


인덱스는 기본 구현에 따라 B-Tree 인덱스와 해시 인덱스로 나눌 수 있습니다. 대부분의 경우 B-Tree 인덱스가 좋은 성능과 특성을 갖고 있기 때문에 Build에 더 적합합니다. 높은 동시성 시스템.
인덱스의 저장 방식에 따라 인덱스는 클러스터형 인덱스와 비클러스터형 인덱스로 나눌 수 있습니다. 비클러스터형 인덱스의 리프 노드에는 모든 필드와 기본 키 ID만 포함되는 반면, 클러스터형 인덱스의 리프 노드에는 전체 레코드 행이 포함됩니다.
클러스터형 인덱스와 비클러스터형 인덱스에 따라 다시 일반 인덱스, 커버링 인덱스, 고유 인덱스, 공동 인덱스로 나눌 수 있습니다.
클러스터형 인덱스는 클러스터형 인덱스라고도 하며, 실제로는 별도의 인덱스 형태가 아닌 데이터 저장 방식입니다. 클러스터형 인덱스의 리프 노드는 모든 열 정보를 하나로 기록합니다. 열. 즉, 클러스터형 인덱스의 리프 노드에는 완전한 레코드 행이 포함됩니다.
비클러스터형 인덱스는 보조 인덱스, 일반 인덱스라고도 하며 리프 노드에는 기본 키 값이 하나만 포함되어 있습니다. 비클러스터형 인덱스를 통해 레코드를 찾으려면 먼저 기본 키를 사용하여 찾아야 합니다. 클러스터형 인덱스의 해당 레코드입니다. 이 프로세스를 테이블 반환이라고 합니다.
예를 들어, 사용자 이름과 연령이 포함된 데이터 테이블에서 기본 키가 사용자 ID라고 가정하면 클러스터형 인덱스의 구조는 다음과 같습니다(주황색은 ID를 나타내고 녹색은 하위 노드에 대한 포인터):
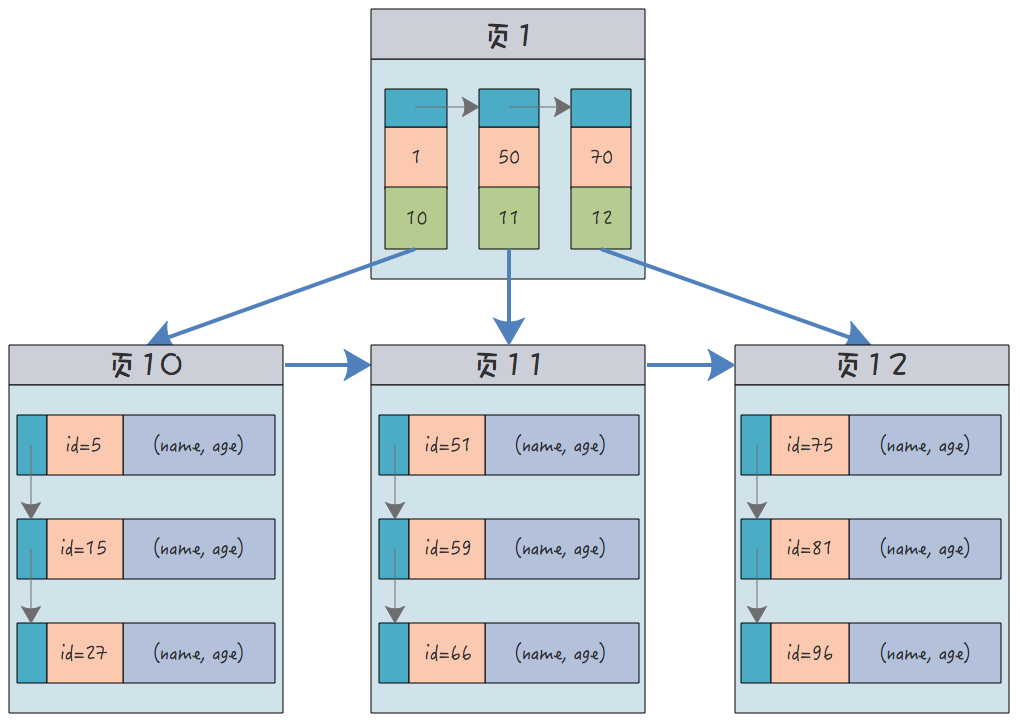
리프 노드에서는 레코드를 강조하기 위해(id, name, age)가 구별되며 실제로는 서로 연결되어 레코드 전체를 형성합니다.
비클러스터형 인덱스(연령별로 인덱싱됨)의 구조는 다음과 같습니다.
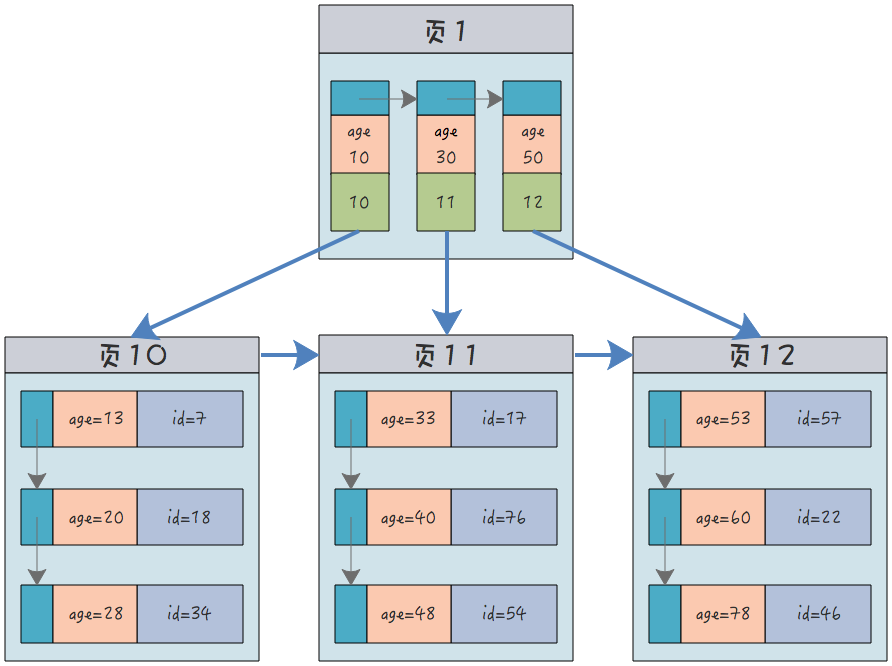
age 필드 자체 외에도 이 노드의 리프 노드에는 현재 레코드의 기본 키 ID만 포함됩니다. 완전한 기록 정보가 아닙니다. 레코드 데이터의 전체 행을 얻으려면 ID 번호를 통해 클러스터형 인덱스를 쿼리해야 합니다.
InnoDB에서 각 테이블에는 기본적으로 기본 키를 기반으로 생성되는 클러스터형 인덱스가 있어야 합니다. 테이블에 기본 키가 없으면 InnoDB는 적합한 열을 클러스터형 인덱스로 선택합니다. 적합한 열이 없으면 숨겨진 열 DB_ROW_ID가 클러스터형 인덱스로 사용됩니다.
비클러스터형 인덱스에는 완전한 데이터 정보가 포함되어 있지 않기 때문에 완전한 데이터 레코드를 검색하려면 테이블 반환이 필요하므로 하나의 쿼리 작업에는 실제로 두 개의 인덱스 쿼리가 필요합니다. 결과를 얻기 위해 모든 인덱스 쿼리를 두 번 실행해야 한다면 필연적으로 효율성이 떨어지게 됩니다. 쿼리를 하나씩 줄일 수 있으면 하나씩 줄여야 하기 때문입니다.
위의 연령 인덱스는 비클러스터형 인덱스입니다. 사용자의 ID를 연령별로 쿼리하려면 다음 명령문을 실행합니다.
1 |
select id from 나이 = 10; |
이 경우에도 시계를 반납해야 하나요? id 값만 필요하기 때문에 이미 age index를 통해 id를 얻을 수 있는데, 그래도 한 번 테이블로 돌아가면 소용없는 작업이 되지 않을까요? 실제로는 필요하지 않습니다. 보조 인덱스에 쿼리에 필요한 모든 정보가 이미 포함되어 있는 경우 인덱스 쿼리에서는 테이블 반환 작업을 피할 수 있습니다.
결합 인덱스는 여러 열에 동시에 생성된 인덱스를 의미하며, 결합 인덱스를 생성한 후 리프 노드에는 각 인덱스 열의 값이 동시에 포함되며 그에 따라 정렬됩니다. 동시에 여러 열에 정렬하는 작업은 사전순으로 이해하는 것과 동일합니다.
예를 들어, 위의 이름과 연령에 대해 동시에 생성된 색인 구조:
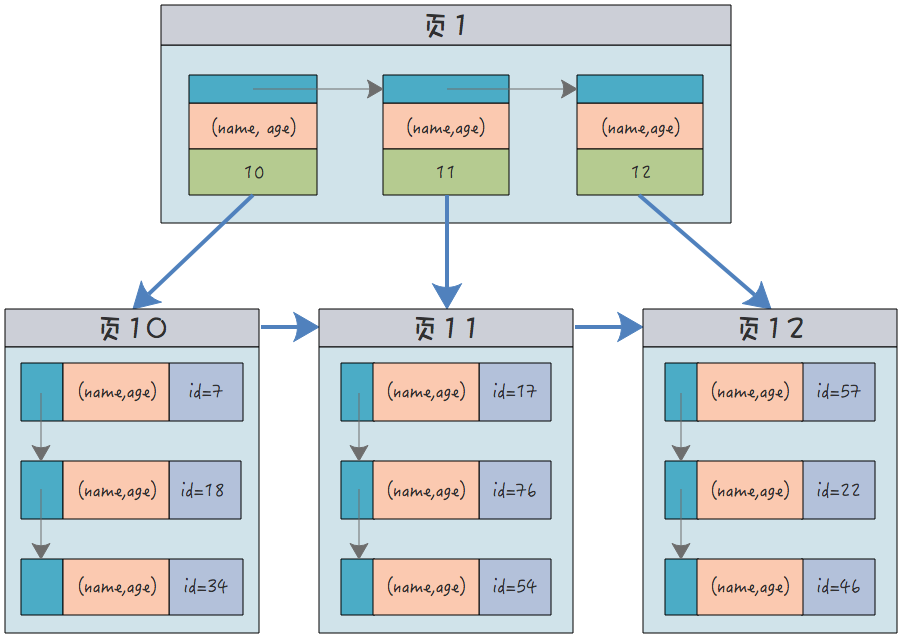
(name, age)는 모두 약어이며 열두 개 이상의 이름을 생각할 수 없습니다.
각 리프 노드는 모든 인덱스 열을 동시에 저장하며 여전히 기본 키 ID만 포함합니다.
여러 열에 대해 인덱스를 생성할 때 인덱스가 생성된 열이 포함되어 있는 한 인덱스를 사용할 수 없습니다. 인덱스 사용은 가장 왼쪽 접두사 일치 원칙을 따라야 합니다.
열 (A, B, C)에 인덱스를 생성한다고 가정하면 다음 시나리오에서만 인덱스를 사용할 수 있습니다.
열 (A, B, C)/(A, C) 또는 (A에 대한 쿼리) , B) 인덱스와 일치하며 (C, A) 또는 (B, C)에는 인덱스를 사용할 수 없습니다.
와일드카드는 LIKE '%VAL%'가 아닌 LIKE 'val%' 형식만 사용할 수 있으므로 전체 테이블 스캔이 발생합니다.
인덱스 열을 연산할 수 없습니다. 예를 들어 WHERE A + 1 = 5이면 인덱스가 실패합니다.
인덱스 열은 LIKE/BETWEEN/>/
인덱스 열에는 NULL 값이 포함될 수 없습니다.
MySQL의 새 버전(5.6 이상)에는 인덱스 푸시다운 메커니즘이 도입되었습니다. 인덱스 순회 프로세스 중에 인덱스에 포함된 필드를 먼저 판단할 수 있으며, 조건을 충족하지 않는 필드는 조건을 직접 필터링할 수 있습니다. 테이블 반환 횟수를 기록하고 줄일 수 있습니다.
예를 들어 위 테이블의 (이름, 나이)에 대한 공동 인덱스를 수행합니다. 일반적인 상황에서의 쿼리 논리는 다음과 같습니다.
이름을 통해 해당 기본 키 ID를 찾습니다.
나이 조건을 기준으로 일치합니다. id 레코드의 열
이러한 접근 방식은 불필요한 테이블 반환을 많이 발생시킵니다. 예를 들어 현재 테이블에는 두 개의 레코드(Zhang San, 10)와 (Zhang San, 15)가 있습니다. (장산(20)씨)의 기록을 조회해볼 필요가 있다. 쿼리할 때 먼저 Zhang San을 통해 조건을 충족하는 모든 기본 키 ID를 찾은 다음 클러스터형 인덱스에서 조건을 충족하는 행을 순회하여 age = 20과 일치하는 레코드가 있는지 확인합니다. 실제 상황에서는 조건에 맞는 기록이 없어 이번 테이블 반환 과정은 무익한 행보로 볼 수 있다.
이를 개선하는 것이 인덱스 푸시다운의 주요 기능입니다. 공동 인덱스에서는 테이블에 반환할 필요가 없는 레코드를 이름과 나이별로 필터링한 다음 인덱스를 테이블에 반환하여 개수를 줄입니다. 테이블 반환.
고유 인덱스는 동일한 인덱스 값을 허용하지 않는 인덱스입니다. 인덱스 생성 시 시스템에서 레코드가 업데이트되거나 추가될 때마다 확인됩니다. . 기본 키 인덱스는 고유 인덱스입니다.
위 내용은 MySQL의 클러스터형 인덱스, 비클러스터형 인덱스, 조인트 인덱스 및 고유 인덱스란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!





























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



