

일반적으로 우리가 다루는 데이터 분포에는 이상치가 있는 것이 일반적이며 많은 알고리즘이 이상치를 처리할 수 있으며 EllipticalEnvelope는 Sklearn에 직접 내장된 이에 대한 예입니다. 이 알고리즘의 장점은 정규 분포(가우스) 특성에서 이상값을 매우 잘 탐지한다는 것입니다.
import numpy as np from sklearn.covariance import EllipticEnvelope # 创建一个样本正态分布 X = np.random.normal(loc=5, scale=2, size=50).reshape(-1, 1) # 拟合估计量 ee = EllipticEnvelope(random_state=0) _ = ee.fit(X) # 测试 test = np.array([6, 8, 20, 4, 5, 6, 10, 13]).reshape(-1, 1) # Predict返回1作为内嵌值,返回-1作为异常值 >>> ee.predict(test) array([ 1, 1, -1, 1, 1, 1, -1, -1])
평가 결과를 확인하기 위해 평균이 5이고 표준 편차가 2인 정규 분포를 생성했습니다. 훈련이 완료된 후 예측 방법에 임의의 숫자를 전달합니다. 이 메서드는 -1을 반환하여 테스트의 이상값(예: 20, 10, 13)을 나타냅니다.
데이터 마이닝 및 기능 엔지니어링을 수행할 때 예측에 가장 유용한 기능을 선택하는 것은 과적합을 방지하고 모델 복잡성을 줄이는 데 필요한 단계입니다. Sklearn에서 제공하는 가장 강력한 알고리즘 중 하나는 RFE(Recursive Feature Elimination)입니다. 교차 검증을 사용하여 가장 중요한 기능을 자동으로 찾고 나머지는 삭제합니다.
이 평가기의 한 가지 장점은 래퍼라는 것입니다. 기능 중요도 또는 계수 점수를 반환하는 모든 Sklearn 알고리즘에 사용할 수 있습니다. 다음은 합성 데이터 세트에 대한 예입니다.
from sklearn.datasets import make_regression from sklearn.feature_selection import RFECV from sklearn.linear_model import Ridge # 构建一个合成数据集 X, y = make_regression(n_samples=10000, n_features=15, n_informative=10) # 初始化和拟合选择器 rfecv = RFECV(estimator=Ridge(), cv=5) _ = rfecv.fit(X, y) # 转换特性阵列 >>> rfecv.transform(X).shape (10000, 10)
데이터 세트에는 15개의 기능이 있으며 그 중 10개는 유익하고 나머지는 중복됩니다. 우리는 능선 회귀를 추정기로 사용하여 5배 RFECV를 적합했습니다. 학습 후 변환 방법을 사용하여 중복 기능을 삭제할 수 있습니다. 마지막으로 .shape를 호출하여 평가자가 5가지 중복 기능을 모두 제거했는지 확인하세요. .shape 查看评估器删除了所有 5 个冗余的特性。
我们都知道,尽管随机森林非常强大,但过度拟合的风险非常高。因此,Sklearn提供了称为 ExtraTrees(分类器和回归器) 的 RF 替代方案。
"Extra" 这个词并不是指更多的树,而是指更多的随机性。该算法使用了另一种类似于决策树的树。唯一的区别是,不同于在构建每棵树时计算分割阈值,这些阈值是为每个特征随机绘制的,并选择最佳阈值作为分割规则。这允许以偏差略微增加的代价来降低方差:
from sklearn.ensemble import ExtraTreesRegressor, RandomForestRegressor
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
X, y = make_regression(n_samples=10000, n_features=20)
# 决策树
clf = DecisionTreeRegressor(max_depth=None, min_samples_split=2, random_state=0)
scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
0.6376080094392635
# 随机森林
clf = RandomForestRegressor(
n_estimators=10, max_depth=None, min_samples_split=2, random_state=0
)
scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
0.8446103607404536
# ExtraTrees
clf = ExtraTreesRegressor(
n_estimators=10, max_depth=None, min_samples_split=2, random_state=0
)
scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
0.8737373931608834如结果所示,ExtraTreesRegressor 在合成数据集上的表现优于随机森林。
如果你正在寻找比 SimpleImputer 更健壮、更先进的 imputation 技术,Sklearn再次为你提供了支持。impute 子包包括两个基于模型的 impute 算法 KNNImputer 和 IterativeImputer。
顾名思义,KNNImputer 使用 k-Nearest-Neighbors 算法来寻找缺失值的最佳替代:
from sklearn.impute import KNNImputer
# 代码取自Sklearn用户指南
X = [[1, 2, np.nan],
[3, 4, 3],
[np.nan, 6, 5],
[8, 8, 7]]
imputer = KNNImputer(n_neighbors=2)
imputer.fit_transform(X)输出:
array([[1. , 2. , 4. ],
[3. , 4. , 3. ],
[5.5, 6. , 5. ],
[8. , 8. , 7. ]])
另一个更健壮的算法是 IterativeImputer。它通过将每个特征的缺失值建模为其他特征的函数来寻找缺失值。 这个过程是按循序渐进的循环方式完成的。在每一步中,选择一个具有缺失值的特征作为目标(y),其余的作为特征数组(X)。然后,使用回归函数预测 y 中的缺失值,并对每个特征继续这个过程,直到 max_iter 次数 (IterativeImputer的一个参数)。
因此,会为一个缺失的值生成多个预测。这种方法的好处在于将每个缺失的值视为随机变量,并将其与内在的不确定性相结合
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.linear_model import BayesianRidge
imp_mean = IterativeImputer(estimator=BayesianRidge())
imp_mean.fit([[7, 2, 3],
[4, np.nan, 6],
[10, 5, 9]])
X = [[np.nan, 2, 3],
[4, np.nan, 6],
[10, np.nan, 9]]
imp_mean.transform(X)输出:
array([[ 6.95847623, 2. , 3. ],
[ 4. , 2.6000004 , 6. ],
[10. , 4.99999933, 9. ]])
结果表明,使用 IterativeImputer 缺失值填补算法的 BayesianRidge 和 ExtraTree
"추가" 이 단어는 더 많은 트리를 의미하는 것이 아니라 더 많은 무작위성을 의미합니다. 이 알고리즘은 의사결정 트리와 유사한 다른 트리를 사용합니다. 유일한 차이점은 각 트리를 작성할 때 분할 임계값을 계산하는 대신 각 기능에 대해 이러한 임계값을 무작위로 추출하고 최상의 임계값을 분할 규칙으로 선택한다는 것입니다. 이렇게 하면 편향이 약간 증가하는 대신 분산이 줄어들 수 있습니다.🎜from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
iris = load_iris()
X, y = iris.data, iris.target
clf = DecisionTreeClassifier()
clf = clf.fit(X, y)
plt.figure(figsize=(15, 10), dpi=200)
plot_tree(clf, feature_names=iris.feature_names,
class_names=iris.target_names);SimpleImputer보다 더 강력하고 고급 대치 기술을 찾고 있다면 Sklearn이 다시 한 번 도움을 드릴 것입니다. 대치 하위 패키지에는 두 가지 모델 기반 대치 알고리즘 KNNImputer 및 IterativeImputer가 포함되어 있습니다. 🎜🎜이름에서 알 수 있듯이 KNNImputer는 k-Nearest-Neighbors 알고리즘을 사용하여 누락된 값에 대한 최상의 대체 항목을 찾습니다. 🎜from sklearn.datasets import make_classification from sklearn.linear_model import Perceptron # 创建一个更大的数据集 X, y = make_classification(n_samples=100000, n_features=20, n_classes=2) # Init/Fit/Score clf = Perceptron() _ = clf.fit(X, y) clf.score(X, y)
🎜array ([[1 . , 2. , 4. ],
> 각 특성의 결측값을 다른 특성의 함수로 모델링하여 결측값을 찾습니다. 이 프로세스는 단계별 주기로 완료됩니다. 각 단계에서 누락된 값이 있는 특징 하나가 대상(y)으로 선택되고 나머지는 특징 배열(X)로 선택됩니다. 그런 다음 회귀 함수를 사용하여 y의 결측값을 예측하고 각 특성에 대해 최대max_iter회(IterativeImputer의 매개변수)까지 이 프로세스를 계속합니다. 🎜🎜따라서 누락된 값에 대해 여러 예측이 생성됩니다. 이 접근 방식의 이점은 각 누락된 값을 무작위 변수로 처리하고 이를 고유한 불확실성과 결합한다는 것입니다. 🎜🎜출력: 🎜from sklearn.feature_selection import SelectFromModel # 创建一个包含40个无信息特征的数据集 X, y = make_regression(n_samples=int(1e4), n_features=50, n_informative=10) # 初始化选择器并转换特性数组 selector = SelectFromModel(estimator=ExtraTreesRegressor()).fit(X, y) selector.transform(X).shape로그인 후 복사로그인 후 복사🎜array([[ 6.95847623, 2. , , 3. ] ,
IterativeImputer누락된 값BayesianRidge및ExtraTree채우기 알고리즘의 성능 효과가 훨씬 더 좋습니다. 🎜🎜5 .linear_model.HuberRegressor🎜🎜정상적인 상황에서는 데이터 분포에 이상치가 존재하는 것이 매우 일반적이지만, 이상치의 존재는 모든 모델의 예측을 심각하게 훼손할 수 있습니다. 많은 이상값 검색 알고리즘은 이상값을 삭제하고 누락된 것으로 표시합니다. 이는 모델 학습에 도움이 되지만 분포에 대한 이상값의 영향을 완전히 제거합니다. 🎜另一种算法是
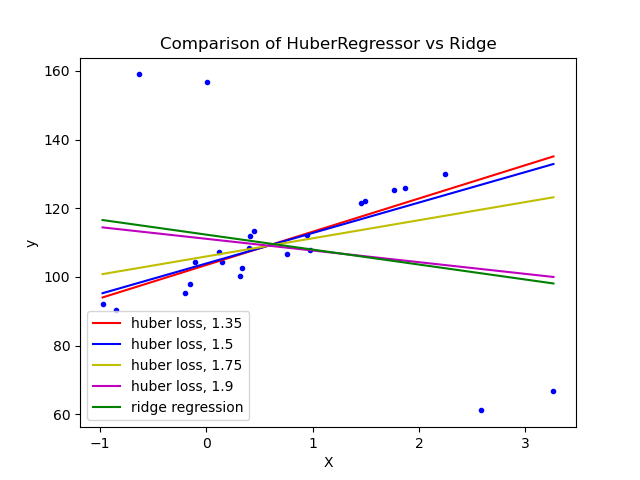
HuberRegressor回归算法。它不是完全去除它们,而是在拟合数据期间给予异常值更小的权重。它有超参数epsilon来控制样本的数量,这些样本应该被归类为异常值。参数越小,对异常值的鲁棒性越强。它的API与任何其他线性回归函数相同。下面,你可以看到它与贝叶斯岭回归器在一个有大量异常值的数据集上的比较:
可以看到,设置参数 epsilon 为 1.35 1.5, 1.75 的
huberregressionor算法设法捕获不受异常值影响的最佳拟合线。6 .tree.plot_tree
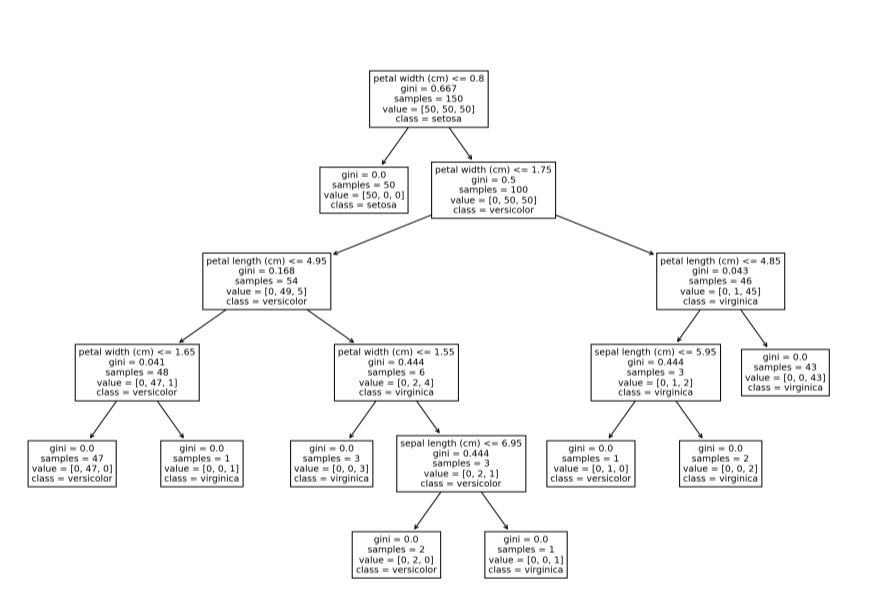
Sklearn 中可以使用
plot_tree函数绘制单个决策树的结构。这个特性可能对刚开始学习基于树的模型和集成模型的初学者很方便,通过该方法,对决策树的决策过程可视化,对其决策过程和原理更加一目了然。from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier, plot_tree iris = load_iris() X, y = iris.data, iris.target clf = DecisionTreeClassifier() clf = clf.fit(X, y) plt.figure(figsize=(15, 10), dpi=200) plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names);로그인 후 복사로그인 후 복사
还有其他绘制树的方法,比如 Graphviz。
7 .linear_model.Perceptron
尽管感知机是一个奇特的名字,但它是一个简单的线性二进制分类器。算法的定义特征是适合大规模学习,默认为:
它不需要学习速率。
不要实现正则化。
它只在分类错误的情况下更新模型。
它等价于
SGDClassifier,loss='perceptron',eta0=1,learning_rate="constant",penalty=None,但略快:from sklearn.datasets import make_classification from sklearn.linear_model import Perceptron # 创建一个更大的数据集 X, y = make_classification(n_samples=100000, n_features=20, n_classes=2) # Init/Fit/Score clf = Perceptron() _ = clf.fit(X, y) clf.score(X, y)로그인 후 복사로그인 후 복사输出:
0.91928
8 .feature_selection.SelectFromModel
Sklearn 中另一个基于模型的特征选择模型是 SelectFromModel。它不像RFECV那样健壮,但由于它具有较低的计算成本,可以作为大规模数据集的一个很好的选择。它也是一个包装器模型,适用于任何具有
.feature_importance_或.coef_属性的模型:from sklearn.feature_selection import SelectFromModel # 创建一个包含40个无信息特征的数据集 X, y = make_regression(n_samples=int(1e4), n_features=50, n_informative=10) # 初始化选择器并转换特性数组 selector = SelectFromModel(estimator=ExtraTreesRegressor()).fit(X, y) selector.transform(X).shape로그인 후 복사로그인 후 복사输出:
(10000, 8)
如结果所示,算法成功地删除了所有40个冗余特征。
9 .metrics.ConfusionMatrixDisplay
总所周知,混淆矩阵是用于评估分类问题的常用方法。大多数我们通常使用的指标,如精度、召回率、F1、ROC AUC等等,都源于它。Sklearn中可以计算和绘制一个默认的混淆矩阵:
from sklearn.metrics import plot_confusion_matrix from sklearn.model_selection import train_test_split # 创建一个二元分类问题 X, y = make_classification(n_samples=200, n_features=5, n_classes=2) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.5, random_state=1121218 ) clf = ExtraTreeClassifier().fit(X_train, y_train) fig, ax = plt.subplots(figsize=(5, 4), dpi=100) plot_confusion_matrix(clf, X_test, y_test, ax=ax);로그인 후 복사
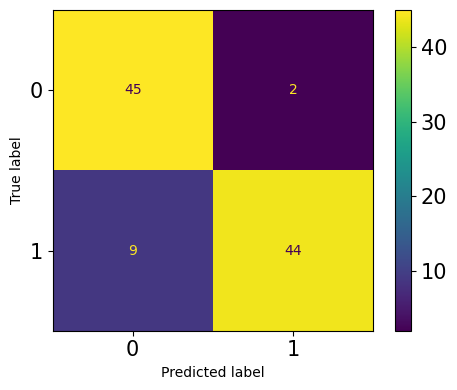
老实说,我不喜欢默认的混淆矩阵。它的格式是固定的—行是
true labels,列是predictions label。第一行和第一列是负类,第二行和第二列是正类。有些人可能更喜欢不同格式的矩阵,可能是转置或翻转的。例如,我喜欢将正类作为第一行和第一列。这有助于我更好地隔离 4 矩阵项 --
TP, FP, TN, FN。幸运的是,你可以用另一个函数ConfusionMatrixDisplay绘制自定义矩阵:from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix clf = ExtraTreeClassifier().fit(X_train, y_train) y_preds = clf.predict(X_test) fig, ax = plt.subplots(figsize=(5, 4), dpi=100) cm = confusion_matrix(y_test, y_preds) cmp = ConfusionMatrixDisplay(cm, display_labels=["Positive", "Negative"]) cmp.plot(ax=ax);로그인 후 복사
在传递给
ConfusionMatrixDisplay之前,可以把 混淆矩阵cm 放在任何格式中。10 .Generalized Linear Models
一般情况下,如果有可用于其他类型分布的替代方案,则将目标(y)转换为正态分布是没有意义的。
例如,Sklearn 为目标变量提供了3种广义线性模型,分别是泊松、Tweedie或Gamma分布 ,而不是所期望的正态分布,
poissonregressionor, TweedieRegressor 和 GammaRegressor可以生成具有各自分布的目标的稳健结果。除此之外,他们的api与任何其他Sklearn模型一样。可以将它们的概率密度函数绘制在同一坐标系上,以确定目标的分布是否与这三个分布相匹配。
例如,要查看目标是否遵循泊松分布,可以使用 Seaborn 的
kdeploy绘制它的 PDF,并在相同的轴上使用np.random_poisson从 Numpy 中采样,绘制完美的泊松分布。11 .ensemble.IsolationForest
通常来说,基于树形模型和集合模型生成的结果更加稳健,同时在检测异常点方面也被证实是有效的。Sklearn 中的 IsolationForest 使用一个极端随机树 (tree.ExtraTreeRegressor) 来检测异常值。每个样本被分裂到树的不同分支上,每个分支根据选定的单一特征,在该特征的最大和最小值之间随机选择一个分裂值。
这种随机分区会在每棵树的根节点和终止节点之间产生明显更短的路径。
因此,当随机树组成的森林为特定样本共同产生更短的路径长度时,它们极有可能是异常——Sklearn用户指南。
from sklearn.ensemble import IsolationForest X = np.array([-1.1, 0.3, 0.5, 100]).reshape(-1, 1) clf = IsolationForest(random_state=0).fit(X) clf.predict([[0.1], [0], [90]])로그인 후 복사输出:
array([ 1, 1, -1])
12 .preprocessing.PowerTransformer
许多线性模型需要在数值特征上进行一些转换才能使其服从正态分布。
StandardScaler和MinMaxScaler在大多数发行版中都比较适用。然而,当数据存在高偏度时,分布的核心指标,如平均值、中位数、最小值和最大值,就会受到影响。因此,简单的标准化和标准化对倾斜分布不起作用。相反,Sklearn 实现中提供了一个名为
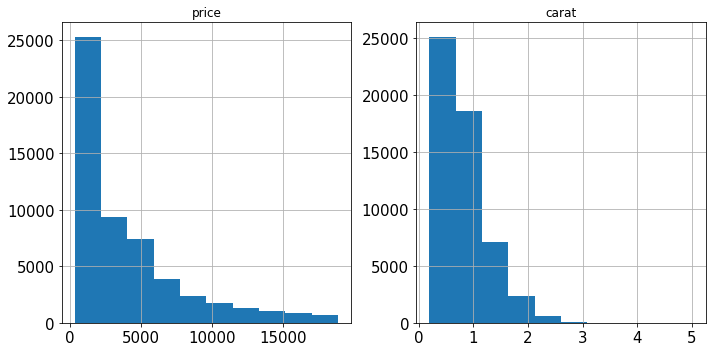
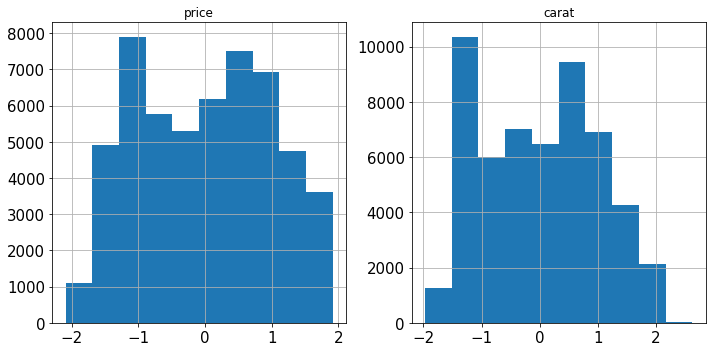
PowerTransformer的方法,它使用对数变换将任何倾斜的特征尽可能地转化为正态分布。考虑 Diamonds 数据集中的两个特征:import seaborn as sns diamonds = sns.load_dataset("diamonds") diamonds[["price", "carat"]].hist(figsize=(10, 5));로그인 후 복사
两者都严重倾斜。我们用对数变换
PowerTransformer来解决这个问题:from sklearn.preprocessing import PowerTransformer pt = PowerTransformer() diamonds.loc[:, ["price", "carat"]] = pt.fit_transform(diamonds[["price", "carat"]]) diamonds[["price", "carat"]].hist(figsize=(10, 5));로그인 후 복사
13 .preprocessing.RobustScaler
Sklearn 中的另一个数字转换器是
RobustScaler,我们可以从它的名称猜出它的用途——可以以一种健壮到异常值的方式转换特性。如果一个特征中存在异常值,就很难使其服从正态分布,因为它们会严重扭曲均值和标准差。与使用均值/标准不同,RobustScaler 使用中值和IQR(四分位数范围)来衡量数据,因为这两个指标都不会因为异常值而有偏差。
14 .compose.make_column_transformer
在 Sklearn 中,有一个用
make_pipeline函数创建 Pipeline 实例的简写。该函数不需要为Pipeline中的每一步命名,而是只接受变形器和估计器并执行它的工作,从而不需要使代码那么长:from sklearn.impute import SimpleImputer from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler pipeline = make_pipeline(SimpleImputer(), StandardScaler(), ExtraTreesRegressor()) pipeline로그인 후 복사Pipeline(steps=[('simpleimputer', SimpleImputer()), ('standardscaler', StandardScaler()), ('extratreesregressor', ExtraTreesRegressor())])로그인 후 복사对于更复杂的场景,使用
ColumnTransformer,这有相同的问题——每个预处理步骤都应该命名,这会使代码变得冗长且不可读。Sklearn提供了与make_pipeline类似的函数:import seaborn as sns from sklearn.compose import make_column_transformer from sklearn.preprocessing import OneHotEncoder # 负载钻石数据集 diamonds = sns.load_dataset("diamonds") X, y = diamonds.drop("price", axis=1), diamonds.price.values.reshape(-1, 1) # 拆分数字和类别标签 num_cols = X.select_dtypes(include=np.number).columns cat_cols = X.select_dtypes(exclude=np.number).columns make_column_transformer((StandardScaler(), num_cols), (OneHotEncoder(), cat_cols))로그인 후 복사ColumnTransformer( transformers=[('standardscaler', StandardScaler(), Index(['carat', 'depth', 'table', 'x', 'y', 'z'], dtype='object')), ('onehotencoder', OneHotEncoder(), Index(['cut', 'color', 'clarity'], dtype='object'))] )로그인 후 복사如上所示,使用
make_column_transformer要短得多,并且它自己负责命名每个转换器步骤。15 .compose.make_column_selector
上文中,我们使用
select_dtypes函数和pandas DataFrames的columns属性来拆分数值列和分类列。虽然这当然有效,但使用 Sklearn 有一个更灵活、更优雅的解决方案。
make_column_selector函数创建一个可以直接传递到 ColumnTransformer 实例中的列选择器。它的工作原理与select_dtypes类似,甚至更好。它有dtype_include和dtype_exclude参数,可以根据数据类型选择列。如果需要自定义列筛选器,可以将正则表达式传递给 pattern,同时将其他参数设置为 None。下面是它的工作原理:from sklearn.compose import make_column_selector make_column_transformer( (StandardScaler(), make_column_selector(dtype_include=np.number)), (OneHotEncoder(), make_column_selector(dtype_exclude=np.number)), )로그인 후 복사只是传递一个实例 make_column_selector 与由你设置相关参数,而不是传递一个列名称列表!
16 .preprocessing.OrdinalEncoder
在我们刚学习机器学习时,常见的一个错误是使用 LabelEncoder 来编码有序的分类特征。注意到,LabelEncoder 一次只允许转换一个列,而不是像 OneHotEncoder 那样同时转换。你可能会认为 Sklearn 犯了一个错误!
实际上,
LabelEncoder应该只用于按照 LabelEncoder 文档中指定的方式对响应变量(y)进行编码。要编码特征数组(X),应该使用OrdinalEncoder,它将有序分类列转换为具有(0, n_categories - 1)类的特性。它在一行代码中跨所有指定列执行此操作,使得在管道中包含它成为可能。from sklearn.preprocessing import OrdinalEncoder oe = OrdinalEncoder() X = [ ["class_1", "rank_1"], ["class_1", "rank_3"], ["class_3", "rank_3"], ["class_2", "rank_2"], ] oe.fit_transform(X)로그인 후 복사输出:
array([[0., 0.],
[0., 2.],
[2., 2.],
[1., 1.]])17 .metrics.get_scorer
Sklearn 内置了 50 多个指标,它们的文本名称可以在
Sklearn.metrics.scores.keys中看到。在单个项目中,如果单独使用它们,则可能需要使用多个指标并导入它们。从
sklearn.metrics中导入大量指标可能会污染你的名称空间,使其变得不必要的长。一种解决方案是可以使用metrics.get_scorer函数使用其文本名称访问任何度量,而不需要导入它:from sklearn.metrics import get_scorer >>> get_scorer("neg_mean_squared_error") make_scorer(mean_squared_error, greater_is_better=False) >>> get_scorer("recall_macro") make_scorer(recall_score, pos_label=None, average=macro) >>> get_scorer("neg_log_loss") make_scorer(log_loss, greater_is_better=False, needs_proba=True)로그인 후 복사18 .model_selection.HalvingGrid 和 HalvingRandomSearchCV
在 sklearn 的 0.24 版本中,引入了两个实验性超参数优化器:
HalvingGridSearchCV和HalvingRandomSearchCV类。与它们详尽的同类
GridSearch和RandomizedSearch不同,新类使用了一种称为连续减半的技术。 不是在所有数据上训练所有候选集,而是只将数据的一个子集提供给参数。通过对更小的数据子集进行训练,筛选出表现最差的候选人。每次迭代后,训练样本增加一定的因子,而可能的候选个数减少尽可能多的因子,从而获得更快的评估时间。快多少呢?在我做过的实验中,
HalvingGridSearch比普通GridSearch快11倍,HalvingRandomSearch甚至比HalvingGridSearch快10倍。19 .sklearn.utils
Sklearn在
sklearn.utils中有一整套实用程序和辅助功能。Sklearn本身使用这个模块中的函数来构建我们使用的所有变形器transformers和估计器transformers。这里有许多有用的方法,如
class_weight.compute_class_weight、estimator_html_repr、shuffle、check_X_y等。你可以在自己的工作流程中使用它们,使你的代码更像 Sklearn,或者在创建适合 Sklearn API 的自定义转换器和评估器时,它们可能会派上用场。위 내용은 Python Sklearn의 매우 유용한 숨겨진 기능은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



