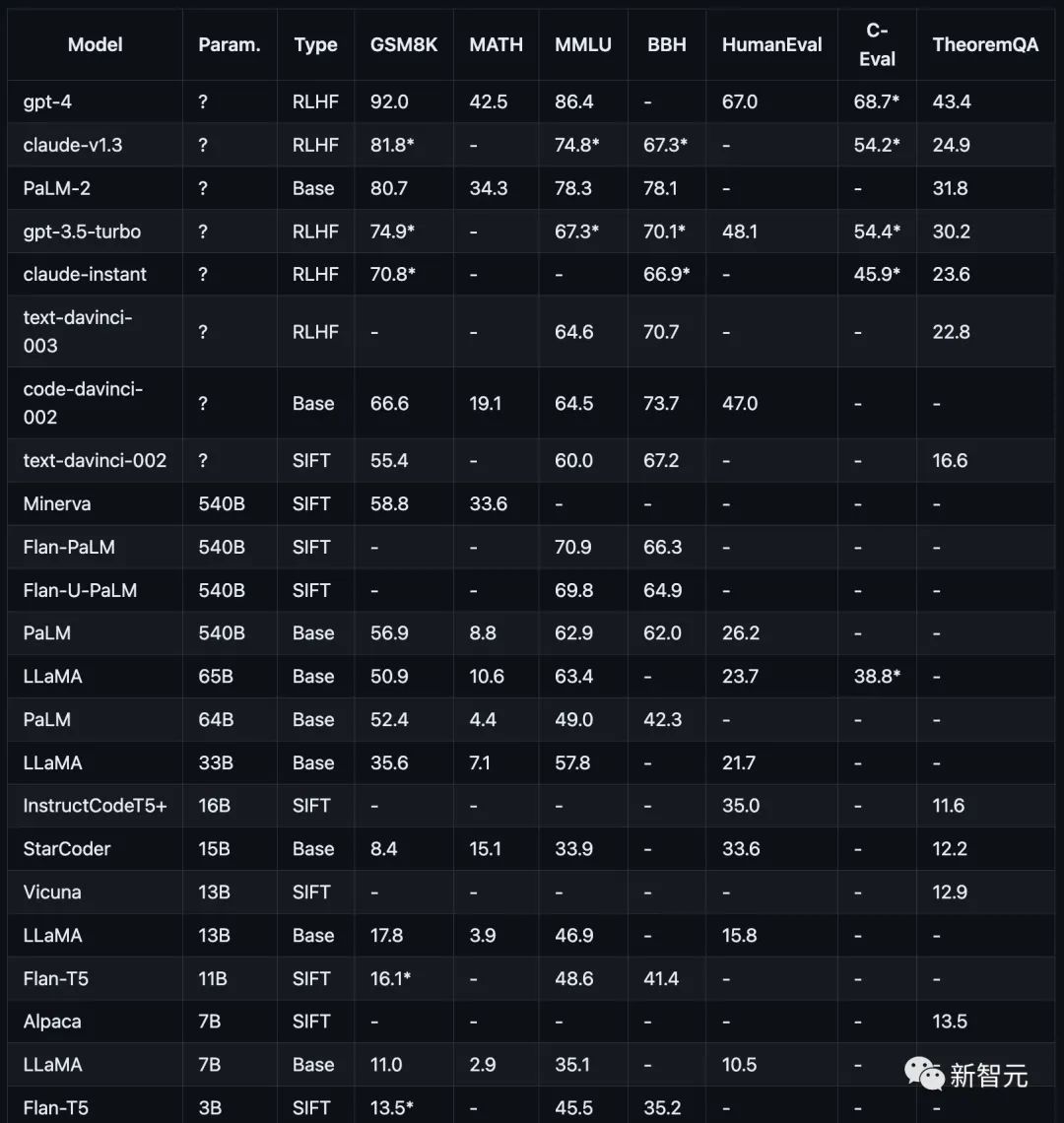
연구원의 연구는 GPT, Claude, PaLM, LLaMA 및 T5 모델 계열을 포함하여 현재 인기 있는 모델에 중점을 두고 있습니다.
OpenAI GPT에는 GPT-4(현재 가장 강력함), GPT3.5-Turbo(더 빠르지만 약함), text-davinci-003, text-davinci-002 및 code-davinci-002(Turbo 중요 버전 이전)가 포함됩니다. .

Anthropic Claude에는 claude-v1.3(느리지만 성능은 높음) 및 claude-instant-v1.0(빠르지만 성능은 낮음)이 포함되어 있습니다.
PaLM, PaLM-2 및 해당 지침 조정 버전(FLan-PaLM 및 Flan-UPaLM)을 포함한 Google PaLM, 강력한 기반 및 지침 조정 모델.

Meta LLaMA(7B, 13B, 33B 및 65B 변형 포함), 중요한 오픈 소스 기본 모델.
GPT-4는 GSM8K 및 MMLU의 다른 모든 모델보다 훨씬 뛰어난 성능을 발휘하며 Claude는 GPT 시리즈와 비교할 수 있는 유일한 모델입니다.
FlanT5 11B 및 LLaMA 7B와 같은 소형 모델은 훨씬 뒤쳐집니다.
실험을 통해 연구자들은 모델 성능이 일반적으로 규모와 관련되어 대략 로그 선형 추세를 보인다는 사실을 발견했습니다.
모수 척도를 공개하지 않는 모델은 일반적으로 척도 정보를 공개하는 모델보다 성능이 더 좋습니다.
에 가깝습니다. 또한 연구원들은 오픈 소스 커뮤니티가 추가 개선을 위해 여전히 규모 및 RLHF와 관련된 "해자"를 탐색해야 할 수도 있다고 지적했습니다.
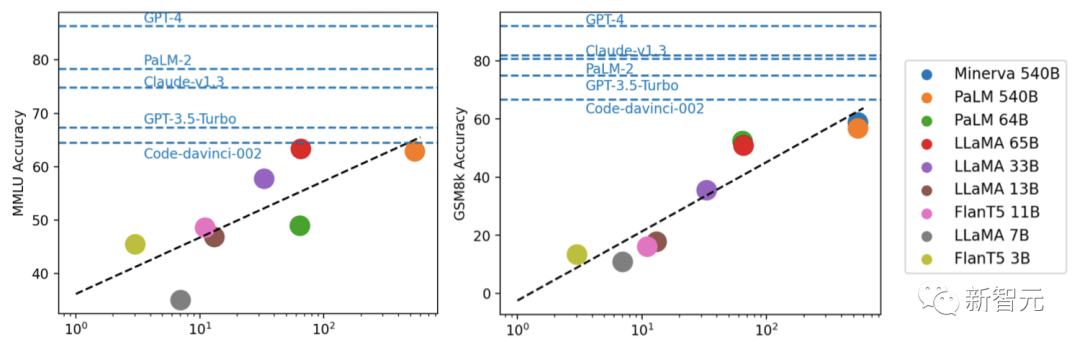
논문의 첫 번째 저자인 Fu Yao는 다음과 같이 결론을 내렸습니다.
1. 오픈 소스와 비공개 사이에는 분명한 차이가 있습니다.
2. 상위권 주류 모델은 대부분 RLHF
3입니다. LLaMA-65B는 GPT-3.5의 기본 모델인 code-davinci-002에 매우 가깝습니다.
4. 이상, 가장 희망하는 방향은 "LLaMA 65B에서 RLHF를 하는 것"입니다.

이 프로젝트에서 저자는 향후 추가 최적화에 대해 설명합니다.
미래에는 특히 상식 추론을 측정하기 위해 더욱 신중하게 선택된 데이터를 포함한 더 많은 추론 데이터 세트가 추가될 것입니다. 그리고 데이터 세트의 수학적 정리.
및 외부 API 호출 기능.
더 중요한 것은 Vicuna7 및 기타 오픈 소스 모델과 같은 LLaMA 기반 지침 미세 조정 모델과 같은 더 많은 언어 모델을 포함하는 것입니다.
Cohere 8과 같은 API를 통해 PaLM-2와 같은 모델의 기능에 액세스할 수도 있습니다.
간단히 말하면, 저자는 이 프로젝트가 오픈 소스 대형 언어 모델 개발을 평가하고 안내하는 공공 복지 시설로서 큰 역할을 할 수 있다고 믿습니다.
위 내용은 중국 과학팀, 대형 모델의 복잡한 추론 능력을 종합적으로 평가하기 위해 'Thinking Chain Collection' 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



