


예를 들어 현재 test_user 테이블이 있는데 이 테이블에 300만 개의 데이터를 삽입합니다.
CREATE TABLE `test_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `user_id` varchar(36) NOT NULL COMMENT '用户id', `user_name` varchar(30) NOT NULL COMMENT '用户名称', `phone` varchar(20) NOT NULL COMMENT '手机号码', `lan_id` int(9) NOT NULL COMMENT '本地网', `region_id` int(9) NOT NULL COMMENT '区域', `create_time` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT;
데이터베이스 개발 과정에서 페이징을 자주 사용하는 것이 핵심 기술입니다. limit start, count Paging 문은 데이터를 읽습니다.
0, 10000, 100000, 500000, 1000000, 1800000(페이지당 100개 항목)부터 페이징 실행 시간을 살펴보겠습니다.
SELECT * FROM test_user LIMIT 0,100; # 0.031 SELECT * FROM test_user LIMIT 10000,100; # 0.047 SELECT * FROM test_user LIMIT 100000,100; # 0.109 SELECT * FROM test_user LIMIT 500000,100; # 0.219 SELECT * FROM test_user LIMIT 1000000,100; # 0.547s SELECT * FROM test_user LIMIT 1800000,100; # 1.625s
시작 기록이 늘어날수록 시간도 늘어나는 것을 확인했습니다. 시작 레코드를 290만으로 변경한 후 페이징 문의 시작 페이지 번호와 제한 사이에 큰 상관 관계가 있음을 알 수 있습니다
SELECT * FROM test_user LIMIT 2900000,100; # 3.062s
MySQL의 페이징 시작 지점이 더 크다는 사실에 놀랐습니다. 데이터가 크고 쿼리가 느려집니다!
그렇다면 왜 위와 같은 상황이 발생하는 걸까요?
답변: limit 2900000,100 구문은 실제로 mysql이 처음 2900100개의 데이터 조각을 스캔한 다음 처음 3000000개의 행을 삭제한다는 의미이기 때문입니다.
이로부터 다음 두 가지 결론을 내릴 수도 있습니다.
제한 문의 쿼리 시간은 시작 레코드의 위치에 비례합니다.
MySQL의 Limit 문은 매우 편리하지만, 레코드가 많은 테이블에 직접 사용하기에는 적합하지 않습니다.
limit 절을 사용하면 select 문이 지정된 수의 레코드를 반환하도록 할 수 있습니다. 구문 형식은 다음과 같습니다.
SELECT * FROM 表名 limit m,n; SELECT * FROM table LIMIT [offset,] rows;
limit는 하나 또는 두 개의 숫자 매개 변수를 허용합니다. 두 개의 매개변수가 제공되는 경우 매개변수는 정수 상수여야 합니다.
첫 번째 매개변수는 처음 반환된 레코드 행의 오프셋을 지정합니다.
두 번째 매개변수는 반환된 레코드 행의 최대 수를 지정합니다.
2.1m은 m+1개 레코드를 나타냅니다. 행이 검색되기 시작하고 n은 n개의 데이터를 가져오는 것을 나타냅니다. (m은 0으로 설정 가능)
SELECT * FROM 表名 limit 6,5;
위 SQL은 7번째 레코드 행부터 5개의 데이터를 꺼낸다는 의미입니다.
2.2 n은 -1로 설정할 수 있다는 점에 유의하세요. n은 -1이며, 이는 m+1 행부터 마지막 데이터가 검색될 때까지 검색이 시작됨을 나타냅니다.
SELECT * FROM 表名 limit 6,-1;
위 SQL은 6번째 레코드 행 이후의 모든 데이터가 검색됨을 나타냅니다.
2.3 m만 제공되면, 첫 번째 레코드 행부터 데이터를 가져온다는 의미입니다. 계산을 시작하고 총 m개의 행을 꺼냅니다.
SELECT * FROM 表名 limit 6;
2.4 처음 3개 행을 나이 역순으로 꺼냅니다.
select * from student order by age desc limit 3;
2.5 처음 3개 행을 건너뛰고 그런 다음 다음 2개 행을 가져옵니다
select * from student order by age desc limit 3,2;
먼저 마지막 페이징의 최대 ID를 찾은 다음 해당 ID의 인덱스를 사용하여 쿼리:
SELECT * FROM test_user WHERE id>1000000 LIMIT 100; # 0.047秒
이 최적화된 SQL을 사용하면 이미 이전 쿼리보다 11배 더 빠릅니다. 기본 키 ID를 사용하는 것 외에도 고유 인덱스를 사용하여 특정 데이터를 빠르게 찾을 수 있으므로 전체 테이블 스캔을 피할 수 있습니다. 다음은 1000~1019 범위의 고유 키(pk)를 사용하여 데이터를 읽기 위한 해당 SQL 최적화 코드입니다.
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
이유: 인덱스 스캔이 매우 빠릅니다.
적용 가능한 시나리오: 데이터 쿼리가 pk 또는 id별로 정렬되고 모든 데이터가 누락되지 않은 경우 이 방법으로 최적화할 수 있습니다. 그렇지 않으면 페이징 작업에서 데이터가 누출됩니다.
인덱스 쿼리를 사용하는 명령문에 해당 인덱스 열(즉, 인덱스 적용 범위)만 포함되어 있으면 쿼리 속도가 매우 빨라진다는 사실은 우리 모두 알고 있습니다.
색인 범위 쿼리가 왜 이렇게 빠른가요?
답변: 인덱스 검색에는 최적화 알고리즘이 있고, 쿼리 인덱스에 데이터가 있기 때문에 관련 데이터 주소를 찾을 필요가 없어 시간이 많이 절약됩니다. 동시성이 높을 때 Mysql은 인덱스와 관련된 캐시도 제공합니다. 이 캐시를 최대한 활용하면 더 나은 결과를 얻을 수 있습니다.
id 필드는 테스트 테이블 test_user의 기본 키이므로 기본 키 인덱스가 기본적으로 포함됩니다. 이제 포함 인덱스를 사용하는 쿼리가 어떻게 수행되는지 살펴보겠습니다.
이번에는 1000001부터 1000100까지의 데이터를 쿼리합니다(커버 인덱스 사용, id 열만 포함).
SELECT id FROM test_user LIMIT 1000000,100; # 0.843秒
이 결과에서 쿼리 속도가 전체 테이블 스캔보다 느린 것을 확인했습니다(물론, 이 SQL을 반복적으로 실행한 후 여러 쿼리 후에 속도가 훨씬 빨라지고 거의 절반의 시간이 절약되었습니다. 이는 캐싱으로 인한 것입니다. 그런 다음 explain 명령을 사용하여 SQL의 실행 계획을 보고 일반 SQL 실행에 사용되는 인덱스는 idx_user_id:
EXPLAIN SELECT id FROM test_user LIMIT 1000000,100;
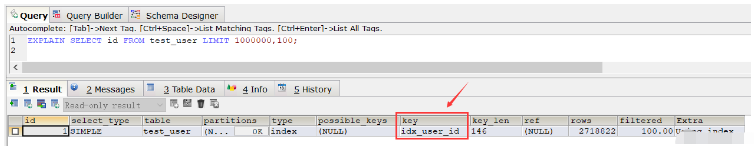
일반 인덱스를 삭제하면 위 SQL 실행 시 기본키 인덱스가 사용됩니다. 일반 인덱스를 삭제하지 않는 경우, 이 경우 위의 SQL이 기본 키 인덱스를 사용하도록 하려면 order by 문을 사용할 수 있습니다.
SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100; # 0.250秒
그런 다음 모든 열도 쿼리하려면 두 가지가 있습니다. 방법 중 하나는 id>=이고, 다른 하나는 조인을 사용하는 것입니다.
첫 번째 작성 방법:
SELECT * FROM test_user WHERE ID >= (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,1) LIMIT 100;
위 SQL 쿼리 시간은 0.281초
두 번째 작성 방법:
SELECT * FROM (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100) a LEFT JOIN test_user b ON a.id = b.id;
위 SQL 쿼리 시간은 0.252초
여기서 pageNum은 페이지 번호를 나타내며, 해당 값은 0부터 시작합니다. pageSize는 페이지당 데이터 조각 수를 나타냅니다.
SELECT * FROM 表名称 WHERE id_pk > (pageNum*pageSize) ORDER BY id_pk ASC LIMIT pageSize;
适应场景:
适用于数据量多的情况
最好ORDER BY后的列对象是主键或唯一索引
id数据没有缺失,可以作为序号使用
使用ORDER BY操作能利用索引被消除,但结果集是稳定的
原因:
索引扫描,速度会很快
但MySQL的排序操作,只有ASC没有DESC。在MySQL中,索引的存储顺序是升序ASC,没有降序DESC的索引。这就是为什么默认情况下,order by 是按照升序排序的原因
PREPARE预编译一个SQL语句,并为其分配一个名称 stmt_name,以便以后引用该语句,预编译好的语句用EXECUTE执行。
PREPARE stmt_name FROM 'SELECT * FROM test_user WHERE id > ? ORDER BY id ASC LIMIT ?'; SET @a = 1000000; SET @b = 100; EXECUTE stmt_name USING @a, @b;;

上述SQL查询时间为0.047秒。
对于定义好的PREPARE预编译语句,我们可以使用下述命令来释放该预编译语句:
DEALLOCATE PREPARE stmt_name;
原因:
索引扫描,速度会很快.
prepare语句又比一般的查询语句快一点。
其中page表示页码,其取值从0开始;pagesize表示指的是每页多少条数据。
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id DESC LIMIT ($page-1)*$pagesize ORDER BY id DESC LIMIT $pagesize);
假设数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中id是主键自增,title用定长,info用text, vtype是tinyint,vtype是一个普通索引。
现在往里面填充数据,填充10万条记录,数据库表占用硬1.6G。
select id,title from collect limit 1000,10;
执行上述SQL速度很快,基本上0.01秒就OK。
select id,title from collect limit 90000,10;
然后再执行上述SQL,就发现非常慢,基本上平均8~9秒完成。
这个时候如果我们执行下述,我们会发现速度又变的很快,0.04秒就OK。
select id from collect order by id limit 90000,10;
那么这个现象的原因是什么?
答案:因为用了id主键做索引, 这里实现了索引覆盖,当然快。
所以如果想一起查询其它列的话,可以按照索引覆盖进行优化,具体如下:
select id,title from collect where id >= (select id from collect order by id limit 90000,1) limit 10;
再看下面的语句,带上where 条件:
select id from collect where vtype=1 order by id limit 90000,10;
可以发现这个速度上也是很慢的,用了8~9秒!
这里有一个疑惑:vtype 做了索引了啊?怎么会慢呢?
vtype做了索引是不错,如果直接对vtype进行过滤:
select id from collect where vtype=1 limit 1000,10;
可以看到速度还是很快的,基本上0.05秒,如果从9万开始,那就是0.05*90=4.5秒的速度了。
其实加了 order by id 就不走索引,这样做还是全表扫描,解决的办法是:复合索引!
因此针对下述SQL深度分页优化时可以加一个search_index(vtype,id)复合索引:
select id from collect where vtype=1 order by id limit 90000,10;
综上:
在进行SQL查询深度分页优化时,如果对于有where条件,又想走索引用limit的,必须设计一个索引,将where放第一位,limit用到的主键放第二位,而且只能select 主键。
最后根据查询出的主键走一级索引找到对应的数据。
按这样的逻辑,百万级的limit 在0.0x秒就可以分完,完美解决了分页问题。
위 내용은 MySQL 튜닝에서 SQL 쿼리의 딥 페이징 문제를 해결하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



