

Network Tuning
nginx와 node.js의 기본 전송 메커니즘을 먼저 이해하고 타겟 최적화를 수행하지 않으면 두 가지의 최적화를 아무리 자세하게 수행해도 헛수고가 됩니다. 일반적으로 nginx는 TCP 소켓을 통해 클라이언트와 업스트림 애플리케이션을 연결합니다.
우리 시스템에는 커널 매개변수를 통해 설정되는 tcp에 대한 많은 임계값과 제한 사항이 있습니다. 이러한 매개변수의 기본값은 일반적인 목적으로 설정되는 경우가 많으며 웹 서버의 높은 트래픽 및 짧은 수명 요구 사항을 충족할 수 없습니다.
다음은 TCP 조정을 위한 후보로 사용할 수 있는 몇 가지 매개변수입니다. 이를 효과적으로 적용하려면 /etc/sysctl.conf 파일에 넣거나 /etc/sysctl.d/99-tuning.conf와 같은 새 구성 파일에 넣은 다음 sysctl -p를 실행하여 커널이 로드하도록 하세요. 우리는 이 물리적 작업을 수행하기 위해 sysctl-cookbook을 사용합니다.
여기에 나열된 값은 사용해도 안전하지만 부하, 하드웨어 및 사용량에 따라 보다 적절한 값을 선택하려면 각 매개변수의 의미를 연구하는 것이 좋습니다.
코드 복사 코드는 다음과 같습니다.
net.ipv4.ip_local_port_range='1024 65000'
net.ipv4 .tcp_tw_reuse='1'
net.ipv4.tcp_fin_timeout='15'
net.core.netdev_max_backlog='4096'
net.core.rmem_max='16777216'
net.core.somaxconn='4096'
net.core .wmem_max='16777216'
net.ipv4.tcp_max_syn_backlog='20480'
net.ipv4.tcp_max_tw_buckets='400000'
net.ipv4.tcp_no_metrics_save='1'
net.ipv4.tcp_rmem='40 9 6 87380 16777216'
net .ipv4.tcp_syn_retries='2'
net.ipv4.tcp_synack_retries='2'
net.ipv4.tcp_wmem='4096 65536 16777216'
vm.min_free_kbytes='65536' ;
그 중 중요한 것을 강조하세요.
net.ipv4.ip_local_port_range
업스트림 애플리케이션을 위한 다운스트림 클라이언트를 제공하려면 nginx는 두 개의 TCP 연결(클라이언트에 하나, 애플리케이션에 하나)을 열어야 합니다. 서버가 많은 연결을 수신하면 시스템의 사용 가능한 포트가 빠르게 고갈됩니다. net.ipv4.ip_local_port_range 매개변수를 수정하면 사용 가능한 포트 범위를 늘릴 수 있습니다. 이러한 오류가 /var/log/syslog에 발견되면 "포트 80에서 가능한 신 플러딩. 쿠키 전송"은 시스템이 사용 가능한 포트를 찾을 수 없음을 의미합니다. net.ipv4.ip_local_port_range 매개변수를 늘리면 이 오류를 줄일 수 있습니다.
net.ipv4.tcp_tw_reuse
서버가 다수의 TCP 연결 사이를 전환해야 할 때 time_wait 상태의 다수의 연결이 생성됩니다. time_wait는 연결 자체는 닫혔지만 리소스는 해제되지 않았음을 의미합니다. net_ipv4_tcp_tw_reuse를 1로 설정하면 커널이 안전할 때 연결을 재활용하려고 시도할 수 있으며 이는 새 연결을 다시 설정하는 것보다 훨씬 저렴합니다.
net.ipv4.tcp_fin_timeout
이것은 time_wait 상태의 연결이 재활용되기 전에 기다려야 하는 최소 시간입니다. 더 작게 만들면 재활용 속도가 빨라질 수 있습니다.
연결 상태를 확인하는 방법
netstat:
netstat -tan | awk '{print $6}' | sort | uniq -c
또는 ss:
ss -s
nginx
ss -s
를 사용하세요. (Kernel 541)
tcp : 47461 (Estab 311, 닫힌 47135, 고아 4, Synrecv 0, Timewait 47135/0), 포트 33938
트랜스 포트 총 IPv6 °* 541 -ayraw 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0. tcp 326 325 1
inet 339 335 4
frag 0 0 0
웹 서버의 부하가 점차 증가함에 따라 nginx의 몇 가지 이상한 제한 사항에 직면하기 시작합니다. 연결이 끊어지고 커널이 계속해서 syn Flood를 보고합니다. 현재로서는 로드 평균과 CPU 사용량이 매우 적고 서버가 더 많은 연결을 처리할 수 있다는 것은 정말 실망스러운 일입니다.
조사 결과 time_wait 상태의 연결이 많은 것으로 나타났습니다. 다음은 서버 중 하나의 출력입니다.
time_wait 연결이 47135개 있습니다! 게다가 ss를 보면 모두 닫힌 연결임을 알 수 있습니다. 이는 서버가 사용 가능한 포트의 대부분을 소비했음을 나타내며 서버가 각 연결에 대해 새 포트를 할당하고 있음을 의미합니다. 네트워크를 조정하면 문제가 약간 해결되었지만 여전히 포트가 충분하지 않았습니다.
추가 조사 끝에 다음과 같은 업스트림 연결 유지 지시문에 대한 문서를 찾았습니다.
업스트림 서버에 대한 최대 유휴 연결 유지 연결 수를 설정하세요. 이러한 연결은 작업자 프로세스의 캐시에 유지됩니다.
흥미롭네요. 이론적으로 이 설정은 캐시된 연결을 통해 요청을 전달하여 낭비되는 연결을 최소화합니다. 문서에는 또한 proxy_http_version을 "1.1"로 설정하고 "connection" 헤더를 지워야 한다고 언급되어 있습니다. 추가 조사를 통해 이것이 좋은 아이디어라는 것을 알았습니다. 왜냐하면 http/1.1은 http1.0에 비해 tcp 연결 사용을 크게 최적화하고 nginx는 기본적으로 http/1.0을 사용하기 때문입니다.
문서에서 권장하는 대로 수정하면 업링크 구성 파일은 다음과 같습니다.
코드 복사 코드는 다음과 같습니다.
업스트림 backend_nodejs {
서버 nodejs-3:5016 max_fails=0 failure_timeout=10s;
서버 nodejs-4:5016 max_fails=0 실패_timeout=10s;
서버 nodejs-5:5016 max_fails=0 failure_timeout=10s;
서버 nodejs- 6:5016 max_fails=0 fall_timeout=10s;
keepalive 512;
}
또한 제안한 대로 서버 섹션의 프록시 설정도 수정했습니다. 동시에 실패한 서버를 건너뛰기 위해 Proxy_next_upstream이 추가되었고 클라이언트의 keepalive_timeout이 조정되었으며 액세스 로그가 꺼졌습니다. 구성은 다음과 같습니다.
코드 복사 코드는 다음과 같습니다.
server {
listen 80;
server_name fast.gosquared.com;
client_max_body_size 16m;
keepalive_timeout 10;
location / {
proxy_next_upstream error timeout http_500 http_50 2 http_503 http_504;
proxy_set_header 연결 "";
proxy_http_version 1.1;
proxy_pass http://backend_nodejs;
}
access_log off;
error_log /dev/null crit;
}
새로운 구성을 채택한 후 다음을 발견했습니다. 서버가 차지하는 소켓이 90% 감소했습니다. 이제 훨씬 적은 수의 연결을 사용하여 요청을 전송할 수 있습니다. 새로운 출력은 다음과 같습니다:
ss -s
total: 558(커널 604)
tcp: 4675(estab 485, close 4183, orphaned 0, synrecv 0, timewait 4183/0), 포트 2768
transport total ip ipv6
* 604 - -
raw 0 0 0
udp 13 10 3
tcp 492 491 1
inet 505 501 4
node.js
I/O를 비동기적으로 처리할 수 있는 이벤트 중심 설계 덕분에 node.js는 대규모 처리가 가능합니다. 즉시 사용 가능한 연결 및 요청 금액입니다. 다른 튜닝 기술이 있지만 이 기사에서는 주로 node.js의 프로세스 측면에 중점을 둘 것입니다.
노드는 단일 스레드이며 다중 코어를 자동으로 사용하지 않습니다. 즉, 응용 프로그램은 서버의 전체 기능을 자동으로 얻을 수 없습니다.
노드 프로세스의 클러스터링 달성
여러 스레드를 포크하고 동일한 포트에서 데이터를 수신하여 로드가 여러 코어에 걸쳐 실행되도록 애플리케이션을 수정할 수 있습니다. Node에는 이 목표를 달성하는 데 필요한 모든 도구를 제공하는 클러스터 모듈이 있지만 이를 애플리케이션에 추가하려면 많은 수작업이 필요합니다. Express를 사용하는 경우 eBay에는 사용할 수 있는 Cluster2라는 모듈이 있습니다.
컨텍스트 전환 방지
여러 프로세스를 실행할 때 각 CPU 코어가 동시에 하나의 프로세스로만 사용되는지 확인해야 합니다. 일반적으로 CPU에 n개의 코어가 있으면 n-1개의 애플리케이션 프로세스를 생성해야 합니다. 이렇게 하면 각 프로세스가 합리적인 시간 조각을 확보하여 커널 스케줄러가 다른 작업을 실행할 수 있도록 하나의 코어를 확보할 수 있습니다. 또한 CPU 경합을 방지하기 위해 기본적으로 node.js 이외의 다른 작업이 서버에서 실행되지 않도록 해야 합니다.
한 번은 실수를 해서 두 개의 node.js 애플리케이션을 서버에 배포한 후 각 애플리케이션이 n-1개의 프로세스를 열었습니다. 결과적으로 서로 CPU를 놓고 경쟁하게 되어 시스템 부하가 급격히 증가하게 됩니다. 우리 서버는 모두 8코어 머신이지만 컨텍스트 전환으로 인한 성능 오버헤드는 여전히 뚜렷하게 느껴집니다. 컨텍스트 스위칭(Context Switching)은 CPU가 다른 작업을 수행하기 위해 현재 작업을 일시 중단하는 현상을 말합니다. 전환할 때 커널은 현재 프로세스의 모든 상태를 일시 중지한 다음 다른 프로세스를 로드하고 실행해야 합니다. 이 문제를 해결하기 위해 각 응용 프로그램에서 시작되는 프로세스 수를 줄이고 CPU를 공정하게 공유하도록 했습니다. 그 결과 시스템 로드가 떨어졌습니다. 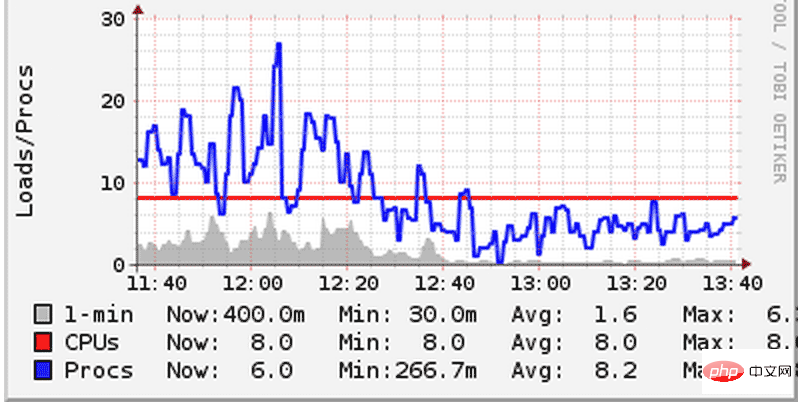
시스템이 어떻게 작동하는지 보려면 위 그림에 주의하세요. 로드(파란색 선)가 CPU 코어 수(빨간색 선) 미만으로 떨어졌습니다. 다른 서버에서도 같은 현상이 나타났습니다. 전체 작업량은 동일하므로 위 그래프의 성능 향상은 컨텍스트 전환의 감소에 따른 것일 수밖에 없습니다.
특별한 순서는 없습니다.
1. 성능에 문제가 발생하면 애플리케이션 계층에서 계산 및 처리를 수행할 수 있으면 데이터베이스 계층에서 꺼내세요. 정렬과 그룹화는 전형적인 예입니다. 데이터베이스 계층보다 애플리케이션 계층에서 성능을 향상시키는 것이 항상 더 쉽습니다. MySQL과 마찬가지로 sqlite도 제어하기가 더 쉽습니다.
2. 병렬 컴퓨팅에 관해서는 피할 수 있으면 피하십시오. 피할 수 없다면 큰 힘에는 큰 책임이 따른다는 사실을 기억하십시오. 가능하다면 스레드를 직접 조작하지 마십시오. 가능할 때마다 더 높은 수준의 추상화에서 작동하십시오. 예를 들어 iOS에서는 GCD, 배포 및 대기열 작업이 친구입니다. 인간의 두뇌는 무한한 일시적 상태를 분석하도록 설계되지 않았습니다. 저는 이것을 힘들게 배웠습니다.
3. 상태를 최대한 단순화하고 현지화하세요. 적용 가능성이 우선입니다.
4. 짧고 결합 가능한 방법이 가장 좋습니다.
5. 코드 주석은 쉽게 구식이거나 오해의 소지가 있기 때문에 위험하지만 이것이 주석을 작성하지 않을 이유는 아닙니다. 사소한 것에 댓글을 달지 마세요. 하지만 필요하다면 특별한 곳에 전략적으로 긴 댓글이 필요합니다. 당신의 기억은 아마도 내일 아침, 어쩌면 커피 한잔 후에 당신을 배반할 것입니다.
6. 사용 사례 시나리오가 "괜찮다"고 생각한다면 한 달 후에 출시된 제품에서 비참하게 실패할 수도 있습니다. 회의적인 사람이 되어 테스트하고 검증하십시오.
7. 의심스러운 경우 팀의 모든 관련 사람들에게 문의하세요.
8. 올바른 일을 하십시오 - 일반적으로 이것이 무엇을 의미하는지 알고 있습니다.
9. 사용자는 바보가 아닙니다. 단지 단축키를 이해할 인내심이 없을 뿐입니다.
10. 개발자가 자신이 개발하는 시스템의 장기 유지 관리를 담당하지 않는 경우 주의하세요. 피, 땀, 눈물의 80%는 소프트웨어가 출시된 후 흘려지는 시간입니다. 그러면 당신은 염세주의자가 될 뿐만 아니라 더 똑똑한 "감정가"가 될 것입니다.
11. 할 일 목록은 가장 친한 친구입니다.
12. 일을 더 재미있게 만들기 위해 솔선하세요. 때로는 노력이 필요할 때도 있습니다.
13. 아직도 악몽에서 깨어나는 조용한 붕괴. 모니터링, 로깅, 경고. 다양한 잘못된 경보와 피할 수 없는 감각 둔화를 인식하세요. 시스템이 오류에 대해 적시에 경고하도록 유지하십시오.
위 내용은 고부하 네트워크에 대해 Nginx 및 Node.js를 최적화하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



