


데이터베이스 아키텍처의 진화
초기에는 대부분의 프로젝트에서 서버 트래픽이 점점 커지면서 더 많은 문제에 직면하게 되었습니다. 여러 개의 슬레이브 데이터베이스 사본(슬레이브)을 사용하여 읽기를 담당하고 마스터 데이터베이스(마스터)를 사용하여 쓰기를 담당하여 데이터베이스 읽기 및 쓰기를 분리했습니다. 데이터 일관성을 유지하기 위한 마스터-슬레이브 복제. 슬레이브 라이브러리는 수평으로 확장할 수 있으므로 더 많은 읽기 요청이 문제가 되지 않습니다
하지만 사용자 레벨이 증가하고 쓰기 요청이 점점 더 많아지면 데이터베이스 부하가 충분한지 어떻게 보장할 수 있을까요? 마스터를 추가해도 문제가 해결되지 않습니다. 데이터는 일관성이 있어야 하고 쓰기 작업에는 두 마스터 간의 동기화가 필요하며 이는 복제와 동일하며 아키텍처 설계가 더 복잡하기 때문입니다
이 경우 샤딩이 필요하고 저장이 필요합니다. 서로 다른 MySQL 서버에 있는 라이브러리와 테이블, 그리고 각 서버는 쓰기 요청 수의 균형을 맞출 수 있습니다
단일 데이터베이스가 너무 큽니다. 단일 데이터베이스의 처리 용량은 제한되어 있으며, 디스크 공간 부족과 IO 병목 현상으로 인해 단일 데이터베이스를 점점 더 작은 데이터베이스로 나누어야 합니다
단일 테이블이 너무 커서 CURD 효율성이 매우 낮습니다.데이터 양이 너무 크면 인덱스 파일이 너무 커지고 디스크 IO가 인덱스를 로드하는 데 시간이 걸리므로 쿼리 시간이 초과됩니다. 따라서 인덱스를 사용하는 것만으로는 충분하지 않습니다. 단일 테이블을 더 작은 데이터 세트가 포함된 여러 테이블로 분할해야 합니다. MyCat에서 제공하는 테이블 분할 알고리즘은 모두 rule.xml에 있으며, 이는 시간 기준 분할, 일관된 해싱, 기본 키를 사용하여 분할 테이블 수를 직접 모듈로 모듈로화하는 등 다양한 테이블 분할 알고리즘에 따라 분할될 수 있습니다.
분할 전략한 개의 라이브러리가 너무 큰 경우 먼저 테이블이 너무 많은지, 데이터가 너무 많은지 고려하세요.
테이블이 너무 많아 데이터가 너무 많으면 수직 분할, 즉 분할을 사용하세요. 업무에 따라 서로 다른 라이브러리로 분리
한 테이블의 데이터 양이 너무 많으면 수평 분할을 사용하세요. 즉, 특정 규칙(규칙에 정의된 테이블 분할 알고리즘)에 따라 테이블 데이터를 여러 테이블로 분할합니다. xml)
데이터베이스와 테이블의 샤딩 원칙은 수직 분할을 먼저 고려한 후 수평 분할을 고려해야 합니다
3. 수직 분할하위 데이터베이스 샤딩과 읽기-쓰기 분리가 함께 가능합니다
server.xml
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB1,USERDB2</property> </user>
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB1" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" /> <!-- 两个逻辑库对应两个不同的数据节点 --> <schema name="USERDB2" checkSQLschema="false" sqlMaxLimit="100"dataNode="dn2" /> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <!-- 两个数据节点对应两个不同的物理机器 --> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- USERDB1对应mytest1,USERDB2对应mytest2 --> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
두 개의 논리 라이브러리는 두 개의 서로 다른 데이터 노드에 해당하고 두 개의 데이터 노드는 두 개의 서로 다른 물리적 시스템에 해당
mytest1과 mytest2는 서로 다른 시스템의 서로 다른 라이브러리로 나누어져 있으며 각각 테이블의 일부를 포함하고 있습니다. 원래는 하나의 시스템에 결합되었지만 이제는 수직으로 분할됩니다.클라이언트는 서로 다른 로직 라이브러리에 연결해야 합니다. 비즈니스 운영에 따라 서로 다른 로직 라이브러리가 사용됩니다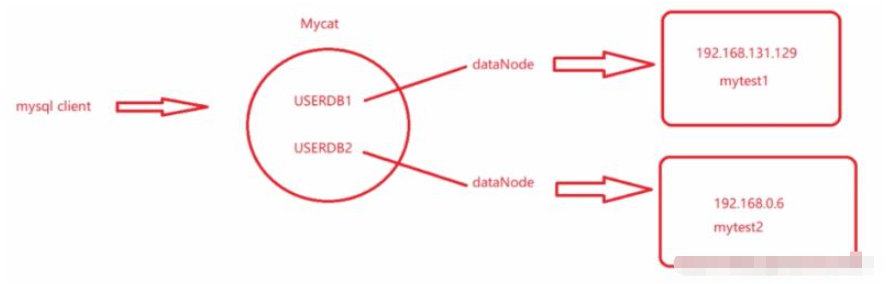
 2. 수직 테이블 샤딩
2. 수직 테이블 샤딩
수직 테이블 샤딩은 열 필드를 기반으로 합니다. 쿼리할 때 대량의 데이터로 인해 발생하는 "페이지 간" 문제를 피하기 위해 일반적으로 수백 개의 열이 있는 대규모 테이블에 사용됩니다.
4. 수평형 하위 데이터베이스 및 하위 테이블
특정 규칙(RANGE, HASH 모듈러스 등), 여러 테이블로 분할됩니다. 테이블이 여전히 동일한 데이터베이스에 있기 때문에 권장되지 않습니다. 따라서 전체 데이터베이스에 대해 작업을 수행할 때 IO 병목 현상이 발생할 수 있습니다.
서버를 켜세요. 이 테이블은 분할될 필요가 없습니다. 학생 테이블의 기본 키는 id에 따라 분할되어 dn1과 dn2에 배치됩니다. 물리적으로는 분리되어 있지만 논리적으로는 여전히 하나입니다. 어떤 테이블에 추가할지, 두 컴퓨터에 대한 쿼리 및 이러한 작업을 병합하는 방법은 모두 mycat에 의해 완료됩니다분할 규칙은 모듈로(mod - long)입니다. 삽입할 때마다 ID 모듈에 존재하는 머신(2)
또한 rule.xml에서 다음 분할 알고리즘을 구성해야 합니다
mod-long 알고리즘을 찾으세요. 논리적 테이블 학생을 두 개의 호스트에 별도로 매핑하므로 수정된 데이터 노드의 수는 2

2개입니다. 테스트 수준 하위 테이블
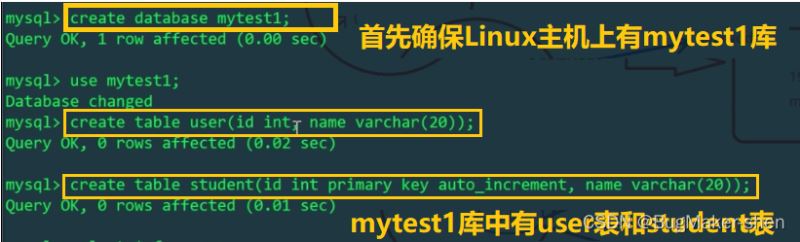
Linux 호스트
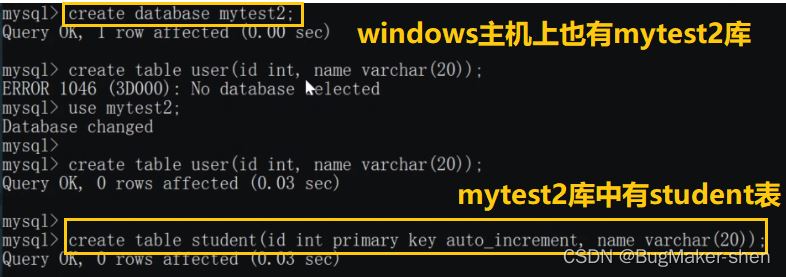
Windows 호스트
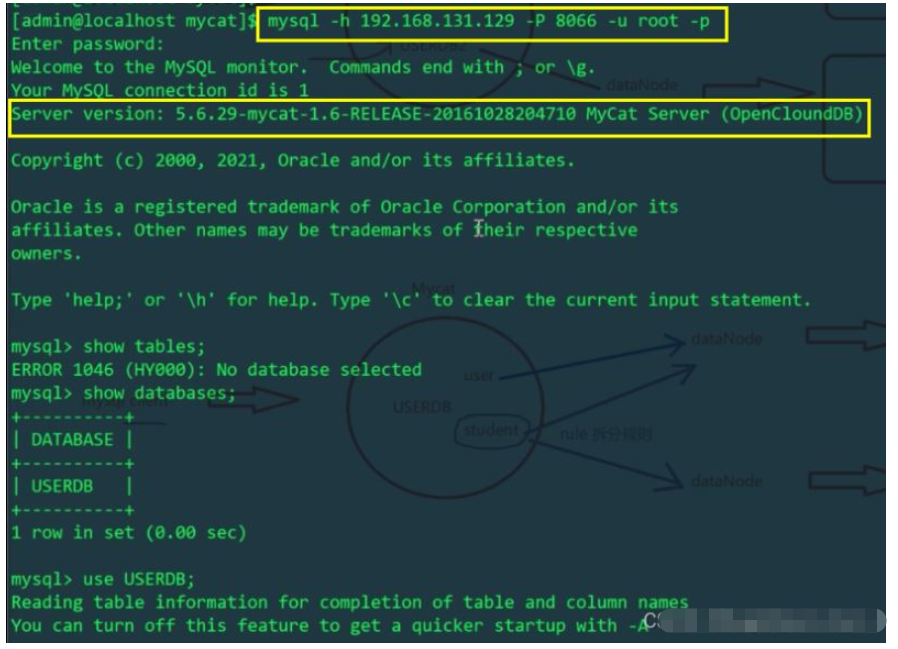
mycat
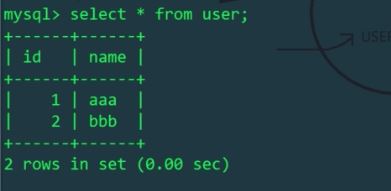
MyCat을 사용하여 사용자 테이블에 두 개의 데이터를 삽입하려면

schema.xml 구성 파일로 인해 논리 테이블 사용자는 8066 포트에 로그인합니다. Linux 호스트의 mytest1 라이브러리에만 있습니다. 예, mycat이 운영하는 논리적 테이블 사용자는 Linux 호스트의 물리적 테이블에 영향을 주지만 Windows 호스트의 테이블에는 영향을 미치지 않습니다. Linux 및 Windows 호스트의 사용자 테이블을 각각 확인합니다.

그런 다음 MyCat

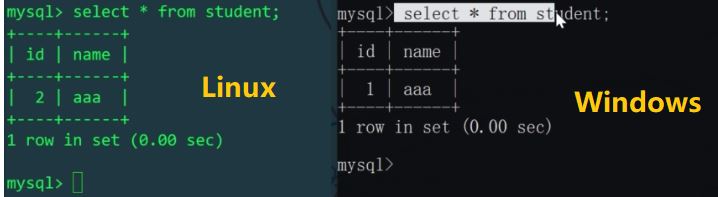
을 통해 두 개의 데이터 조각을 학생 테이블에 삽입합니다. 논리적 테이블 학생은 두 개의 컴퓨터에 해당합니다. 호스트의 두 라이브러리 mytest1 및 mytest2에는 두 개의 테이블이 있으므로 논리적 테이블에 삽입된 두 데이터 조각은 실제로 두 개의 물리적 테이블에 영향을 미칩니다(어떤 물리적 테이블을 추가할지 결정하려면 id%机器数를 사용하세요). 에 집어 넣다). Linux 및 Windows 호스트의 학생 테이블을 각각 확인해 보겠습니다.
그런 다음 MyCat을 통해 id=3 및 id=4의 데이터를 삽입해야 합니다. 이는 서로 다른 호스트의 서로 다른 물리적 테이블에 삽입되어야 합니다.
이것은 학생 테이블을 수평으로 분할하는 것과 같습니다. MyCat을 통해 쿼리할 때는 정상적으로 입력하기만 하면 됩니다. MyCat은 두 개의 데이터베이스에 대해 쿼리를 분할하여 배치하도록 구성합니다. 그리고 데이터 병합을 수행합니다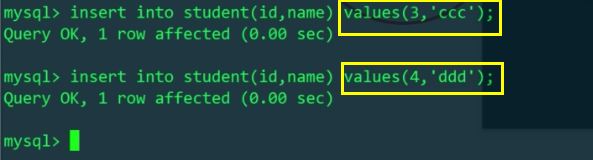
위 내용은 MySQL 하위 데이터베이스 및 하위 테이블 분석 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



