

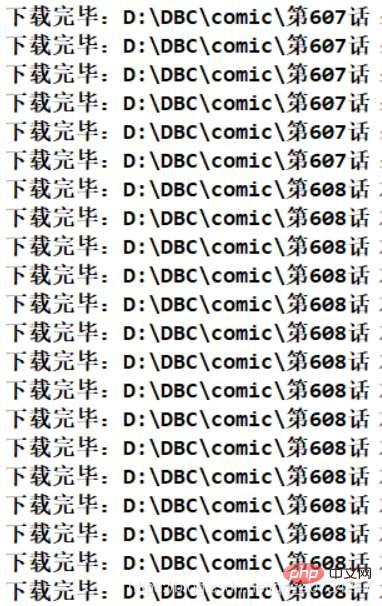
프로그램 실행 효과
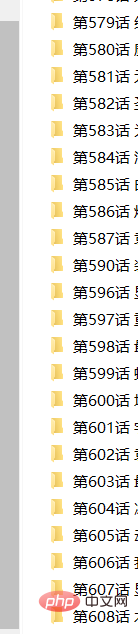
획득된 파일 디렉터리 정보
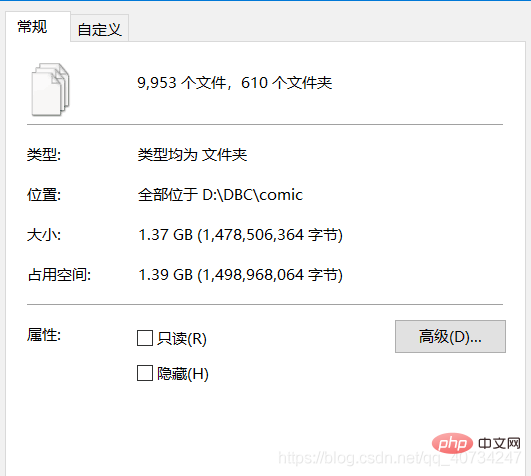
파일의 전체 정보

참고: 여기에 작은 문제는 얻은 파일 중 일부에 접미사 이름이 없을 수 있지만, 구체적인 이유는 영향을 미치지 않으므로 열어서 볼 수 있다는 것입니다. (또는 자체 코드를 사용하여 파일 이름을 바꾸세요.)
다음은 만화를 예로 들어 보겠습니다. 먼저 위의 숫자는 만화의 목차 페이지를 나타냅니다. 이 페이지에 목차가 있다는 것이 매우 중요합니다. 그런 다음 디렉토리에 있는 장을 하나씩 클릭하면 각 장의 만화 정보를 볼 수 있습니다.


여기서 이 페이징은 매우 이상합니다. 각 장의 페이지 수가 동일하지 않기 때문입니다. 그러나 실제로는 직접 선택할 수 있으므로 미리 로드하거나 비동기적으로 로드해야 함을 나타냅니다(실제로는 그렇지 않습니다). 프론트엔드 지식은 모르고 그냥 듣기만 했습니다.) 나중에 소스를 찾아보니(눈으로 발견했습니다) 정말 모든 만화 페이지를 미리 불러올 수 있는 링크였습니다. 비동기적으로 로드되지 않습니다.
여기에서 만화 이미지를 클릭하여 이미지 주소를 얻은 다음 찾은 링크와 비교하면 볼 수 있습니다. 그런 다음 URL을 연결하면 모든 링크를 얻을 수 있습니다.
해당 챕터 페이지에서 브라우저의 뷰소스를 이용하여 해당 스크립트를 찾아보세요. 분석 후 스크립트 배열의 정보는 각 만화 페이지의 해당 정보입니다.

위 스크린샷은 대략적인 구조 정보이므로 획득 과정은 다음과 같습니다. Contents 페이지–>Chapter 페이지–>Comic page
여기에서는 이 스크립트를 문자열로 가져온 다음 "[ " 및 "]"를 사용하여 문자열을 가져온 다음 fastjson을 사용하여 이를 목록 컬렉션으로 변환합니다.
// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);여기서 강조할 점은 Element 객체의 텍스트 메소드는 눈에 보이는 정보를 얻는 것이고, 데이터 메소드는 보이지 않는 정보를 얻는 것입니다. 스크립트 정보는 직접적으로 보이지 않기 때문에 data 메소드를 사용하여 정보를 얻습니다. 소위 보이는 정보와 보이지 않는 정보는 웹 페이지에 표시될 수 있고 소스를 보면 얻을 수 있는 정보를 말합니다. 예를 들어, 이스케이프 문자는 텍스트 확장을 통해 얻을 때 이스케이프 문자가 됩니다.
연결 관리를 위해 HttpClient 연결 풀을 사용하는데, IP 주소가 하나뿐이어서 멀티스레딩을 사용하지 않았습니다. 스레드 시간은 여전히 허용됩니다. 결국 만화는 약 10분 정도 지속됩니다. (예를 들어 600장을 보세요)
package com.comic;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}가장 중요한 클래스로 HTML 페이지를 구문 분석하여 링크 데이터를 얻는 데 사용됩니다. 참고: 여기서 DIR_PATH는 하드코딩된 경로이므로 테스트를 원할 경우 해당 디렉터리를 직접 생성해 주시기 바랍니다.
package com.comic;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.alibaba.fastjson.JSONArray;
public class ComicSpider {
private static final String DIR_PATH = "D:/DBC/comic/";
private String url;
private String root;
private CloseableHttpClient httpClient;
public ComicSpider(String url, String root) {
this.url = url;
// 这里不做非空校验,或者使用下面这个。
// Objects.requireNonNull(root);
if (root.charAt(root.length()-1) == '/') {
root = root.substring(0, root.length()-1);
}
this.root = root;
this.httpClient = HttpClients.createDefault();
}
public void start() {
try {
String html = this.getHtml(url); //获取漫画主页数据
List<Chapter> chapterList = this.mapChapters(html); //解析数据,得到各话的地址
this.download(chapterList); //依次下载各话。
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 从url中获取原始的网页数据
* @throws IOException
* @throws ClientProtocolException
* */
private String getHtml(String url) throws ClientProtocolException, IOException {
HttpGet get = new HttpGet(url);
//下面这两句,是因为总是报一个 Invalid cookie header,然后我在网上找到的解决方法。(去掉的话,不影响使用)。
RequestConfig defaultConfig = RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD).build();
get.setConfig(defaultConfig);
//因为是初学,而且我这里只是请求一次数据即可,这里就简单设置一下 UA
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
HttpEntity entity = null;
String html = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTF-8");
}
}
}
return html;
}
//获取章节名 链接地址
private List<Chapter> mapChapters(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
Elements name_urls = doc.select("#chapter-list-1 > li > a");
/* 不采用直接返回map的方式,封装一下。
return name_urls.stream()
.collect(Collectors.toMap(Element::text,
name_url->root+name_url.attr("href")));
*/
return name_urls.stream()
.map(name_url->new Chapter(name_url.text(),
root+name_url.attr("href")))
.collect(Collectors.toList());
}
/**
* 依次下载对应的章节
* 我使用当线程来下载,这种网站,多线程一般容易引起一些问题。
* 方法说明:
* 使用循环迭代的方法,以 name 创建文件夹,然后依次下载漫画。
* */
public void download(List<Chapter> chapterList) {
chapterList.forEach(chapter->{
//按照章节创建文件夹,每一个章节一个文件夹存放。
File dir = new File(DIR_PATH, chapter.getName());
if (!dir.exists()) {
if (!dir.mkdir()) {
try {
throw new FileNotFoundException("无法创建指定文件夹"+dir);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
//开始按照章节下载
try {
List<ComicPage> urlList = this.getPageUrl(chapter);
urlList.forEach(page->{
SinglePictureDownloader downloader = new SinglePictureDownloader(page, dir.getAbsolutePath());
downloader.download();
});
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
//获取每一个页漫画的位置
private List<ComicPage> getPageUrl(Chapter chapter) throws IOException {
String html = this.getHtml(chapter.getUrl());
Document doc = Jsoup.parse(html, "UTF-8");
Element script = doc.getElementsByTag("script").get(2); //获取第三个脚本的数据
// 获取的script 无法直接解析,必须先将 page url 取出来,
// 这里以 [ ] 为界限,分割字符串。
String pageUrls = script.data();
int start = pageUrls.indexOf("[");
int end = pageUrls.indexOf("]") + 1;
String urls = pageUrls.substring(start, end);
//json 转 集合,这个可以总结一下,不熟悉。
List<String> urlList = JSONArray.parseArray(urls, String.class);
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式
return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径
.map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url))
.collect(Collectors.toList());
}
}참고: 여기서 내 생각은 모든 만화가 DIR_PATH 디렉토리에 저장된다는 것입니다. 그러면 각 장은 하위 디렉토리(챕터 이름을 따서 명명됨)이고, 각 챕터의 만화는 디렉토리에 배치되지만 여기에는 문제가 있습니다. 만화는 실제로 한 페이지씩 읽히기 때문에 순서에 문제가 있다. 그래서 각 만화 페이지에 번호를 부여하고 위 스크립트의 순서에 따라 번호를 매겼습니다. 하지만 Java8의 Lambda 표현식을 사용하고 있기 때문에 인덱스를 사용할 수 없습니다. (이것은 또 다른 문제와 관련이 있습니다). 여기서 해결 방법은 다른 사람들이 추천한 것입니다. 인덱스의 getAndIncrement 메서드를 호출할 때마다 인덱스 값을 늘릴 수 있어 매우 편리합니다.
AtomicInteger index=new AtomicInteger(0); //我无法使用索引,这是别人推荐的方式 return urlList.stream() //注意这里拼接的不是 root 路径,而是一个新的路径 .map(url->new ComicPage(index.getAndIncrement(),"https://restp.dongqiniqin.com//"+url)) .collect(Collectors.toList());
두 개의 엔터티 클래스는 객체 지향적이므로 정보를 캡슐화하기 위해 두 개의 간단한 엔터티 클래스를 설계하여 작업을 더 편리하게 했습니다.
Chapter 클래스는 디렉토리에 있는 각 장의 정보, 장 이름 및 장에 대한 링크를 나타냅니다. ComicPage 클래스는 각 장의 만화 정보 페이지, 각 페이지의 번호 및 링크 주소를 나타냅니다.
package com.comic;
public class Chapter {
private String name; //章节名
private String url; //对应章节的链接
public Chapter(String name, String url) {
this.name = name;
this.url = url;
}
public String getName() {
return name;
}
public String getUrl() {
return url;
}
@Override
public String toString() {
return "Chapter [name=" + name + ", url=" + url + "]";
}
}package com.comic;
public class ComicPage {
private int number; //每一页的序号
private String url; //每一页的链接
public ComicPage(int number, String url) {
this.number = number;
this.url = url;
}
public int getNumber() {
return number;
}
public String getUrl() {
return url;
}
}因为前几天使用多线程下载类爬取图片,发现速度太快了,ip 好像被封了,所以就又写了一个当线程的下载类。 它的逻辑很简单,主要是获取对应的漫画页链接,然后使用get请求,将它保存到对应的文件夹中。(它的功能大概和获取网络中的一张图片类似,既然你可以获取一张,那么成千上百也没有问题了。)
package com.comic;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private CloseableHttpClient httpClient;
private ComicPage page;
private String filePath;
private String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
public SinglePictureDownloader(ComicPage page, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.page = page;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(page.getUrl());
String url = page.getUrl();
//取文件的扩展名
String prefix = url.substring(url.lastIndexOf("."));
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", headers[rand.nextInt(headers.length)]);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, page.getNumber()+prefix);
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}package com.comic;
public class Main {
public static void main(String[] args) {
String root = "https://www.manhuaniu.com/"; //网站根路径,用于拼接字符串
String url = "https://www.manhuaniu.com/manhua/5830/"; //第一张第一页的url
ComicSpider spider = new ComicSpider(url, root);
spider.start();
}
}위 내용은 Java를 사용하여 만화를 크롤링하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



