


관계형 데이터베이스에서 인덱스는 데이터베이스 테이블에 있는 하나 이상의 열 값을 정렬하는 별도의 물리적 저장 구조입니다. 해당 값을 물리적으로 식별하는 테이블의 데이터 페이지에 대한 논리적 포인터 목록과 함께 테이블의 열에 대한 정보입니다.
색인의 역할은 책의 목차와 동일합니다. 데이터베이스는 목차의 주요 페이지 번호를 기준으로 원하는 내용을 빠르게 찾을 수 있으며, 이를 통해 특정 값을 찾을 수 있습니다. 포인터를 따라가면 해당 값이 포함된 행을 찾을 수 있습니다. 이는 테이블에 해당하는 SQL 문일 수 있습니다. 데이터베이스 테이블의 특정 정보에 더 빠르고 빠르게 액세스할 수 있습니다.
InnoDB에는 일반 인덱스, 고유 인덱스(기본 키 인덱스는 비어 있지 않은 특수 고유 인덱스), 전체 텍스트 인덱스의 세 가지 인덱스 유형이 있습니다.
다음으로 다시 작성: 일반 인덱스(비고유 인덱스라고도 함)에는 제한이 없습니다. 고유: 고유 인덱스는 키 값이 반복될 수 없어야 합니다(비어 있을 수 있음). 기본 키 인덱스는 실제로 특수 고유 인덱스이지만 키 값이 비어 있으면 안 된다는 추가적인 제한 사항도 있습니다. 기본 키 인덱스는 기본 키를 사용하여 생성됩니다. 전문: 기사, 텍스트, 이메일 등과 같이 상대적으로 큰 데이터의 경우 하나의 필드에 몇 kb가 필요할 수 있습니다. 전체 텍스트 매칭에서 같은 쿼리의 효율성이 낮은 문제를 해결하려면 전체 텍스트를 생성할 수 있습니다. 색인. char, varchar 및 text 유형의 필드만 전체 텍스트 인덱스를 생성할 수 있습니다. MyISAM과 InnoDB는 모두 전체 텍스트 인덱싱을 지원합니다.
한 문장으로 요약:
Index는 데이터 검색의 효율성을 향상시키고 데이터베이스의 IO 비용을 줄일 수 있습니다.
질문하기: 시간을 위해 공간을 교환하지만 데이터 구조, 쿼리 IO 비용 및 데이터 저장 방법은 어떻습니까?
우리는 Page을 사용합니다 B+ 트리의 진화 과정을 관점에서 살펴보세요.
페이지는 InnoDB가 저장 공간을 관리하는 기본 단위입니다. InnoDB는 페이지라는 기본 저장 단위로 데이터베이스에 데이터를 저장하며, 데이터베이스는 메모리와 디스크 간의 상호 작용의 기본 단위이기도 합니다. 페이지 크기의 데이터가 메모리로 전송되고, 메모리에 있는 페이지 크기의 데이터도 디스크로 플러시됩니다.
⼼한 페이지의 메모리 크기는 16KB입니다.
이 SQL을 실행하여 10개의 레코드를 얻고 싶다고 가정해 보겠습니다.
SELECT * FROM INNODB_USER LIMIT 0 , 10;
레코드의 데이터 크기가 4K라면 한 페이지에 몇 개의 데이터를 저장할 수 있나요?
16K를 4K로 나누면 4개의 레코드가 나오죠.
페이지의 모든 데이터에는 Record_type이라는 키 속성이 있습니다.
0 일반 사용자 레코드 1 디렉터리 인덱스 레코드 2 최소 3 최대
페이지에 데이터가 배치되는 방식을 보여주는 그림을 그립니다.

이 페이지는 데이터를 저장합니다. 데이터를 기본 키에 따라 순서대로 저장합니다.
데이터 저장은 저장이 편리하다는 것을 알고 있습니다. , 쿼리하는 것은 문제가 되지 않습니다. 마지막 항목을 확인하는 경우 데이터의 전체 페이지를 탐색해야 합니까? 2.1 질문데이터를 확인하고 싶다면 어떻게 해야 빠르게 찾을 수 있나요?
링크드 리스트
페이지 페이지의 데이터가 어떻게 연결되는지(데이터가 같은 페이지에 있음):
MySQL은단방향을 통해 페이지에 있는 데이터를 연결합니다. 연결 목록 기본 키를 기반으로 쿼리하는 경우 이진 위치 지정을 사용하면 매우 빠릅니다. 기본 키가 아닌 인덱스를 기반으로 쿼리하면 가장 작은 것부터 시작하여 단방향 연결 목록만 순회할 수 있습니다.
여러 페이지 간 연결을 설정하는 방법(데이터가 서로 다른 페이지에 있음):
MySQL은 양방향 연결 목록을 통해 서로 다른 페이지를 연결하므로 이전 페이지를 통해 다음 페이지를 찾을 수 있습니다. 다음 페이지에서 한 페이지를 찾아보세요.데이터가 있는 페이지를 빠르게 찾을 수 없기 때문에 이중 연결 리스트를 따라 첫 번째 페이지부터 아래까지만 찾을 수 있습니다. 각 페이지에서 동일한 페이지를 검색합니다. 지정된 레코드를 찾는 방법이기도 하며 전체 테이블 스캔입니다.

페이지가 많아지면 쿼리에서 어떤 문제가 발생하나요?
연결된 목록의 레코드 수가 늘어나면 직접 찾을 수 없기 때문에 쿼리 속도가 느려지는 문제가 발생합니다. 소위 느린 쿼리는 실제로 다음 두 가지 문제입니다.
쿼리 시간 복잡도 0(N)
디스크에 읽고 쓰는 IO 개수가 너무 많습니다.
우리가 평소에 책을 읽다가 정보를 찾고 싶을 때 생각해 봅시다. 특정 페이지, 어떻게 해야 하나요?
카탈로그를 확인해보시죠? 디렉토리란 무엇입니까? 그냥 지수 아닌가요?
Baidu에서 디렉터리를 찾아 사진을 게시하세요.

이 디렉터리에는 두 가지 매우 중요한 정보가 있음을 발견했습니다.
콘텐츠 소개(장 제목)
페이지 번호
데이터를 빠르게 쿼리하려는 목적을 달성하기 위해 책의 목차를 참조하는 아이디어가 있습니다.
데이터에 목차를 추가하고 데이터를 확인합니다. 목차 페이지에 따라 데이터가 어느 페이지에 있는지 알아보세요. 쿼리 성능을 향상시킬 수 있는 곳.
하지만, 2.3 질문: 디렉토리를 만드는 방법은 무엇입니까? 각 페이지의 목차를 만드시겠습니까? 디렉토리를 정기적으로 만들어야 합니까? 예를 들어, 사전의 디렉토리는 알파벳 순서로 구성되어 있습니다. 어떻게 생각하셨나요? 맞습니다,기본 키. MySQL의 자동 증가 기본 키는 우리의 요구 사항을 충족하며, 내용이 적고, 각 페이지의 기본 키를 저장합니다. 규칙에 따라 포인터를 추가합니다. 쿼리할 때 기본 키 크기를 기반으로 직접 이분법을 사용하여 디렉터리를 찾은 다음 데이터를 찾습니다. 하지만 모든 데이터 페이지에 대해 디렉터리를 만들어야 하나요? 이것이 여전히 필요한 것 같습니다. 각 페이지에 대한 데이터를 생성하지 않으면 페이지에서 데이터를 어떻게 찾을 수 있습니까? 전체페이지 스캔인가요?
그러나 각 페이지마다 디렉터리를 생성해야 합니다
. 각 디렉터리를 순회해야 하며 쿼리 성능도 저하됩니다. 디렉토리에 대한 디렉토리를 생성
할 수 있나요? 그래서 디렉터리 페이지에 대한 디렉터리를 만들고 루트 노드의 한 계층을 위쪽으로 추출하면 쿼리하기가 더 쉬워집니다.
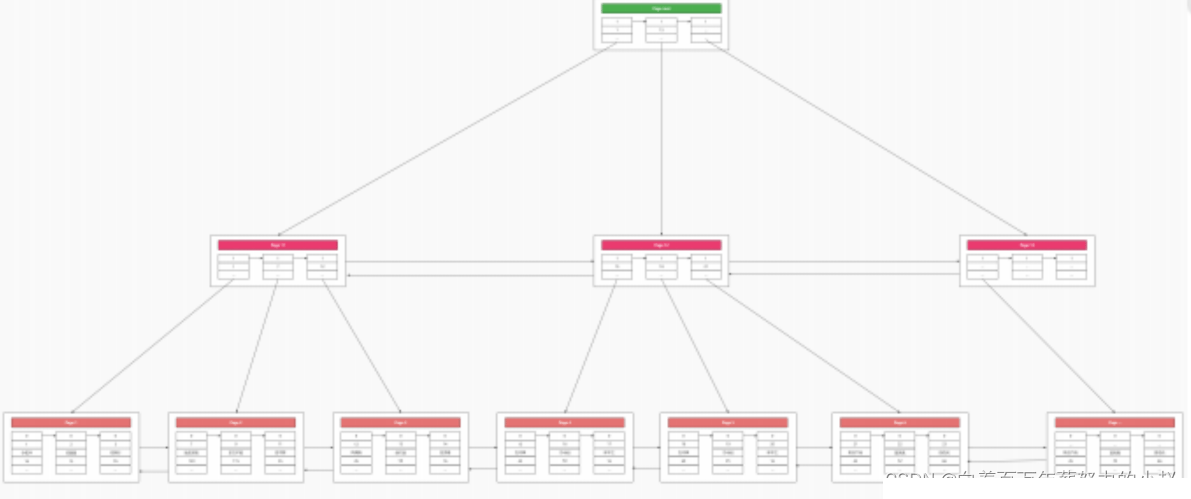 이 트리는
이 트리는
기본 키 인덱스 트리라고 부릅니다. 기본 키 인덱스 트리는 테이블의 모든 데이터를 저장하므로 MySQL에서는 Index가 데이터입니다. 데이터는 인덱스이것이 이유이기도 합니다. MysqlB+ 트리 기본키 인덱스 트리의 데이터 구조는 어떤가요? 직접 외워서 얻는 지식보다 더 인상적이신가요?
2.4 인덱스 트리, 페이지 분할 및 병합 향상된 쿼리 성능 측면에서 페이지 페이지를 추가, 수정, 삭제할 때 어떤 문제가 발생하게 됩니까?
순서 증가인데 새로운 데이터가 추가되면 어떻게 되나요? 그리고 페이지의 데이터는 다음 조건을 충족해야 합니다.
다음 데이터 페이지에 있는 사용자 레코드의 기본 키 값은 이전 페이지에 있는 사용자 레코드의 기본 키 값보다 커야 합니다.有序增加,新增一条数据怎么办?
页写满了,那么是不是得开启一个新页!
并且页的数据必须满足一个条件:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值
因为是有序增加,我们直接在页的双向链表末端增加一个页即可。
那如果是无序增加순서대로 증가하므로 , 페이지의 이중 연결 목록 끝에 직접 추가합니다. 페이지를 추가하면 됩니다.
무순증가인데 새로운 데이터가 추가된다면 어떨까요? 요약:
페이지 페이지 추가, 수정, 삭제 시 발생하는 문제:순서가 지정되지 않은 추가, 기본 키 ID 업데이트 및 인덱스 페이지 업데이트 작업이 있는 경우 많은 수의 페이지가 발생한다고 말할 수 있습니다. 노드 조정은 하위 리프 노드 페이지와 상위 리프 노드 및 루트 노드 페이지의 페이징 및 병합을 트리거하여 대량의 디스크 조각화 및 데이터베이스 성능 손실을 유발합니다. 이는 자주 업데이트되고 수정되었습니다. 색인을 생성하거나 기본 키를 업데이트하지 마세요.
요약하자면:
클러스터형 인덱스(클러스터형 인덱스):
기본 키 인덱스 트리는 클러스터형 인덱스 또는 클러스터형 인덱스라고도 합니다. InnoDB에서 테이블에는 클러스터형 인덱스 트리가 하나만 있습니다. A 테이블이 기본 키 인덱스를 생성하면 이 기본 키 인덱스는 클러스터형 인덱스입니다. 클러스터형 인덱스 트리의 키 값을 기반으로 데이터 행의 물리적 저장 순서를 결정합니다. 테이블의 모든 열입니다. 인덱스는 데이터이고 데이터는 기본 키 인덱스 트리를 참조하는 인덱스입니다.
기본 키 ID가 증가하는 추세를 갖는 것이 가장 좋은 이유는 무엇인가요?
你刚刚看完啊,不会没记住吧,有序递增,下一个数据页中用户记录的主键值必须大于上一个页中用户的主键值,假如我是趋势递增,存入的数据肯定是在最末尾链表或者新增一个链表,就不会触发页的分裂与合并,导致添加的速度变慢。
三层B+数能存多少数据?
考察点:Page页的大小,B+树的定义
1GB = 1024 M, 1mb = 1024k,1k= 1024 bytes
答:
已知:索引逻辑单元 16bytes 字节,16KB=16* 1024*1024,肯定比一千万多,在InnoDB中B+树的深度为3层就能满足千万级别的数据存储。
mysql 大字段为什么要拆分?
一个Page页可存放16K的数据,大字段占用大量的存储空间,意味着一个Page页可存储的数据条数变少,那么就需要更多的页来存储,需要更多的Page,意味着树的深度会变高。那么磁盘IO的次数会增加,性能下降,查询更慢。大字段不管是否被使用都会存放在索引上,占据大量内存空间压缩Page数据条数。
为什么用B+树?
B+树的底层是多路平衡查找树,对于每一次的查询的都是从根节点触发,到子叶结点才存放数据,根节点和非叶子结点都是存放的索引指针,查找叶子结点互,可以根据键值数据查询。具备更强的扫库、扫表能力、排序能力以及查询效率和性能的稳定性,存储能力也更强,仅使用三层B+树就能存储千万级别的数据。
刚才看的是根据主键得来的索引,我们如果不查主键,或者说表里压根就没有主键,怎么办?我们还可以根据几个字段来创建联合索引(组合索引聚合索引。。哎呀名字而已怎么叫都行)。
根据主键得到的索引树叫主键索引树,根据别的字段得到的索引树叫二级索引树。
通过下面的SQL 可以建立一个组合索引
ALTER TABLE INNODB_USER ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
其实,看似建立了1个索引,但是你使用 age 查询 age,user_name 查询 age,user_name,phone 都能生效
您也可以认为建立了三个这样的索引:
ALTER TABLE INNODB__USER ADD INDEX SECOND_INDEX_AGE__USERNAME_PHONE('age'); ALTER TABLE INNODB_USER ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name'); ALTER TABLE `INNODB_USER`ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
首先需要知道参与排序的字段类型是否有有序?
如果是有序字段,就按照有序字段排序比如(int) 1 2 3 4。
如果是无序字段,按照这个列的字符集的排序规则来排序,这点不去深入,知道就好。
我现在有一个组合索引(A-B-C)他会按照你建立字段的顺序来进行排序:
如果A相同按照B排序,如果B相同按照C排序,如果ABC全部相同,会按照聚集索引进行排序。
我们的Page会根据组合索引的字段建立顺序来存储数据,年龄 用户名 手机号。
它的数据结构其实是一样的
还是上面那个索引,年龄用户名手机号,age,username,phone
那么可以看到我们第一个字段是AGE,如果需要这个索引生效,是不是在查询的时候需要先使用Age查询,然后如果还需要user_name,就使用user_name。
只使用了user_name 能使用到索引吗?
其实是不行的,因为我是先使用age进行排序的,你必须先命中age,再命中user_name,再命中phone,这个其实
就是我们所说的最左匹配原则。
最左其实就是因为我们是按照组合索引的顺序来存储的。大家常说的"索引桥"也是这个原因。在命中组合索引中,必须像过桥一样,先跨过第一块木板,再到第二块木板,最后到第三块木板。
二级索引树有三个重要的概念,分别是回表、覆盖索引、索引下推。.
回表就是:我们查询的数据不在二级索引树中需要拿到ID去主键索引树找的过程。
覆盖索引就是:我们需要查询的数据都在二级索引树中,直接返回这种情况就叫做覆盖索引。
索引下推(index condition pushdown )简称ICP:在Mysql5.6以后的版本上推出,用于优化回表查询;
为什么离散度低的列不走索引?
분산의 개념은 무엇인가요? 동일한 데이터가 많을수록 분산이 낮아지고, 동일한 데이터가 적을수록 분산이 높아집니다.
죄송합니다. 모두 동일한 데이터를 가지고 있습니다. 어떻게 정렬하나요? 정렬할 수 없나요?
B+Tree에 중복된 값이 너무 많습니다. MySQL 옵티마이저가 인덱싱이 전체 테이블 스캔을 사용하는 것과 거의 동일하다고 판단하면 인덱스를 생성하더라도 진행되지 않습니다. 인덱스 사용 여부는 MySQL 최적화 프로그램에 의해 결정됩니다.
인덱스는 많을수록 좋나요?
공간 측면에서: 시간과 공간을 교환하려면 인덱스가 디스크 공간을 차지해야 합니다.
시간: 인덱스를 실행하여 쿼리 효율성을 높이세요. 업데이트 및 삭제인 경우 페이지 분할 및 병합이 발생하여 삽입 및 업데이트 문의 응답 시간에 영향을 주지만 성능은 저하됩니다.
자주 업데이트해야 하는 열인 경우 페이지 분할 및 병합이 자주 발생하므로 인덱스를 생성하지 않는 것이 좋습니다.
결합 인덱스(복합 인덱스)라고도 하는 보조 인덱스 트리는 인덱스 생성 시 열 이름의 순서를 저장합니다. 열 이름에 데이터가 있으면 쿼리를 지원하고 쿼리 효율성을 향상시키기 위해 보조 인덱스 트리가 탄생했습니다. 보조 인덱스 트리에는 테이블 반환, 인덱스 포함 및 인덱스 푸시다운의 세 가지 작업이 있습니다. 그 중 가장 성능이 좋은 것은 커버링 지수입니다.
온라인에서 차이점 그림을 찾았습니다
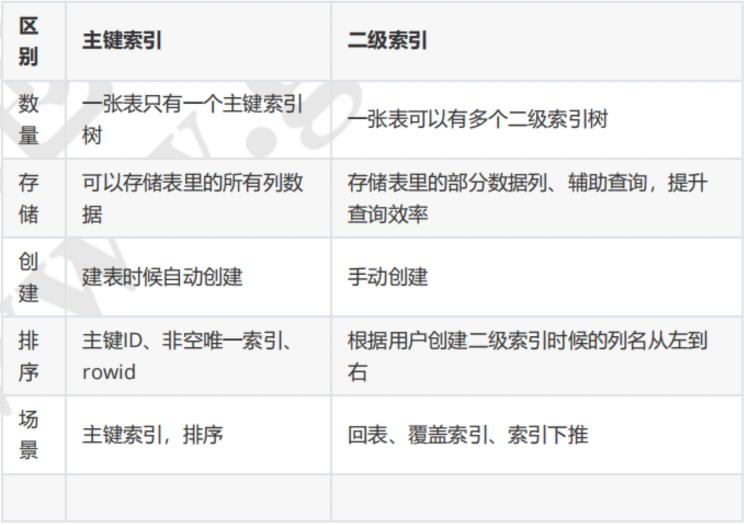
위 내용은 MySQL 인덱스 지식 포인트 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



