


응용 시스템 개발 과정에서는 초기 데이터의 양이 적기 때문에 개발자들은 SQL 문을 작성할 때 기능적 구현에 더 많은 관심을 기울이게 됩니다. 그러나 응용 시스템이 정식 출시되면 급격한 증가를 겪게 됩니다. 생산 데이터의 양이 증가함에 따라 많은 SQL 문이 점차 성능 문제를 드러내기 시작하고 생산 환경에 미치는 영향도 증가하고 있습니다. 이때 이러한 문제가 있는 SQL 문은 전체 시스템 성능의 병목 현상이 되므로 최적화해야 합니다.
MySQL 클라이언트가 성공적으로 연결되면 show [session|global]status 명령을 통해 서버 상태 정보를 제공하거나 mysqladmin 확장을 사용할 수 있습니다. -운영 체제 명령의 상태를 확인하여 이러한 메시지를 확인하세요. show [session|global] status 필요에 따라 "session" 또는 "global" 매개변수를 추가하여 세션 수준(현재 연결)의 통계 결과와 전역 수준(데이터베이스가 마지막으로 시작된 이후)의 통계 결과를 표시할 수 있습니다. ). 작성하지 않은 경우 사용되는 기본 매개변수는 "session"입니다.
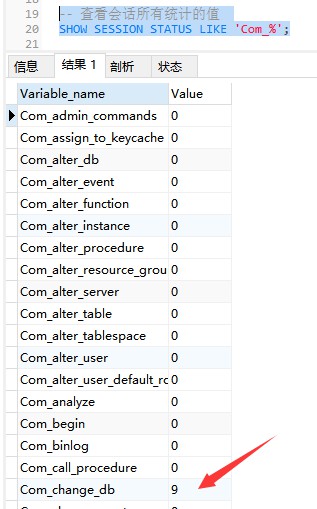
다음 명령은 현재 세션의 모든 통계 매개변수 값을 표시합니다.
-- 查看会话所有统计的值 SHOW STATUS LIKE 'Com_%'; Or SHOW SESSION STATUS LIKE 'Com_%';
다음 명령은 현재 전역의 모든 통계 매개변수 값을 표시합니다.
-- 값 보기 모든 전역 통계 중
SHOW GLOBAL STATUS LIKE 'Com_%';
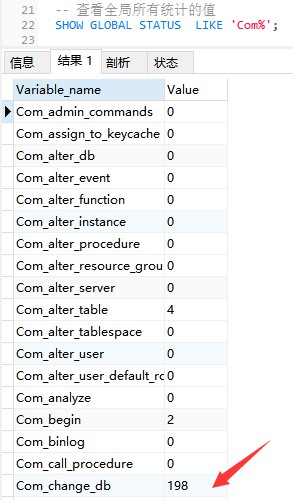
Com_xxx는 각 xxx 문이 실행되는 횟수를 나타냅니다. 일반적으로 다음 통계 매개변수에 관심을 둡니다.
Com_select: SELECT 작업이 실행되는 횟수는 1입니다. 하나의 쿼리에 대해 누적되었습니다.
Com_insert: INSERT 작업을 수행하는 횟수입니다. 일괄 삽입 INSERT 작업의 경우 한 번만 누적됩니다.
Com_update: UPDATE 작업이 수행되는 횟수입니다.
Com_delete: DELETE 작업을 수행하는 횟수입니다.
위의 매개변수는 모든 스토리지 엔진 테이블 작업에 대해 누적됩니다. 이러한 매개변수는 InnoDB 스토리지 엔진에만 적용되며 누적 알고리즘은 약간 다릅니다.
Innodb_rows_read: SELECT 쿼리에서 반환된 행 수입니다.
Innodb_rows_inserted: INSERT 작업을 수행하여 삽입된 행 수입니다.
Innodb_rows_updated: UPDATE 작업으로 업데이트된 행 수입니다.
Innodb_rows_deleted: DELETE 작업으로 삭제된 행 수입니다.
위의 매개변수를 통해 현재 데이터베이스 응용 시스템이 주로 삽입과 업데이트 또는 쿼리 연산을 기반으로 하는지, 다양한 유형의 SQL의 대략적인 실행 비율은 얼마인지 쉽게 이해할 수 있습니다. 커밋이나 롤백과 관계없이 업데이트 작업 횟수가 누적되며, count 개체는 실행 횟수입니다.
트랜잭션 애플리케이션의 경우 Com_commit 및 Com_rollback을 사용하여 트랜잭션 제출 및 롤백을 이해할 수 있습니다. 롤백 작업이 매우 빈번한 데이터베이스의 경우 애플리케이션 작성에 문제가 있음을 의미할 수 있습니다. 또한 다음 매개변수는 사용자가 데이터베이스의 기본 상황을 이해하는 데 도움이 됩니다.
연결: MySQL 서버에 연결을 시도한 횟수입니다.
가동 시간: 서버 작동 시간.
Slow_queries: 느린 쿼리 수입니다.
다음 두 가지 방법으로 실행 효율성이 낮은 SQL 문을 찾을 수 있습니다.
느린 쿼리 로그를 통해 실행 효율성이 낮은 SQL 문을 찾습니다. --log-slow-queries[=file_name] 옵션으로 시작하면 mysqld는 실행 시간이 long_query_time 초를 초과하는 모든 SQL 문을 포함하는 로그 파일을 작성합니다.
느린 쿼리 로그는 쿼리가 완료된 후 기록됩니다. 따라서 응용 프로그램 시스템에서 실행 효율성 문제가 반영되는 경우 느린 쿼리 로그를 쿼리하여 문제를 찾을 수 없습니다. 현재 MySQL 스레드를 보려면 , 스레드를 포함하여 상태, 테이블 잠금 여부 등을 실시간으로 확인하고 일부 테이블 잠금 작업을 동시에 최적화할 수 있습니다.
실행 효율성이 낮은 SQL 문을 찾은 후 EXPLAIN 또는 DESC 명령을 사용하여 실행 중을 포함하여 MySQL이 SELECT 문을 실행하는 방법에 대한 정보를 얻을 수 있습니다. 테이블을 연결하는 방법과 연결 순서 예를 들어 모든 재고 사다리의 수를 계산하려면 products_stock 테이블과 products_stock_price 테이블을 연결하고 합계 연산을 수행해야 합니다. Goods_stock_price.Qty 필드에 해당하는 SQL 실행 계획은 다음과 같습니다.
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

위 그림과 같이 각 컬럼에 대한 간단한 설명은 다음과 같습니다.
select_type: SELECT 유형을 나타냅니다. 일반적인 값은 다음과 같습니다:
SIMPLE(간단한 테이블, 즉 테이블 연결이나 하위 쿼리가 사용되지 않음).
PRIMARY(주 쿼리, 즉 외부 쿼리), UNION(UNION의 두 번째 또는 후속 쿼리 문), ◎SUBQUERY(하위 쿼리의 첫 번째 SELECT) 등
table: 결과 집합을 출력하는 테이블입니다.
type:表示表的连接类型,性能由好到差的连接类型为:
system(表中仅有一行,即常量表)。
const(单表中最多有一个匹配行,例如primary key或者unique index)。
eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用primary key或者unique index)。
ref(与eq_ref类似,区别在于不是使用primary key或者unique index,而是使用普通的索引)。
ref_or_null(与ref类似,区别在于条件中包含对NULL的查询)。
index_merge(索引合并优化)。
unique_subquery(in的后面是一个查询主键字段的子查询)。
index_subquery(与unique_subquery类似,区别在于in的后面是查询非唯一索引字段的子查询)。
range(单表中的范围查询)。
index(对于前面的每一行,都通过查询索引来得到数据)。
all(对于前面的每一行,都通过全表扫描来得到数据)。
possible_keys:表示查询时,可能使用的索引。
key:表示实际使用的索引。
key_len:索引字段的长度。
rows:扫描行的数量。
filtered:返回结果的行占需要读到的行(rows列的值)的百分比。
Extra:执行情况的说明和描述。
Using index(此值表示mysql将使用覆盖索引,以避免访问表)。
Using where(mysql 将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。“Using where”有时提示了一种可能性:查询可以从不同的索引中受益。
Using temporary(mysql 对查询结果排序时会使用临时表)。
MySQL will apply an external index sorting on the results instead of reading rows from the table in index order.。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成)。
Range checked for each record(index map: N) (没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的)。
经过以上定位步骤,我们基本就可以分析到问题出现的原因。此时我们可以根据情况采取相应的改进措施,进行优化提高语句执行效率。
在上面的例子中,已经可以确认是goods_stock是走主键索引的,但是对goods_stock_price子表的进行了全表扫描导致效率的不理想,那么应该对goods_stock_price表的GoodsStockID字段创建索引,具体命令如下:
-- 创建索引 CREATE INDEX idx_stock_price_1 ON goods_stock_price (GoodsStockID); -- 附加删除跟查询索引语句 ALTER TABLE goods_stock_price DROP INDEX idx_stock_price_1; SHOW INDEX FROM goods_stock_price;
创建索引后,我们再看一下这条语句的执行计划,具体如下:
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

可以发现建立索引后对goods_stock_price子表需要扫描的行数明显减少(从 3 行减少到1行),可见索引的使用可以大大提高数据库的访问速度,尤其在表很庞大的时候这种优势更为明显。
위 내용은 MySQL에서 SQL 문을 최적화하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!





























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



