

Redis는 요청/응답 프로토콜 구현이라고도 알려진 클라이언트-서버 모드 TCP 서비스입니다. client-server模式的TCP服务,也被称为Request/Response协议的实现。

这意味着通常一个请求的完成是遵循下面两个步骤:
Client发送一个操作命令给Server,从TCP的套接字Socket中读取Server的响应值,通常来说这是一种阻塞的方式
Server执行操作命令,然后将响应值返回给Client
举个例子
Client: INCR X Server: 1 Client: INCR X Server: 2 Client: INCR X Server: 3 Client: INCR X Server: 4
Clients和Servers是通过网络进行连接。网络连接速度可能会快得很快(例如本地回环网络)或者慢得很慢(例如跨越多个主机的网络)。不管网络怎么样,一个数据包从Client到Server,然后相应值又从Server返回Client都需要一定的时间。
这个时间被称为RTT(Round Trip Time)。当一个Client需要执行多个连续请求(比如添加许多个元素到一个list中,或者清掉Redis中许多个键值对),那么RTT是怎样影响到性能的呢?这个也是很方便去计算的。比如如果RTT的时间为250ms(假设互联网连接速度非常慢),即使Server可以每秒处理100k个请求,那么最多也只能接受每秒4个请求。
如果是回环网络,RTT将会特别的短(比如作者的127.0.0.1,RTT的响应时间为44ms),但是对于执行连续多次写操作时,也是一笔不小的消耗。
其实我们有其他办法来降低这种场景的消耗,开心不?惊喜不?
在一个Request/Response方式的服务中有一个特性:即使Client没有收到之前的响应值,也可以继续发送新的请求。这种特性意味着我们可以不需要等待Server的响应,可以率先发送许多操作命令给Server,然后在一次性读取Server的所有响应值。
这种方式被称为Pipelining技术,该技术近几十年来被广泛的使用。比如多POP3协议的实现就支持这个特性,大大的提升了从server端下载新的邮件的速度。
Redis在很早的时候就支持该项技术,所以不管你运行的是什么版本,你都可以使用pipelining技术,比如这里有一个使用 netcat 工具的:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379 +PONG +PONG +PONG
现在我们不需要为每一次请求付出RTT的消耗了,而是一次性发送三个操作命令。为了便于直观的理解,还是拿之前的说明,使用pipelining技术该的实现顺序如下:
Client: INCR X Client: INCR X Client: INCR X Client: INCR X Server: 1 Server: 2 Server: 3 Server: 4
划重点(敲黑板):当client使用pipelining发送操作命令时,server端将强制使用内存来排列响应结果。所以在使用pipelining发送大量的操作命令的时候,最好确定一个合理的命令条数,一批一批的发送给Server端,比如发送10k个操作命令,读取响应结果,再发送10k个操作命令,以此类推…虽然说耗时近乎相同,但是额外的内存消耗将是这10k操作命令的排列响应结果所需的最大值。(为防止内存耗尽,选择一个合理的值)
Pipelining不是减少因为 RTT 造成消耗的唯一方式,但是它确实帮助你极大的提升每秒的执行命令数量。事实的真相是:从访问相应的数据结构并且生成答复结果的角度来看,不使用pipelining确实代价很低;但是从套接字socket I/O的角度来看,恰恰相反。因为这涉及到了read()和write()调用,需要从用户态切换到内核态。这种上下文切换会特别损耗时间的。
一旦使用了pipelining技术,很多操作命令将会从同一个read()调用中执行读操作,大量的答复结果将会被分发到同一个write()调用中执行写操作。基于此,随着管道的长度增加,每秒执行的查询数量最开始几乎呈直线型增加,直到不使用pipelining技术的基准的10倍,如下图:
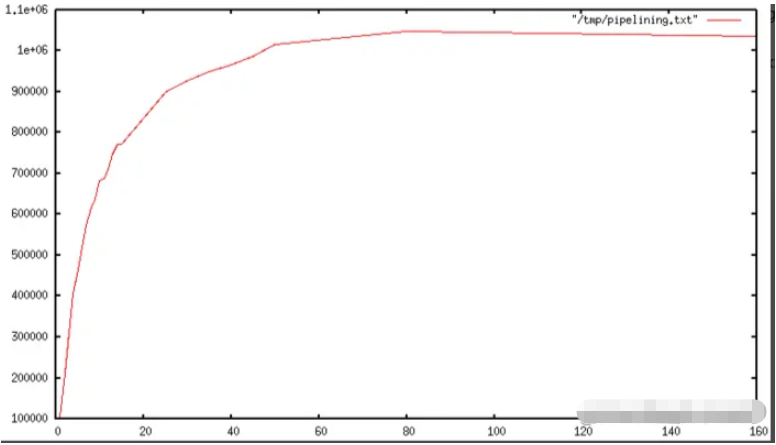
不翻译,基本上就是说使用了pipelining
🎜🎜이것은 일반적으로 다음 두 단계를 수행하여 요청이 완료됨을 의미합니다. 🎜FOR-ONE-SECOND:
Redis.SET("foo","bar")
END요청/응답 서비스에는 클라이언트가 이전 응답 값을 받지 못하더라도 계속해서 새로운 요청을 보낼 수 있는 기능이 있습니다. 이 기능은 서버의 응답을 기다릴 필요가 없다는 것을 의미합니다. 먼저 서버에 많은 작업 명령을 보낸 다음 서버의 모든 응답 값을 한 번에 읽을 수 있습니다. 🎜🎜이 방법을 파이프라이닝 기술이라고 하는데, 최근 수십 년 동안 널리 사용되었습니다. 예를 들어, 여러 POP3 프로토콜을 구현하면 이 기능이 지원되므로 서버에서 새 이메일을 다운로드하는 속도가 크게 향상됩니다. 🎜🎜Redis는 이 기술을 매우 일찍 지원했으므로 실행 중인 버전에 관계없이 파이프라이닝 기술을 사용할 수 있습니다. 예를 들어 다음은 netcat 도구를 사용하는 것입니다. 🎜rrreee🎜Now We no. 더 이상 각 요청에 대해 RTT를 지불해야 하지만 한 번에 세 가지 작업 명령을 보냅니다. 직관적인 이해를 돕기 위해 이전 지침을 살펴보겠습니다. 파이프라이닝 기술을 사용하는 구현 순서는 다음과 같습니다. 🎜rrreee🎜강조(칠판을 두드리세요): 클라이언트가 파이프라이닝을 사용할 때. to send 명령을 실행할 때 서버 측은 응답 결과를 정렬하기 위해 메모리를 강제로 사용합니다. 따라서 파이프라이닝을 사용하여 다수의 작업 명령을 보낼 때에는 10k개의 작업 명령을 보내고 응답을 읽는 등 합리적인 명령 수를 결정하여 일괄적으로 서버에 보내는 것이 가장 좋습니다. , 그런 다음 10k 작업 명령을 보냅니다. 시간 소모는 거의 동일하지만 추가 메모리 소모는 이러한 10k 작업 명령의 배열 응답 결과에 필요한 최대 값이 됩니다. (메모리 소모를 방지하려면 합리적인 값을 선택하세요) 🎜🎜단순한 RTT의 문제가 아닙니다🎜🎜파이프라이닝이 RTT로 인한 소비를 줄이는 유일한 방법은 아니지만 도움이 됩니다. 초당 실행되는 명령 수가 크게 향상됩니다. 문제의 진실은 해당 데이터 구조에 액세스하고 응답 결과를 생성하는 관점에서 볼 때 파이프라인을 사용하지 않는 것이 실제로 매우 저렴하다는 것입니다. 그러나 소켓 I/O의 관점에서는 정확히 그렇습니다. 반대로. 여기에는 read() 및 write() 호출이 포함되므로 사용자 모드에서 커널 모드로 전환해야 합니다. 이러한 종류의 컨텍스트 전환은 특히 시간이 많이 걸립니다. 🎜🎜파이프라이닝 기술이 사용되면 많은 작업 명령이 동일한 read() 호출에서 읽기 작업을 수행하고 많은 수의 응답 결과가 same write() 호출 중에 쓰기 작업이 수행됩니다. 이를 바탕으로 파이프라인의 길이가 증가함에 따라 초당 실행되는 쿼리 수는 아래와 같이 파이프라이닝 기술을 사용하지 않고도 기준선의 10배가 될 때까지 거의 선형적으로 증가합니다. 🎜🎜🎜🎜Some 실제 코드 예제🎜 🎜 번역하지 않으면 기본적으로 파이프라인을 사용하면 성능이 5배 향상된다는 의미입니다. 🎜Redis Scripting(2.6+版本可用),通过使用在Server端完成大量工作的脚本Scripting,可以更加高效的解决大量pipelining用例。使用脚本Scripting的最大好处就是在读和写的时候消耗更少的性能,使得像读、写、计算这样的操作更加快速。(当client需要写操作之前获取读操作的响应结果时,pepelining就显得相形见拙。) 有时候,应用可能需要在使用pipelining时,发送 EVAL 或者 EVALSHA 命令,这是可行的,并且Redis明确支持这么这种SCRIPT LOAD命令。(它保证可可以调用 EVALSHA 而不会有失败的风险)。
读完全文,你可能还会感到疑问:为什么如下的Redis测试基准 benchmark 会执行这么慢,甚至在Client和Server在一个物理机上也是如此:
FOR-ONE-SECOND:
Redis.SET("foo","bar")
END毕竟Redis进程和测试基准benchmark在相同的机器上运行,并且这是没有任何实际的延迟和真实的网络参与,不就是消息通过内存从一个地方拷贝到另一个地方么? 原因是进程在操作系统中并不是一直运行。真实的情景是系统内核调度,调度到进程运行,它才会运行。比如测试基准benchmark被允许运行,从Redis Server中读取响应内容(与最后一次执行的命令相关),并且写了一个新的命令。这时命令将在回环网络的套接字中,但是为了被Redis Server读取,系统内核需要调度Redis Server进程(当前正在系统中挂起),周而复始。所以由于系统内核调度的机制,就算是在回环网络中,仍然会涉及到网络延迟。 简言之,在网络服务器中衡量性能时,使用回环网络测试并不是一个明智的方式。应该避免使用此种方式来测试基准。
위 내용은 Redis에서 쿼리 속도를 높이기 위해 파이프라이닝을 사용하는 문제를 해결하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



