

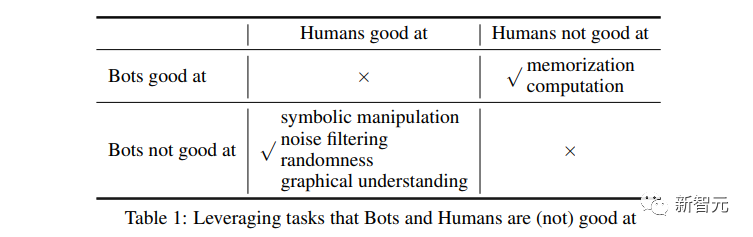
모든 주요 언어 모델을 능가하는 "튜링 테스트"의 "궁극적 거지 버전"입니다.
인간은 쉽게 시험을 통과할 수 있습니다.
연구원들은 매우 간단한 방법을 사용했습니다.
실제 문제를 대문자로 작성된 지저분한 단어에 섞어서 대규모 언어 모델에 제출하세요.
대규모 언어 모델이 실제 질문을 효과적으로 식별할 수 있는 방법은 없습니다.
인간은 문제에서 "대문자"라는 단어를 쉽게 제거하고, 혼란스러운 대문자 속에 숨겨진 실제 질문을 식별하고, 답변을 제공하고, 테스트를 통과할 수 있습니다.
그림 자체의 질문은 매우 간단합니다. 물이 젖었습니까 아니면 건조합니까?

인간은 그냥 젖었다고 대답하면 끝이에요.
하지만 ChatGPT는 질문에 답할 때 대문자의 간섭을 제거할 방법이 없습니다.
그래서 질문에 의미없는 단어가 많이 섞여서 답변이 매우 길고 의미가 없게 되었습니다.
ChatGPT 외에도 연구원들은 GPT-3 및 Meta의 LLaMA 및 여러 오픈 소스 미세 조정 모델에 대해서도 유사한 테스트를 수행했지만 모두 "대문자 테스트"에 실패했습니다.

테스트의 원리는 실제로 간단합니다. AI 알고리즘은 일반적으로 대소문자를 구분하지 않고 텍스트 데이터를 처리합니다.
그래서 대문자가 문장에 실수로 배치되면 혼동을 일으킬 수 있습니다.
AI는 고유명사로 처리할지, 오류로 처리할지, 아니면 그냥 무시할지 모릅니다.

이를 사용하면 대화 상대 중 실제 사람과 챗봇을 쉽게 구분할 수 있습니다.
AI를 좀 더 과학적으로 밝히는 방법은 무엇일까요?
향후 대량으로 나타날 수 있는 챗봇을 이용한 사기 등 심각한 불법 행위에 대응하기 위해.
위에서 언급한 대문자 테스트 외에도 연구자들은 온라인 환경에서 인간과 챗봇을 보다 효율적으로 구별할 수 있는 방법을 찾으려고 노력하고 있습니다.

종이: //m.sbmmt.com/link/f30a31bcad7560324b3249ba66ccf7aa
연구원들은 대규모 언어 모델의 약점을 설계하는 데 중점을 둡니다.
대형 언어 모델이 테스트를 통과하는 것을 막기 위해 AI의 "7인치"를 붙잡아 폭파시키세요.
우리는 다음과 같은 테스트 방법을 개발했습니다.
큰 모델이 질문에 대답을 잘 못하는 한, 우리는 그들을 미친 듯이 타겟팅할 것입니다.
Counting
첫 번째 일은 계산입니다. 대형 모델을 세는 것만으로는 충분하지 않다는 사실을 아는 것입니다.

물론, 세 글자를 모두 틀릴 수도 있어요.
텍스트 교체
그런 다음 텍스트 교체가 있습니다. 여기서 여러 문자가 서로 교체되고 대형 모델이 새 단어를 철자하게 됩니다.
AI는 오랫동안 애썼지만 출력 결과는 여전히 틀렸습니다.

직위 교체
이것도 ChatGPT의 강점은 아닙니다.
초등학생도 정확하게 완성할 수 있는 문자 필터링 챗봇도 완성할 수 없습니다.

질문: 두 번째 "S" 다음 4번째 문자를 입력하세요. 정답은 "c"입니다. 노력했지만 AI는 여전히 통과하지 못했습니다.
Noise Implantation
이것이 처음에 말씀드린 "대문자 테스트"입니다. 
질문에 다양한 노이즈(예: 대문자로 된 관련 없는 단어 등)를 추가하면 챗봇이 질문을 정확하게 식별하지 못하여 테스트에 실패하게 됩니다.
그리고 인간의 경우 이렇게 뒤죽박죽된 대문자에서 실제 문제를 보는 것은 정말 어렵습니다.

Symbol text

는 인간에게 거의 도전이 없는 또 다른 작업입니다.
그러나 챗봇이 이러한 상징적 텍스트를 이해할 수 있으려면 많은 전문 교육 없이는 어려울 것입니다.
연구원들이 대규모 언어 모델을 위해 특별히 설계한 일련의 "불가능한 작업" 이후.
기억과 계산
초기 학습을 통해 대규모 언어 모델은 이 두 가지 측면에서 비교적 좋은 성능을 발휘합니다.
인간은 기본적으로 다양한 보조 장치를 사용할 수 없기 때문에 대용량 메모리와 4자리 계산에 효과적으로 대응할 수 없습니다.
인간 VS 대형 언어 모델
연구원들은 GPT3, ChatGPT 및 기타 세 가지 오픈 소스 대형 모델인 LLaMA, Alpaca 및 Vicuna
에서 이 "인간 차이 테스트"를 수행했습니다. 대형 모델이 인류 속으로 성공적으로 혼합되지 않았음을 분명히 볼 수 있습니다.
연구팀은 https://github.com/hongwang600/FLAIR

에서 문제를 오픈소스화했습니다. 가장 성능이 좋은 ChatGPT는 직위 교체 테스트 비율의 25% 미만을 통과했습니다.
그리고 다른 대규모 언어 모델은 해당 모델을 위해 특별히 설계된 테스트에서 성능이 매우 낮습니다.
시험 합격이 전혀 불가능합니다.
하지만 인간에게는 매우 간단해서 거의 100% 통과했습니다.
인간이 잘 못하는 문제는 인간이 거의 전멸하고 완전히 패퇴하고 있는 상황이죠.
AI는 분명히 능력이 있습니다.
연구원들이 테스트 설계에 정말 많은 신경을 쓴 것 같습니다.
"어떤 AI도 버리지 말고, 어떤 인간에게도 해를 끼치지 말라"
이것은 대단한 차별점입니다!
참조: //m.sbmmt.com/link/5e632913bf096e49880cf8b92d53c9ad
위 내용은 인간과 AI를 구별하는 질문 하나! '거지판' 튜링 테스트, 대형 모델 모두 어렵다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



