

여기서 데이터 정리에 필요한 라이브러리는 pandas 라이브러리입니다. 다운로드 방법은 여전히 터미널에서 실행 중입니다: pip install pandas.
먼저 데이터를 읽어야 합니다
import pandas as pd data = pd.read_csv(r'E:\PYthon\用户价值分析 RFM模型\data.csv') pd.set_option('display.max_columns', 888) # 大于总列数 pd.set_option('display.width', 1000) print(data.head()) print(data.info())
세 번째 줄은 내부에서 데이터를 읽는 것입니다. pandas 라이브러리 읽기 기능을 호출하기만 하면 csv 형식이 읽기 및 쓰기 속도가 가장 빠릅니다.
4행과 5행은 실시간 읽기를 위해 모든 열을 표시하는 것입니다. 열이 많은 경우 pycharm은 중간 열 중 일부를 숨기므로 숨김을 방지하기 위해 다음 두 줄의 코드를 추가합니다.
6번째 줄에는 어떤 필드가 있는지, 열 이름이 있는지 알 수 있습니다.
7번째 줄에는 테이블의 기본 정보와 각 열에 데이터가 얼마나 들어 있는지, 해당 필드가 어떤 데이터인지 표시됩니다. . 비어 있지 않은 데이터가 얼마나 됩니까? 첫 번째 단계에서 어떤 기본 열에 null 값이 있는지 확인할 수 있습니다.
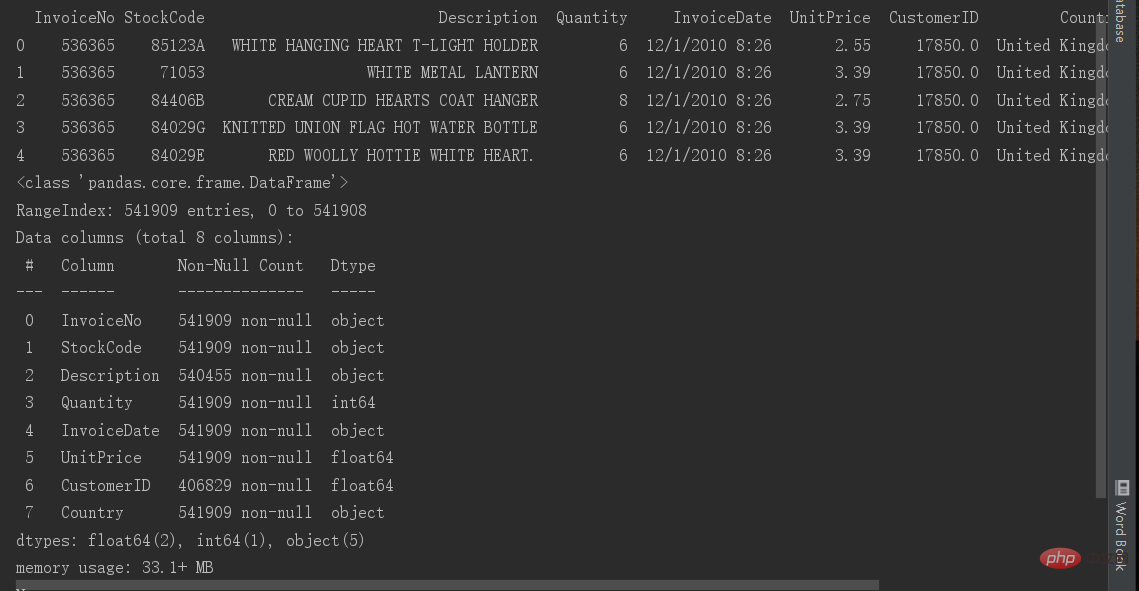
data.info()를 처리한 후 대부분의 데이터에 541909개의 행이 있음을 볼 수 있으므로 Description 및 CustomerID 열에 결과가 누락된 것으로 대략 추측합니다
# 空值处理 print(data.isnull().sum()) # 空值中和,查看每一列的空值 # 空值删除 data.drop(columns=['Description'], inplace=True) print(data.info()) data.isnull()判断是否为空。data.isnumll().sum()计算空值数量。
5번째 줄 null 값 삭제를 수행합니다. 여기서 먼저 설명 열의 null 값을 삭제합니다. inplace=True는 데이터를 수정한다는 의미입니다. inplace=True가 없으면 인쇄된 데이터는 이전과 동일하게 유지됩니다. , 그렇지 않으면 할당을 위해 변수가 재정의됩니다.
이 열에는 Null 값이 상대적으로 적기 때문에 이 데이터 열은 데이터 분석에 그다지 중요하지 않으므로 이 열 전체를 삭제하기로 결정했습니다.
우리 테이블은 고객을 필터링하는 데 사용되므로 CustomerID를 기준으로 다른 열은 강제 삭제됩니다
# CustomerID有空值 # 删除所有列的空值 data.dropna(inplace=True) # print(data.info()) print(data.isnull().sum()) # 由于CustomerID为必须字段,所以强制删除其他列,以CustomerID为准
여기서 먼저 다른 필드에 대한 유형 변환을 수행합니다
유형 변환
# 转换为日期类型 data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate']) # CustomerID 转换为整型 data['CustomerID'] = data['CustomerID'].astype('int') print(data.info())
위에서 null 값을 처리했습니다. , 다음으로 이상값을 처리합니다.
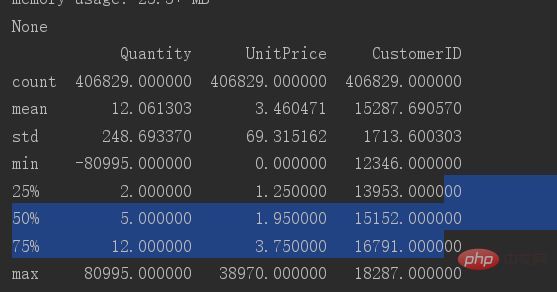
테이블의 기본 데이터 분포를 보려면 explain
print(data.describe())
을 사용하면 됩니다. 데이터 수량 열의 최소값이 -80995인 것을 볼 수 있습니다. 이 열에는 분명히 이상값이 있으므로 이 열에는 다음이 필요합니다. 이상값을 필터링합니다.
0보다 큰 값만 필요합니다.
data = data[data['Quantity'] > 0] print(data)
인쇄하면 397924줄만 나옵니다.
# 查看重复值 print(data[data.duplicated()])
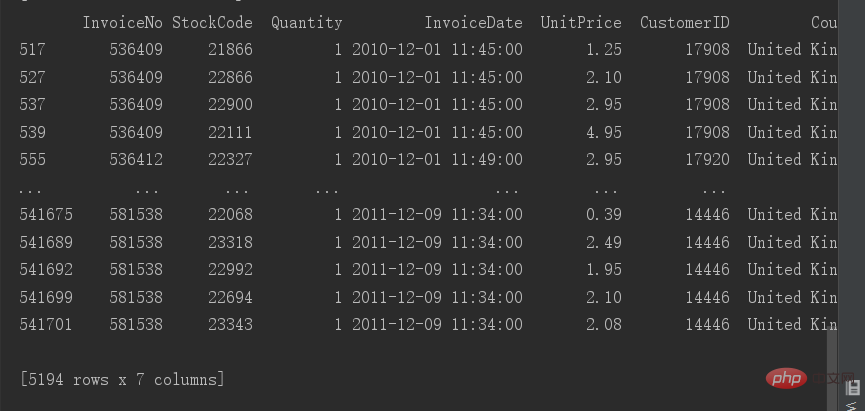
중복 값이 5194행 있습니다. 여기 중복 값은 완전히 중복되어 있어서 쓸모없는 데이터로 삭제할 수 있습니다.
# 删除重复值 data.drop_duplicates(inplace=True) print(data.info())
삭제 후 원본 테이블을 저장한 후 테이블의 기본 정보를 확인하세요
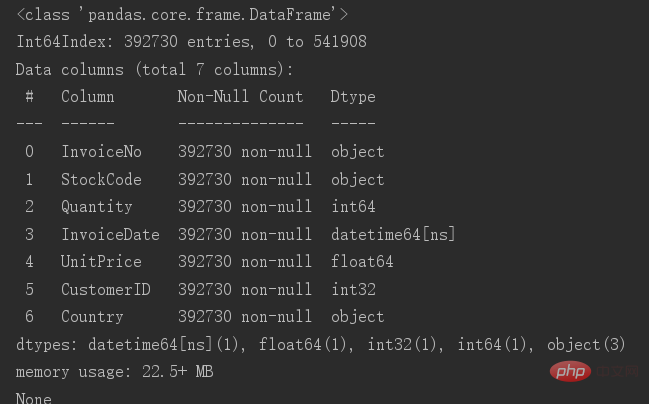
이제 남은 데이터는 392730개입니다. 이 단계에서 데이터 정리가 완료됩니다.
위 내용은 Python의 데이터 정리 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



