

얼마 전 LMSYS Org(UC Berkeley 주도)의 연구원들이 대규모 언어 모델 버전 예선 대회라는 큰 소식을 전했습니다!
이번 팀은 4명의 새로운 선수뿐만 아니라 (준) 중국 리더보드도 데려왔습니다.
GPT-4만큼은 의심의 여지가 없습니다. 전투에 참여하면 꾸준하게 1위를 차지하게 됩니다.
그러나 놀랍게도 Claude는 OpenAI를 제단으로 끌어올린 GPT-3.5보다 2위를 차지했을 뿐만 아니라 GPT-4보다 50점밖에 뒤지지 않았습니다.
이에 비해 3위인 GPT-3.5는 130억 개의 매개변수를 갖춘 가장 강력한 오픈소스 모델인 비쿠나(Vicuna)보다 72포인트만 더 높다.
그리고 140억 개의 매개변수가 있는 "순수 RNN 모델" RWKV-4-Raven-14B는 뛰어난 성능을 바탕으로 모든 Transformer 모델을 능가하며 6위에 올랐습니다. Vicuna 모델을 제외하고 RWKV는 다른 모든 오픈 소스와 경쟁하고 있습니다. 모델 무승부 게임에서 50% 이상 승리했습니다.
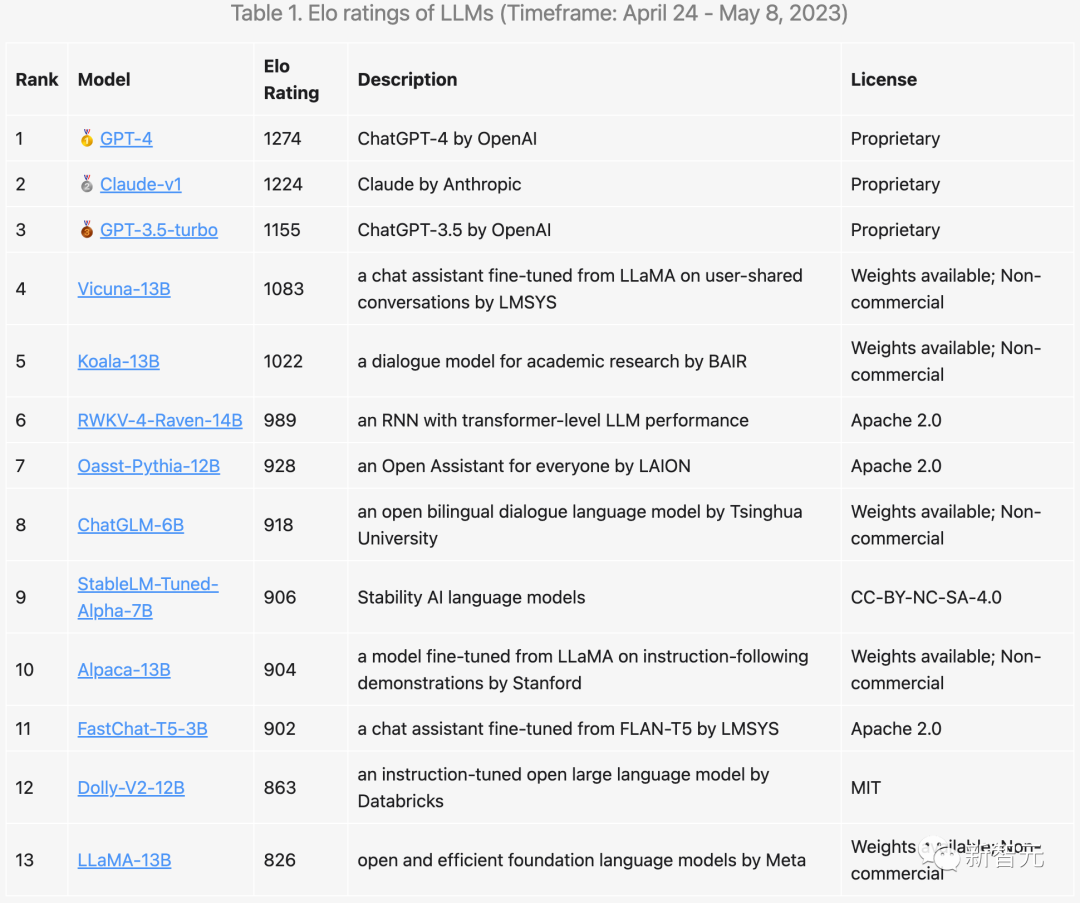
또한 팀에서는 "영어 전용"과 "비영어"(대부분 중국어로 되어 있음)라는 두 가지 별도의 순위도 만들었습니다.
많은 모델들의 순위가 크게 달라진 것을 보실 수 있습니다.
예를 들어, 더 많은 중국 데이터로 훈련된 ChatGLM-6B는 더 나은 성능을 보였으며 GPT-3.5도 성공적으로 Claude를 제치고 2위에 올랐습니다.
이 업데이트의 주요 기여자는 Sheng Ying, Lianmin Zheng, Hao Zhang, Joseph E. Gonzalez 및 Ion Stoica입니다.
Sheng Ying은 LMSYS Org의 세 창립자(나머지 두 명은 Lianmin Zheng 및 Hao Zhang) 중 한 명이며 스탠포드 대학교 컴퓨터 공학과의 박사 과정 학생입니다.
그녀는 단일 GPU에서 175B 모델 추론을 실행할 수 있는 인기 있는 FlexGen 시스템의 작품이기도 합니다. 현재 8,000개의 별을 받았습니다.

논문 주소: https://arxiv.org/abs/2303.06865
프로젝트 주소: https://github.com/FMInference/FlexGen
개인 홈페이지 :https://sites.google.com/view/yingsheng/home
커뮤니티의 도움으로 팀은 총 13,000명의 익명 투표를 모았고, 몇 가지 흥미로운 발견.
3가지 독점 모델 중 GPT-3.5-터보보다 Anthropic의 Claude 모델이 사용자들에게 더 인기가 높습니다.
또한 Claude는 가장 강력한 GPT-4와 경쟁할 때 매우 경쟁력 있는 성적을 거두었습니다.
아래 승률 차트를 보면 GPT-4와 Claude의 무승부 66경기 중 Claude가 32승(48%)을 이겼습니다.
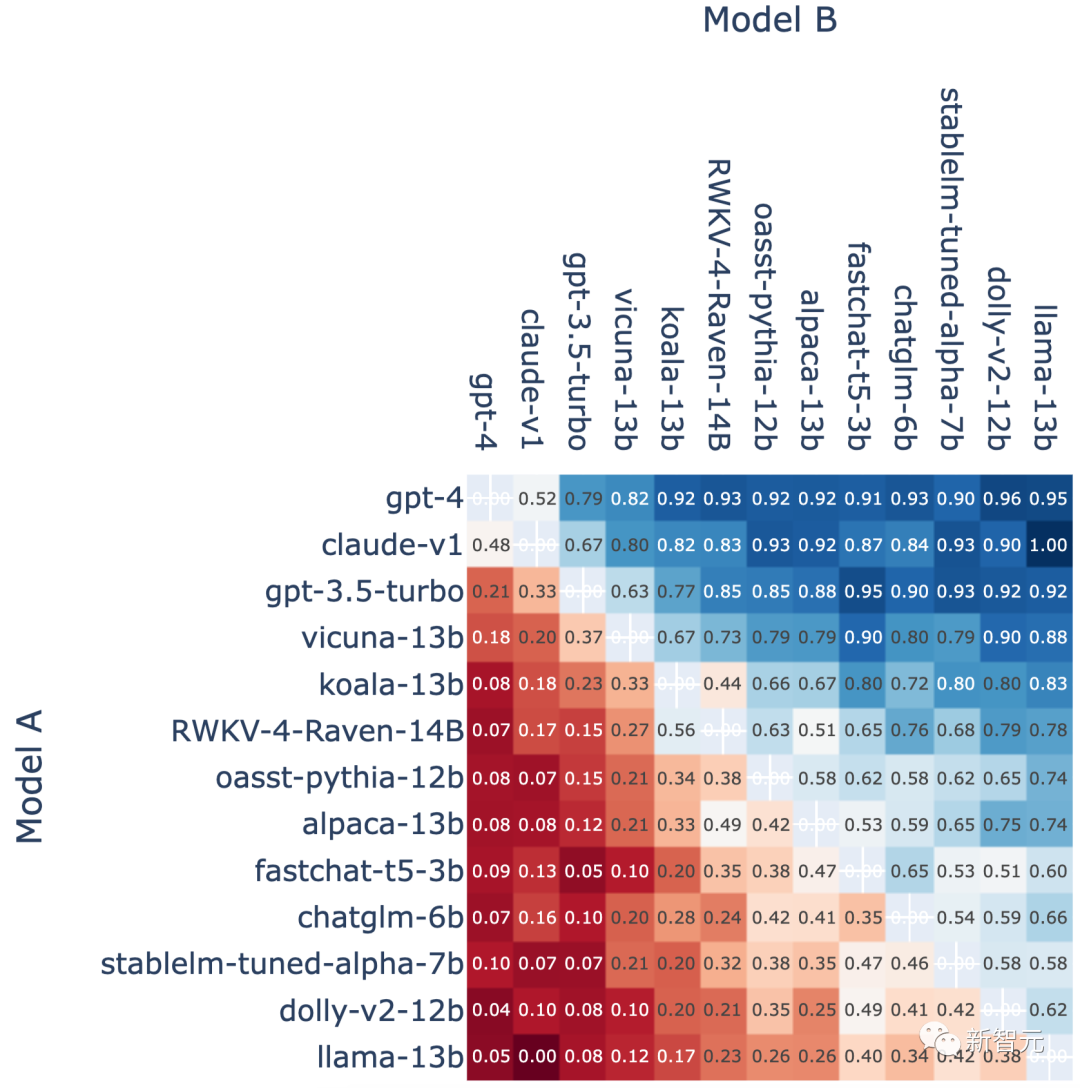
모든 무승부 A 대 B 전투에서 모델 A의 승리 비율
그러나 다른 오픈 소스 모델과 이 세 가지 독점 모델 사이에는 여전히 큰 격차가 있습니다.
특히 GPT-4는 Elo 점수 1274점으로 순위 선두를 달리고 있습니다. 이는 목록에 있는 최고의 오픈 소스 대안인 Vicuna-13B보다 거의 200포인트 더 높습니다.
동점을 제거한 후 GPT-4는 Vicuna-13B를 상대로 게임의 82%를 승리했으며 심지어 이전 세대 GPT-3.5 터보를 상대로 79%를 승리했습니다.
그러나 리더보드에 있는 이러한 오픈 소스 모델은 일반적으로 독점 모델보다 매개변수가 30억~140억 개로 적다는 점에 주목할 가치가 있습니다.
실제로 최근 LLM 및 데이터 큐레이션의 발전으로 더 작은 모델을 사용하여 상당한 성능 향상을 달성할 수 있게 되었습니다.
Google의 최신 PaLM 2가 좋은 예입니다. PaLM 2는 더 작은 모델 크기를 사용할 때 이전 제품보다 더 나은 성능을 달성한다는 것을 알고 있습니다.
따라서 팀은 오픈 소스 언어 모델이 따라잡을 것이라고 낙관하고 있습니다.
아래 이미지에서 사용자는 신중한 추론과 계획이 필요한 까다로운 질문을 했습니다. Claude와 GPT-4는 비슷한 답변을 제공했지만 Claude의 답변은 약간 더 좋았습니다.
그러나 샘플링의 무작위성으로 인해 이러한 상황이 항상 재현될 수는 없다는 사실을 팀에서는 발견했습니다. 때로는 GPT-4도 Claude와 동일한 시퀀스를 제공할 수 있지만 이번 세대 시험에서는 실패했습니다.
또한 팀은 OpenAI API 및 ChatGPT 인터페이스를 사용할 때 GPT-4가 약간 다르게 동작한다는 사실을 발견했습니다. 이는 프롬프트, 샘플링 매개변수 또는 기타 알 수 없는 요인으로 인해 발생할 수 있습니다.

GPT-4보다 Claude를 선호하는 사용자의 예
아래 이미지에서 Claude와 GPT-4 모두 놀라운 기능을 갖추고 있음에도 불구하고 여전히 이러한 유형의 복잡한 문제를 다루고 있습니다. 추론 질문.
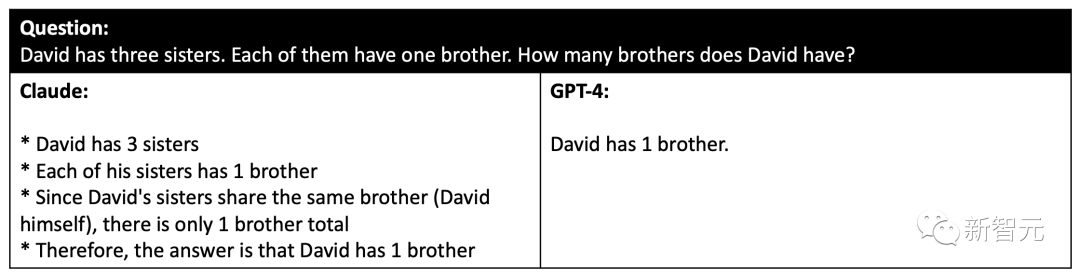
사용자가 Claude와 GPT-4가 모두 틀렸다고 생각하는 예
이러한 까다로운 상황 외에도 복잡한 추론이나 지식이 필요하지 않은 간단한 문제가 많이 있습니다.
이 경우 Vicuna와 같은 오픈 소스 모델은 GPT-4와 비슷한 성능을 발휘할 수 있으므로 GPT-4와 같은 더 강력한 모델 대신 약간 더 약한(그러나 더 작거나 저렴한) LLM(대형 언어 모델)을 사용할 수 있습니다. .
세 가지 강력한 독점 모델이 참여한 이후로 챗봇 분야는 그 어느 때보다 경쟁이 치열했습니다.
오픈 소스 모델이 독점 모델과 대결할 때 많은 게임에서 패했기 때문에 Elo 점수가 떨어졌습니다.
마지막으로 팀에서는 사용자가 자신의 챗봇을 등록하여 순위 매치에 참여할 수 있도록 일부 API도 공개할 계획입니다.
위 내용은 UC Berkeley LLM 준중국어 순위가 나왔습니다! GPT-4가 1위를 차지하고 중국 오픈 소스 RNN 모델이 상위 6위 안에 들었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



